데이터 분석을 위한파이썬
(Python for Data Analysis)
2018. 7.
강병호수석
2.
I. 소개 및환경설정
II. 파이썬 언어
III. NumPy
IV. Matplotlib
Contents
3.
작성자 소개
학력
•1993년 숭실대학교 인공지능학과 입학
• 2000년 숭실대학교 컴퓨터학부 졸업
경력
• 2000년 SKC&C (현, SK주식회사) 입사 ~
• 국내 프로젝트 수행
• 2000년 ~ 2003년 SK Telecom Web Development
• 2010년 ~ 2014년 SK Telecom Web Development
• 2017년 ~ 2018년 인공지능 프로젝트
• 해외 프로젝트 수행
• 2003년 ~ 2004년 베트남 S Telecom 영업시스템
• 2005년 ~ 2009년 미국 Virgin Mobile USA 영업시스템
• 2009년 ~ 2010년 미국 Union Back 모바일 프로젝트
• 2015년 ~ 2016년 중국 SKC&C 중국법인 역량개발 총괄
기타
• 회사 사내 강사 (2012년~)
• 자바, 스프링, 웹 개발, 인공지능 강의 수행
• 국가 자격증 문제 출제 위원 (Pilot, 2014년)
• 한국소프트웨어기술협회(KOSTA) SW개발자 L4 자격
강병호 수석
medit74@sk.com
데이터 분석을 위한파이썬
Python은 간단하고 배우기 쉬운 오픈 소스 프로그래밍 언어
Python이란?
• Python은 1990년 귀도 반 로섬(Guido Van Rossum)이 개발한 Interpreter 언어이다. 즉 컴파일 과정이 없다.
• 사전적 의미는 고대 신화에 나오는 파르나소스 산의 동굴에 살던 큰 뱀을 의미
• 교육 목적 뿐만 아니라 실무에서도 많이 활용.
• http://www.python.org
Python의 특징
• 영어와 유사한 문법으로 프로그램을 작성하는 인간다운 언어
• 문법이 쉬워 빠르게 배울 수 있다.
• 코드는 읽기 쉽고 간결하면서도 성능도 뛰어나다.
• 개발 속도가 매우 빠르다.
“Life is too short, You need python.”
Python 버전
• 현재의 Python은 2.x와 3.x 두 가지 버전이 공존.
• 위 두 가지는 서로 호환되지 않음.
소개 및 환경설정
6.
데이터 분석을 위한파이썬
Python의 주요 용도는 Web 개발 및 Data Science이다.
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
소개 및 환경설정
7.
데이터 분석을 위한파이썬
Python 3가 Python 2보다 더 많이 사용된다.
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
• 2016년에는 Python 2 점유율 60%
• 2020년에는 Python 2 유지보수 중단
2017년 Survey
소개 및 환경설정
8.
필수 파이썬 라이브러리
과학계산용파이썬 필수 라이브러리
Library Description Description
NumPy http://www.numpy.org/
과학 계산용 라이브러리.
빠르고 효율적인 다차원 배열 객체 (ndarray)
데이터 분석에서는 알고리즘에 사용할 데이터 컨테이너 역할 수행
Numpy 배열은 파이썬 기본 자료 구조보다 효율적으로 데이터를 저장 및 처리
pandas https://pandas.pydata.org/
구조화된 데이터를 빠르고 쉽게 가공할 수 있는 라이브러러.
DataFrame 객체는 2차원 표 또는 행과 열을 나타내는 자료 구조
Matplotlib https://matplotlib.org/ 데이터의 시각화 라이브러리
SciPy https://www.scipy.org/
과학계산 컴퓨터 영역의 기본적인 작업을 위한 라이브러리
NumPy, pandas, Matplotlib와 함께 동작
• NumPy와 SciPy를 함께 사용하면 MATLIB을 완벽하게 대체할 수 있다.
소개 및 환경설정
딥러닝 구현 시데이터 시각화를 위해 그래프를 그려주는 matplotlib를 사용한다.
matplotlib 라이브러리 import
그래프 그리기
이미지 표시하기
import matplotlib.pyplot as plt
from matplotlib.image import imread
# 데이터준비
x = np.arange(0, 6, 0.1) #0에서 6까지 0.1 간격으로 배열생성
y1 = np.sin(x)
y2 = np.cos(x)
# 그래프 그리기
plt.plot(x, y1, label="sin")
plt.plot(x, y2, linestyle="--", label="cos")
plt.xlabel("x")
plt.ylabel("y")
plt.title("sin & cos")
plt.legend()
plt.show()
img = imread("../resources/Scream.jpg")
plt.imshow(img)
plt.show()
필수 파이썬 라이브러리 소개 및 환경설정
11.
Anaconda는 데이터 분석에중점을 둔 배포판
환경설정
Anaconda란?
• Python 기반의 Open Data Science Platform
• Python 및 Python Library등을 하나로 정리해 둔 배포판.
• NumPy와 Matplotlib을 포함해 데이터 분석이 유용한 라이브러리
가 포함.
• https://www.anaconda.com/distribution/
Anaconda Package 주요 List
Name Summary
djanggo 빠른 웹 개발을 위한 프레임워크
flask Micro Web Framework
jupyter Python 개발 도구
matplotlib 그래프를 그려주는 라이브러리
numpy 수치 계산용 라이브러리
pandas 강력한 데이터 구조 분석 도구
python Python 프로그래밍 언어
scipy Python 과학 라이브러리
소개 및 환경설정
12.
개발환경은 간단한 편집기부터통합개발환경(IDE) 까지 다양하다.
환경설정
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
소개 및 환경설정
13.
Eclipse에서 Python 개발환경을 구축하기 위한 Plug-in
PyDev란?
• Eclipse에서 실행되는 Python 개발환경
• http://www.pydev.org/
Eclipse PyDev 설치
• Eclipse Marketplace에서 PyDev로 검색 후 설치
• Eclipse Preferences > PyDev > Interpreters > Python
Interpreters 에서 Quick Auto-Config를 통한 Python 인터프
리터 라이브러리 연결
Eclipse 일반설정
• Eclipse Preferences > General > Workspace에서 Text file
encoding을 UTF-8로 설정
• Eclipse Preferences > General > Appearance > Colors and
Fonts에서 Text Font를 Consolas 9 사이즈로 설정
환경설정 소개 및 환경설정
14.
실습
#1 - Anaconda설치하기
Anaconda 배포판 설치
• https://www.anaconda.com/distribution/ 에서 사용하고 있는 OS에 맞추어 Anaconda 다운로드 후 설치
설치 후 버전 확인
• 윈도우 명령 프롬프트 또는 Anaconda Prompt 실행하여 확인
C:>python --version
Python 3.6.5 :: Anaconda, Inc.
소개 및 환경설정
15.
#2 - PyDev설치하기
사전조건
• Java Platform (JDK) 8 이상 설치
• Eclipse 설치 (https://www.eclipse.org/downloads/)
PyDev 설치
• Eclipse Marketplace에서 PyDev로 검색 후 설치
• Eclipse Preferences > PyDev > Interpreters > Python Interpreters 에서 Quick Auto-Config를 통한 Python
인터프리터 라이브러리 연결
Eclipse 일반설정
• Eclipse Preferences > General > Workspace에서 Text file encoding을 UTF-8로 설정
• Eclipse Preferences > General > Appearance > Colors and Fonts에서 Text Font를 Consolas 9 사이즈로 설정
실습 소개 및 환경설정
16.
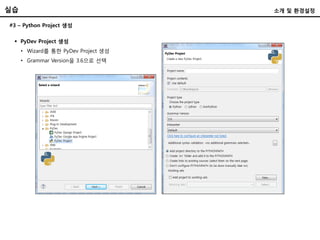
#3 – PythonProject 생성
PyDev Project 생성
• Wizard를 통한 PyDev Project 생성
• Grammar Version을 3.6으로 선택
실습 소개 및 환경설정
파이썬 기초
파이썬은인터프리터 언어이다. 즉 컴파일 없이 한 번에 하나의 명령어만 실행한다.
파이썬 언어
C:UsersAdministrator>python
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("hello")
hello
파이썬은 다른 언어와 달리 중괄호{} 대신 들여쓰기를 사용해서 코드를 구조화 한다.
while count <= 10 :
total += count
count += 1
print(count) # 11
print(total)
def bears():
return ("카스", "칭다오", "아사히")
>>> a = 3
>>> type(a)
<class 'int'>
모든 것은 객체이다.
• 모든 자료구조, 함수, 클래스 등 모두 객체로 간주한다.
• 객체는 속성(Attribute)과 함수(Method)를 가진다.
19.
자료형
변수는 값을 저장하며,자료형(Data Type)에 기반하여 메모리를 할당한다.
변수에 값 할당 하기
• 파이썬 변수는 명시적 선언을 통해 메모리를 할당할 필요가 없다.
• = : 변수 선언에 사용
파이썬 언어
counter = 100 # An integer assignment
miles = 1000.0 # A floating point
name = "John" # A string
print(counter)
print(miles)
print(name)
20.
자료형
Python 숫자형에는 int,float, complex type이 있다.
숫자형 종류
파이썬 언어
a = 123 # int
a = 0o12 # int
a = 0xFF # int
a = 1.23 # float
a = 3.4e10 # float
a = complex(1,2j) # complex
print(7/4) # 1.75
print(7//4) # 1
print(7%4) # 3
Type 사용 예
int 정수형
10진수 123, -345, 0,
8진수 0o34, 0o25,
16진수 0x2A, 0xFF
float 실수형 123.45, -1234.5, 3.4e10
complex 복소수형 1+2j
숫자형 연산자
연산 결과
x + y 합
x - y 차
x * y 곱
x / y 나눗셈
x // y 나눗셈의 몫
x % y 나눗셈의 나머지
x ** y 거듭제곱
-x 음의 x
21.
자료형
Python 문자열을 만드는방법은 4가지가 있다.
문자열 생성
파이썬 언어
문자열 포맷팅
방법 예
큰따옴표로 양쪽 둘러싸기 '"My name is Tiger" he said'
작은따옴표로 양쪽 둘러싸기 "Python's favorite food is perl"
큰따옴표 3개를 연속으로 써서 양쪽 둘러싸기 """Life is too short, You need python"""
작은따옴표 3개를 연속으로 써서 양쪽 둘러싸기 '''Life is too short, You need python'''
방법 예
숫자 대입 "I eat %d apples." % 3
문자열 대입 "I eat %s apples." % "five"
2개 이상 값 넣기 "I ate %d apples. so I was sick for %s days." % (10, "three")
print('Hello')
print("What's your name")
print('"My name is Tiger" he said')
print("Life is too short.nYou need python")
print("I've been to %d countries." % 15)
print("%s is the best country in %d" % ("Swiss", 15))
22.
자료형
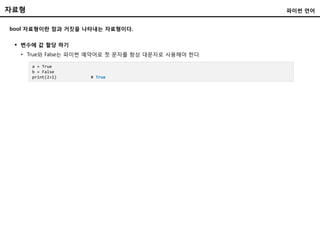
bool 자료형이란 참과거짓을 나타내는 자료형이다.
변수에 값 할당 하기
• True와 False는 파이썬 예약어로 첫 문자를 항상 대문자로 사용해야 한다.
파이썬 언어
a = True
b = False
print(2>1) # True
23.
자료형
리스트는 데이터의 모음으로데이터 항목을 추가, 삭제, 변경을 할 수 있다.
리스트 생성
• 리스트명 = [요소1, 요소2, 요소3, ...]
파이썬 언어
odd = [1, 3, 5, 7, 9]
리스트 인덱싱과 슬라이싱
odd = [1, 3, 5, 7, 9]
print(odd[0]) # 1
print(odd[-1]) # 9
print(odd[1:3]) # [3,5]
print(odd[:3]) # [1,3,5]
print(odd[3:]) # [7,9]
리스트 관련 함수
mylist = ['my','python','list']
print(mylist, type(list)) # ['my', 'python', 'list'] <class 'type'>
mylist.append("added")
print(mylist) # ['my', 'python', 'list', 'added']
mylist.remove('python')
print(mylist) # ['my', 'list', 'added']
mylist.sort()
print(mylist) # ['added', 'list', 'my']
• 기타 관련 함수 매우 많음.
24.
자료형
튜플(Tuple)은 리스트와 비슷하지만,그 값을 바꿀 수 없다.
Tuple 생성
• 튜플명 = (요소1, 요소2, 요소3, ...)
파이썬 언어
t1 = (1, 2, 'a', 'b')
Tuple 인덱싱과 슬라이싱, 더하기와 반복하기
t1 = (1, 2, 'a', 'b')
t2 = (3, 4)
print(t1[0]) # 1
print(t1[-2:]) # ('a', 'b')
print(t1+t2) # (1, 2, 'a', 'b', 3, 4)
print(t2*2) # (3, 4, 3, 4)
• 더하기와 반복하기는 List에도 같이 적용된다.
25.
자료형
딕셔너리(Dictionary)는 키-값의 쌍을리스트 형태로 가진다.
Dictionary 생성
• 딕셔너리명 = {Key1:Value1, Key2:Value2, Key3:Value3, ...}
파이썬 언어
dict1 = {'name': '강병호', 'co': 'SK', 'birth': '1128'}
Dictionary의 Value 얻기 및 딕셔너리 쌍 추가, 삭제
