
Download as PDF, PPTX
















![//compute the sum of tw o arrays in parallel
#include < stdio.h >
#include < mpi.h >
#define N 1000000
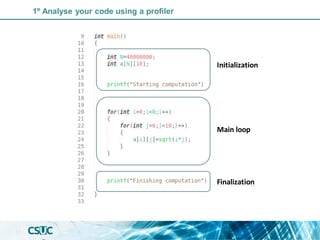
int main(void) {
MPI_Init(NULL, NULL);
int w orld_size,w orld_rank;
MPI_Comm_size(MPI_COMM_WORLD, &w orld_size);
MPI_Comm_rank(MPI_COMM_WORLD, &w orld_rank);
int Ni=N/w orld_size; //Be carefull w ith the memory....
if (w orld_rank==0)
{float a[N], b[N], c[N];}
else{float a[Ni], b[Ni], c[Ni];}
int i;
/* Initialize arrays a and b */
for (i = 0; i < Ni; i++) {
a[i] = i * 2.0;
b[i] = i * 3.0;
}
/* Compute values of array c = a+b in parallel. */
for (i = 0; i < Ni; i++){
c[i] = a[i] + b[i]; }
MPI_Gather( a, Ni, MPI_Int, a, int recv_count, MPI_Int, 0,
MPI_COMM_WORLD);
MPI_Gather(b, Ni, MPI_Int, b, int recv_count, MPI_Int, 0,
MPI_COMM_WORLD);
MPI_Gather( c, Ni, MPI_Int,c, int recv_count, MPI_Int, 0,
MPI_COMM_WORLD);
MPI_Finalize();}
//compute the sum of tw o arrays in parallel
#include < stdio.h >
#include < omp.h >
#define N 1000000
int main(void) {
float a[N], b[N], c[N];
int i;
/* Initialize arrays a and b */
for (i = 0; i < N; i++) {
a[i] = i * 2.0;
b[i] = i * 3.0;
}
/* Compute values of array c = a+b in parallel. */
#pragma omp parallel shared(a, b, c) private(i)
{
#pragma omp for
for (i = 0; i < N; i++) {
c[i] = a[i] + b[i];
}
}
}
Tips & Tricks: Programming hints(memory optimizations)](https://image.slidesharecdn.com/parallelization-1-221220122200-2be7b2cd/85/Introduction-to-Parallelization-and-performance-optimization-19-320.jpg)

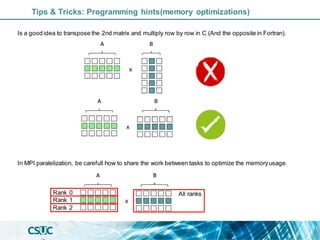




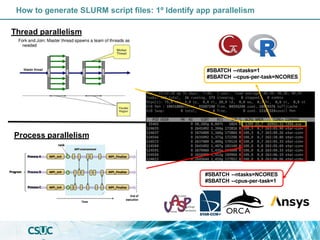

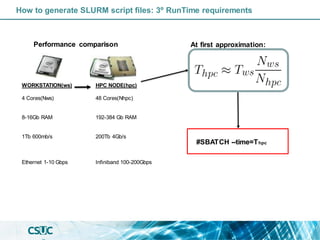
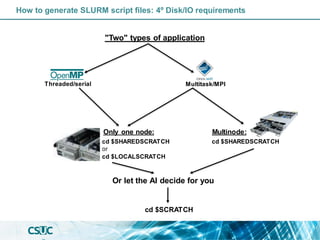

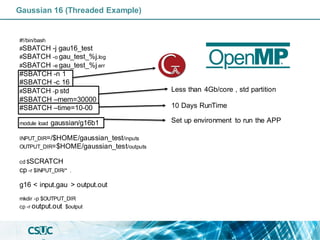
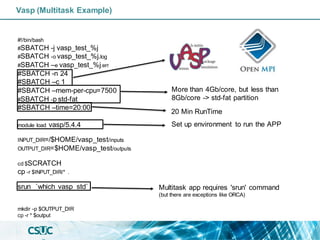




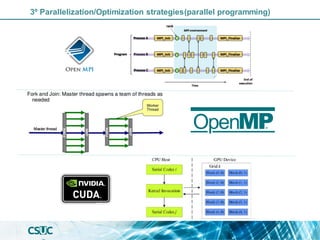
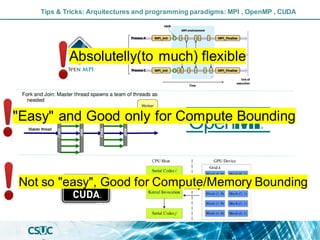
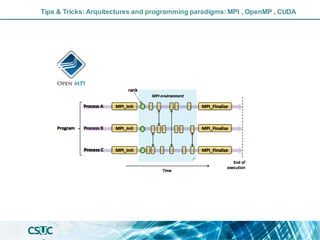
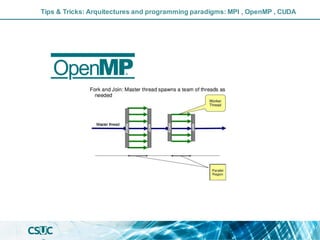
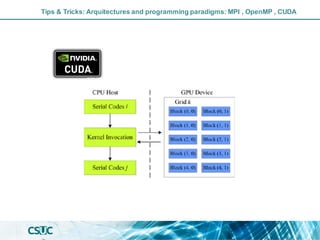

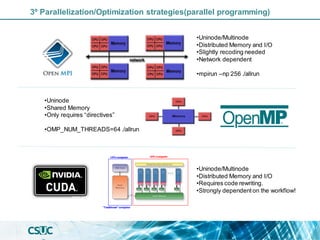
The document discusses parallelization and performance optimization for computational tasks, emphasizing the need to analyze code using profilers to identify bottlenecks in compute, memory, or I/O performance. It outlines strategies for optimizing code, such as utilizing parallel libraries and programming paradigms like OpenMP and MPI. Additionally, it provides tips for efficient resource management and SLURM job submission scripts, highlighting best practices for improving runtime and resource utilization.



































































