Downloaded 64 times



























![33
Building with SBT
build.sbt
Should include Scala version and Spark dependencies
Directory Structure
./myapp/src/main/scala/MyApp.scala
Package the jar
from the ./myapp folder run
sbt package
a jar file is created in
./myapp/target/scala-2.10/myapp_2.10-1.0.jar
spark-submit, specific master URL or local
SPARK_HOME/bin/spark-submit
--class "MyApp"
--master local[4]
target/scala-2.10/myapp_2.10-1.0.jar](https://image.slidesharecdn.com/datafactzintroductiontospark-151013200232-lva1-app6892/75/Introduction-to-Spark-DataFactZ-33-2048.jpg)


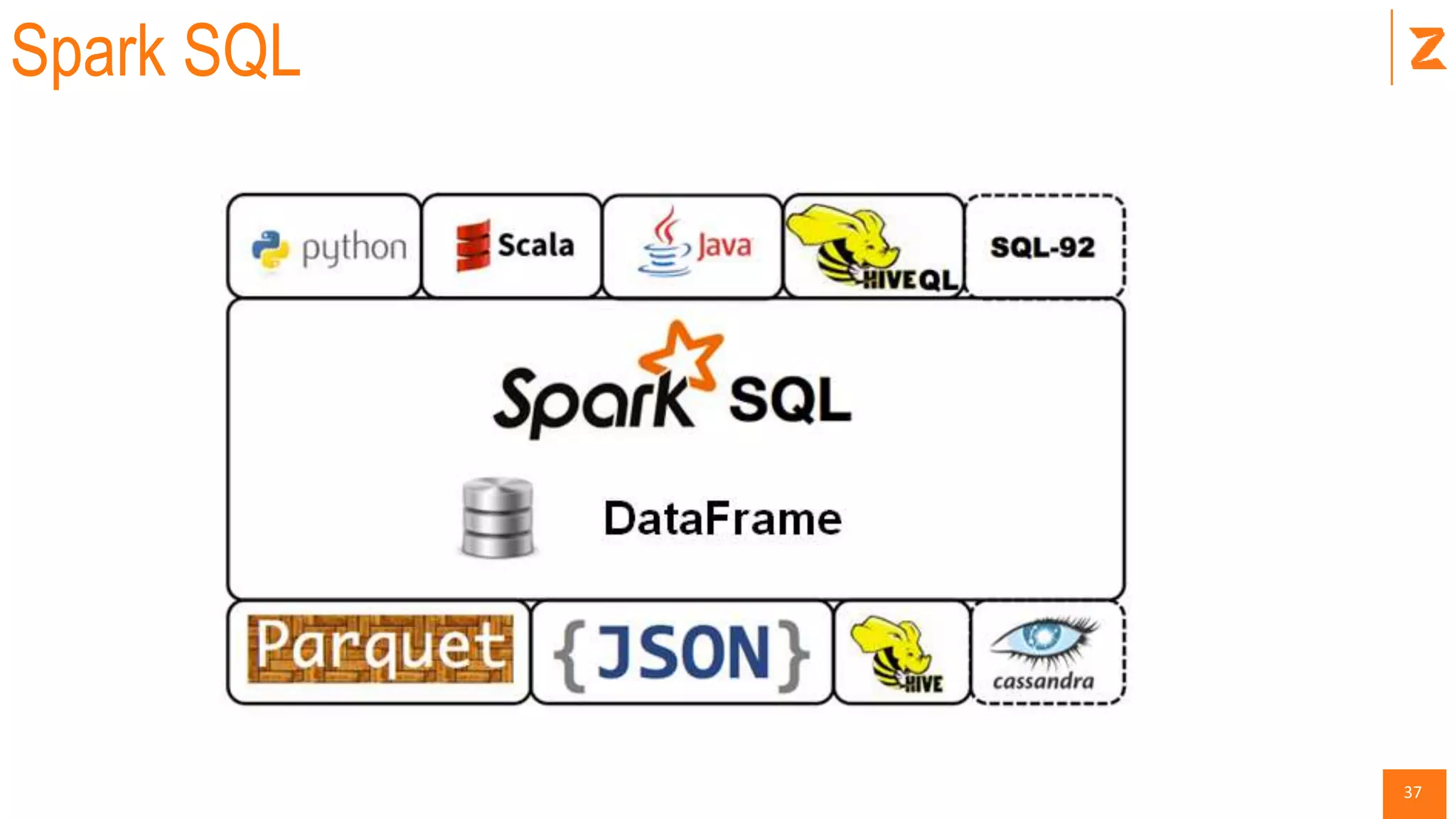
























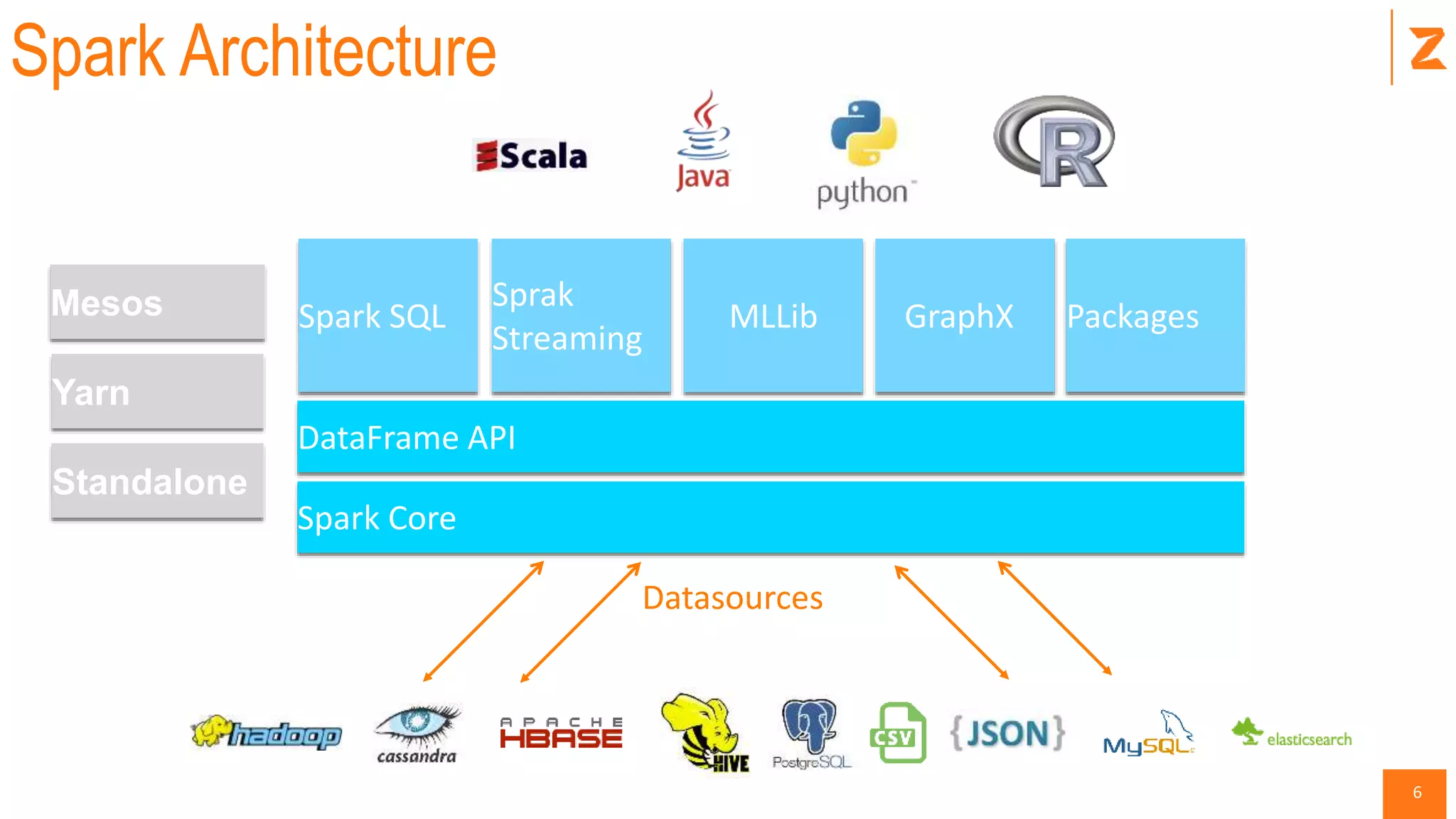
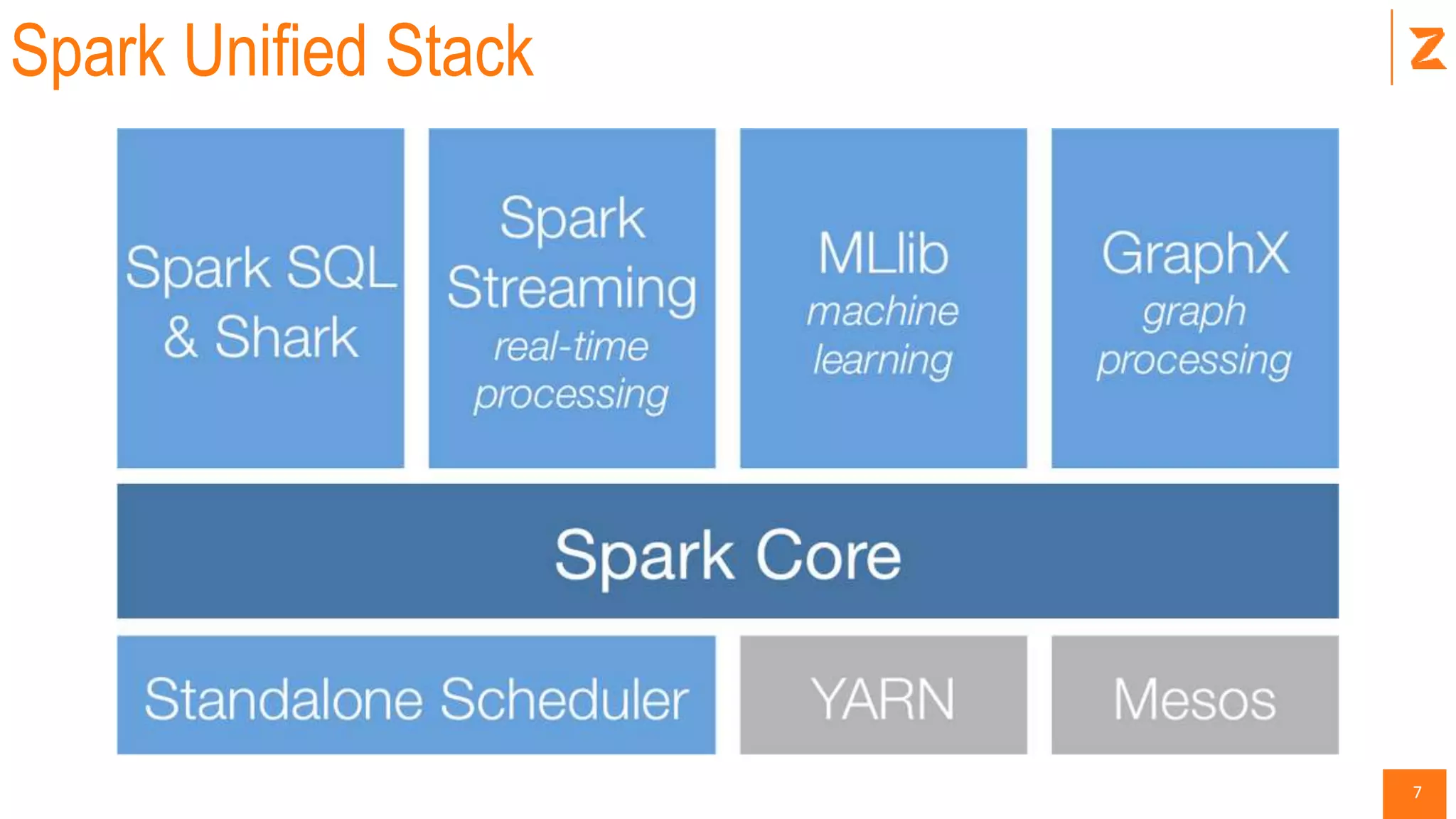
The document provides a comprehensive introduction to Apache Spark, covering its architecture, advantages over Hadoop, and different components such as Spark SQL, DataFrames, and RDDs. It explains Spark's capabilities in handling diverse workloads including batch, streaming, and interactive applications, as well as its programming in Scala. Additionally, the document outlines the Spark ecosystem, setup instructions, and examples, including how to use key functionalities like transformations and actions.