dict1 = {'name': '강병호', 'co': 'SK', 'birth': '1128'}
print(dict1.get('name')) # 강병호
dict1['addr'] = '성남시'
print(dict1) # {'name': '강병호', 'co': 'SK', 'birth': '1128', 'addr': '성남시'}
del dict1['birth']
print(dict1) # {'name': '강병호', 'co': 'SK', 'addr': '성남시'}
dict1['co'] = 'SK주식회사'
print(dict1) # {'name': '강병호', 'co': 'SK주식회사', 'addr': '성남시'}
제어문
조건문 : if,elif, else
조건문
• 다른 프로그래밍 언어와 달리, Python 조건문 다음에는 괄호{ } 대신 콜론 (:)이 붙는다.
• 조건을 판단하기 위해 사용하는 연산자로 and, or, not이 있다.
파이썬 언어
import time
localtime = time.localtime(time.time())
print(localtime) # 현재 날짜 및 시간 (time.struct_time 객체를 리턴)
localhour = localtime.tm_hour
print(localhour) # 현재 시간
greeting = ""
if localhour >= 6 and localhour < 11:
greeting = "Good Morning"
elif localhour >= 11 and localhour < 17:
greeting = "Good Afternoon"
elif localhour >= 17 and localhour < 22:
greeting = "Good Evening"
else:
greeting = "Hello"
print(greeting)
28.
제어문
반복문 : while
while문
• 조건이 True 인 동안 while 문 아래에 속하는 문장들이 반복해서 수행된다.
• break나 continue를 이용하에 제어할 수 있다.
파이썬 언어
total = 0
count = 1
while count <= 10 :
total += count
count += 1
print(count) # 11
print(total) # 1에서 10까지의 합 : 55
total = 0
count = 1
while count <= 10 :
total += count
if total > 10 :
break
count += 1
print(count) # 5
print(total) # total이 10이 넘어가 첫 번째 수: 15
total = 0
count = 0
while count <= 10 :
count += 1
if count % 2 == 1 :
continue
total += count
print(count) # 11
print(total) # 1에서 10까지 짝수의 합 : 30
29.
제어문
반복문 : for
for문
파이썬 언어
for 변수 in 리스트(또는 튜플, 문자열):
수행할 문장1
수행할 문장2
...
list1 = ['apple','banana','mango']
for item in list1:
print(item) # apple, banana, mango
list2 = [(1,2),(3,4),(5,6)]
for (a, b) in list2:
print(a + b) # 3, 7, 11
total = 0
for idx in range(1,5):
total += idx
print(total) # 1에서 4까지의 합 : 10
for idx in range(len(list1)):
print('과일 %d번은 %s입니다.' % (idx, list1[idx])) # 과일 0번은 apple입니다...
for문은 range 함수와 같이 사용되는 경우가 많다. while문
• range(10)은 0부터 10 미만의 숫자를 포함하는 range 객체를 만들어 준다.
• range(1, 11)은 숫자 1부터 10까지(1 이상 11 미만)의 숫자를 데이터로 갖는 객체이다
30.
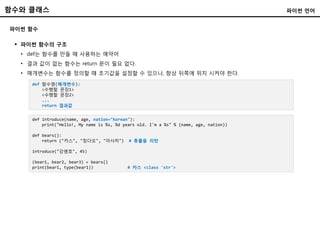
함수와 클래스
파이썬 함수
파이썬언어
def 함수명(매개변수):
<수행할 문장1>
<수행할 문장2>
...
return 결과값
파이썬 함수의 구조
• def는 함수를 만들 때 사용하는 예약어
• 결과 값이 없는 함수는 return 문이 필요 없다.
• 매개변수는 함수를 정의할 때 초기값을 설정할 수 있으나, 항상 뒤쪽에 위치 시켜야 한다.
def introduce(name, age, nation="korean"):
print("Hello!, My name is %s, %d years old. I'm a %s" % (name, age, nation))
def bears():
return ("카스", "칭다오", "아사히") # 튜플을 리턴
introduce("강병호", 45)
(bear1, bear2, bear3) = bears()
print(bear1, type(bear1)) # 카스 <class 'str'>
31.
함수와 클래스
Lambda 함수
파이썬언어
lambda 매개변수1, 매개변수2, ... : 매개변수를 이용한 표현식
lambda 구조
• lambda 함수는 보통 함수를 한 줄로 간결하게 만들 때 사용한다.
myfunc = lambda a, b: 3*a+2*b
print(myfunc(1,2)) # 7
funclist = [lambda a,b:a+b, lambda a,b:a-b, lambda a,b:a*b, lambda a,b:a/b]
for myfunc in funclist:
print(myfunc(3,2)) # 5, 1, 6, 1.5
32.
함수와 클래스
내장 함수
파이썬언어
내장함수는 별도의 설정 없이 바로 사용할 수 있는 함수이다.
print(abs(-1.2)) # 절대값 : 1.2
print(bool(1)) # bool 값 : True
print(chr(97)) # 아스키코드값에 해당되는 문자 : a
print(dict(one=1, two=2, three=3)) # 딕셔너리 객체 생성 : {'one': 1, 'two': 2, 'three': 3}
print(float("3.14")) # float형 객체생성 : 3.14
print(int('100')) # int형 객체생성 : 100
print(len('python')) # 입력값의 길이 : 6
print(list('python')) # 리스트 객체 생성 : ['p', 'y', 't', 'h', 'o', 'n']
print(max([1,2,3])) # 최대값 : 3
print(min([1,2,3])) # 최소값 : 1
print(pow(2,3)) # 거듭제곱 : 8
print(list(range(0,50,10))) # 0부터 49까지 10씩 증가하면서 리스트 생성 : [0, 10, 20, 30, 40]
print(round(1.2345, 2)) # 소수점 둘째자리에서 반올림 : 1.23
print(sorted([3,1,2])) # 입력값을 정렬 후 결과를 리스트로 리턴 : [1, 2, 3]
print(str(3.14)) # 문자열객체로 반환 : 3.14
print(sum([1,2,3])) # 합계 : 6
print(tuple('python')) # 튜플객체 생성 : ('p', 'y', 't', 'h', 'o', 'n')
print(type("python")) # 객체 타입을 반환 : <class 'str'>
문자열 내장함수
a = "I love you"
print(a.count('o')) # 문자갯수세기 : 2
print(a.replace("you", "her")) # 문자열 치환 : I love her
print(a.upper()) # 대문자 변환 : I LOVE YOU
33.
함수와 클래스
클래스와 객체
파이썬언어
클래스 선언과 인스턴스
• 클래스는 class 키워드를 이용해 선언하고 초기화 메서드를 호출하여 객체를 생성한다.
• 파이썬 메서드명으로 __init__ 을 사용하면 이 메서드는 생성자가 된다
• 파이썬 클래스 메소드의 첫번째 파라미터 명은 관례적으로 self라는 이름을 사용한다.
• self를 이용해서 객체 변수(Attribute)를 만들며, self는 외부에서 함수 호출 시 전달하지 않는다.
class Calculator:
def __init__(self):
self.result = 0
def add(self, num):
self.result += num
return self.result
def subtract(self, num):
self.result -= num
return self.result
cal1 = Calculator()
print(cal1.add(3)) # 3
print(cal1.add(4)) # 7
print(cal1.subtract(2)) # 5
[From] https://wikidocs.net/images/page/12392/setdata.png
34.
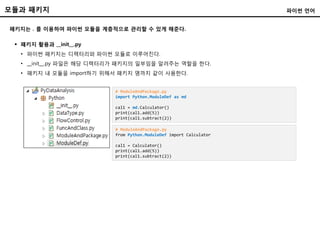
모듈과 패키지
모듈은 함수나변수 또는 클래스들을 모아 놓은 파일이다.
파이썬 언어
모듈 불러오기
• import는 현재 디렉터리에 있는 파일이나 파이썬 라이브러리가 저장된 디렉터리에 있는 모듈을 불러올 수 있다.
• from ~ import ~를 이용하면 모듈이름을 붙이지 않고 바로 해당 모듈의 함수를 쓸 수 있다.
# ModuleDef.py
class Calculator:
def __init__(self):
self.result = 0
def add(self, num):
self.result += num
return self.result
def subtract(self, num):
self.result -= num
return self.result
if __name__ == "__main__":
print("직접 이 파일을 실행하셨습니다.")
import ModuleDef as md
cal1 = md.Calculator()
print(cal1.add(5))
print(cal1.subtract(2))
from ModuleDef import Calculator
cal1 = Calculator()
print(cal1.add(5))
print(cal1.subtract(2))
if __name__ == "__main__"
• 직접 이 파일을 실행 시킬 경우 수행 되는 코드를 작성.
• 모듈을 통해서 호출 될 때는 호출되지 않는다.
35.
모듈과 패키지
패키지는 .를 이용하여 파이썬 모듈을 계층적으로 관리할 수 있게 해준다.
파이썬 언어
패키지 활용과 __init__.py
• 파이썬 패키지는 디렉터리와 파이썬 모듈로 이루어진다.
• __init__.py 파일은 해당 디렉터리가 패키지의 일부임을 알려주는 역할을 한다.
• 패키지 내 모듈을 import하기 위해서 패키지 명까지 같이 사용한다.
# ModuleAndPackage.py
import Python.ModuleDef as md
cal1 = md.Calculator()
print(cal1.add(5))
print(cal1.subtract(2))
# ModuleAndPackage.py
from Python.ModuleDef import Calculator
cal1 = Calculator()
print(cal1.add(5))
print(cal1.subtract(2))
36.
모듈과 패키지
표준라이브러리 :sys, os
파이썬 언어
sys 모듈은 파이썬 인터프리터가 제공하는 변수들과 함수들을 직접 제어할 수 있게 해 주는 모듈
• sys.argv : 명령 행에서 인수 전달하기
• sys.exit : 프로그램 강제로 종료하기
• sys.path : 모듈들이 저장되어 있는 위치로 이 위치에 있는 모듈은 어디에서나 불러올 수 있다.
import sys, os
print(sys.path)
print(os.environ)
print(os.environ['PATH'])
print(os.getcwd())
os 모듈은 환경 변수나 디렉터리, 파일 등의 OS 자원을 제어 할 수 있게 해주는 모듈
• os.environ : 시스템의 환경 변수 값을 dictionary 객체로 리턴
• os.environ['PATH'] : 시스템 PATH 환경변수
• os.getcwd : 현재 자신의 디렉토리
37.
모듈과 패키지
표준라이브러리 :time. calendar
파이썬 언어
time 모듈은 시간과 관련된 함수가 많다.
• time.time() : UTC를 이용하여 현재 시간을 실수 형태로 리턴. 1970년 1월 1일 0시 0분 0초를 기준
• time.localtime() : time.time()에 의해 반환된 실수 값을 이용해서 년/월/일/시/분/초로 변환
• time.strftime(‘출력포맷’, localtime) : 시간 출력을 포맷팅 함.
import time, calendar
print(time.time())
localtime = time.localtime(time.time())
print(localtime)
print(time.strftime('%Y.%m.%d %X', localtime))
print(calendar.prmonth(localtime.tm_year, localtime.tm_mon))
calendar 는 달력을 볼 수 있게 해 준다.
• calendar.prmonth : 해당 월의 달력만 보여 준다.
38.
모듈과 패키지
표준라이브러리 :random
파이썬 언어
random은 난수를 발생시키는 모듈이다.
• random.random() : 0.0에서 1.0 사이의 실수를 return.
• random.randint(1, 10) : 1에서 10사이의 정수 중에서 난수 값을 return.
• random.choice(data) : 입력 받은 리스트에서 무작위로 하나를 선택하여 return.
• random.shuffle(data) : 입력 받은 리스트항목을 무작위로 섞는다.
import random
print(random.random())
print(random.randint(-10,10))
data = [-3, -2, -1, 0, 1, 2, 3]
print(random.choice(data))
random.shuffle(data)
print(data)
39.
모듈과 패키지
표준라이브러리 :pickle
파이썬 언어
pickle은 객체의 형태를 그대로 유지하면서 파일에 저장하고 불러올 수 있게 하는 모듈이다.
• pickle.dump(data, file) : data 객체를 그대로 파일에 저장
• data = pickle.load(file) : pickle.dump에 의해 저장된 파일을 객체 상태 그대로 읽기.
import pickle
dict1 = {'name': '강병호', 'co': 'SK', 'birth': '1128'}
f = open("./pickle.txt", "wb")
pickle.dump(dict1, f)
f.close()
f = open("./pickle.txt", "rb")
dict2 = pickle.load(f)
