Apache Spark
• ApacheSpark is a distributed processing system used to perform big
data and machine learning tasks on large datasets. With Apache
Spark, users can run queries and machine learning workflows on
petabytes of data, which is impossible to do on your local device.
• Apache Spark is one of the most widely used analytics engines. It
performs distributed data processing and can handle petabytes of
data. Spark can work with a variety of data formats, process data at
high speeds, and support multiple use cases.
• Spark is designed to cover a wide range of workloads such as batch
applications, iterative algorithms, interactive queries and streaming.
3.
Features of ApacheSpark
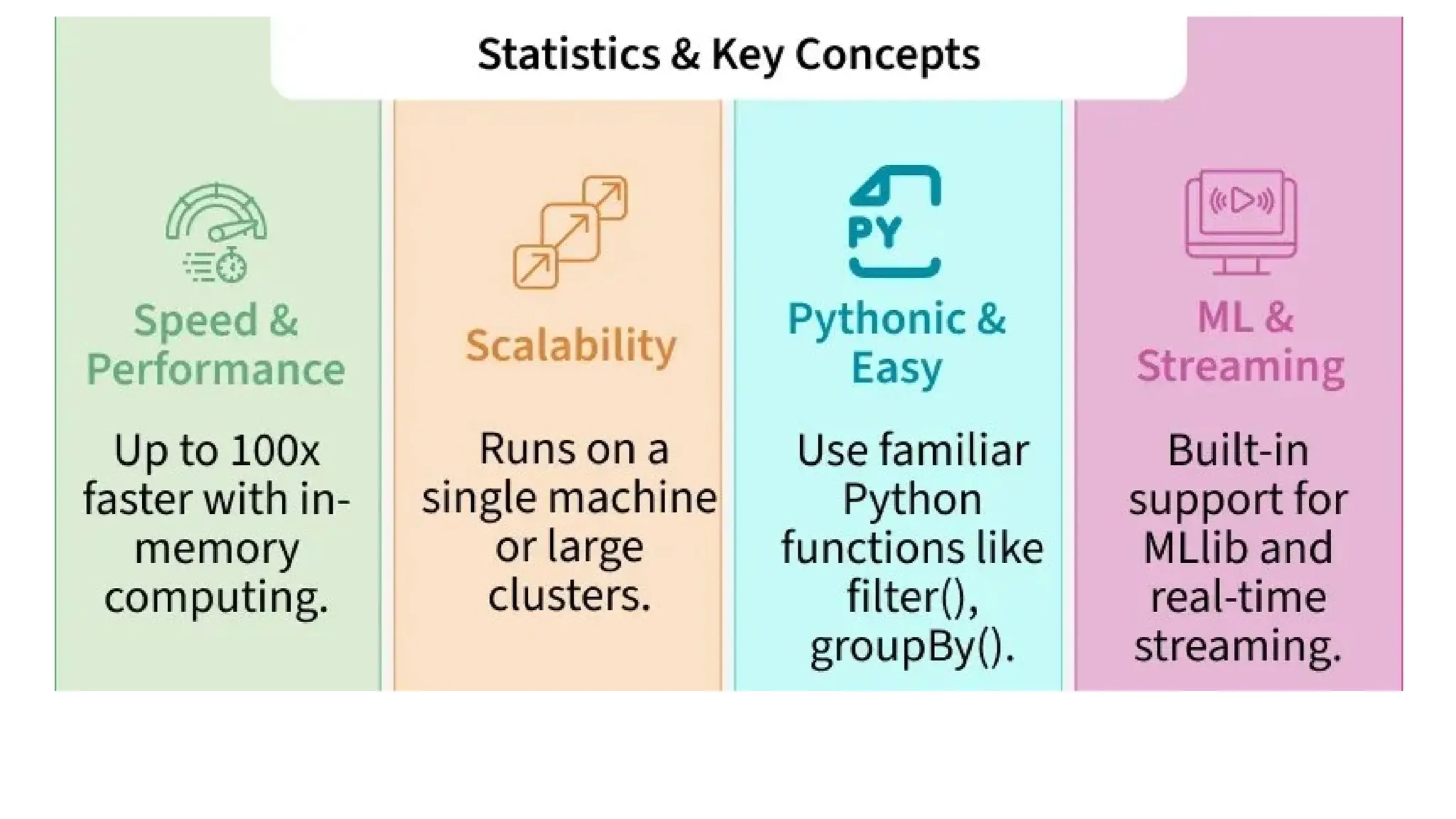
• Speed − Spark helps to run an application in Hadoop cluster, up to 100
times faster in memory, and 10 times faster when running on disk. This is
possible by reducing number of read/write operations to disk. It stores
the intermediate processing data in memory.
• Supports multiple languages − Spark provides built-in APIs in Java, Scala,
or Python. Therefore, you can write applications in different languages.
Spark comes up with 80 high-level operators for interactive querying.
