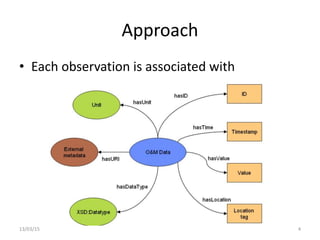
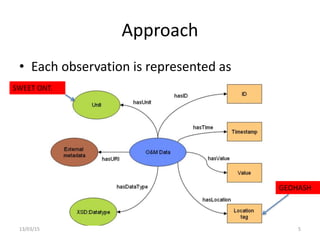
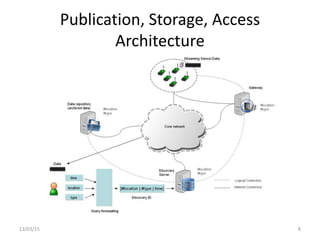
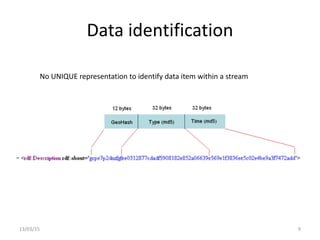
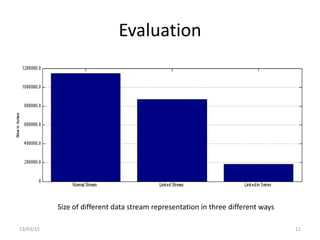
The document discusses a linked-data model aimed at representing semantic sensor data streams to enhance the efficiency of queries on large-scale annotated data. It proposes a solution that centralizes static attributes and facilitates their association with dynamic observations, utilizing a clustering approach for storage and retrieval. Evaluation focuses on data representation, identification, and the efficiency of clustering methods in various scenarios.






























![Valen Metadata and the [Data] Repository](https://cdn.slidesharecdn.com/ss_thumbnails/valen-2-feb23-170223194717-thumbnail.jpg?width=640&height=640&fit=bounds)







![Naming in content_oriented_architectures [repaired]](https://cdn.slidesharecdn.com/ss_thumbnails/namingincontentorientedarchitecturesrepaired-140704214639-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Databeers] 17/06/2014 - Oscar Corcho: LSD](https://cdn.slidesharecdn.com/ss_thumbnails/databeerslsdoscarcorcho-140626050217-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






































