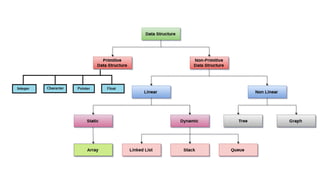
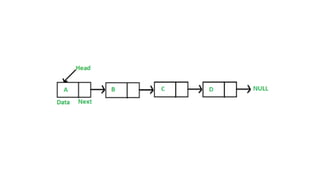
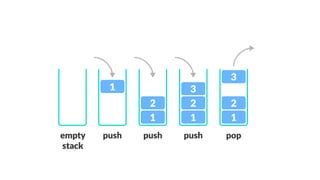
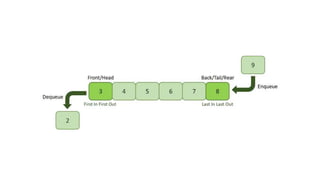
Data structures allow us to organize and store data in an efficient manner. Some common linear data structures include arrays, linked lists, stacks, and queues. Arrays use contiguous memory locations to store data while linked lists connect nodes using pointers. Stacks follow LIFO principles for insertion and deletion while queues follow FIFO. These data structures find applications in areas like recursion, expression evaluation, memory management, and more.