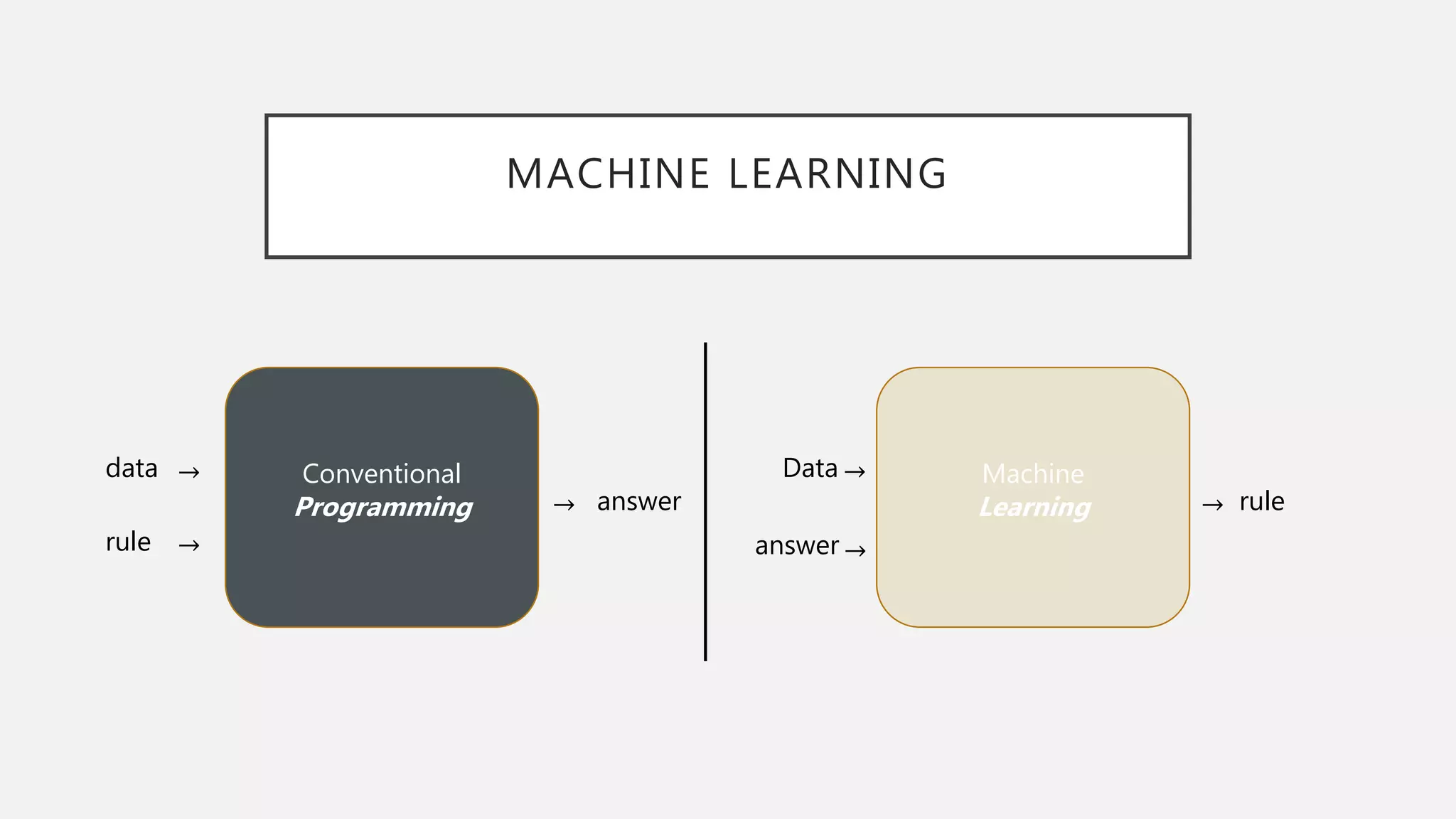
LEARN REPRESENTATION FROMDATA
(데이터에서 표현을 학습하기)
• 3 Prerequisites(Speech Recognition)
• Input Data: recorded sound files 녹음된 대화 파일
• Answer: Transcription of the input sound files 해당 대화 파일의 전사(받아 쓴)
텍스트
• Measure of performance: difference from answer and output. Feedback for
learning.
