Download to read offline













![2020
Example 2
document key: route_55758
{
"airlineid": "airline_5209",
"destinationairport": "ORD",
"distance": 1050.394306634423,
"equipment": "ER4 ERJ",
"schedule": [
{ "day": 0, "flight": "UA479", "utc": "15:05:00" },
{ "day": 1, "flight": "UA842", "utc": "02:27:00" },
{ "day": 1, "flight": "UA252", "utc": "03:00:00" },
// ... etc ...
],
"sourceairport": "CMH",
"stops": 0,
"type": "route"
}](https://image.slidesharecdn.com/introsqlplusplus-allthingsopen-october2019-191022134224/85/Introduction-to-SQL-for-Big-Data-Same-Language-More-Power-19-320.jpg)












![4040
Superpower: arrays
key 1
{
"name" : "matt",
"favoriteFoods" : [
"pizza",
"cheesecake",
"donuts"
]
}
key 2
{
"name" : "emma",
"favoriteFoods" : [
"donuts",
"Lucky Charms",
"chicken"
]
}
SELECT favoriteFoods[1]
FROM myusers
myusers](https://image.slidesharecdn.com/introsqlplusplus-allthingsopen-october2019-191022134224/85/Introduction-to-SQL-for-Big-Data-Same-Language-More-Power-39-320.jpg)
![4242
Superpower: Quantification
key 1
{
"name" : "matt",
"favoriteFoods" : [
"pizza",
"cheesecake",
"donuts"
]
}
key 2
{
"name" : "emma",
"favoriteFoods" : [
"donuts",
"Lucky Charms",
"chicken"
]
}
SELECT u.name
FROM myusers u
WHERE ANY f
IN u.favoriteFoods
SATISFIES f == 'pizza'
END;
myusers](https://image.slidesharecdn.com/introsqlplusplus-allthingsopen-october2019-191022134224/85/Introduction-to-SQL-for-Big-Data-Same-Language-More-Power-40-320.jpg)

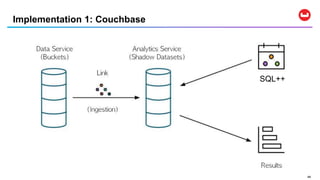

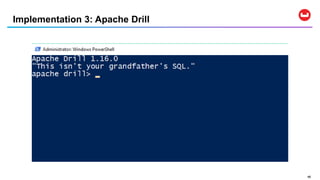
















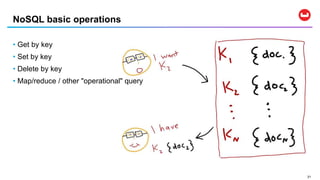
SQL++ is a query language that extends SQL to enable analytics on NoSQL data stored in JSON documents. It allows SQL queries to be run directly on JSON data without requiring an ETL process to move data into a relational database first. SQL++ supports features like querying nested objects and arrays in documents as well as aggregation functions. Several database systems like Couchbase, AsterixDB, and Apache Drill support SQL++.
























![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)


