Downloaded 11 times



























![208 | P a g e
Firewalls
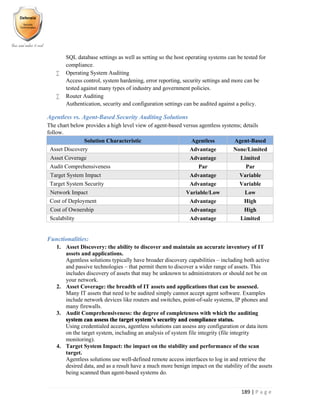
Understanding Firewalls (1, 2, 3, 4, 5 generations)
A firewall is a device or set of devices designed to permit or deny network transmissions based upon a set
of rules and is frequently used to protect networks from unauthorized access while permitting legitimate
communications to pass.
Many personal computer operating systems include software-based firewalls to protect against threats from
the public Internet. Many routers that pass data between networks contain firewall components and,
conversely, many firewalls can perform basic routing functions.
First generation: packet filters
The first paper published on firewall technology was in 1988, when engineers from Digital Equipment
Corporation (DEC) developed filter systems known as packet filter firewalls. This fairly basic system was
the first generation of what became a highly involved and technical internet security feature. At AT&T Bell
Labs, Bill Cheswick and Steve Bellovin were continuing their research in packet filtering and developed a
working model for their own company based on their original first generation architecture.
Packet filters act by inspecting the "packets" which transfer between computers on the Internet. If a packet
matches the packet filter's set of rules, the packet filter will drop (silently discard) the packet, or reject it
(discard it, and send "error responses" to the source).
This type of packet filtering pays no attention to whether a packet is part of an existing stream of traffic
(i.e. it stores no information on connection "state"). Instead, it filters each packet based only on information
contained in the packet itself (most commonly using a combination of the packet's source and destination
address, its protocol, and, for TCP and UDP traffic, the port number).
TCP and UDP protocols constitute most communication over the Internet, and because TCP and UDP
traffic by convention uses well known ports for particular types of traffic, a "stateless" packet filter can
distinguish between, and thus control, those types of traffic (such as web browsing, remote printing, email
transmission, file transfer), unless the machines on each side of the packet filter are both using the same
non-standard ports.
Packet filtering firewalls work mainly on the first three layers of the OSI reference model, which means
most of the work is done between the network and physical layers, with a little bit of peeking into the
transport layer to figure out source and destination port numbers.[8]
When a packet originates from the
sender and filters through a firewall, the device checks for matches to any of the packet filtering rules that
are configured in the firewall and drops or rejects the packet accordingly. When the packet passes through
the firewall, it filters the packet on a protocol/port number basis (GSS). For example, if a rule in the
firewall exists to block telnet access, then the firewall will block the TCP protocol for port number 23.](https://image.slidesharecdn.com/implementingandauditingsecuritycontrols-part2-170328164334/85/Implementing-and-auditing-security-controls-part-2-36-320.jpg)




































![246 | P a g e
1. The resulting EPS is the PE or NE depending upon whether we began with peak activity
or normal activity. Once we have completed this computation for every device needing
security information event management, we can insert the resulting numbers in the
formula below to determine Normal EPS and Peak EPS totals for a benchmark
requirement.
Formula 2:
1. In your production environment determine the peak number of security events (PEx)
created by each device that requires logging using Formula1. (If you have identical
devices with identical hardware, configurations, load, traffic, etc., you may use this
formula to avoid having to determine PE for every device):
2. [PEx (# of identical devices)]
Sum all PE numbers to come up with a grand total for your environment
3. 3. Add at least 10% to the Sum for headroom and another 10% for growth.
So, the resulting formula looks like this:
Step 1: (PE1+PE2+PE3...+ (PE4 x D4) + (PE5 x D5)...) = SUM1 [baseline PE]
Step 2: SUM1 + (SUM1 x 10%) = SUM2 [adds 10% headroom]
Step 3: SUM2 + (SUM2 x 10%) = Total PE benchmark requirement [adds 10% growth
potential]
Once these computations are complete, the resulting Peak EPS set of numbers will reflect that
grand, but impractical, peak total mentioned above. Again, it is unlikely that all devices will ever
simultaneously produce log events at maximum rate. Seek consultation from SMEs and the
system engineers provided by the vendor in order to establish a realistic Peak EPS that the SIEM
system must be able to handle, and then set filters for getting required event information through
to SIEM analysis, should an overload occur.
We have used these equations to evaluate a hypothetical mid-market network with a set number
of devices. If readers have a similar infrastructure, similar rates may apply. If the organization is
different, the benchmark can be adjusted to fit organizational infrastructures using our equations.
The Baseline Network
A mid-sized organization is defined as having 500–1000 users, according to a December guide by
Gartner, Inc., titled “Gartner’s New SMB Segmentation and Methodology.” Gartner Principal
Analyst Adam Hils, together with a team of Gartner analysts, helped us determine that a 750–
1000 user organization is a reasonable base point for our benchmark. As Hils puts it, this number
represents some geo and technical diversity found in large enterprises without being too complex
to scope and benchmark.
With Gartner’s advice, we set our hypothetical organization to have 750 employees, 750 user end
points, five offices, six subnets, five databases, and a central data center. Each subnet will have](https://image.slidesharecdn.com/implementingandauditingsecuritycontrols-part2-170328164334/85/Implementing-and-auditing-security-controls-part-2-74-320.jpg)






