• 가설 공간을 사전에 정의하고 피드백 신호의 도움을 받아 입력 데이터에
대한 유용한 변환을 찾는것
NE
• 층(layer): 신경망의핵심구성요소 / 데이터 처리 필터
• Sequential 모델
• 2개의 layer
• Activation function: relu
• Output Activation function: softmax
8.
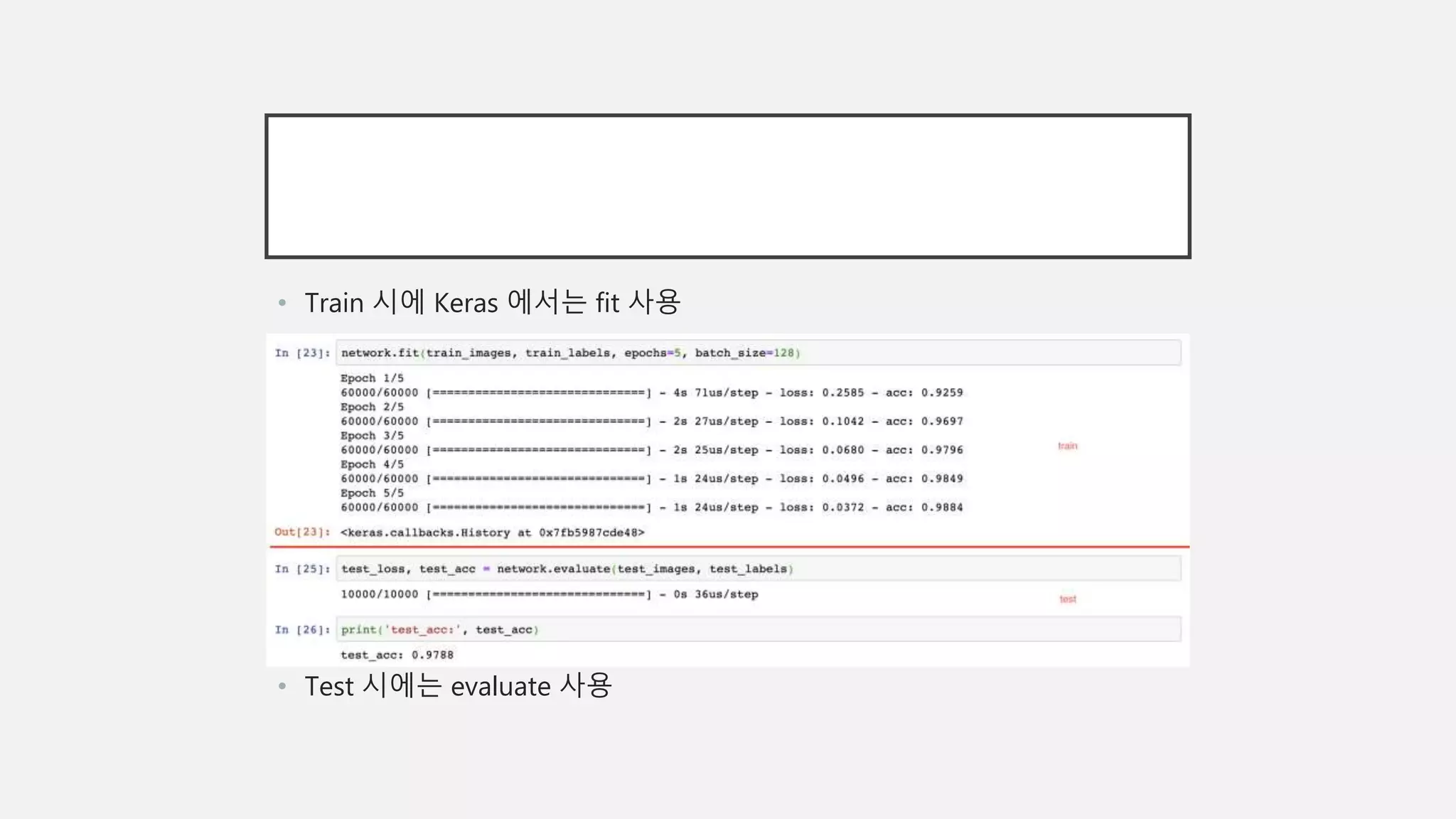
NETWORK COMPILE
• Compile단계에 포함될 3가지
• Loss function: 신경망 성능측정
• Optimizer: network update mechanism
• Training 과 Test 과정을 Monitoring 할 Measure: 정확도(정확히 분류된 이미지
의 비율) for this example!
9.