• Advanced Analytics − Spark not only supports Map and reduce. It also
supports SQL queries, Streaming data, Machine learning (ML), and Graph
algorithms.
4.
Apache Spark –RDD (Resilient Distributed Datasets)
• Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable
distributed collection of objects.
• Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of
the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined
classes.
• Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through
deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant
collection of elements that can be operated on in parallel.
• There are two ways to create RDDs − parallelizing an existing collection in your driver program,
or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or
any data source offering a Hadoop Input Format.
5.
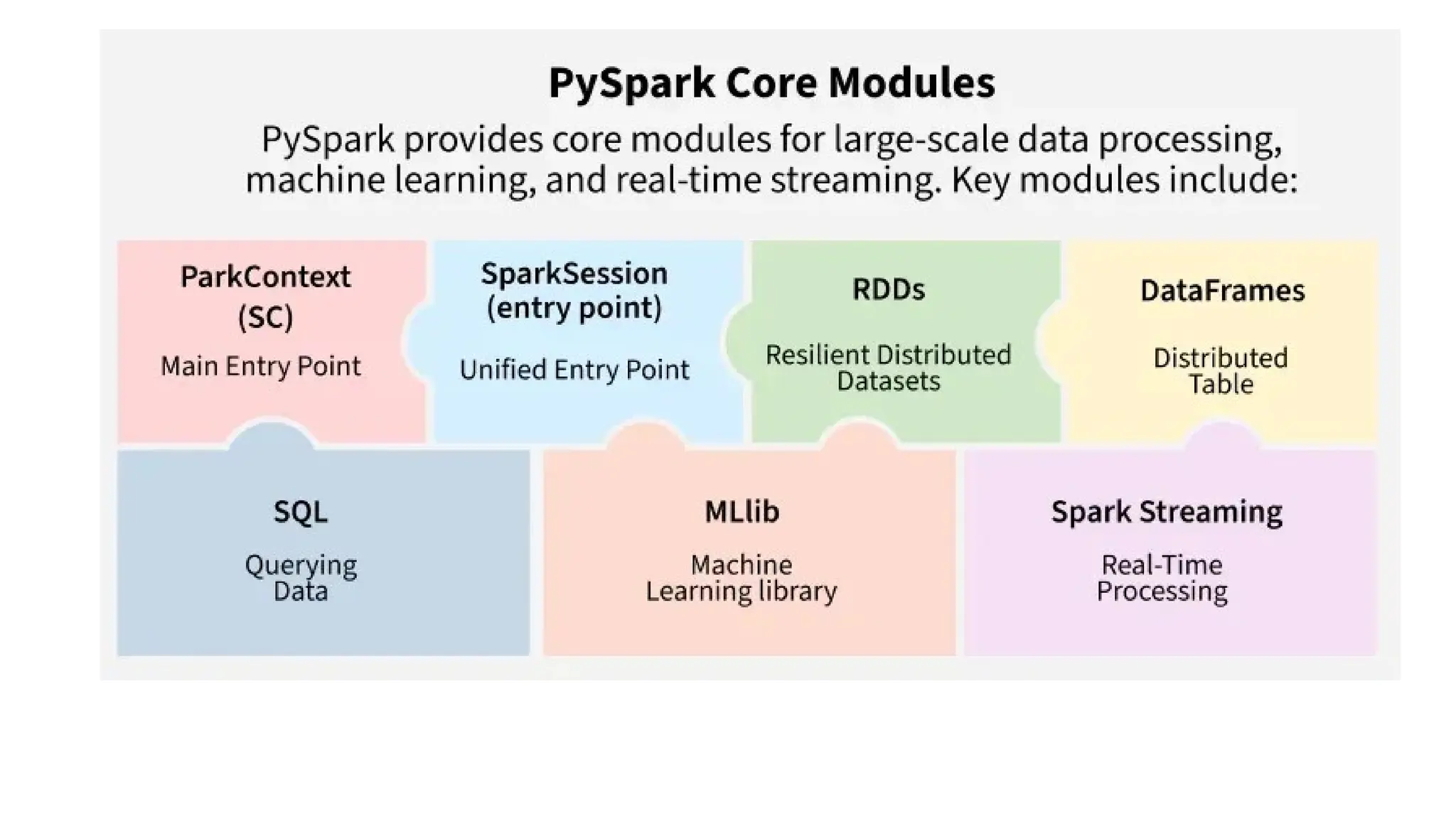
PySpark
• PySpark isthe Python API for Apache Spark, designed for big data
processing and analytics.
6.
• Distributed Computing:PySpark runs computations in parallel across
a cluster, enabling fast data processing.
• Fault Tolerance: Spark recovers lost data using lineage information in
resilient distributed datasets (RDDs).
• Lazy Evaluation: Transformations aren’t executed until an action is
called, allowing for optimization.
10.
