





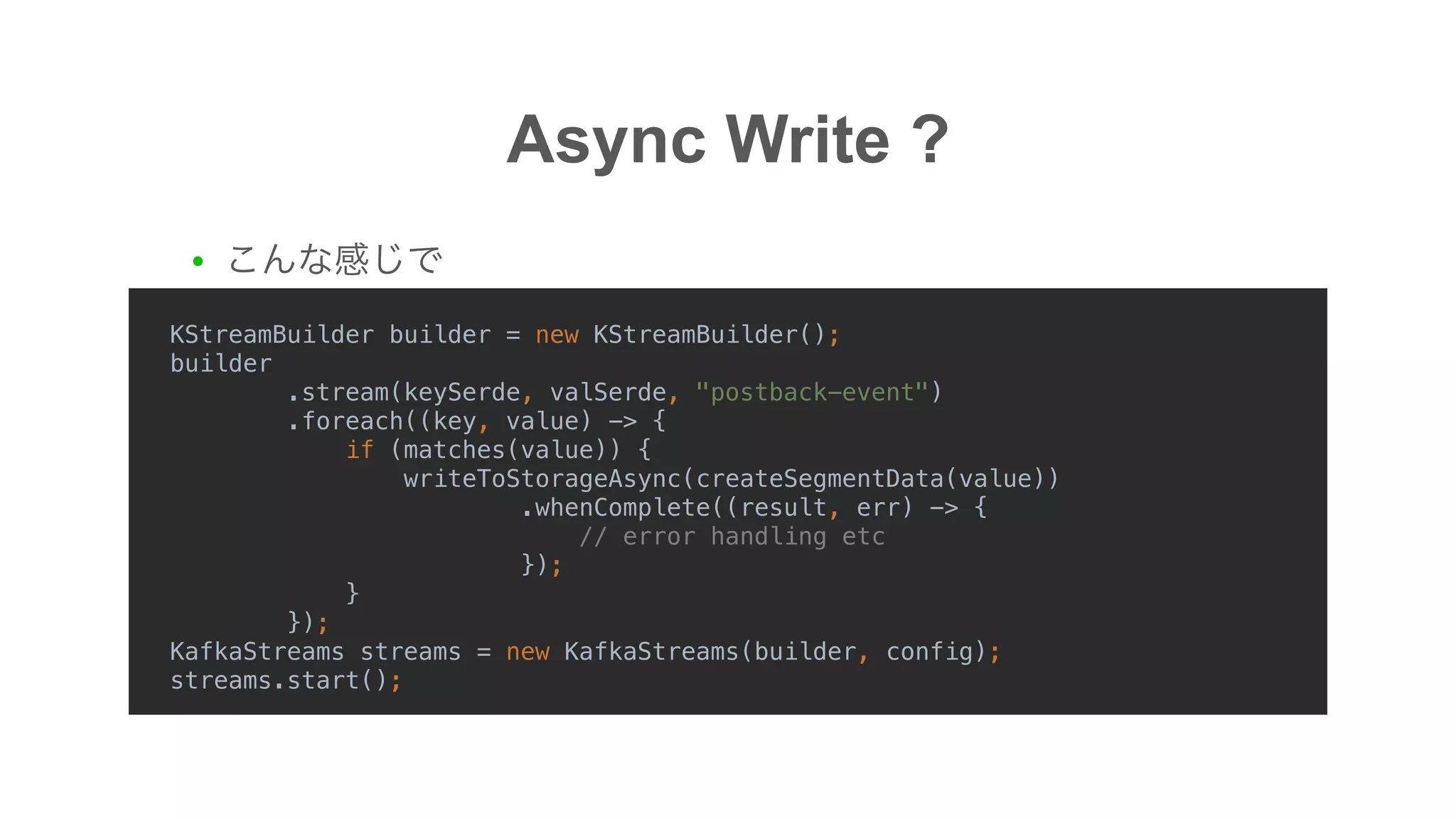
![Problem
● Data loss possibility
● 1. offset[3,4,5] message consume
● 2. HBase Kafka Streams offset commit
