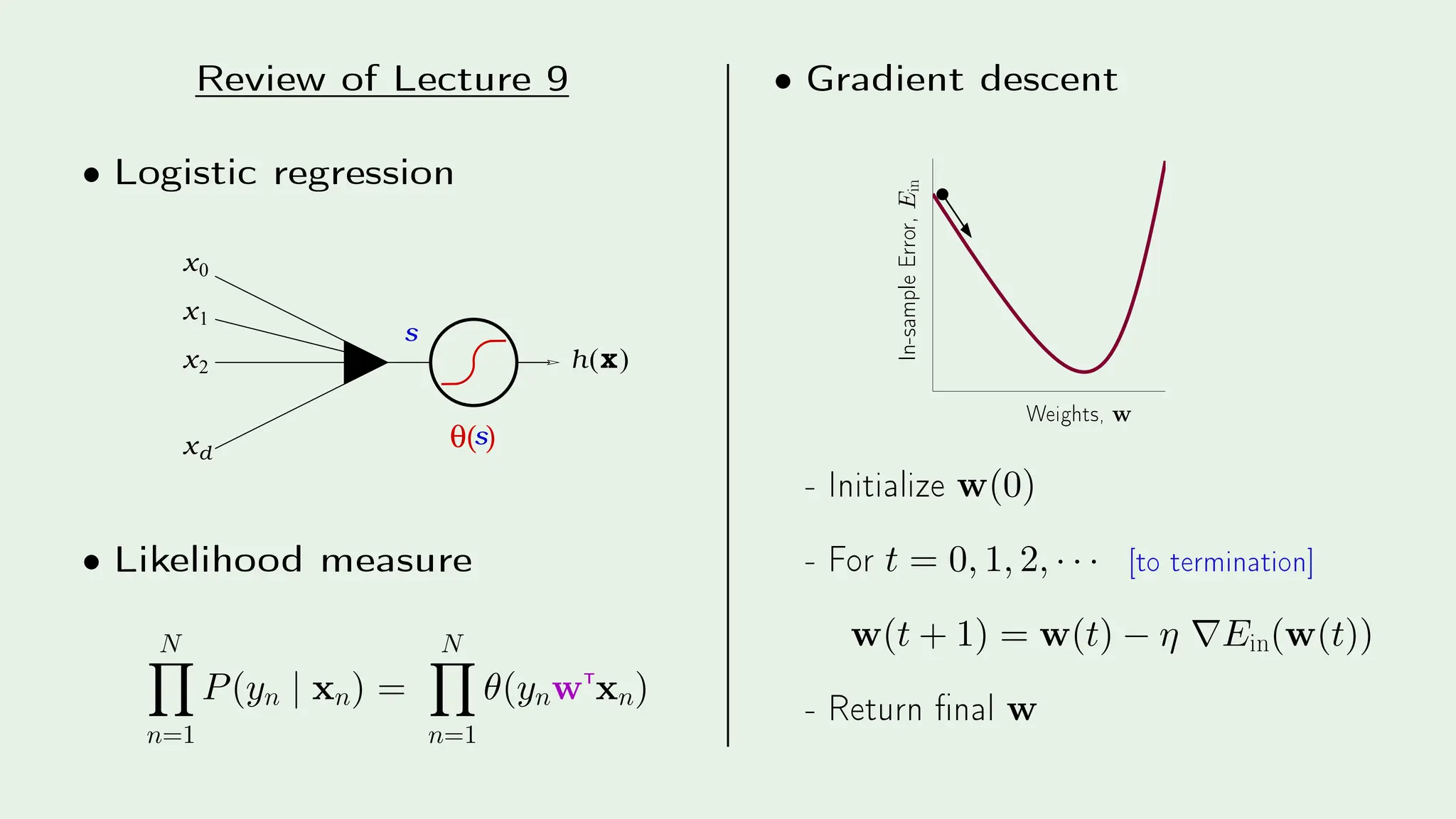
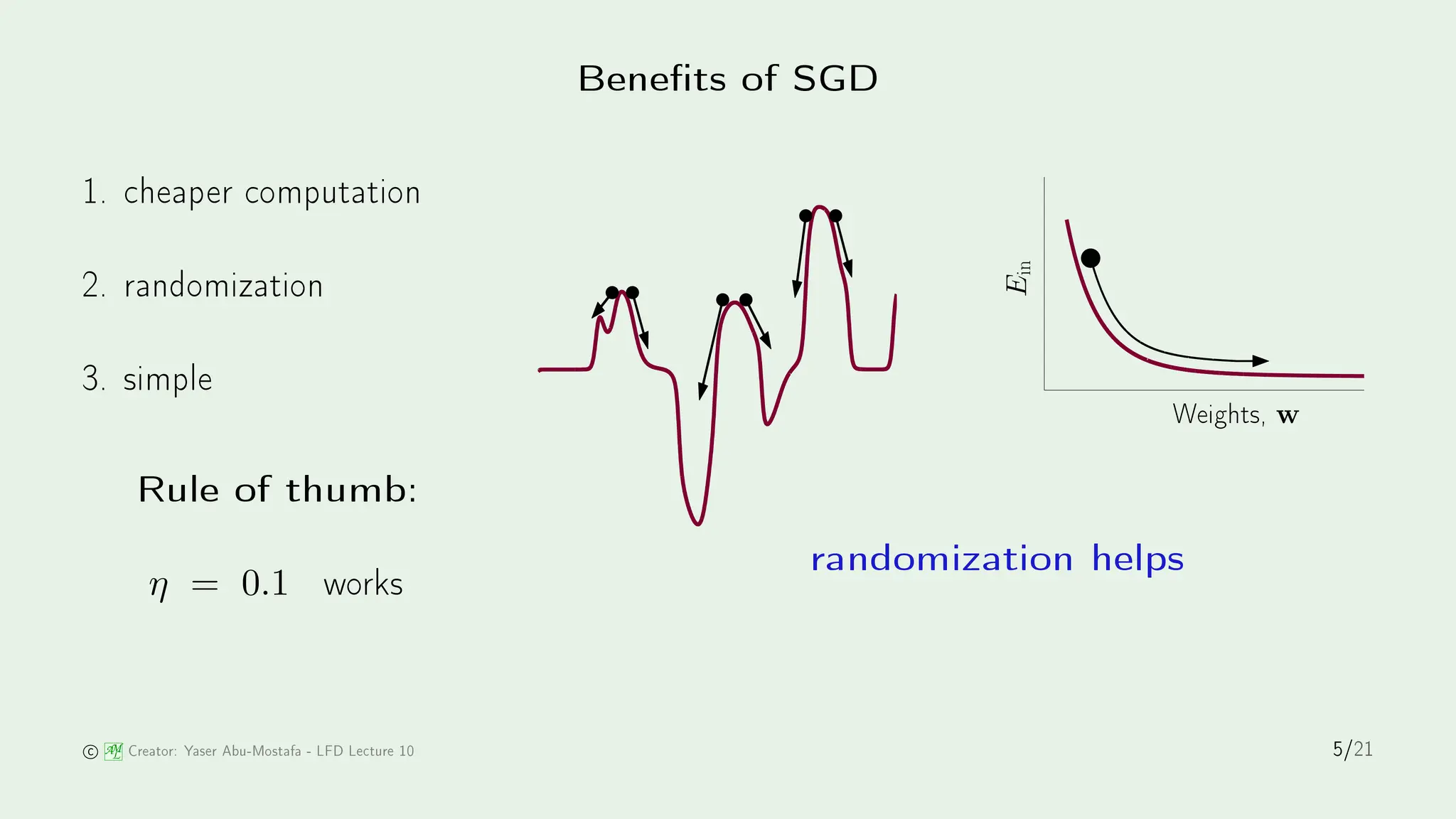
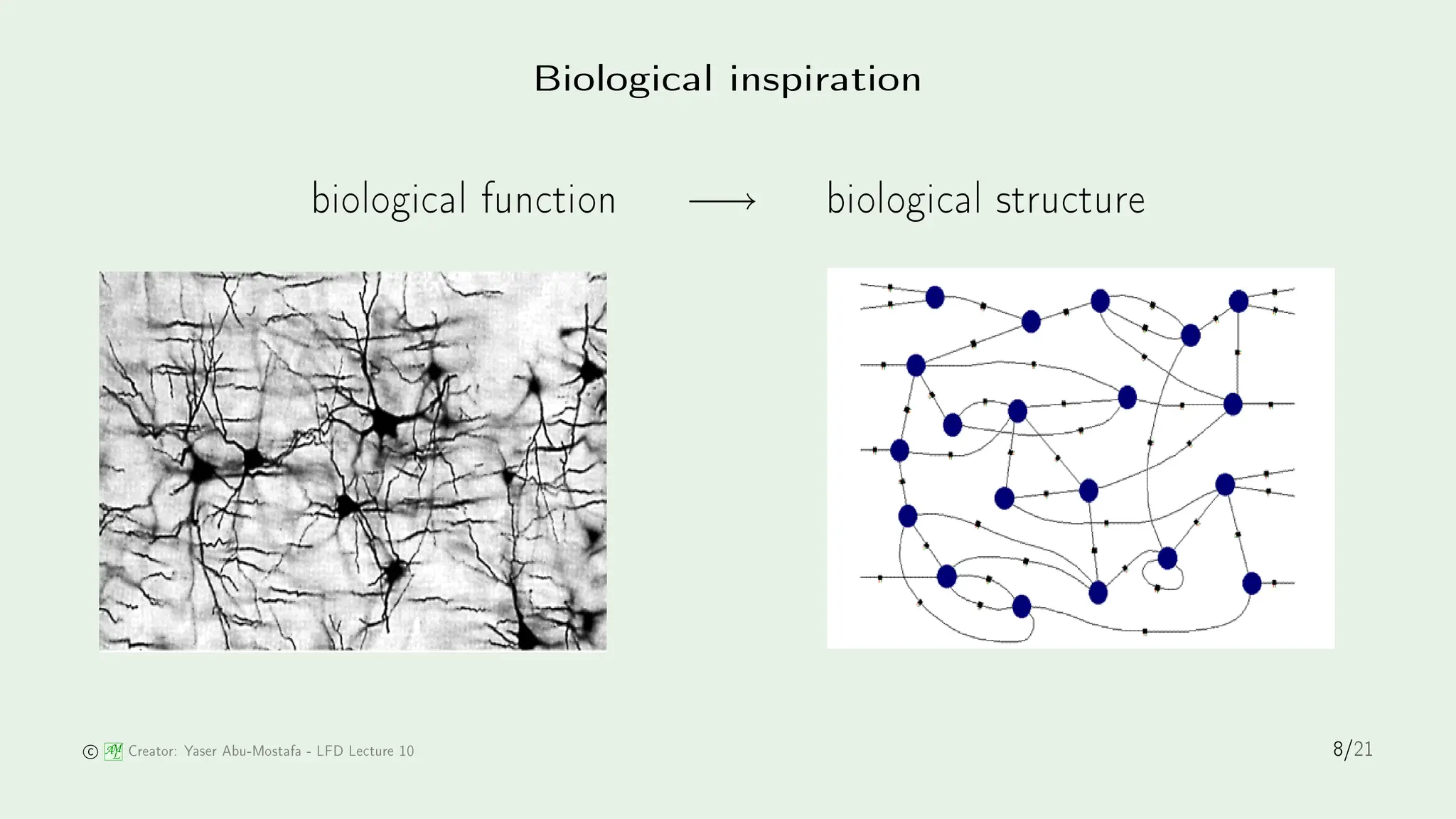
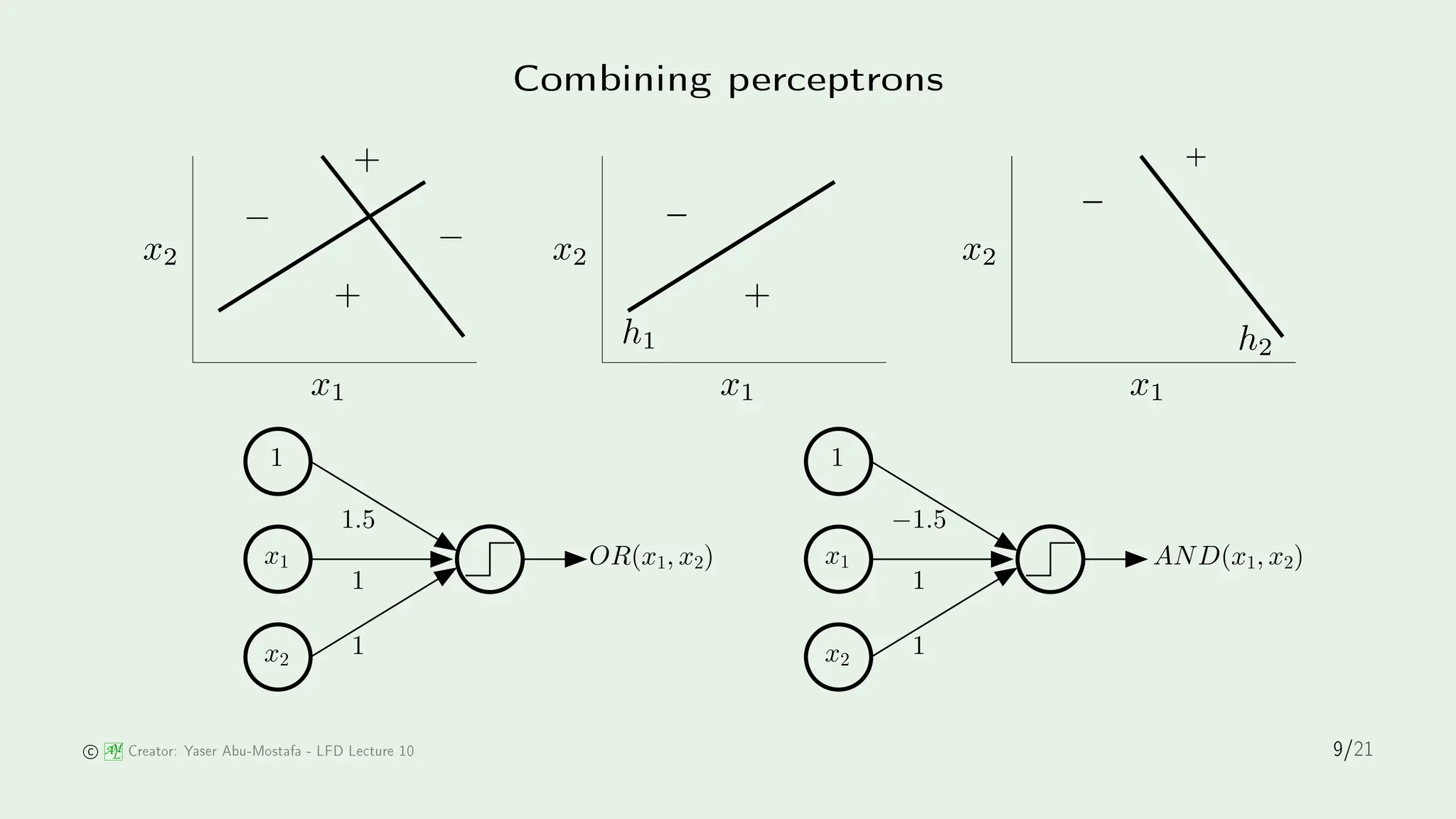