print(dict2)
40.
파일 입출력
파일 열고닫기 : open, close
파이썬 언어
내장함수 open은 파일 객체를 리턴한다.
파일 객체 = open(파일 이름, 파일 열기 모드)
파일 열기 모드 설명
r 읽기모드 - 파일을 읽기만 할 때 사용
w 쓰기모드 - 파일에 내용을 쓸 때 사용, 해당 파일이 이미 존재하면 기존 내용은 삭제 됨.
a 추가모드 - 파일의 마지막에 새로운 내용을 추가 시킬 때 사용
b 바이너리 파일
내장함수 close는 열러 있는 파일 객체를 닫아준다.
파일 객체.close()
41.
파일 입출력
파일 읽고쓰기 : read, write
파이썬 언어
파일 내용 읽기 : readline(), readlines(), read()
파일 객체 = open(파일 이름, 파일 열기 모드)
함수 설명
readline 라인단위로 읽기
readlines 모든 라인을 읽어서 라인 단위로 리스트로 리턴
read 파일 전체를 읽어 문자열로 리턴
파일 내용 쓰기 : write
파일 객체.write()
f = open("./myfile.txt", "w")
for idx in range(1, 6):
data = "%d번째 줄입니다.n" % idx
f.write(data)
f.close()
f = open("./myfile.txt", "r")
data = f.read()
print(data)
f.close()
1번째 줄입니다.
2번째 줄입니다.
3번째 줄입니다.
4번째 줄입니다.
5번째 줄입니다.
42.
파일 입출력
with 문을이용한 파일 처리
파이썬 언어
with문을 이용하면 파일을 열고 닫는 것을 자동으로 처리할 수 있다.
• with 블록을 벗어나면 파일 객체가 자동으로 close 된다.
with open("./myfile.txt", "r") as f:
data = f.read()
print(data)
43.
실습 파이썬 언어
3과 5의 배수 합하기
• 10 미만의 자연수에서 3과 5의 배수를 구하면 3, 5, 6, 9이다. 이들의 총합은 23이다.
• 1000 미만의 자연수에서 3의 배수와 5의 배수의 총합을 구하라.
#1 – 자료형 & 제어문
# 정답
233,168
44.
실습 파이썬 언어
평균값 계산 함수 작성
• 입력으로 들어오는 모든 수의 평균 값을 계산해 주는 함수를 작성한다.
• 함수의 파라미터로는 튜플을 전달받으며, 튜플 내 데이터의 수는 제한을 두지 않는다.
#2 – 함수
# 정답
3.0
423.0
# getavg 함수를 작성하세요
print(getavg((1,2,3,4,5)))
print(getavg((154, 709, 406)))
45.
실습 파이썬 언어
파일 수정
• 다음 내용의 파일 test1.txt의 내용 중 Japan이라는 문자열을 China로 바꾸어 test2.txt로 저장하기.
• 파일 객체 생성 시 한 번 이상 with 문을 사용하기
#3 – 파일처리
# test1.txt
Hello,
I want to go to Japan.
# test2.txt
Hello,
I want to go to China.
다차원 배열
ndarray :N-dimensional array type
NumPy
다차원 배열 객체
• NumPy의 ndarray는 파이썬에서 사용할 수 있는 배열 구조이다.
• ndarray는 같은 종류의 데이터를 담을 수 있는 다차원 배열이며, 모든 원소는 같은 자료형 이어야 한다.
• 모든 배열은 각 차원의 크기를 알려주는 shape라는 튜플과 배열에 저장된 자료형을 알려주는 dtype 이라는 객체를 가
지고 있다.
[From] https://www.safaribooksonline.com/library/view/elegant-scipy/9781491922927/ch01.html
48.
다차원 배열
dtype :자료형
NumPy는 파이썬 자료형보다 더 다양한 자료형을 지원한다.
종류 설명
int8, unit8 부호가 있는 8비트 정수형, 부호가 없는 8비트 정수형
int16, unit16 부호가 있는 16비트 정수형, 부호가 없는 16비트 정수형
int32, unit32 부호가 있는 32비트 정수형, 부호가 없는 32비트 정수형
int64, unit64 부호가 있는 64비트 정수형, 부호가 없는 64비트 정수형
float16 반정밀도 부동소수점
float32 단정밀도 부동소수점, C 언어의 float형과 호환
float64 배정밀도 부동소수점, C 언어의 double형과 Python의 float 객체와 호환
float128 확장 정밀도 부동소수점
complex64, complex128, complex256 각각 2개의 32, 64, 128비트 부동소수점을 가지는 복소수
bool True / False
object 파이썬 객체형
string_ 고정 길이 문자열형
unicode_ 고정 길이 유니코드형
NumPy
49.
다차원 배열
ndarray 객체의Attribute (속성)
ndarray의 다양한 attribute
속성 설명
shape 다차원 배열의 구조. Tuple 형으로 return
ndim 차원의 수
size 요소(element)의 전체 수
dtype 자료 형
import numpy as np
a = np.array([[1,2],[3,4]]) # 파이썬 리스트를 이용하여 ndarray 객체생성
print(a.shape) # (2,2)
print(a.ndim) # 2
print(a.size) # 4
print(a.dtype) # int32
print(type(a)) # <class 'numpy.ndarray'>
NumPy
50.
다차원 배열의 생성과조작
ndarray 객체의 생성
ndarray 생성함수
함수 설명
array 입력 데이터 (리스트, 튜플, 배열)를 ndarray로 변환. Dtype은 명시되지 않으면 추론하여 저장
arange 파이썬 내장 range함수와 유사하지만, 리스트 대신 ndarray를 반환
ones, ones_like
주어진 dtype과 shape를 가진 ndarray를 생성하지만 1로 값을 초기화. ones_like는 주어진 배
열과 동일한 모양과 dtype을 가지지만 1로 값을 초기화
zeros, zeros_like ones, ones_like와 같지만 값을 0으로 초기화
empty, empty_like 메모리를 할당하여 새로운 배열을 생성하지만 값을 초기화 하지 않음.
import numpy as np
a = np.arange(-3, 3, 0.5)
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = np.zeros((2,3), dtype=np.float16)
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = np.ones_like(b, dtype=np.int8)
print(c)
print(c.shape, c.ndim, c.size, c.dtype)
[-3. -2.5 -2. -1.5 -1. -0.5 0. 0.5 1. 1.5 2. 2.5]
(12,) 1 12 float64
[[0. 0. 0.]
[0. 0. 0.]]
(2, 3) 2 6 float16
[[1 1 1]
[1 1 1]]
(2, 3) 2 6 int8
NumPy
51.
랜덤 샘플링 :numpy.random 모듈은 다양한 확률분포로 부터 표본 값을 생성한다.
numpy.random 함수
함수 설명
rand (d0, d1, …, dn) 균등분포에서 표본을 추출한다.
randint (low[, high, size, dtype]) 주어진 최소/최대 범위 안에서 임의의 정수를 추출한다. *return은 int 형이다.
randn (d0, d1, …, dn) 표준편차가 1이로 평균값이 0인 정규분포에서 표본을 추출한다.
normal ([loc, scale, size]) 정규분포(가우시안)에서 표본을 추출한다.
uniform ([low, high, size]) 균등(0,1)분포에서 표본을 추출한다
choice (a[, size, replace, p]) 주어진 1차원 array에서 랜덤 샘플 추출
a = np.random.normal(size=(4,4))
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = np.random.randn(2,4)
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = np.random.randint(0, 10)
print(c, type(c))
# 0에서 100 사이의 랜덤 수 5개 추출 (아래 2개는 같다)
print(np.random.choice(100, 5))
print(np.random.randint(0, 100, 5))
[[ 0.72999925 1.42421993 0.37492005 0.44970711]
[-0.35747215 1.26062921 -0.38538562 0.03554219]
[ 0.03747665 0.38745867 0.15693495 -0.68242266]
[ 1.61439767 -0.74602597 -0.81712355 1.15703498]]
(4, 4) 2 16 float64
[[ 0.67698349 -0.26603332 -1.51366372 -0.0360499 ]
[-0.88502674 -1.29097582 0.5591134 0.24685393]]
(2, 4) 2 8 float64
5 <class 'int'>
[30 24 13 21 7]
[78 99 45 63 84]
[Details] https://docs.scipy.org/doc/numpy/reference/routines.random.html
다차원 배열의 생성과 조작 NumPy
52.
배열 조작 기법: Shape 변경 및 전치행렬
ndarray 객체는 shape를 변경하거나 전치행렬을 만드는 함수들을 제공한다.
함수 설명
reshape ndarray data의 변경 없이 shape을 변경
flatten 다차원 배열을 1차원으로 변경 (평탄화)
transpose 전치행렬 : 행렬의 주 대각선을 기준으로 뒤집는다.
ndarray.T self.transpose()와 동일함
a = np.arange(6).reshape(2,3)
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = a.flatten()
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = a.transpose()
print(c)
print(c.shape, c.ndim, c.size, c.dtype)
[[0 1 2]
[3 4 5]]
(2, 3) 2 6 int32
[0 1 2 3 4 5]
(6,) 1 6 int32
[[0 3]
[1 4]
[2 5]]
(3, 2) 2 6 int32
[Details] https://docs.scipy.org/doc/numpy/reference/routines.array-manipulation.html
다차원 배열의 생성과 조작 NumPy
53.
인덱싱과 슬라이싱 :1차원 배열
1차원 배열은 파이썬 리스트와 유사하게 동작.
a = np.arange(10)
print(a)
print(a[2]) # 2번 항목
print(a[3:5]) # 3~4번 항목
print(a[:8:2]) # 0~7번 항목 중 2번째 마다
print(a[::-1]) # 전체항목 중 1씩 감소할때 마다
[0 1 2 3 4 5 6 7 8 9]
2
[3 4]
[0 2 4 6]
[9 8 7 6 5 4 3 2 1 0]
다차원 배열의 생성과 조작
print(a)
a_slice = a[3:5]
a_slice[:] = -1
print(a)
[0 1 2 3 4 5 6 7 8 9]
[ 0 1 2 -1 -1 5 6 7 8 9]
파이썬 리스트와 차이점은 배열 조각은 원본 배열의 복사본이 아니라 View 이다.
• 즉, View에 대한 변경은 그대로 원본 배열에 반영된다.
NumPy
54.
인덱싱과 슬라이싱 :다차원 배열
2차원 배열에서 각 색인에 해당하는 요소는 스칼라 값이 아니라 1차원 배열이 된다.
a = np.arange(1,21,1).reshape(4,5)
print(a)
print(a[2,3])
print(a[0:4,1])
print(a[1,])
print(a[-1,])
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]]
14
[ 2 7 12 17]
[ 6 7 8 9 10]
[16 17 18 19 20]
다차원 배열의 생성과 조작
b = np.arange(1,25).reshape(2,3,4)
print(b)
print(b[0])
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
다차원 배열에서 색인은 한 차원 낮은 ndarray가 된다.
• 예) a가 2x3x4 크기의 배열이라면 a[0]은 3x4 크기의 ndarray이다.
NumPy
55.
배열의 연산
같은 크기의배열간 산술연산
같은 크기의 배열 간 산술 연산은 배열의 각 요소 단위로 적용된다.
import numpy as np
a1 = np.arange(1,5).reshape(2,2)
a2 = np.arange(5,9).reshape(2,2)
print(a1)
print(a2)
print(a1+a2)
print(a1-a2)
print(a1*a2)
print(a1/a2)
[[1 2]
[3 4]]
[[5 6]
[7 8]]
[[ 6 8]
[10 12]]
[[-4 -4]
[-4 -4]]
[[ 5 12]
[21 32]]
[[0.2 0.33333333]
[0.42857143 0.5 ]]
NumPy
56.
배열과 스칼라 값에대한 산술 연산
배열과 스칼라 값에 대한 산술 연산 시 산술 연산은 각 요소로 전달된다.
import numpy as np
a1 = np.arange(1,5).reshape(2,2)
print(a1)
print(a1**2)
print(a1>2)
[[1 2]
[3 4]]
[[ 1 4]
[ 9 16]]
[[False False]
[ True True]]
배열의 연산 NumPy
57.
행렬 곱셈(내적)에 대한이해
행렬의 곱셈(내적)은 일정한 규칙에 따라 계산하며 행렬과 벡터의 크기에 따라 그 결과가 달라진다.
배열의 연산 NumPy
유니버설 함수 (ufunc): ndarray 안에 있는 데이터 원소 별로 연산을 수행하는 함수
단항 유니버설 함수
넘파이 함수
함수 설명
abs, fabs 각 원소의 절대 값을 구한다. 복소수가 아닌 경우에는 빠른 연산을 위해 fabs를 사용한다.
sqrt 각 원소의 제곱근을 구한다. arr ** 0.5 와 동일하다
square 각 원소의 제곱을 계산한다. arr ** 2 와 동일하다.
exp 각 원소에서 지수 𝑒 𝑥
를 계산한다.
log 각 원소에서 자연로그를 계산한다.
sin, cos, tan 각 원소에서 삼각함수를 계산한다.
sinh, cosh, tanh 각 원소에서 쌍곡 삼각함수를 계산한다.
import numpy as np
a = np.arange(1, 6)
print(a)
print(np.sqrt(a))