● 3. offset=4 record => Data loss](https://image.slidesharecdn.com/20181218kafkameetupokada-181218092708/75/I-O-intensive-Kafka-Consumer-LINE-Ads-Platform-12-2048.jpg)



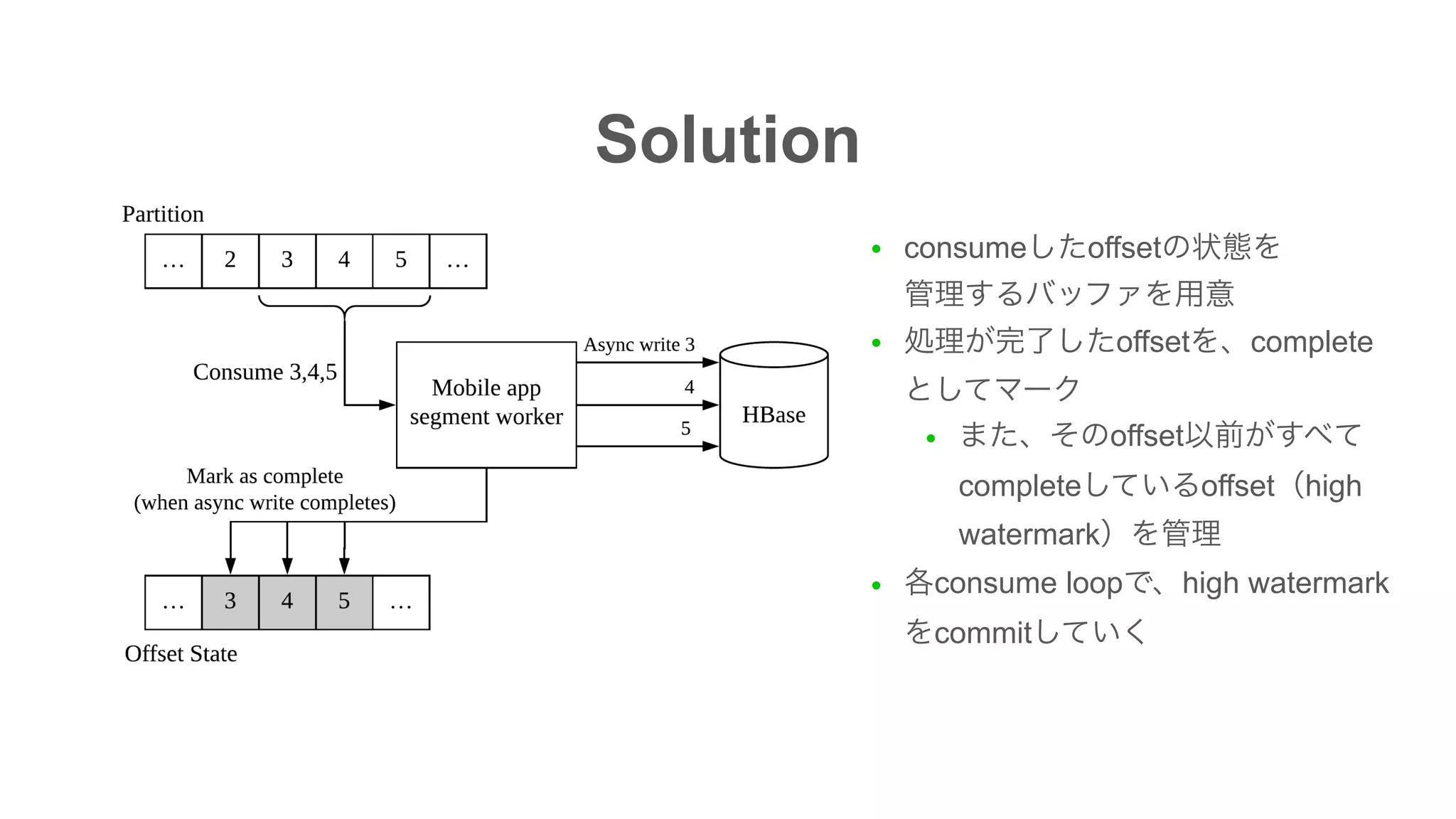
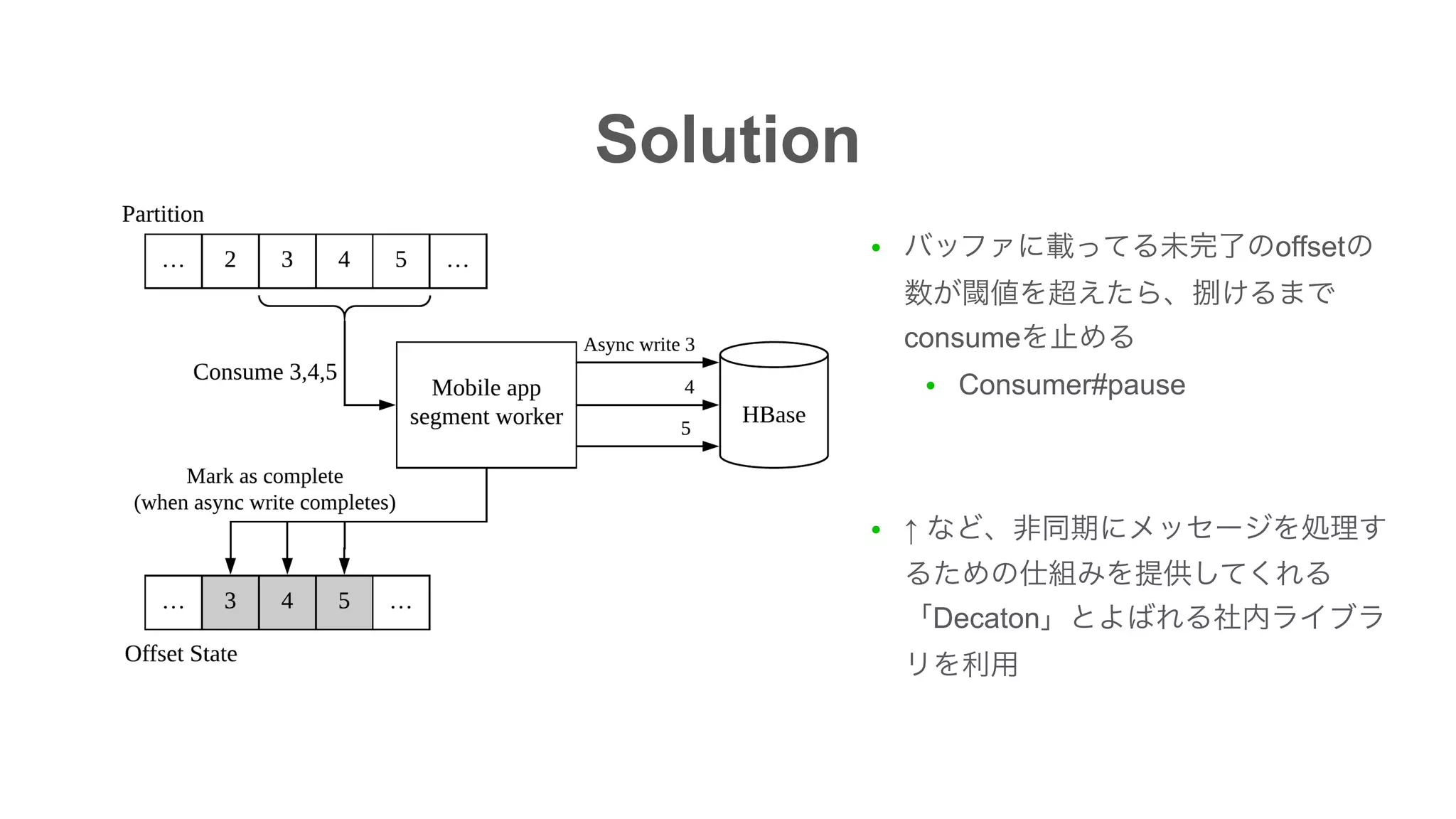


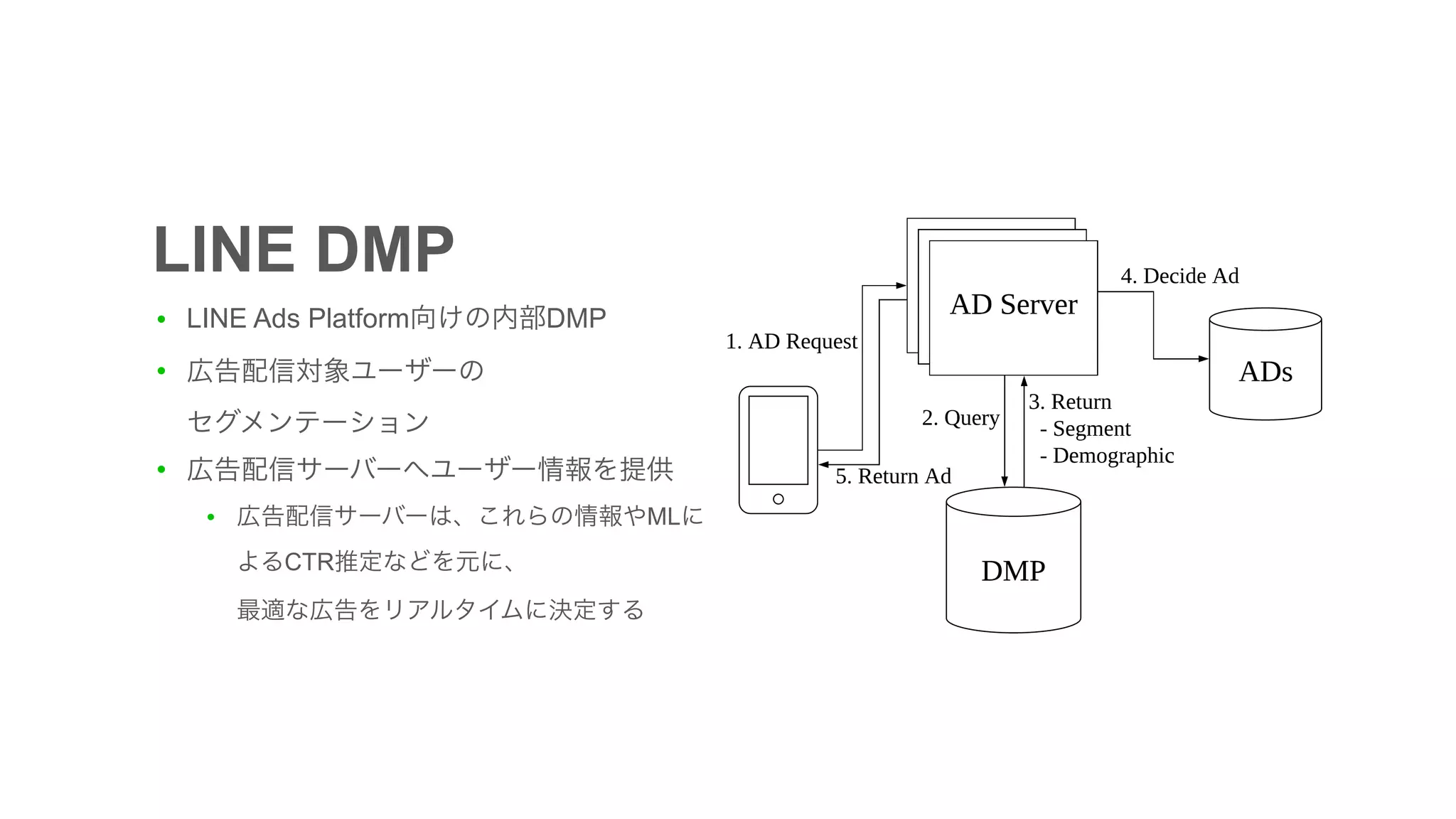
