使用 Keras, Tensorflow 進行分散式訓練初探 (Distributed Training in Keras and Tensorflow)
1.
使用 Keras, Tensorflow進行分散式訓練初探
王建凱 JianKai Wang
2019/03/20
https://github.com/jiankaiwang
https://www.linkedin.com/in/wangjiankai/
從設計架構到實作方式,進入高效模型訓練
2.
內容與資源 AI xCloud
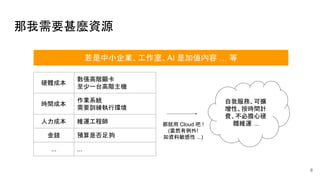
● 本份文件:
https://ppt.cc/fl8Qex
● 原始碼:
https://github.com/jiankaiwang/distributed_training
● AI、機器學習與深度學習
● 雲端、終端與 AI
● Keras 與 Tensorflow
● 架構與實作概念
Keras
Tensorflow
Deep Learning
Machine Learning
Medical
Commerce
Industry 4.0
2
3.
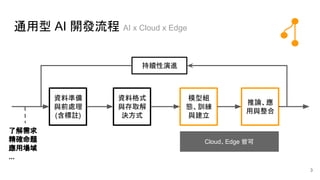
通用型 AI 開發流程AI x Cloud x Edge
資料準備
與前處理
(含標註)
資料格式
與存取解
決方式
模型組
態、訓練
與建立
推論、應
用與整合
了解需求
精確命題
應用場域
...
持續性演進
3
Cloud、Edge 皆可




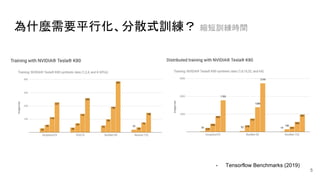
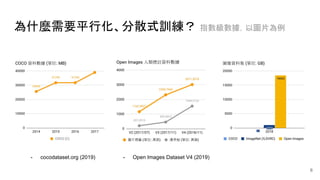
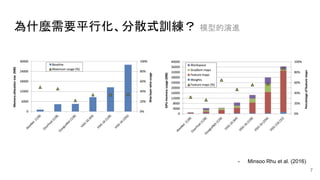






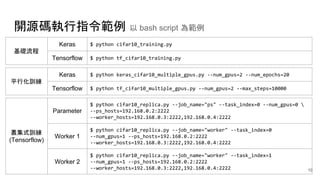
![Tensorflow 的實現方式
def main(unused_argv):
cluster = tf.train.ClusterSpec({"ps": ps_spec, "worker": worker_spec})
with tf.device(tf.train.replica_device_setter(
worker_device, ps_device="/job:ps/cpu:0", cluster=cluster)):
global_step = tf.Variable(...)
y = _inception_v3(x)
opt = tf.train.AdamOptimizer(FLAGS.learning_rate)
if FLAGS.sync_replicas:
opt = tf.train.SyncReplicasOptimizer(opt, num_workers, ...)
train_step = opt.minimize(cross_entropy, global_step)
...
sv = tf.train.Supervisor(..., init_op, local_init_op, global_step)
sess = sv.prepare_or_wait_for_session(...)
if FLAGS.sync_replicas and is_chief:
sess.run(sync_init_op)
sv.start_queue_runners(sess, [chief_queue_runner])
while True:
_, step = sess.run([train_step, global_step])
...
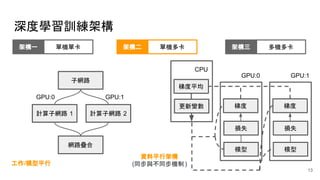
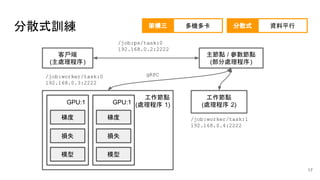
● global_step 為訓練指標
● 透過 queue 及 prefetch 操作資料
● 資料於各工作節點分別讀取
● 透過執行緒進行資料預擷取
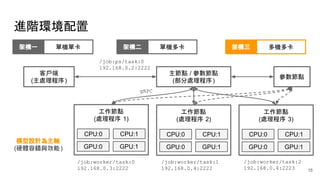
● 須清楚定義參數與工作節點
● 透過 gRPC 傳遞更新參數與梯度
● 參數伺服器建立於單 CPU 節點
● 工作節點建立於多 GPU 節點
● 參數儲存會分配於參數伺服器
● 計算操作子優先分配 GPU 節點
● 參數由第一個工作節點初始化
● session 由第一個工作節點開始
● 透過同步優化器增加容錯
設計架構
18](https://image.slidesharecdn.com/kerastensorflowdistributedtraining-190321151821/85/Keras-Tensorflow-Distributed-Training-in-Keras-and-Tensorflow-18-320.jpg)



















![[students AI workshop] Pytorch](https://cdn.slidesharecdn.com/ss_thumbnails/pytorch1-170911183243-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Python - Deep Learning] Data generator](https://cdn.slidesharecdn.com/ss_thumbnails/datageneratortopublic-180111155736-thumbnail.jpg?width=640&height=640&fit=bounds)

