print(np.square(a))
print(np.exp(a))
print(np.log(a))
print(np.sin(a))
print(np.tanh(a))
[1 2 3 4 5]
[1. 1.41421356 1.73205081 2. 2.23606798]
[ 1 4 9 16 25]
[ 2.71828183 7.3890561 20.08553692 54.59815003 148.4131591 ]
[0. 0.69314718 1.09861229 1.38629436 1.60943791]
[ 0.84147098 0.90929743 0.14112001 -0.7568025 -0.95892427]
[0.76159416 0.96402758 0.99505475 0.9993293 0.9999092 ]
NumPy
64.
유니버설 함수 (Cont’d)
이항 유니버설 함수 : 2개의 배열을 인자로 취해서 단을 배열을 반환하는 함수
넘파이 함수
함수 설명
add 두 배열에서 같은 위치의 원소끼리 더한다.
subtract 첫 번째 배열의 원소에서 두 번째 배열의 원소를 뺀다.
multiply 배열의 원소끼리 곱한다.
divide 첫 번째 배열의 원소에서 두 번째 배열의 원소로 나눈다.
mod 첫 번째 배열의 원소에서 두 번째 배열의 원소를 나눈 후 나머지를 구한다.
maximum 두 원소 중 큰 값을 반환한다.
minimum 두 원소 중 작은 값을 반환한다.
import numpy as np
a1 = np.array([2,3,4])
a2 = np.array([1,5,2])
print(np.maximum(a1, a2))
print(np.minimum(a1, a2))
[2 5 4]
[1 3 2]
NumPy
65.
통계 함수 :배열 전체 혹은 배열에서 한 축에 따르는 자료에 대한 통계를 계산하는 함수
기본 배열 통계 함수
넘파이 함수
함수 설명
sum 배열 전체 혹은 특정 축에 대한 모든 원소의 합
mean 배열 전체 혹은 특정 축에 대한 모든 원소의 평균
min, max 최소 값, 최대 값
argmin, argmax 최소 원소의 색인 값, 최대 원소의 색인 값
import numpy as np
a = np.array([[6,2,4,8,2,4],[-7,3,4,-1,9,0]])
print(a)
print(np.sum(a))
print(np.mean(a))
print(np.min(a))
print(np.max(a))
print(np.argmin(a))
print(np.argmax(a))
[[ 6 2 4 8 2 4]
[-7 3 4 -1 9 0]]
34
2.8333333333333335
-7
9
6
10
NumPy
66.
통계 함수 (Cont’d)
일부 통계 함수는 선택적으로 axis 인자를 받아 해당 axis에 대한 통계를 계산하고 한 차수 낮은 배열을 반환한다.
넘파이 함수
import numpy as np
a = np.array([[6,2,4,8,2,4],[-7,3,4,-1,9,0]])
print(a)
print(np.sum(a, axis=0))
print(np.mean(a, axis=0))
print(np.argmax(a, axis=0))
print(np.argmax(a, axis=1))
[[ 6 2 4 8 2 4]
[-7 3 4 -1 9 0]]
[-1 5 8 7 11 4]
[-0.5 2.5 4. 3.5 5.5 2. ]
[0 1 0 0 1 0]
[3 4]
[From]
https://www.python-course.eu/numpy_create_arrays.php
https://docs.rs/ndarray/*/ndarray/type.ArrayView.html
NumPy
67.
실습
다음 2개의ndarray 객체를 생성하고 그 내적의 결과를 확인한다.
#1 – 2차원 배열의 생성 및 내적 계산
NumPy
𝟓 𝟔
𝟕 𝟖
𝟗 𝟏𝟎
𝟏 𝟐 𝟑
𝟒 𝟓 𝟔
=
𝟐𝟗 𝟒𝟎 𝟓𝟏
𝟑𝟗 𝟓𝟒 𝟔𝟗
𝟒𝟗 𝟔𝟖 𝟖𝟕
68.
실습
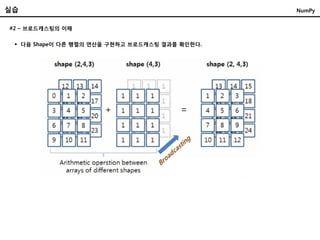
다음 Shape이다른 행렬의 연산을 구현하고 브로드캐스팅 결과를 확인한다.
#2 – 브로드캐스팅의 이해
NumPy
69.
실습
Sigmoid 함수는아래의 공식으로 계산되는 함수 이다.
• 시그모이드 함수를 구현하고 x 값이 0일 때 결과 값을 계산하라.
#3 – 시그모이드(Sigmoid) 함수 구현 및 계산
NumPy
𝒚 =
𝟏
𝟏 + 𝒆−𝒙
0.5
70.
실습
다음 신경망은행렬 내적 식으로 표현할 수 있다.
• 위 계산을 수행하는 함수를 구현하고 입력 값이 [1, 2] 배열이 들어 온 경우 출력 값을 구하시오.
#4 – 신경망의 계산 이해
NumPy
𝒙 𝟏
𝒙 𝟐
1
𝒚 𝟐
𝒚 𝟏
𝒚 𝟑
2
3
4
5
6
𝒙 𝟏 𝒙 𝟐
𝟏 𝟑 𝟓
𝟐 𝟒 𝟔
= 𝒚 𝟏 𝒚 𝟐 𝒚 𝟑
[ 5 11 17]
Simple Plot Matplotlib
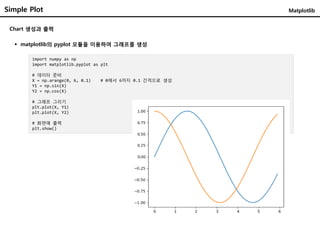
Chart생성과 출력
matplotlib의 pyplot 모듈을 이용하여 그래프를 생성
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
X = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
Y1 = np.sin(X)
Y2 = np.cos(X)
# 그래프 그리기
plt.plot(X, Y1)
plt.plot(X, Y2)
# 화면에 출력
plt.show()
73.
Simple Plot Matplotlib
plot함수와 Line Styling
pyplot 모듈 내 plot 함수의 정의
• kwargs : keyword arguments 를 활용하여 Plot되는 라인의 속성을 정의할 수 있다.
plot([x], y, [fmt], data=None, **kwargs)
속성 설명
color or c Plot 되는 선의 색상 (blue, green, red, cyan, magenta, yellow, black, white)
label Plot 되는 데이터의 Label. 범례 표시를 위해 legend() 함수에서 활용 됨.
linestyle or ls Plot 되는 선의 스타일 (solid : - dashed : -- dashdot : -. dotted : :)
linewidth or lw Plot 되는 선의 굵기 (float value)
[Details] https://matplotlib.org/api/_as_gen/matplotlib.pyplot.plot.html#matplotlib.pyplot.plot
74.
Simple Plot Matplotlib
ChartStyling
pyplot 모듈 내 차트를 꾸미기는 함수들
함수 설명
xlabel, ylabel x축과 y축에 전체에 대한 label
xticks, yticks x축과 y축에 대응 값에 대한 label
title 차트의 제목
legend 범례 표시
axis X축 y축의 최소 및 최대값 설정 [xmin, xmax, ymin, ymax]
annotate xy point 에 text로 annotation 를 함. annotate(*args, **kwargs)
[Details] https://matplotlib.org/api/pyplot_summary.html
75.
Simple Plot Matplotlib
Styling후의 Chart
matplotlib의 pyplot 모듈을 이용하여 그래프를 생성
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
X = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
Y1 = np.sin(X)
Y2 = np.cos(X)
# 그래프 그리기
plt.plot(X, Y1, color="magenta", label="sin", linestyle="dashed", linewidth=2.5)
plt.plot(X, Y2, c="yellow", label="cos", ls="dashdot", lw=1.5)
plt.xlabel("x")
plt.ylabel("y")
plt.title("sin & cos")
plt.legend()
# 화면에 출력
plt.show()
76.
Simple Plot Matplotlib
한글폰트사용
pyplot 모듈의 rc 메소드를 통한 rc 파라미터의 조정을 통해 한글을 표시
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
X = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
Y1 = np.sin(X)
Y2 = np.cos(X)
# 한글처리
plt.rc('font',family='Malgun Gothic') # 맑은고딕 사용
plt.rc('axes',unicode_minus=False) # 그래프에서 마이너스 폰트 깨지는 문제 대처
# 그래프 그리기
plt.plot(X, Y1, color="magenta", label="sin", linestyle="dashed", linewidth=2.5)
plt.plot(X, Y2, c="yellow", label="cos", ls="dashdot", lw=1.5)
plt.xlabel("x")
plt.ylabel("y")
plt.title("삼각함수 그래프")
plt.legend()
# 화면에 출력
plt.show()
[Details] https://programmers.co.kr/learn/courses/21/lessons/950
77.
Simple Plot Matplotlib
SimplePlot 예 : 프로듀스 시즌 1 Top 3 순위 변동 차트
import numpy as np
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# 순위 데이터
somi = (1, 1, 1, 2, 4, 4, 1, 1)
sejeong = (2, 2, 2, 1, 1, 1, 2, 2)
yujeong = (11,13,8, 3, 2, 2, 3, 3)
# x축
xs = [i for i,_ in enumerate(somi)]
print(xs) # [0, 1, 2, 3, 4, 5, 6, 7]
plt.plot(xs, somi , 'g-', label="소미")
plt.plot(xs, sejeong, 'r-', label="세정")
plt.plot(xs, yujeong, 'b-', label="유정")
plt.axis([-0.5, 7.5, 14, 0])
plt.xticks(xs, ['1회', '2회', '3회', '5회', '6회', '8회', '10회', '11회'])
plt.xlabel("순위 선정 회차")
plt.ylabel("순위")
plt.title("프로듀스 시즌 1 Top 3 순위변동차트")
plt.legend()
plt.show()
78.
다른 유형의 PlotMatplotlib
Image Plot
pyplot 모듈 내 이미지를 처리하는 함수들
함수 설명
imread 이미지 파일을 읽어 배열(numpy.ndarray)로 저장. format 파라미터가 없으면 png 파일로 인식
imsave 배열을 이미지 파일로 저장
imshow 이미지를 축에 따라 Plotting
[Details] https://matplotlib.org/api/pyplot_summary.html
import matplotlib.pyplot as plt
# 이미지 데이터
img = plt.imread("saturn.png")
print(type(img), img.shape) # <class 'numpy.ndarray'> (238, 714, 4)
# 이미지 그리기
plt.imshow(img)
plt.title("Saturn")
# 화면에 출력
plt.show()
79.
다른 유형의 PlotMatplotlib
Bar Plot
pyplot 모듈 내 bar 함수를 이용하여 처리
bar(x, height, *, align='center', **kwargs)
bar(x, height, width, *, align='center', **kwargs)
bar(x, height, width, bottom, *, align='center', **kwargs)
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# 데이타
people = ('소미','세정','유정','청하','소혜','결경','채연','도연','미나','나영','연정')
scores = (858333,525352,438778,403633,229732,218338,215338,200069,173762,138726,136780)
# 그래프
xs = [i for i,_ in enumerate(people)]
plt.bar(xs, scores, facecolor='#9999ff', edgecolor='white')
plt.xticks(xs, people)
plt.ylabel('득표 수')
plt.title('프로듀스 시즌 1 최종 득표 수')
plt.show()
다른 유형의 PlotMatplotlib
Scatter Plot
pyplot 모듈 내 hist 함수를 이용하여 처리
scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None,
linewidths=None, verts=None, edgecolors=None, hold=None, data=None, **kwargs)
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# Scatter
people = ('소미','세정','유정','청하','소혜','결경','채연','도연','미나','나영','연정')
scores = (858333,525352,438778,403633,229732,218338,215338,200069,173762,138726,136780)
search = (432800,607000,400500,201300,454900,340600,912800,236000,52800 ,167700,96000 )
plt.scatter(scores, search)
# Point에 Label추가 (label을 Point 근처에서 약간 떨어지게)
for people, scores_cnt, search_cnt in zip(people, scores, search):
plt.annotate(people, xy=(scores_cnt, search_cnt), xytext=(5, 0), textcoords='offset points')
plt.axis([0, 1000000, 0, 1000000])
plt.title("최종득표수 대비 검색량")
plt.xlabel("최종득표수")
plt.ylabel("검색량")
plt.show()
82.
실습
#1 – Sigmoid함수의 시각화
Matplotlib
-10에서 10까지 0.1 간격으로 1차원 배열을 생성 후 Sigmoid 함수 호출한 결과를 시각화 한다.
• Plot 되는 Line을 Styling 한다.
• Chart 에 X축, Y축, 제목, 범례를 표시한다.
𝒚 =
𝟏
𝟏 + 𝒆−𝒙





