Download as PDF, PPTX




















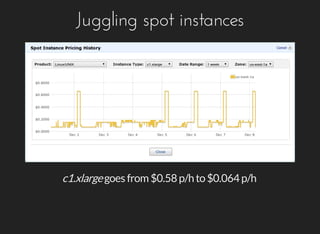









The document discusses the challenges and methodologies involved in web data extraction and analysis using tools like Google Analytics and Hadoop. It highlights how leaked browsing history can be estimated and the costs associated with processing large datasets, emphasizing the feasibility of utilizing cloud computing for such tasks. Additionally, it provides resources for accessing raw web data and examples for implementation.


