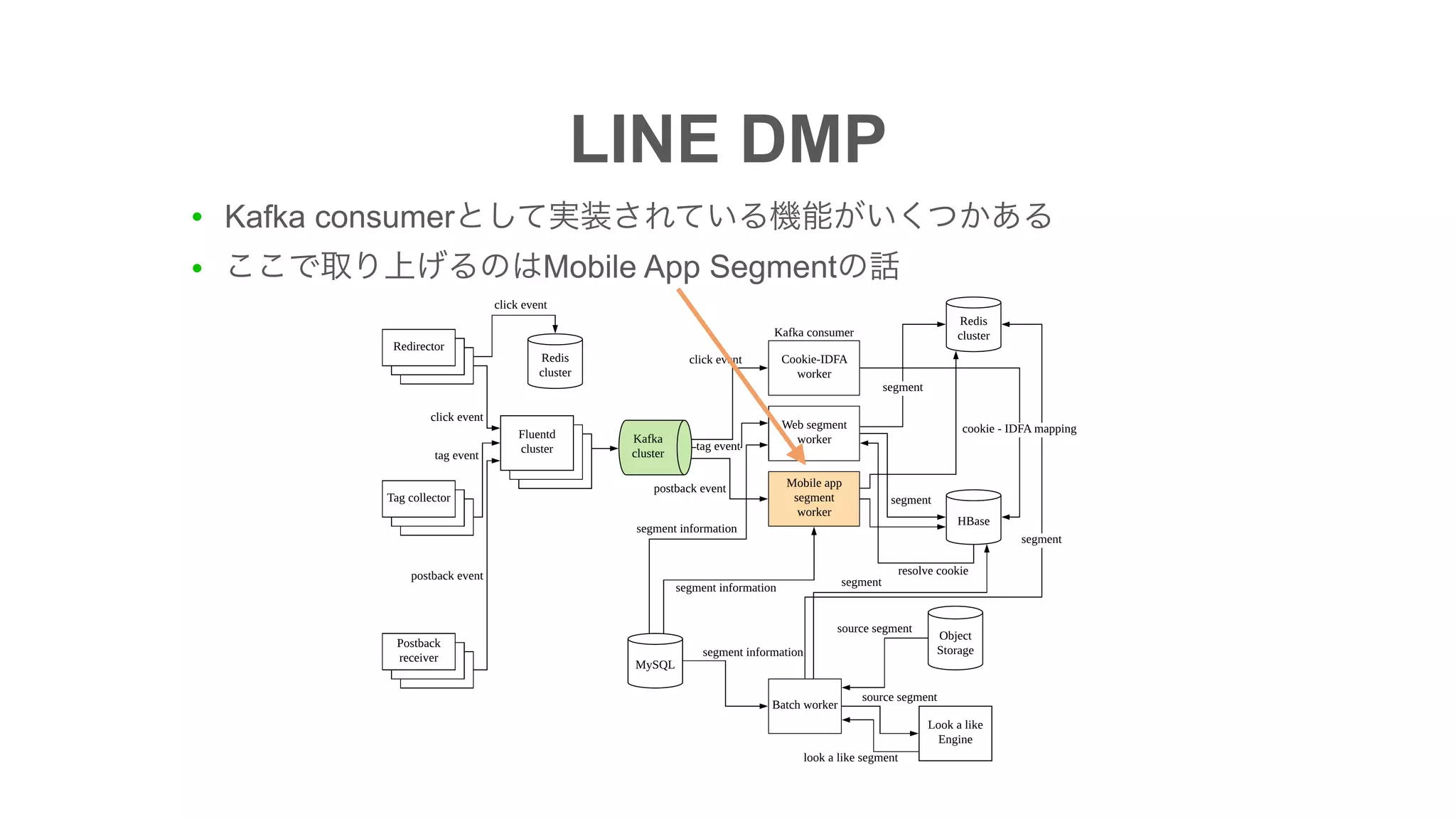
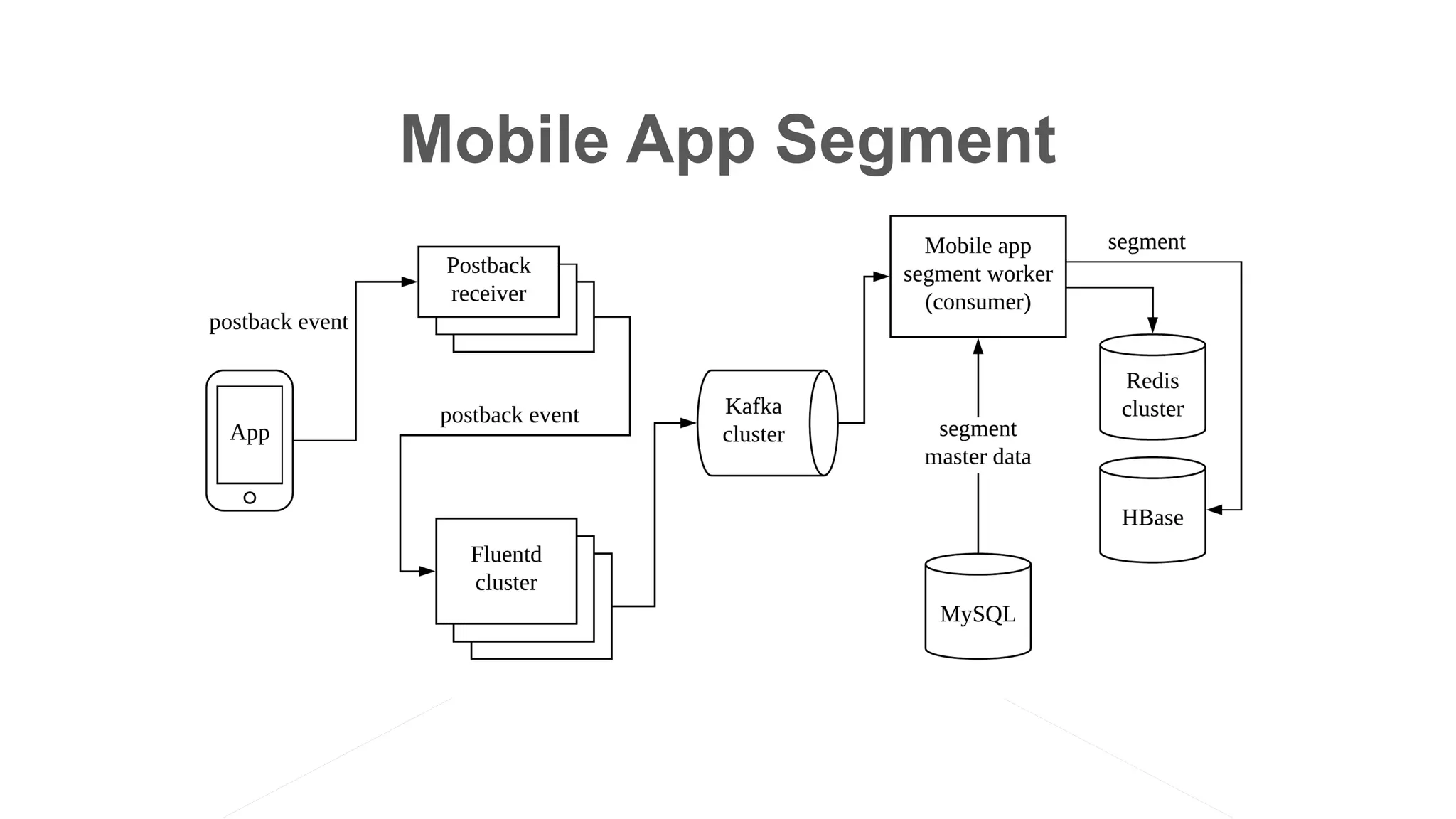
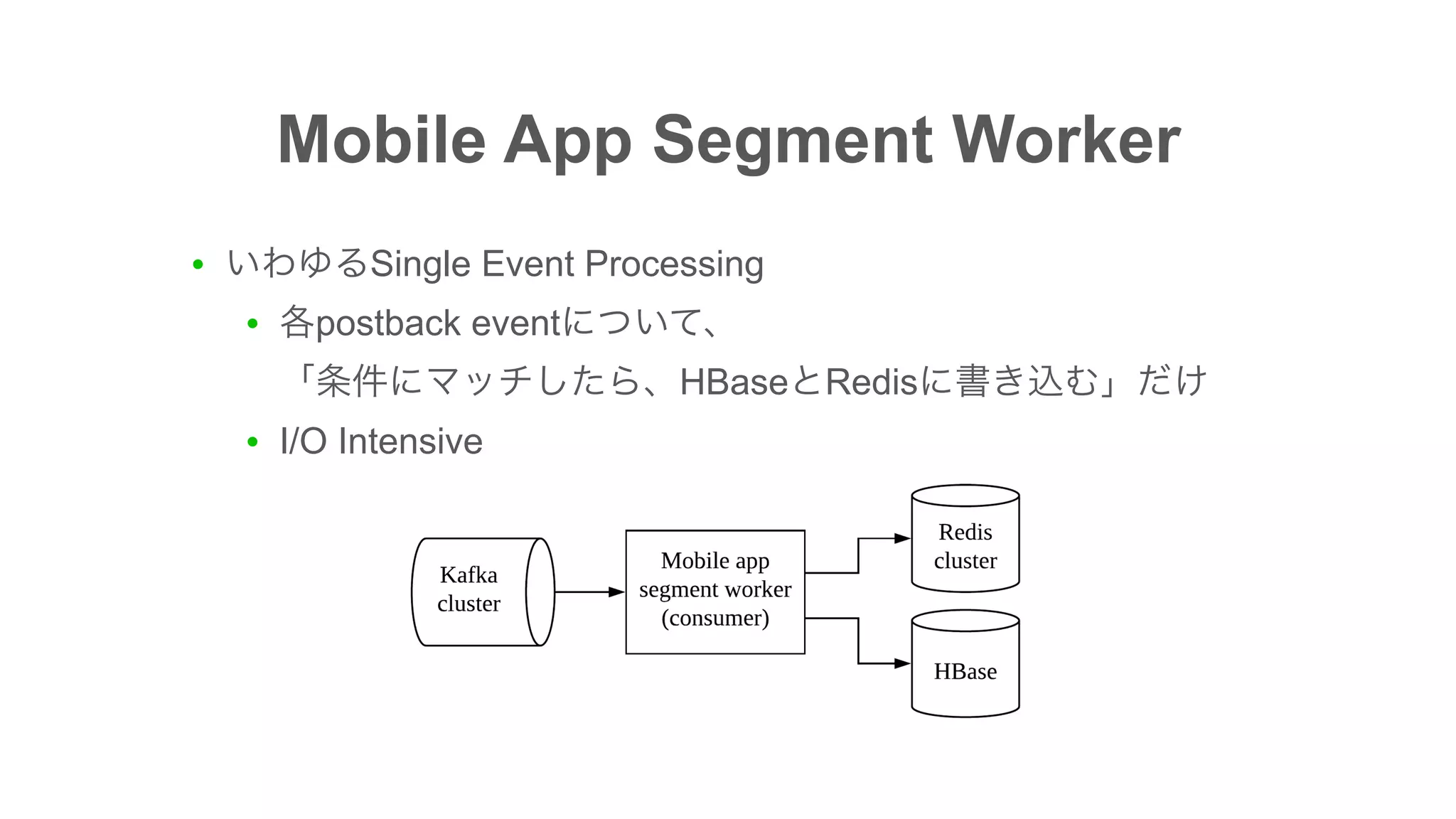
The document discusses the implementation of an I/O intensive Kafka consumer for the Line Ads platform, focusing on mobile app segment processing using Kafka Streams. It addresses various challenges such as data loss and throughput issues, proposing solutions like partitioning and asynchronous writing to storage. Additionally, it highlights the architecture of the Kafka cluster that handles a significant volume of daily messages.


































