![데이터 분석을 위한 파이썬
Python의 주요 용도는 Web 개발 및 Data Science이다.
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
소개 및 환경설정](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-6-320.jpg)
![데이터 분석을 위한 파이썬
Python 3가 Python 2보다 더 많이 사용된다.
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
• 2016년에는 Python 2 점유율 60%
• 2020년에는 Python 2 유지보수 중단
2017년 Survey
소개 및 환경설정](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-7-320.jpg)

![딥러닝 구현 시 배열과 행렬 계산이 많은데 NumPy의 배열 클래스에는 이를 위한 method가 많이 있다.
NumPy 라이브러리 import 하기
NumPy 배열 생성하기
• 1차원 배열 (벡터) 생성하기
• 2차원 배열 (행렬) 생성하기
NumPy 배열 원소 접근하기
NumPy 배열 연산하기
• NumPy 배열 산술 연산
import numpy as np
x1 = np.array([1.0, 2.0, 3.0])
y1 = np.array([5.0, 10.0, 15.0])
x2 = np.array([[1.0, 2.0],[ 3.0, 4.0]])
y2 = np.array([[5.0,10.0],[15.0,20.0]])
print(x1[0])
print(x2[1][0])
print(x1 + y1)
print(x1 - y1)
print(x2 + y2)
print(x2 * y2)
NumPy 배열 Broadcast 연산
필수 파이썬 라이브러리 소개 및 환경설정](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-9-320.jpg)