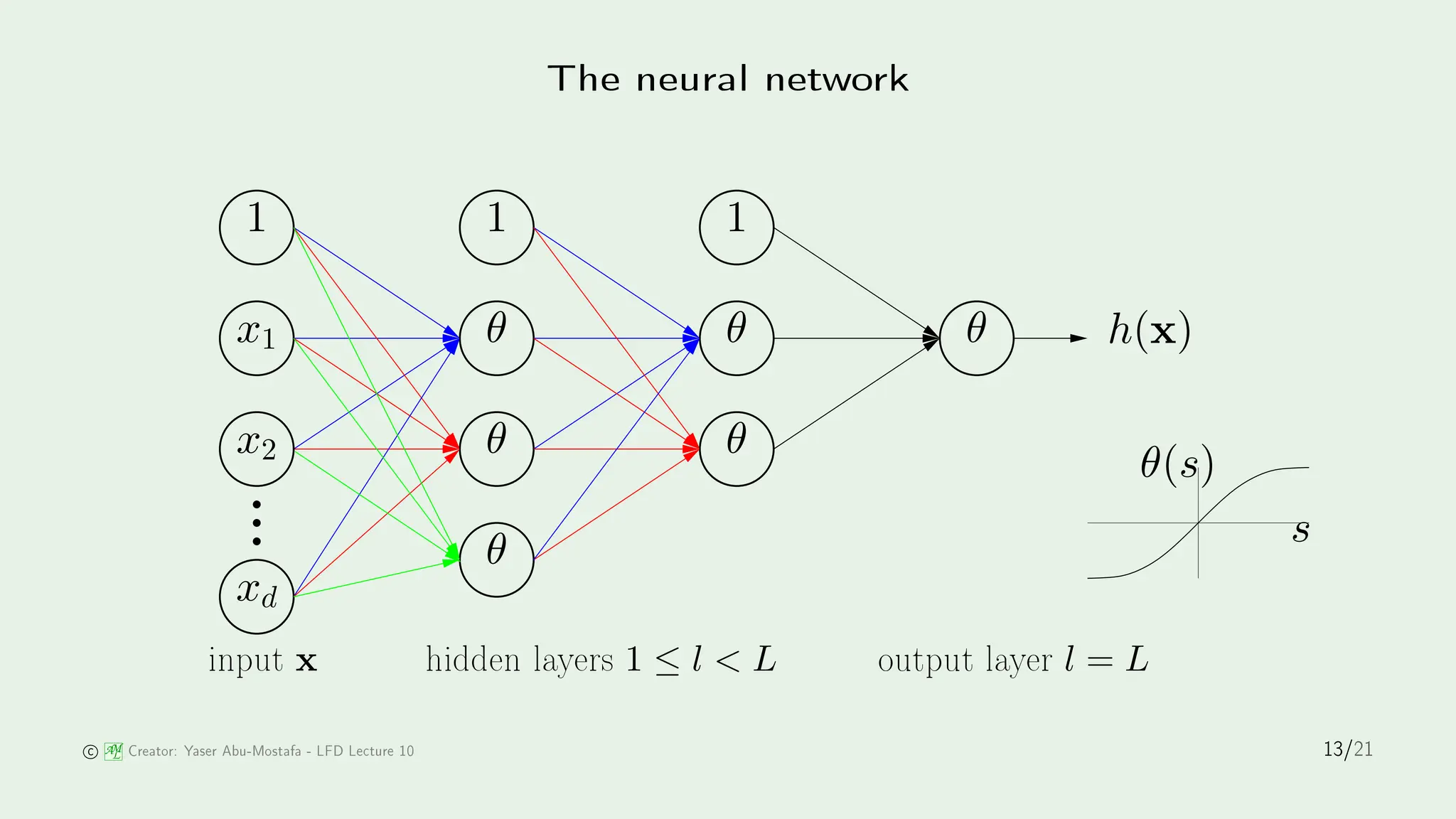
The document discusses stochastic gradient descent (SGD) and its application in logistic regression and neural networks, outlining the principles of how SGD minimizes error through iterative weight updates. It further details the backpropagation algorithm as a method for training multilayer perceptrons through the calculation of gradients. The influence of biological inspiration on neural network architecture is also addressed, emphasizing the complexity and power of neural models.






































![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)





















