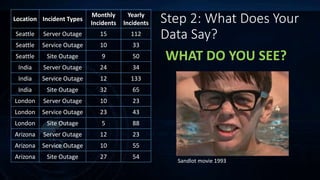
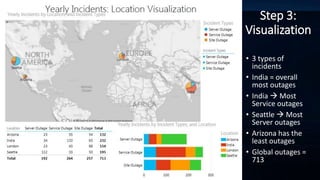
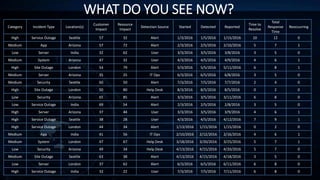
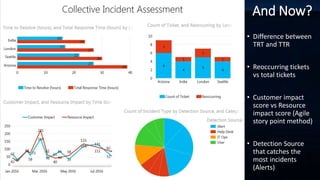
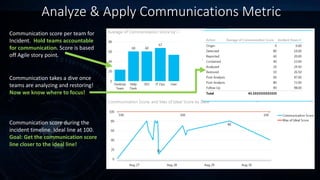
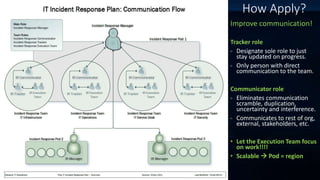
The document outlines incident response management (IRM) processes at a $10 billion non-profit organization, focusing on metrics, data analysis, and visualization techniques. Key metrics include incident response volume, time to detect, and time to resolve incidents, with visual data revealing patterns in outages by location. The findings emphasize the need for improved communication among teams during incidents to enhance response effectiveness and track accountability.