![개발환경은 간단한 편집기부터 통합개발환경(IDE) 까지 다양하다.
환경설정
[From] https://www.jetbrains.com/research/python-developers-survey-2017/
소개 및 환경설정](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-12-320.jpg)




![파이썬 기초
파이썬은 인터프리터 언어이다. 즉 컴파일 없이 한 번에 하나의 명령어만 실행한다.
파이썬 언어
C:UsersAdministrator>python
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("hello")
hello
파이썬은 다른 언어와 달리 중괄호{} 대신 들여쓰기를 사용해서 코드를 구조화 한다.
while count <= 10 :
total += count
count += 1
print(count) # 11
print(total)
def bears():
return ("카스", "칭다오", "아사히")
>>> a = 3
>>> type(a)
<class 'int'>
모든 것은 객체이다.
• 모든 자료구조, 함수, 클래스 등 모두 객체로 간주한다.
• 객체는 속성(Attribute)과 함수(Method)를 가진다.](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-18-320.jpg)



![자료형
리스트는 데이터의 모음으로 데이터 항목을 추가, 삭제, 변경을 할 수 있다.
리스트 생성
• 리스트명 = [요소1, 요소2, 요소3, ...]
파이썬 언어
odd = [1, 3, 5, 7, 9]
리스트 인덱싱과 슬라이싱
odd = [1, 3, 5, 7, 9]
print(odd[0]) # 1
print(odd[-1]) # 9
print(odd[1:3]) # [3,5]
print(odd[:3]) # [1,3,5]
print(odd[3:]) # [7,9]
리스트 관련 함수
mylist = ['my','python','list']
print(mylist, type(list)) # ['my', 'python', 'list'] <class 'type'>
mylist.append("added")
print(mylist) # ['my', 'python', 'list', 'added']
mylist.remove('python')
print(mylist) # ['my', 'list', 'added']
mylist.sort()
print(mylist) # ['added', 'list', 'my']
• 기타 관련 함수 매우 많음.](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-23-320.jpg)
![자료형
튜플(Tuple)은 리스트와 비슷하지만, 그 값을 바꿀 수 없다.
Tuple 생성
• 튜플명 = (요소1, 요소2, 요소3, ...)
파이썬 언어
t1 = (1, 2, 'a', 'b')
Tuple 인덱싱과 슬라이싱, 더하기와 반복하기
t1 = (1, 2, 'a', 'b')
t2 = (3, 4)
print(t1[0]) # 1
print(t1[-2:]) # ('a', 'b')
print(t1+t2) # (1, 2, 'a', 'b', 3, 4)
print(t2*2) # (3, 4, 3, 4)
• 더하기와 반복하기는 List에도 같이 적용된다.](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-24-320.jpg)
![자료형
딕셔너리(Dictionary)는 키-값의 쌍을 리스트 형태로 가진다.
Dictionary 생성
• 딕셔너리명 = {Key1:Value1, Key2:Value2, Key3:Value3, ...}
파이썬 언어
dict1 = {'name': '강병호', 'co': 'SK', 'birth': '1128'}
Dictionary의 Value 얻기 및 딕셔너리 쌍 추가, 삭제
dict1 = {'name': '강병호', 'co': 'SK', 'birth': '1128'}
print(dict1.get('name')) # 강병호
dict1['addr'] = '성남시'
print(dict1) # {'name': '강병호', 'co': 'SK', 'birth': '1128', 'addr': '성남시'}
del dict1['birth']
print(dict1) # {'name': '강병호', 'co': 'SK', 'addr': '성남시'}
dict1['co'] = 'SK주식회사'
print(dict1) # {'name': '강병호', 'co': 'SK주식회사', 'addr': '성남시'}](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-25-320.jpg)
![자료형
집합(Set)은 키만 남은 딕셔너리와 같으며, 각 키는 유일해야 한다.
Set 생성
• Set명 = set([리스트]) 또는 set(“문자열”)
파이썬 언어
set1 = set([1,1,2,3,5,8])
print(set1) # {1, 2, 3, 5, 8}
set2 = set("Hello")
print(set2) # {'e', 'o', 'H', 'l'}
교집합/합집합/차집합
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
print(s1 & s2) # 교집합 {4, 5, 6}
print(s1 | s2) # 합집합 {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(s1 - s2) # 차집합 {1, 2, 3}](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-26-320.jpg)


![제어문
반복문 : for
for문
파이썬 언어
for 변수 in 리스트(또는 튜플, 문자열):
수행할 문장1
수행할 문장2
...
list1 = ['apple','banana','mango']
for item in list1:
print(item) # apple, banana, mango
list2 = [(1,2),(3,4),(5,6)]
for (a, b) in list2:
print(a + b) # 3, 7, 11
total = 0
for idx in range(1,5):
total += idx
print(total) # 1에서 4까지의 합 : 10
for idx in range(len(list1)):
print('과일 %d번은 %s입니다.' % (idx, list1[idx])) # 과일 0번은 apple입니다...
for문은 range 함수와 같이 사용되는 경우가 많다. while문
• range(10)은 0부터 10 미만의 숫자를 포함하는 range 객체를 만들어 준다.
• range(1, 11)은 숫자 1부터 10까지(1 이상 11 미만)의 숫자를 데이터로 갖는 객체이다](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-29-320.jpg)
![함수와 클래스
Lambda 함수
파이썬 언어
lambda 매개변수1, 매개변수2, ... : 매개변수를 이용한 표현식
lambda 구조
• lambda 함수는 보통 함수를 한 줄로 간결하게 만들 때 사용한다.
myfunc = lambda a, b: 3*a+2*b
print(myfunc(1,2)) # 7
funclist = [lambda a,b:a+b, lambda a,b:a-b, lambda a,b:a*b, lambda a,b:a/b]
for myfunc in funclist:
print(myfunc(3,2)) # 5, 1, 6, 1.5](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-31-320.jpg)
![함수와 클래스
내장 함수
파이썬 언어
내장함수는 별도의 설정 없이 바로 사용할 수 있는 함수이다.
print(abs(-1.2)) # 절대값 : 1.2
print(bool(1)) # bool 값 : True
print(chr(97)) # 아스키코드값에 해당되는 문자 : a
print(dict(one=1, two=2, three=3)) # 딕셔너리 객체 생성 : {'one': 1, 'two': 2, 'three': 3}
print(float("3.14")) # float형 객체생성 : 3.14
print(int('100')) # int형 객체생성 : 100
print(len('python')) # 입력값의 길이 : 6
print(list('python')) # 리스트 객체 생성 : ['p', 'y', 't', 'h', 'o', 'n']
print(max([1,2,3])) # 최대값 : 3
print(min([1,2,3])) # 최소값 : 1
print(pow(2,3)) # 거듭제곱 : 8
print(list(range(0,50,10))) # 0부터 49까지 10씩 증가하면서 리스트 생성 : [0, 10, 20, 30, 40]
print(round(1.2345, 2)) # 소수점 둘째자리에서 반올림 : 1.23
print(sorted([3,1,2])) # 입력값을 정렬 후 결과를 리스트로 리턴 : [1, 2, 3]
print(str(3.14)) # 문자열객체로 반환 : 3.14
print(sum([1,2,3])) # 합계 : 6
print(tuple('python')) # 튜플객체 생성 : ('p', 'y', 't', 'h', 'o', 'n')
print(type("python")) # 객체 타입을 반환 : <class 'str'>
문자열 내장함수
a = "I love you"
print(a.count('o')) # 문자갯수세기 : 2
print(a.replace("you", "her")) # 문자열 치환 : I love her
print(a.upper()) # 대문자 변환 : I LOVE YOU](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-32-320.jpg)
![함수와 클래스
클래스와 객체
파이썬 언어
클래스 선언과 인스턴스
• 클래스는 class 키워드를 이용해 선언하고 초기화 메서드를 호출하여 객체를 생성한다.
• 파이썬 메서드명으로 __init__ 을 사용하면 이 메서드는 생성자가 된다
• 파이썬 클래스 메소드의 첫번째 파라미터 명은 관례적으로 self라는 이름을 사용한다.
• self를 이용해서 객체 변수(Attribute)를 만들며, self는 외부에서 함수 호출 시 전달하지 않는다.
class Calculator:
def __init__(self):
self.result = 0
def add(self, num):
self.result += num
return self.result
def subtract(self, num):
self.result -= num
return self.result
cal1 = Calculator()
print(cal1.add(3)) # 3
print(cal1.add(4)) # 7
print(cal1.subtract(2)) # 5
[From] https://wikidocs.net/images/page/12392/setdata.png](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-33-320.jpg)

![모듈과 패키지
표준라이브러리 : sys, os
파이썬 언어
sys 모듈은 파이썬 인터프리터가 제공하는 변수들과 함수들을 직접 제어할 수 있게 해 주는 모듈
• sys.argv : 명령 행에서 인수 전달하기
• sys.exit : 프로그램 강제로 종료하기
• sys.path : 모듈들이 저장되어 있는 위치로 이 위치에 있는 모듈은 어디에서나 불러올 수 있다.
import sys, os
print(sys.path)
print(os.environ)
print(os.environ['PATH'])
print(os.getcwd())
os 모듈은 환경 변수나 디렉터리, 파일 등의 OS 자원을 제어 할 수 있게 해주는 모듈
• os.environ : 시스템의 환경 변수 값을 dictionary 객체로 리턴
• os.environ['PATH'] : 시스템 PATH 환경변수
• os.getcwd : 현재 자신의 디렉토리](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-36-320.jpg)

![모듈과 패키지
표준라이브러리 : random
파이썬 언어
random은 난수를 발생시키는 모듈이다.
• random.random() : 0.0에서 1.0 사이의 실수를 return.
• random.randint(1, 10) : 1에서 10사이의 정수 중에서 난수 값을 return.
• random.choice(data) : 입력 받은 리스트에서 무작위로 하나를 선택하여 return.
• random.shuffle(data) : 입력 받은 리스트항목을 무작위로 섞는다.
import random
print(random.random())
print(random.randint(-10,10))
data = [-3, -2, -1, 0, 1, 2, 3]
print(random.choice(data))
random.shuffle(data)
print(data)](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-38-320.jpg)








![다차원 배열
ndarray : N-dimensional array type
NumPy
다차원 배열 객체
• NumPy의 ndarray는 파이썬에서 사용할 수 있는 배열 구조이다.
• ndarray는 같은 종류의 데이터를 담을 수 있는 다차원 배열이며, 모든 원소는 같은 자료형 이어야 한다.
• 모든 배열은 각 차원의 크기를 알려주는 shape라는 튜플과 배열에 저장된 자료형을 알려주는 dtype 이라는 객체를 가
지고 있다.
[From] https://www.safaribooksonline.com/library/view/elegant-scipy/9781491922927/ch01.html](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-47-320.jpg)

