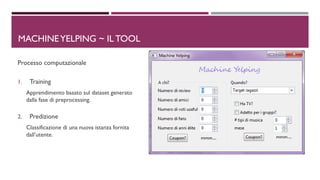
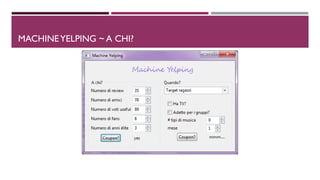
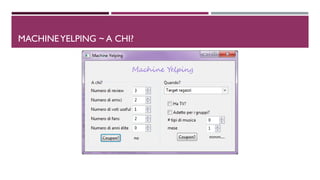
Il documento discute l'analisi del dataset di Yelp per valutare l'efficacia della distribuzione di coupon promozionali. Si utilizzano metodi di machine learning, in particolare SVM e Random Forest, per classificare gli utenti e i business, ottimizzando quando e a chi fornire i coupon. Nonostante le sfide presentate, i risultati mostrano un potenziale significativo per selezionare i consumatori interessati in momenti favorevoli.


![DATASET
Il dataset si presenta come file json distinti. Ognuno rappresenta una certa categoria
Utenti [1milione]
Business [144 mila] dislocati in 11 città
Recensioni [+4 milioni]
Ed altre informazioni…
Tips ed immagini
Non pertinenti al nostro studio.](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-3-320.jpg)
![UTENTI
{
" user_id" : "id crittografato dell’utente",
" name" : "nome utente",
" review_count" : numero di recensioni,
" yelping_since" : data nel formato AAAA -MM -DD,
" friends" : ["un array di id crittografati degli utenti amici all’utente corrente"],
" useful" : "numero di voti useful rilasciati dall’utente",
" funny" : "numero di voti funny rilasciati dall’utente",
" cool" : "numero di voti cool rilasciati dall’utente",
" fans" : "numero di fan dell'utente corrente",
" elite" : [" array di anni che l'utente corrente stato considerato elite"],
" average_stars" : votazione media rilasciata in floating point, ad esempio 4.31,
" compliment_... " : numero di complimenti … ricevuti dall’utente
}](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-4-320.jpg)
![BUSINESS
{
" business_id " : "id crittografato del business ",
" name " : " nome del business ",
" neighborhood " : " vicinato ",
" city " : " città ",
" state " : " stato ", //altre info relative alla localizzazione geografica
" stars " : voto sotto forma di stelline arrotondate a half -stars ,
" review_count " : numero di review ,
" is_open " : 0/1 ( chiuso / aperto ),
" attributes " : ["array di stringhe : ogni elemento e un attributo"],
" categories " : ["array di stringhe di categorie a cui il business corrente e associato"],
" hours " : ["array di stringhe che riportano gli orari di apertura"],
" type " : " business "
}](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-5-320.jpg)




![1PREPROCESSING ~ BUSINESS [PRIMO APPROCCIO]
Non
Coupon
Coupon
Etichettare i business.
Il dataset etichettato è costituito dalle
informazioni del business associate al
mese e alla classificazione.
✓ Dataset cresce di dimensione
✓ Unico valore di output da
produrre
Classi](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-14-320.jpg)
![PREPROCESSING ~ BUSINESS [PRIMO APPROCCIO]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-15-320.jpg)
![PREPROCESSING ~ BUSINESS [PRIMO APPROCCIO]
Pizza
Restaurant CafèPub
Bar
Gelato
Wine
Chocolatiers
DessertTea
BakeryCreperies
IceCream
Sushi
Tapas
Pita
Tacos
Gluten-Free
Vegeterian
Fruit &Veggies
Beer](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-16-320.jpg)
![PREPROCESSING ~ BUSINESS [PRIMO APPROCCIO]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-17-320.jpg)
![PREPROCESSING ~ BUSINESS [SECONDO APPROCCIO]
Forse
Coupon
Non
Coupon
Coupon
Si passa da una classificazione
due valori ad una classificazione
a tre.
✓ Raffinamento della
classificazione
✓ Possibilità di estendere le
informazioni del business](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-18-320.jpg)
![PREPROCESSING ~ BUSINESS [SECONDO APPROCCIO]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-19-320.jpg)
![Elaborazione:
PREPROCESSING ~ BUSINESS [SECONDO APPROCCIO]
foreach(Business business)
foreach(mese)
avg = calcolo star media
count review](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-20-320.jpg)
![PREPROCESSING ~ BUSINESS [SECONDO APPROCCIO]
Business COUPON:
business nei mesi con review
che contengono keyword
coupon, koupon o voucher
Business POSSIBILI coupon:
business nei mesi con review
con 1 o 5 stelle
Business NON coupon :
altri](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-21-320.jpg)
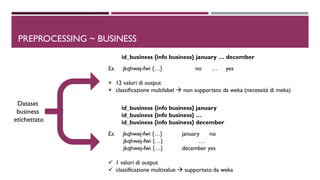
![ id_business {info business} january
id_business {info business} …
id_business {info business} december
PREPROCESSING ~ BUSINESS [ULTERIORI TEST]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-22-320.jpg)
![ id_business {info business} january #review_per_month star_avg_per_month
id_business {info business} …
id_business {info business} december #review_per_month star_avg_per_month
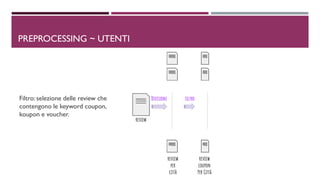
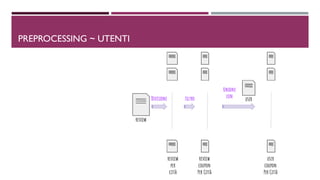
YES business con review che contengono le keyword
MAYBE business nei mesi di picchi di minimo e massimo, in termini di affluenza
NO i rimanenti
YES business nei mesi di picchi di minimo e massimo, in termini di affluenza
NO i rimanenti
PREPROCESSING ~ BUSINESS [ULTERIORI TEST]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-23-320.jpg)