PREPROCESS
• Data preprocess
•Shape: (60000, 28, 28) => (60000, 28*28)
• Value: [0,255] uint8 => [0,1] float32
One-hot encoding ( one-dimensional labels => (n, k) n: number of data, k: number of classes)
DATA
• Tensor: 임의의차원을 가지는 행렬의 일반화된 모습
• Scalar
• 0d tensor
• Just a value
• Vector
• 1d tensor
• Array
• Ex. [1,2,3,4,5]
• Ambigous!! 5D Vector / 5D Tensor
12.
• Matrix
• 2axises
• Row(행) / Column(열)
• A = np.array([[1,2,3,4,5], [6,7,8,9,10], [0,0,0,0,0]]) / A.shape => (3,5)
• 3D tensor
• Array of Matrix
• 직육면체
13.
• Key Attribute
•Axis(축, rank): ndim
• Shape: 텐서의 각 축을 따라 얼마나 많은 차원(dimension)이 있는지 나타내는
tuple. Length
• Ex. [1,2,3,4,5] => (5,)
• Data type: 텐서에 담긴 데이터의 타입. Float32, uint8, float64
• 사전에 할당된 메모리(동적할당 X)이므로 가변길이 지원 X
BATCH
• 딥러닝 모델은한번에 모든 데이터셋을 처리하지 않고 데이터를 작은 배
치로 나누어서 학습한다
• 딥러닝에서 사용하는 모든 데이터 텐서의 첫번째 축을 샘플(sample) 축
이라고 한다 => 데이터의 개수
16.
TENSOR WITH EXAMPLES
•Vector Data: 가장 흔한 데이터 형태
• (samples, features) 형태의 2D Tensor
• Ex. 행: 데이터 개수 열: 나이, 우편번호, 소득등
• Sequence Data or 시계열 데이터
• (samples, timesteps, features) 형태의 3D Tensor
• Timestep은 진짜 시간! 또는 순서를 의미한다
• Ex. 주식 가격데이터셋(Time): 1분마다 현재 주식가격, 지난 1분동안의 최고/최저가격을
기록한다고 할때 하루의 주식 데이터셋은 (390, 3) 2D 텐서로 저장 가능. 250 일치의 주
식 데이터셋은: (250, 390, 3)
• Ex. Tweet Dataset(Sequence): 128개의 알파벳. 280개의 문자 시퀀스일때 100만개의 트
윗으로 이루어진 데이터셋은 (1000000, 280, 128) cf. 알파벳은 128 D binary vector로
one-hot encoding
17.
TENSOR WITH EXAMPLES
•Image : (samples, height, width, channels) 또는 (samples, channels,
height, width) 형태의 4D 텐서
• MNIST 데이터 셋 (배치, 높이, 너비, 채널) → (N, 28, 28, 1)
• Video : (samples, frames, height, width, channels) 또는 (samples, frames,
channels, height, width) 형태의 5D 텐서
• 60초 짜리 144$times$256 유튜브 비디오 클립을 초당 4프레임으로 샘플링하면
240 프레임이며, 이런 비디오 클립을 4개 가진 배치는 (4, 240, 144, 256, 3) 텐서
에 저장된다
ELEMENT-WISE OPERATION
• 원소별연산(element-wise operation): 텐서에 있는 각 원소에 독립적으로
적용되는 연산
• Numpy: BLAS 사용(C/fortran) So fast!!
20.