![다차원 배열
ndarray 객체의 Attribute (속성)
ndarray의 다양한 attribute
속성 설명
shape 다차원 배열의 구조. Tuple 형으로 return
ndim 차원의 수
size 요소(element)의 전체 수
dtype 자료 형
import numpy as np
a = np.array([[1,2],[3,4]]) # 파이썬 리스트를 이용하여 ndarray 객체생성
print(a.shape) # (2,2)
print(a.ndim) # 2
print(a.size) # 4
print(a.dtype) # int32
print(type(a)) # <class 'numpy.ndarray'>
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-49-320.jpg)
![다차원 배열의 생성과 조작
ndarray 객체의 생성
ndarray 생성함수
함수 설명
array 입력 데이터 (리스트, 튜플, 배열)를 ndarray로 변환. Dtype은 명시되지 않으면 추론하여 저장
arange 파이썬 내장 range함수와 유사하지만, 리스트 대신 ndarray를 반환
ones, ones_like
주어진 dtype과 shape를 가진 ndarray를 생성하지만 1로 값을 초기화. ones_like는 주어진 배
열과 동일한 모양과 dtype을 가지지만 1로 값을 초기화
zeros, zeros_like ones, ones_like와 같지만 값을 0으로 초기화
empty, empty_like 메모리를 할당하여 새로운 배열을 생성하지만 값을 초기화 하지 않음.
import numpy as np
a = np.arange(-3, 3, 0.5)
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = np.zeros((2,3), dtype=np.float16)
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = np.ones_like(b, dtype=np.int8)
print(c)
print(c.shape, c.ndim, c.size, c.dtype)
[-3. -2.5 -2. -1.5 -1. -0.5 0. 0.5 1. 1.5 2. 2.5]
(12,) 1 12 float64
[[0. 0. 0.]
[0. 0. 0.]]
(2, 3) 2 6 float16
[[1 1 1]
[1 1 1]]
(2, 3) 2 6 int8
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-50-320.jpg)
![랜덤 샘플링 : numpy.random 모듈은 다양한 확률분포로 부터 표본 값을 생성한다.
numpy.random 함수
함수 설명
rand (d0, d1, …, dn) 균등분포에서 표본을 추출한다.
randint (low[, high, size, dtype]) 주어진 최소/최대 범위 안에서 임의의 정수를 추출한다. *return은 int 형이다.
randn (d0, d1, …, dn) 표준편차가 1이로 평균값이 0인 정규분포에서 표본을 추출한다.
normal ([loc, scale, size]) 정규분포(가우시안)에서 표본을 추출한다.
uniform ([low, high, size]) 균등(0,1)분포에서 표본을 추출한다
choice (a[, size, replace, p]) 주어진 1차원 array에서 랜덤 샘플 추출
a = np.random.normal(size=(4,4))
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = np.random.randn(2,4)
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = np.random.randint(0, 10)
print(c, type(c))
# 0에서 100 사이의 랜덤 수 5개 추출 (아래 2개는 같다)
print(np.random.choice(100, 5))
print(np.random.randint(0, 100, 5))
[[ 0.72999925 1.42421993 0.37492005 0.44970711]
[-0.35747215 1.26062921 -0.38538562 0.03554219]
[ 0.03747665 0.38745867 0.15693495 -0.68242266]
[ 1.61439767 -0.74602597 -0.81712355 1.15703498]]
(4, 4) 2 16 float64
[[ 0.67698349 -0.26603332 -1.51366372 -0.0360499 ]
[-0.88502674 -1.29097582 0.5591134 0.24685393]]
(2, 4) 2 8 float64
5 <class 'int'>
[30 24 13 21 7]
[78 99 45 63 84]
[Details] https://docs.scipy.org/doc/numpy/reference/routines.random.html
다차원 배열의 생성과 조작 NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-51-320.jpg)
![배열 조작 기법 : Shape 변경 및 전치행렬
ndarray 객체는 shape를 변경하거나 전치행렬을 만드는 함수들을 제공한다.
함수 설명
reshape ndarray data의 변경 없이 shape을 변경
flatten 다차원 배열을 1차원으로 변경 (평탄화)
transpose 전치행렬 : 행렬의 주 대각선을 기준으로 뒤집는다.
ndarray.T self.transpose()와 동일함
a = np.arange(6).reshape(2,3)
print(a)
print(a.shape, a.ndim, a.size, a.dtype)
b = a.flatten()
print(b)
print(b.shape, b.ndim, b.size, b.dtype)
c = a.transpose()
print(c)
print(c.shape, c.ndim, c.size, c.dtype)
[[0 1 2]
[3 4 5]]
(2, 3) 2 6 int32
[0 1 2 3 4 5]
(6,) 1 6 int32
[[0 3]
[1 4]
[2 5]]
(3, 2) 2 6 int32
[Details] https://docs.scipy.org/doc/numpy/reference/routines.array-manipulation.html
다차원 배열의 생성과 조작 NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-52-320.jpg)
![인덱싱과 슬라이싱 : 1차원 배열
1차원 배열은 파이썬 리스트와 유사하게 동작.
a = np.arange(10)
print(a)
print(a[2]) # 2번 항목
print(a[3:5]) # 3~4번 항목
print(a[:8:2]) # 0~7번 항목 중 2번째 마다
print(a[::-1]) # 전체항목 중 1씩 감소할때 마다
[0 1 2 3 4 5 6 7 8 9]
2
[3 4]
[0 2 4 6]
[9 8 7 6 5 4 3 2 1 0]
다차원 배열의 생성과 조작
print(a)
a_slice = a[3:5]
a_slice[:] = -1
print(a)
[0 1 2 3 4 5 6 7 8 9]
[ 0 1 2 -1 -1 5 6 7 8 9]
파이썬 리스트와 차이점은 배열 조각은 원본 배열의 복사본이 아니라 View 이다.
• 즉, View에 대한 변경은 그대로 원본 배열에 반영된다.
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-53-320.jpg)
![인덱싱과 슬라이싱 : 다차원 배열
2차원 배열에서 각 색인에 해당하는 요소는 스칼라 값이 아니라 1차원 배열이 된다.
a = np.arange(1,21,1).reshape(4,5)
print(a)
print(a[2,3])
print(a[0:4,1])
print(a[1,])
print(a[-1,])
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]]
14
[ 2 7 12 17]
[ 6 7 8 9 10]
[16 17 18 19 20]
다차원 배열의 생성과 조작
b = np.arange(1,25).reshape(2,3,4)
print(b)
print(b[0])
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
다차원 배열에서 색인은 한 차원 낮은 ndarray가 된다.
• 예) a가 2x3x4 크기의 배열이라면 a[0]은 3x4 크기의 ndarray이다.
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-54-320.jpg)
![배열의 연산
같은 크기의 배열간 산술연산
같은 크기의 배열 간 산술 연산은 배열의 각 요소 단위로 적용된다.
import numpy as np
a1 = np.arange(1,5).reshape(2,2)
a2 = np.arange(5,9).reshape(2,2)
print(a1)
print(a2)
print(a1+a2)
print(a1-a2)
print(a1*a2)
print(a1/a2)
[[1 2]
[3 4]]
[[5 6]
[7 8]]
[[ 6 8]
[10 12]]
[[-4 -4]
[-4 -4]]
[[ 5 12]
[21 32]]
[[0.2 0.33333333]
[0.42857143 0.5 ]]
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-55-320.jpg)
![배열과 스칼라 값에 대한 산술 연산
배열과 스칼라 값에 대한 산술 연산 시 산술 연산은 각 요소로 전달된다.
import numpy as np
a1 = np.arange(1,5).reshape(2,2)
print(a1)
print(a1**2)
print(a1>2)
[[1 2]
[3 4]]
[[ 1 4]
[ 9 16]]
[[False False]
[ True True]]
배열의 연산 NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-56-320.jpg)


![2차원 배열의 내적 계산 프로그래밍
NumPy의 dot()함수를 이용하여 내적을 쉽게 계산한다
import numpy as np
a1 = np.arange(1,5).reshape(2,2)
a2 = np.arange(5,9).reshape(2,2)
a3 = np.arange(1,7).reshape(2,3)
a4 = np.arange(5,11).reshape(3,2)
print(a1)
print(a2)
print(a3)
print(a4)
print(np.dot(a1, a2))
print(np.dot(a3, a4))
[[1 2]
[3 4]]
[[5 6]
[7 8]]
[[1 2 3]
[4 5 6]]
[[ 5 6]
[ 7 8]
[ 9 10]]
[[19 22]
[43 50]]
[[ 46 52]
[109 124]]
배열의 연산 NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-59-320.jpg)
![브로드캐스팅
브로드캐스팅(Broadcasting)은 다른 모양의 배열 간 산술 연산을 설명한다.
배열의 연산
[From] http://rfriend.tistory.com/287
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-60-320.jpg)
![브로드캐스팅 (Cont’d)
3차원 배열의 0번 축에 대한 브로드캐스팅
배열의 연산
[From] http://rfriend.tistory.com/287
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-61-320.jpg)
![브로드캐스팅 (Cont’d)
브로드캐스팅 연산 예
배열의 연산
import numpy as np
a1 = np.arange(0,12).reshape(4,3)
b1 = np.arange(0,3)
b2 = np.arange(0,4).reshape(4,1)
print(a1)
print(b1)
print(b2)
print(a1+b1)
print(a1+b2)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[0 1 2]
[[0]
[1]
[2]
[3]]
[[ 0 2 4]
[ 3 5 7]
[ 6 8 10]
[ 9 11 13]]
[[ 0 1 2]
[ 4 5 6]
[ 8 9 10]
[12 13 14]]
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-62-320.jpg)
![유니버설 함수 (ufunc) : ndarray 안에 있는 데이터 원소 별로 연산을 수행하는 함수
단항 유니버설 함수
넘파이 함수
함수 설명
abs, fabs 각 원소의 절대 값을 구한다. 복소수가 아닌 경우에는 빠른 연산을 위해 fabs를 사용한다.
sqrt 각 원소의 제곱근을 구한다. arr ** 0.5 와 동일하다
square 각 원소의 제곱을 계산한다. arr ** 2 와 동일하다.
exp 각 원소에서 지수 𝑒 𝑥
를 계산한다.
log 각 원소에서 자연로그를 계산한다.
sin, cos, tan 각 원소에서 삼각함수를 계산한다.
sinh, cosh, tanh 각 원소에서 쌍곡 삼각함수를 계산한다.
import numpy as np
a = np.arange(1, 6)
print(a)
print(np.sqrt(a))
print(np.square(a))
print(np.exp(a))
print(np.log(a))
print(np.sin(a))
print(np.tanh(a))
[1 2 3 4 5]
[1. 1.41421356 1.73205081 2. 2.23606798]
[ 1 4 9 16 25]
[ 2.71828183 7.3890561 20.08553692 54.59815003 148.4131591 ]
[0. 0.69314718 1.09861229 1.38629436 1.60943791]
[ 0.84147098 0.90929743 0.14112001 -0.7568025 -0.95892427]
[0.76159416 0.96402758 0.99505475 0.9993293 0.9999092 ]
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-63-320.jpg)
![유니버설 함수 (Cont’d)
이항 유니버설 함수 : 2개의 배열을 인자로 취해서 단을 배열을 반환하는 함수
넘파이 함수
함수 설명
add 두 배열에서 같은 위치의 원소끼리 더한다.
subtract 첫 번째 배열의 원소에서 두 번째 배열의 원소를 뺀다.
multiply 배열의 원소끼리 곱한다.
divide 첫 번째 배열의 원소에서 두 번째 배열의 원소로 나눈다.
mod 첫 번째 배열의 원소에서 두 번째 배열의 원소를 나눈 후 나머지를 구한다.
maximum 두 원소 중 큰 값을 반환한다.
minimum 두 원소 중 작은 값을 반환한다.
import numpy as np
a1 = np.array([2,3,4])
a2 = np.array([1,5,2])
print(np.maximum(a1, a2))
print(np.minimum(a1, a2))
[2 5 4]
[1 3 2]
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-64-320.jpg)
![통계 함수 : 배열 전체 혹은 배열에서 한 축에 따르는 자료에 대한 통계를 계산하는 함수
기본 배열 통계 함수
넘파이 함수
함수 설명
sum 배열 전체 혹은 특정 축에 대한 모든 원소의 합
mean 배열 전체 혹은 특정 축에 대한 모든 원소의 평균
min, max 최소 값, 최대 값
argmin, argmax 최소 원소의 색인 값, 최대 원소의 색인 값
import numpy as np
a = np.array([[6,2,4,8,2,4],[-7,3,4,-1,9,0]])
print(a)
print(np.sum(a))
print(np.mean(a))
print(np.min(a))
print(np.max(a))
print(np.argmin(a))
print(np.argmax(a))
[[ 6 2 4 8 2 4]
[-7 3 4 -1 9 0]]
34
2.8333333333333335
-7
9
6
10
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-65-320.jpg)
![통계 함수 (Cont’d)
일부 통계 함수는 선택적으로 axis 인자를 받아 해당 axis에 대한 통계를 계산하고 한 차수 낮은 배열을 반환한다.
넘파이 함수
import numpy as np
a = np.array([[6,2,4,8,2,4],[-7,3,4,-1,9,0]])
print(a)
print(np.sum(a, axis=0))
print(np.mean(a, axis=0))
print(np.argmax(a, axis=0))
print(np.argmax(a, axis=1))
[[ 6 2 4 8 2 4]
[-7 3 4 -1 9 0]]
[-1 5 8 7 11 4]
[-0.5 2.5 4. 3.5 5.5 2. ]
[0 1 0 0 1 0]
[3 4]
[From]
https://www.python-course.eu/numpy_create_arrays.php
https://docs.rs/ndarray/*/ndarray/type.ArrayView.html
NumPy](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-66-320.jpg)