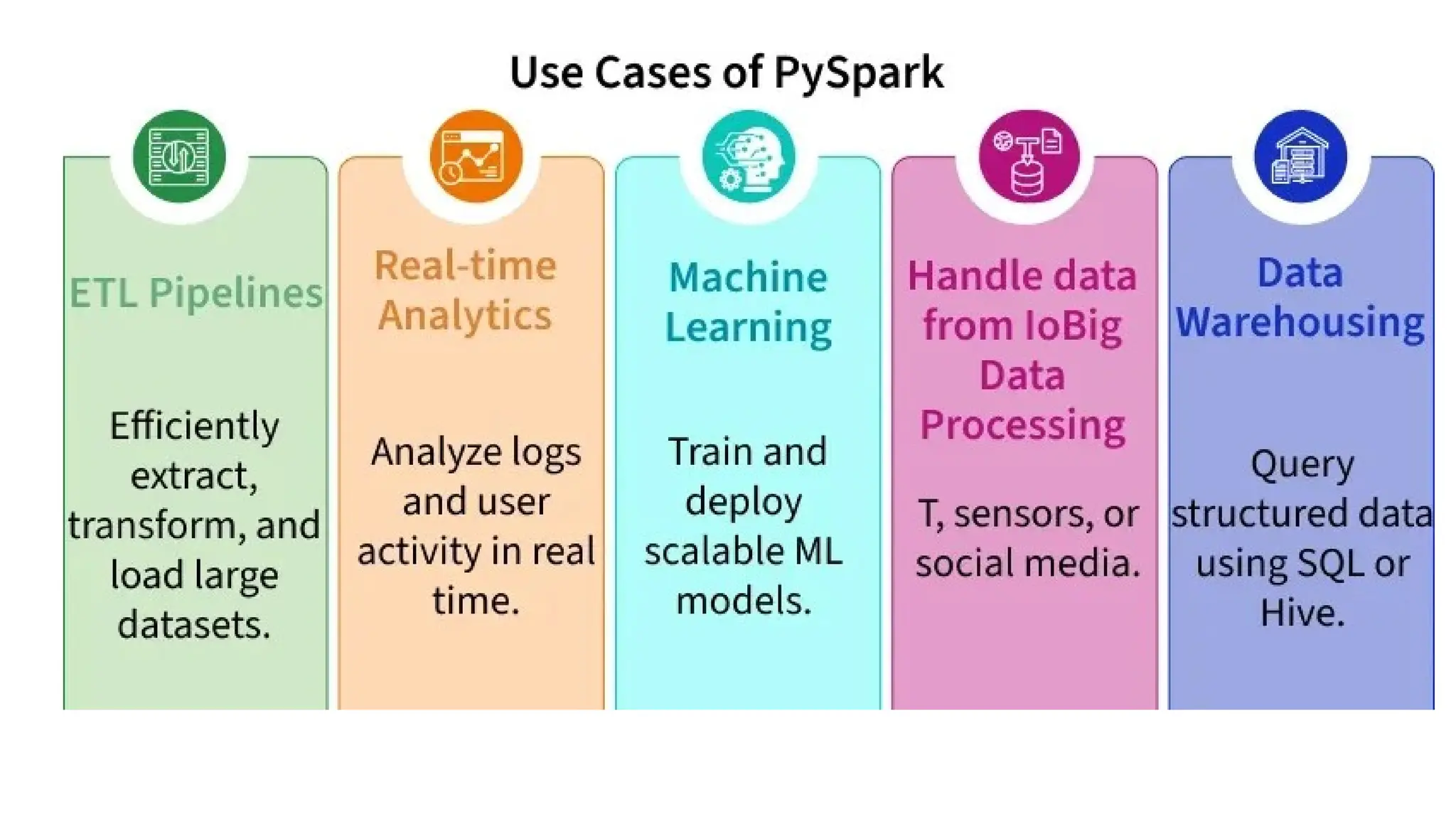
What is PySparkUsed For?
• PySpark helps programmer to use Python to process and analyze
huge datasets that can’t fit on one computer. It runs across many
machines, making big data tasks faster and easier. You can use
PySpark to:
• Perform batch and real-time processing on large datasets.
• Execute SQL queries on distributed data.
• Run scalable machine learning models.
• Stream real-time data from sources like Kafka or TCP sockets.
• Process graph data using GraphFrames.
11.
Working with PySpark
Step1: Creating a SparkSession
Step 2: Creating the DataFrame
Step 3: Exploratory data analysis
Step 4: Data pre-processing
Step 5: Building the machine learning model
12.
Step 1: Creatinga SparkSession
• A SparkSession is an entry point into all functionality in Spark, and is
required to build a dataframe in PySpark. Run the following lines of
code to initialize a SparkSession:
from pyspark.sql import SparkSession
spark = ( SparkSession.builder
.appName("Datacamp Pyspark
Tutorial") .config("spark.memory.offHeap.enabled",
"true") .config("spark.memory.offHeap.size", "10g")
.getOrCreate()
)

















![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)







































