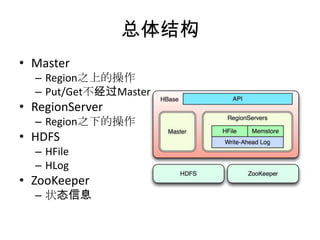
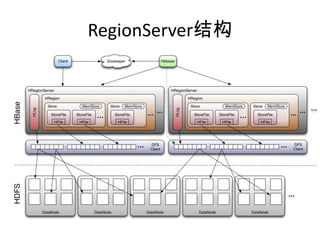
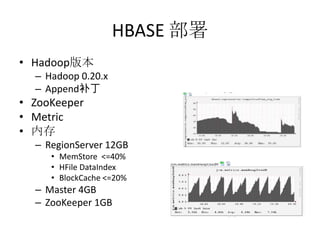
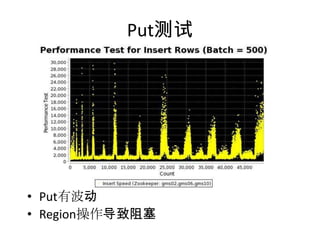
HBase 是一个基于 HDFS 的 NoSQL 数据库,支持实时的随机读写和大规模的线性扩展。文档涵盖了 HBase 的基本概念、架构设计、操作方法、使用技巧和性能优化等内容。此外,具体的性能参数和管理运维建议也在文档中详细说明。