![DMACHINEYELPING ~ QUANDO? [RAGAZZI]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-29-320.jpg)
![DMACHINEYELPING ~ QUANDO? [RAGAZZI]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-30-320.jpg)
![DMACHINEYELPING ~ QUANDO? [FAMIGLIE]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-31-320.jpg)
![DMACHINEYELPING ~ QUANDO? [FAMIGLIE]](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-32-320.jpg)







![DRISULTATI ~ A CHI?
Feature considerate: Review count, Friends, Useful, Fans, Èlite.
Classificatore: SMO
Training set: sia casi negativi che positivi [50K istanze].
Test set:
Yes No
50 21 Yes
0 111 No
Yes No
0 0 Yes
0 111 No
Solo casi negativiSia casi negativi che positivi
#istanze = 184
#istanze classificate correttamente = 89%
#istanze = 111
#istanze classificate correttamente = 100%](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-40-320.jpg)
![DRISULTATI ~ QUANDO? [PRIMO APPROCCIO]
Approccio a target: Ragazzi e Famiglie.
Feature [Ragazzi] HasTv, GoodForGroups e Music.
Feature [Famiglie] GoodForKids, BusinessParking e TableService.
Classificatori: SMO e Random Forest, con split del 80%
Training set: sia casi negativi che positivi [13K istanze].](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-41-320.jpg)
![DRISULTATI ~ QUANDO? [PRIMO APPROCCIO]
Yes No
958 290 Yes
657 541 No
Yes No
1000 248 Yes
684 514 No
SMORandom Forest
#istanze = 2466
#istanze classificate correttamente = 61%
#istanze = 2466
#istanze classificate correttamente = 62%
TARGET RAGAZZI](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-42-320.jpg)
![DRISULTATI ~ QUANDO? [PRIMO APPROCCIO]
Yes No
959 289 Yes
651 647 No
Yes No
1073 175 Yes
658 540 No
SMORandom Forest
#istanze = 2466
#istanze classificate correttamente = 66%
#istanze = 2466
#istanze classificate correttamente = 66%
TARGET FAMIGLIE](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-43-320.jpg)
![DRISULTATI ~ QUANDO? [PRIMO APPROCCIO]
Yes No
885 363 Yes
338 860 No
Yes No
915 333 Yes
411 787 No
SMORandom Forest
#istanze = 2466
#istanze classificate correttamente = 71%
#istanze = 2466
#istanze classificate correttamente = 70%
FEATURES SELECTION
Feature BusinessParking,Ambience, GoodForMeal,WheelchairAccesible e #Review.](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-44-320.jpg)
![DRISULTATI ~ QUANDO? [SECONDO APPROCCIO]
Le classi diventano da {yes, no} a {yes, no, maybe}
Feature Feature Selection
Classificatori Random Forest e SMO, con split del 80%
Training set: sia casi negativi che positivi.
Yes No Maybe
832 129 278 Yes
99 521 98 No
269 168 233 Maybe
Yes No Maybe
977 262 0 Yes
112 606 0 No
384 286 0 Maybe
SMORandom Forest
#istanze = 2627
#istanze classificate correttamente = 60%
#istanze = 2627
#istanze classificate correttamente = 60%](https://image.slidesharecdn.com/machineyelpingslide-180102095213/85/Machine-Yelping-45-320.jpg)






