![실습
다음 신경망은 행렬 내적 식으로 표현할 수 있다.
• 위 계산을 수행하는 함수를 구현하고 입력 값이 [1, 2] 배열이 들어 온 경우 출력 값을 구하시오.
#4 – 신경망의 계산 이해
NumPy
𝒙 𝟏
𝒙 𝟐
1
𝒚 𝟐
𝒚 𝟏
𝒚 𝟑
2
3
4
5
6
𝒙 𝟏 𝒙 𝟐
𝟏 𝟑 𝟓
𝟐 𝟒 𝟔
= 𝒚 𝟏 𝒚 𝟐 𝒚 𝟑
[ 5 11 17]](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-70-320.jpg)

![Simple Plot Matplotlib
plot 함수와 Line Styling
pyplot 모듈 내 plot 함수의 정의
• kwargs : keyword arguments 를 활용하여 Plot되는 라인의 속성을 정의할 수 있다.
plot([x], y, [fmt], data=None, **kwargs)
속성 설명
color or c Plot 되는 선의 색상 (blue, green, red, cyan, magenta, yellow, black, white)
label Plot 되는 데이터의 Label. 범례 표시를 위해 legend() 함수에서 활용 됨.
linestyle or ls Plot 되는 선의 스타일 (solid : - dashed : -- dashdot : -. dotted : :)
linewidth or lw Plot 되는 선의 굵기 (float value)
[Details] https://matplotlib.org/api/_as_gen/matplotlib.pyplot.plot.html#matplotlib.pyplot.plot](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-73-320.jpg)
![Simple Plot Matplotlib
Chart Styling
pyplot 모듈 내 차트를 꾸미기는 함수들
함수 설명
xlabel, ylabel x축과 y축에 전체에 대한 label
xticks, yticks x축과 y축에 대응 값에 대한 label
title 차트의 제목
legend 범례 표시
axis X축 y축의 최소 및 최대값 설정 [xmin, xmax, ymin, ymax]
annotate xy point 에 text로 annotation 를 함. annotate(*args, **kwargs)
[Details] https://matplotlib.org/api/pyplot_summary.html](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-74-320.jpg)

![Simple Plot Matplotlib
한글폰트 사용
pyplot 모듈의 rc 메소드를 통한 rc 파라미터의 조정을 통해 한글을 표시
import numpy as np
import matplotlib.pyplot as plt
# 데이터 준비
X = np.arange(0, 6, 0.1) # 0에서 6까지 0.1 간격으로 생성
Y1 = np.sin(X)
Y2 = np.cos(X)
# 한글처리
plt.rc('font',family='Malgun Gothic') # 맑은고딕 사용
plt.rc('axes',unicode_minus=False) # 그래프에서 마이너스 폰트 깨지는 문제 대처
# 그래프 그리기
plt.plot(X, Y1, color="magenta", label="sin", linestyle="dashed", linewidth=2.5)
plt.plot(X, Y2, c="yellow", label="cos", ls="dashdot", lw=1.5)
plt.xlabel("x")
plt.ylabel("y")
plt.title("삼각함수 그래프")
plt.legend()
# 화면에 출력
plt.show()
[Details] https://programmers.co.kr/learn/courses/21/lessons/950](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-76-320.jpg)
![Simple Plot Matplotlib
Simple Plot 예 : 프로듀스 시즌 1 Top 3 순위 변동 차트
import numpy as np
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# 순위 데이터
somi = (1, 1, 1, 2, 4, 4, 1, 1)
sejeong = (2, 2, 2, 1, 1, 1, 2, 2)
yujeong = (11,13,8, 3, 2, 2, 3, 3)
# x축
xs = [i for i,_ in enumerate(somi)]
print(xs) # [0, 1, 2, 3, 4, 5, 6, 7]
plt.plot(xs, somi , 'g-', label="소미")
plt.plot(xs, sejeong, 'r-', label="세정")
plt.plot(xs, yujeong, 'b-', label="유정")
plt.axis([-0.5, 7.5, 14, 0])
plt.xticks(xs, ['1회', '2회', '3회', '5회', '6회', '8회', '10회', '11회'])
plt.xlabel("순위 선정 회차")
plt.ylabel("순위")
plt.title("프로듀스 시즌 1 Top 3 순위변동차트")
plt.legend()
plt.show()](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-77-320.jpg)
![다른 유형의 Plot Matplotlib
Image Plot
pyplot 모듈 내 이미지를 처리하는 함수들
함수 설명
imread 이미지 파일을 읽어 배열(numpy.ndarray)로 저장. format 파라미터가 없으면 png 파일로 인식
imsave 배열을 이미지 파일로 저장
imshow 이미지를 축에 따라 Plotting
[Details] https://matplotlib.org/api/pyplot_summary.html
import matplotlib.pyplot as plt
# 이미지 데이터
img = plt.imread("saturn.png")
print(type(img), img.shape) # <class 'numpy.ndarray'> (238, 714, 4)
# 이미지 그리기
plt.imshow(img)
plt.title("Saturn")
# 화면에 출력
plt.show()](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-78-320.jpg)
![다른 유형의 Plot Matplotlib
Bar Plot
pyplot 모듈 내 bar 함수를 이용하여 처리
bar(x, height, *, align='center', **kwargs)
bar(x, height, width, *, align='center', **kwargs)
bar(x, height, width, bottom, *, align='center', **kwargs)
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# 데이타
people = ('소미','세정','유정','청하','소혜','결경','채연','도연','미나','나영','연정')
scores = (858333,525352,438778,403633,229732,218338,215338,200069,173762,138726,136780)
# 그래프
xs = [i for i,_ in enumerate(people)]
plt.bar(xs, scores, facecolor='#9999ff', edgecolor='white')
plt.xticks(xs, people)
plt.ylabel('득표 수')
plt.title('프로듀스 시즌 1 최종 득표 수')
plt.show()](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-79-320.jpg)
![다른 유형의 Plot Matplotlib
히스토그램
pyplot 모듈 내 hist 함수를 이용하여 처리
hist(x, bins=None, range=None, density=None, weights=None, cumulative=False, bottom=None, histtype='bar',
align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False,
normed=None, hold=None, data=None, **kwargs)
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# 임의 50명 연령
data = (22, 45, 23, 42, 9, 41, 28, 33, 32, 61, 11, 19, 20, 42, 12, 42, 72, 66, 52, 42,
22, 42, 52, 44, 61, 2, 48, 52, 81, 79, 24, 19, 11, 22, 29, 43, 35, 52, 13, 42,
32, 39, 28, 16, 19, 19, 8, 39, 29)
# x축
bins = [x*10 for x in range(11)]
print(bins) # [0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
plt.hist(data, bins, rwidth=0.8, facecolor="#ff9999")
plt.ylabel('인원')
plt.title('연령대별 합계')
plt.show()](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-80-320.jpg)
![다른 유형의 Plot Matplotlib
Scatter Plot
pyplot 모듈 내 hist 함수를 이용하여 처리
scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=None,
linewidths=None, verts=None, edgecolors=None, hold=None, data=None, **kwargs)
import matplotlib.pyplot as plt
# 한글처리
plt.rc('font',family='Malgun Gothic')
plt.rc('axes',unicode_minus=False)
# Scatter
people = ('소미','세정','유정','청하','소혜','결경','채연','도연','미나','나영','연정')
scores = (858333,525352,438778,403633,229732,218338,215338,200069,173762,138726,136780)
search = (432800,607000,400500,201300,454900,340600,912800,236000,52800 ,167700,96000 )
plt.scatter(scores, search)
# Point에 Label추가 (label을 Point 근처에서 약간 떨어지게)
for people, scores_cnt, search_cnt in zip(people, scores, search):
plt.annotate(people, xy=(scores_cnt, search_cnt), xytext=(5, 0), textcoords='offset points')
plt.axis([0, 1000000, 0, 1000000])
plt.title("최종득표수 대비 검색량")
plt.xlabel("최종득표수")
plt.ylabel("검색량")
plt.show()](https://image.slidesharecdn.com/pythondataanalysis-180720012542/85/18-81-320.jpg)










![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Tf2017] day1 jwkang_pub](https://cdn.slidesharecdn.com/ss_thumbnails/tf2017day1jwkangpub-171028123944-thumbnail.jpg?width=640&height=640&fit=bounds)
![[222]딥러닝을 활용한 이미지 검색 포토요약과 타임라인 최종 20161024](https://cdn.slidesharecdn.com/ss_thumbnails/22220161024-161025034006-thumbnail.jpg?width=640&height=640&fit=bounds)




![[226]대용량 텍스트마이닝 기술 하정우](https://cdn.slidesharecdn.com/ss_thumbnails/226-161025031656-thumbnail.jpg?width=640&height=640&fit=bounds)




























