











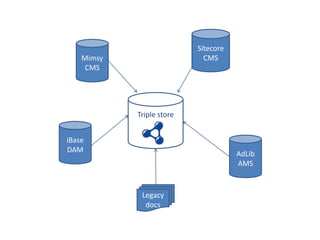











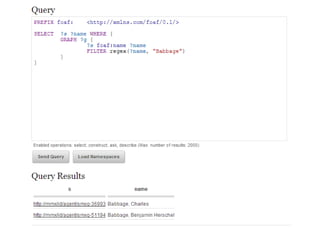























The document discusses the integration of linked data into the collections management systems at the Science Museum to enhance data connectivity and extensibility. It outlines the challenges faced, such as identifiers stability and the need for a mindset change regarding linked data's capabilities. The future direction emphasizes leveraging existing data sources and expanding to linked open data through various ontologies and public APIs.

























