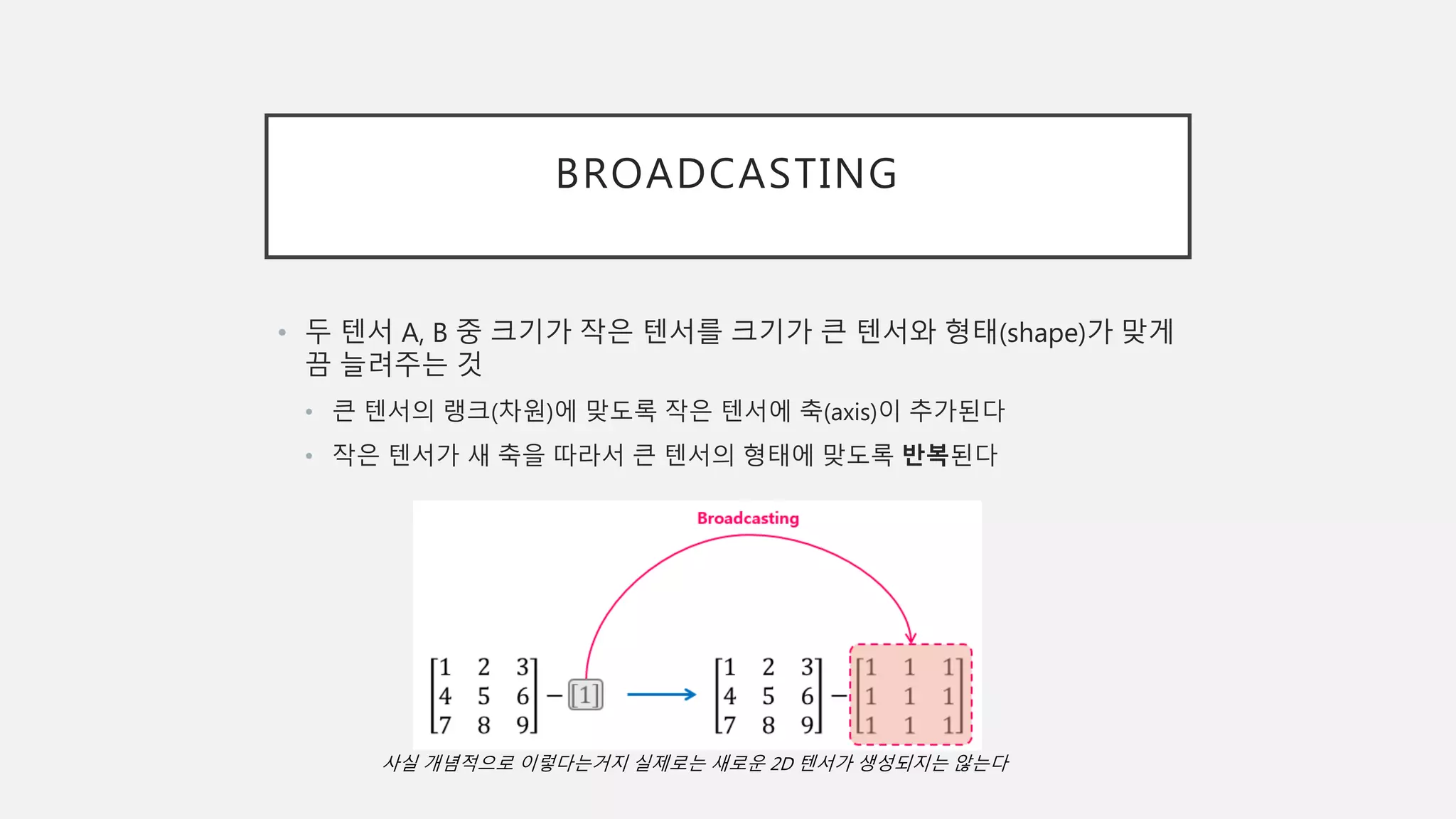
BROADCASTING
• 두 텐서A, B 중 크기가 작은 텐서를 크기가 큰 텐서와 형태(shape)가 맞게
끔 늘려주는 것
• 큰 텐서의 랭크(차원)에 맞도록 작은 텐서에 축(axis)이 추가된다
• 작은 텐서가 새 축을 따라서 큰 텐서의 형태에 맞도록 반복된다
사실 개념적으로 이렇다는거지 실제로는 새로운 2D 텐서가 생성되지는 않는다
21.
TENSOR DOT
• Tensorflow에서는matmul 라고 부르지만 keras에서는 dot이라고 부른다
(but also numpy)
• 가장 유용한 텐서 연산 (also called as “tensor product”)
• 원소별 연산과는 다르게 입력 텐서의 원소들을 결합시킨다
• 두 벡터의 dot은 scalar 값이다 => 원소가 같은 벡터끼리 점곱가능
• Matrix * vector => column 개수와 vector의 원소개수가 같아야 함
• 즉, matrix.shape[1] == vector.shape[0]
• Return 값은 matrix.shape[1] 크기의 벡터
22.
TENSOR DOT
• Matrix* Matrix => A의 column 개수와 B
의 row 개수가 같아야함
• 즉, A.shape[1] == B.shape[0]
• Return 값은 (A.shape[0], B.shape[1])의
Matrix
• (a, b) ∙ (b, c) → (a, c)
• (a, b, c, d) ∙ (d,) → (a, b, c)
• (a, b, c, d) ∙ (d, e) → (a, b, c, e)
23.
