Download as PDF, PPTX

























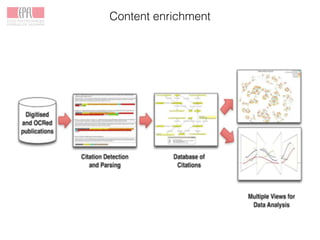
![Content enrichment
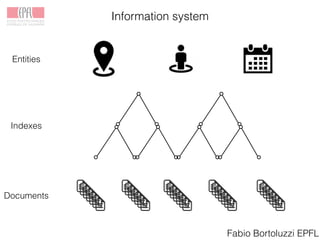
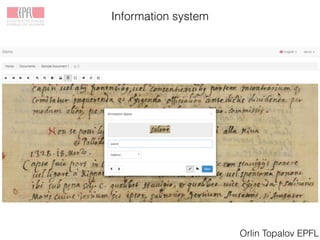
Linked Books Project
EPFL, Ca’ Foscari, Marciana
FNS funded
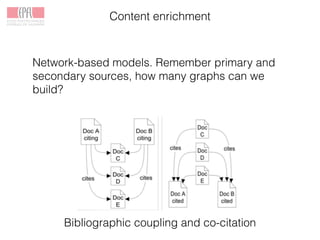
Approx. half of the citations in humanities are to primary
sources [Wiberley (2009)].
Their use has hardly ever been studied with citation analytic
methods.
Network effects: directly link scholarship with primary sources.](https://image.slidesharecdn.com/colavizza-padua-150608201313-lva1-app6892/85/Introduction-to-the-Venice-Time-Machine-35-320.jpg)















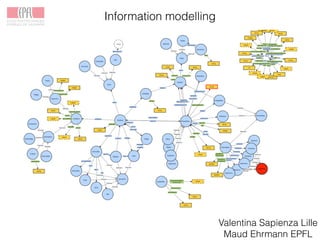
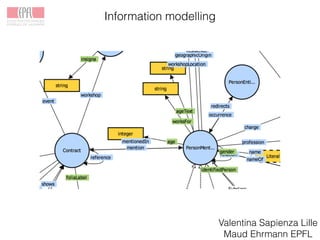
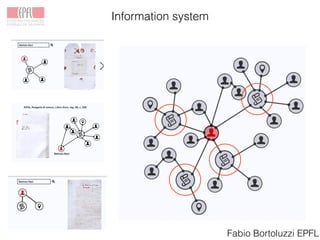
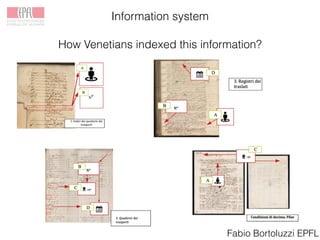
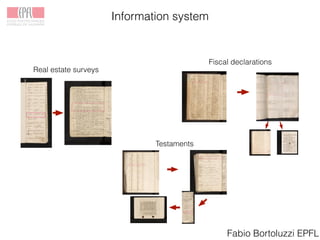
The Venice Time Machine aims to digitally preserve and provide access to historical documents from Venice through various projects. These include digitizing documents using tomography, developing tools to extract text from images, modeling the information and relationships within documents, building an information system to allow searching across documents, linking documents to related scholarship to enrich the content, and creating digital experiences to promote research and teaching. The goal is to make the historical record of Venice available while ensuring long-term preservation, and to demonstrate the value of digital humanities approaches and tools.




























































