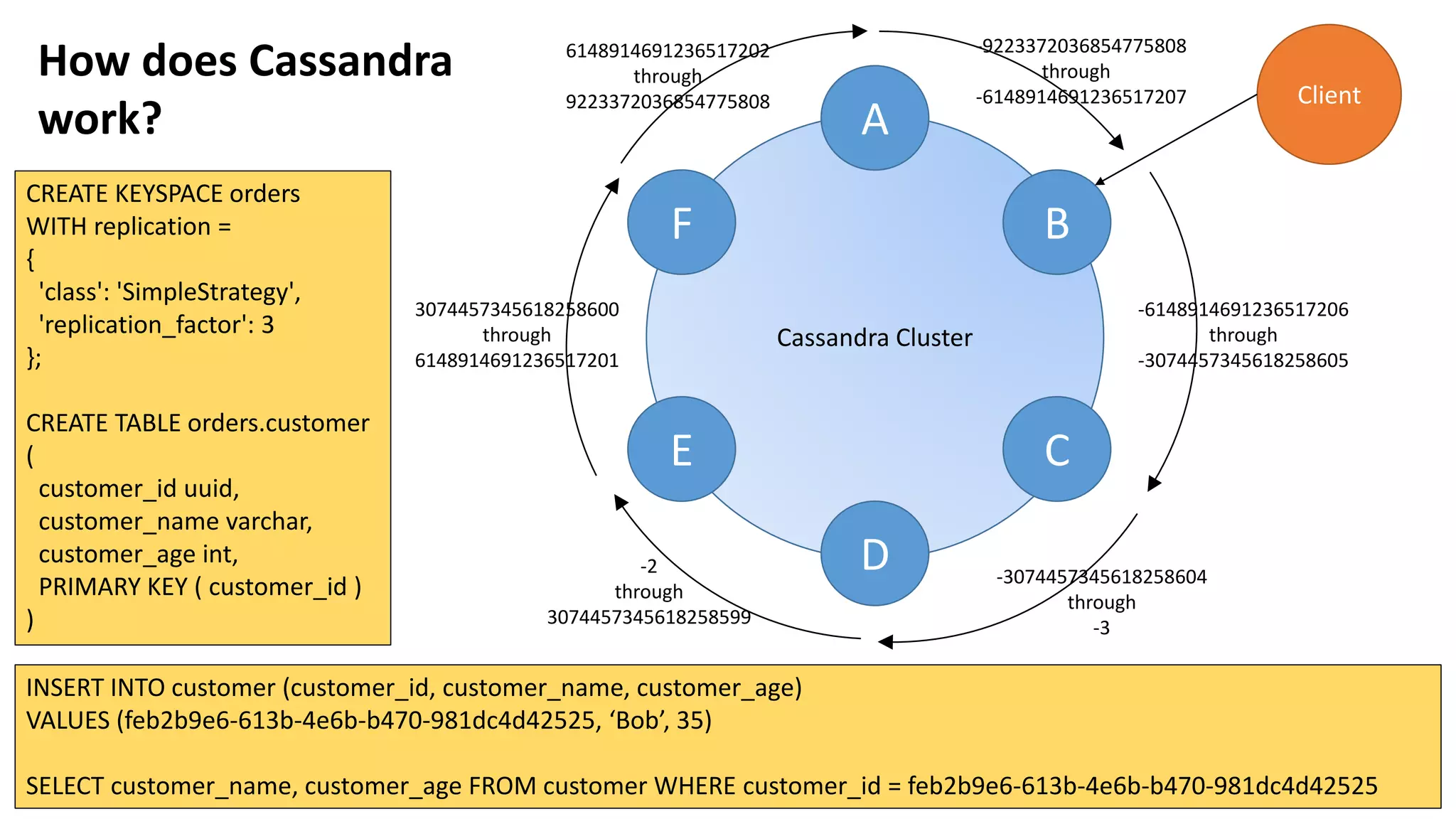
Jim Hatcher gave a presentation on introducing data modeling with Apache Cassandra. He discussed how Cassandra works by distributing data across nodes and replicating data. He also covered CQL for querying Cassandra, embracing denormalization in data modeling, using an appropriate key structure, and some advanced Cassandra techniques. The presentation provided an overview of modeling data in Cassandra and resources for further learning.