RESHAPING
• 특정 형태에맞게 행과 열을 재배열
• NumPy의 .reshape()을 이용해 형태를 변환
• 가장 많이 사용: 전치(Transposition) : 행과 열 바꾸기
24.
텐서 연산의 기하학적해석
• 아핀변환(affine transformation) 회전, 스케일링(scaling) 등 기본적인 기
하학적 연산을 표현
• Affine transformation: 점, 직선, 평면을 보존하는 아핀 공간으로의 변환
• 거리의 비율과 직선의 평행을 유지하는 이동, 스케일링, 회전
• Affine Space : 아핀공간은 벡터공간을 평행이동한 것
• 따라서, Fully-Connected layer를 Affine layer라고도 함
#6 머신러닝에서 카테고리 분류 문제를 다를때 분류해야할 카테고리를 “클래스” 라고 부르고, 각 데이터는 sample이라고 부른다. 또한 각 sample의 클래스는 label이라고 부른다.
#12 이 벡터의 차원: 1 / ndim: 1. 원소 개수: 5개 -> 5차원 벡터라고 부르지만 5D 벡터와 5D 텐서를 혼동하면 안된다! 차원은 특정 축(axis)를 따라 놓인 원소의 개수 또는 텐서의 축 개수(5 axis) 를 의미하므로 혼동할 수 있다. 후자의 경우에는 rank 5 tensor라고 부르기도 한다








![PREPROCESS
• Data preprocess
• Shape: (60000, 28, 28) => (60000, 28*28)
• Value: [0,255] uint8 => [0,1] float32
One-hot encoding ( one-dimensional labels => (n, k) n: number of data, k: number of classes)](https://image.slidesharecdn.com/keras-190309142615/75/Keras-9-2048.jpg)
![DATA
• Tensor: 임의의 차원을 가지는 행렬의 일반화된 모습
• Scalar
• 0d tensor
• Just a value
• Vector
• 1d tensor
• Array
• Ex. [1,2,3,4,5]
• Ambigous!! 5D Vector / 5D Tensor](https://image.slidesharecdn.com/keras-190309142615/75/Keras-11-2048.jpg)
![• Matrix
• 2 axises
• Row(행) / Column(열)
• A = np.array([[1,2,3,4,5], [6,7,8,9,10], [0,0,0,0,0]]) / A.shape => (3,5)
• 3D tensor
• Array of Matrix
• 직육면체](https://image.slidesharecdn.com/keras-190309142615/75/Keras-12-2048.jpg)
![• Key Attribute
• Axis(축, rank): ndim
• Shape: 텐서의 각 축을 따라 얼마나 많은 차원(dimension)이 있는지 나타내는
tuple. Length
• Ex. [1,2,3,4,5] => (5,)
• Data type: 텐서에 담긴 데이터의 타입. Float32, uint8, float64
• 사전에 할당된 메모리(동적할당 X)이므로 가변길이 지원 X](https://image.slidesharecdn.com/keras-190309142615/75/Keras-13-2048.jpg)






![TENSOR DOT
• Tensorflow에서는 matmul 라고 부르지만 keras에서는 dot이라고 부른다
(but also numpy)
• 가장 유용한 텐서 연산 (also called as “tensor product”)
• 원소별 연산과는 다르게 입력 텐서의 원소들을 결합시킨다
• 두 벡터의 dot은 scalar 값이다 => 원소가 같은 벡터끼리 점곱가능
• Matrix * vector => column 개수와 vector의 원소개수가 같아야 함
• 즉, matrix.shape[1] == vector.shape[0]
• Return 값은 matrix.shape[1] 크기의 벡터](https://image.slidesharecdn.com/keras-190309142615/75/Keras-21-2048.jpg)
![TENSOR DOT
• Matrix * Matrix => A의 column 개수와 B
의 row 개수가 같아야함
• 즉, A.shape[1] == B.shape[0]
• Return 값은 (A.shape[0], B.shape[1])의
Matrix
• (a, b) ∙ (b, c) → (a, c)
• (a, b, c, d) ∙ (d,) → (a, b, c)
• (a, b, c, d) ∙ (d, e) → (a, b, c, e)](https://image.slidesharecdn.com/keras-190309142615/75/Keras-22-2048.jpg)



![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 6장 결정 트리](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-181010080045-thumbnail.jpg?width=640&height=640&fit=bounds)





![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)












![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)