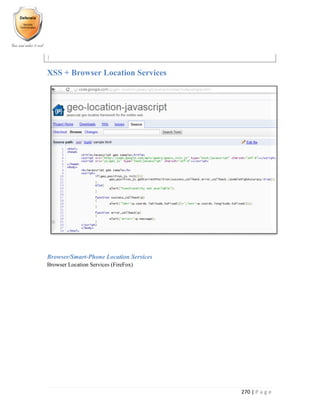












![283 | P a g e
Bypassing Web Application Firewalls
There is no single ideal system in the world, and this applies to Web application firewalls too
(WAF’s).
While the advantages and positive features far outweigh the negative in WAF’s, one major
problem is there are only a few action rules allowed. The white list is expanding, and requires
more development efforts because it is very important to clearly establish allowed parameters.
The second major problem is that sometimes WAF vendors fail to update their signature
definitions, or do not develop the required security rule on time, and this can put the web server at
risk of attacks.
The first vulnerability is (http://www.security-database.com/detail.php?alert=CVE-2009-1593),
which allows the inserting extra characters in the JavaScript close tag to bypass the XSS
protection mechanisms. An example is shown below:
http://testcases/phptest/xss.php?var=%3Cscript%3Ealert(document.cookie)%3C/script%20ByPas
s%3
Another example (http://www.security-database.com/detail.php?alert=CVE-2009-1594) also
allows remote attackers to bypass certain protection mechanisms via a %0A (encoded newline),
as demonstrated by a %0A in a cross-site scripting (XSS) attack URL.
HTTP Parameter Pollution (HPP)
HPP was first developed by two Italian network experts, Luca Carettoni and Stefano diPaola.
HPP provides an attacker the ability to submit new HTTP-parameters (POST, GET) with multiple
input parameters (query string, post data, cookies, etc.) with same name.
The application may react in unexpected ways and open up new avenues of server-side and
client-side exploitation. The most outstanding example is a vulnerability in IIS + ModSecurity
which allows SQL-injection based attacks on two features:
1. IIS HTTP parameters submit the same name. for Example:
POST /index.aspx?a=1&a=2 HTTP/1.0
Host: www.example.com
Cookie: a=5;a=6
Content-type: text/plain
Content-Length: 7
Connection: close
a=3&a=4
If such a request to IIS/ASP.NET setting a (Request.Params["a"]) is equal to 1,2,3,4,5,6.
2. ModSecurity analyzes the request after that it has been already processed by webserver. And
reject it: http://testcases/index.aspx?id=1+UNION+SELECT+username,password+FROM+users
However the query submitted:](https://image.slidesharecdn.com/implementingandauditingsecuritycontrols-part2-170328164334/85/Implementing-and-auditing-security-controls-part-2-111-320.jpg)









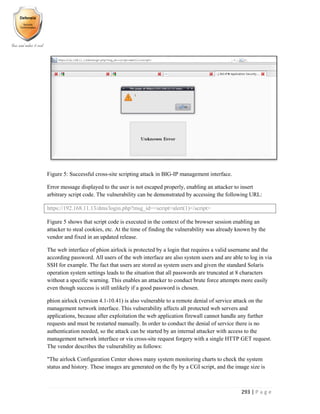



















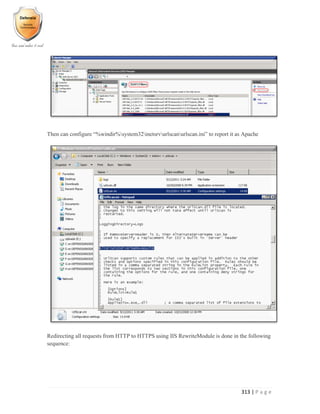













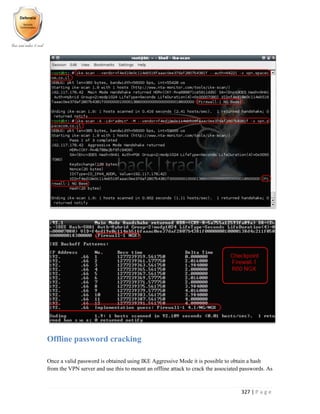



![331 | P a g e
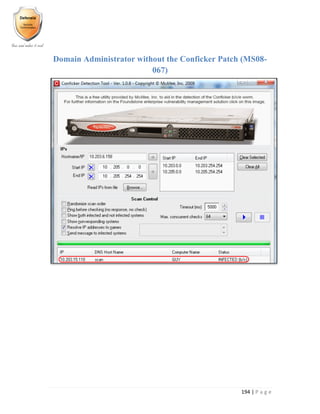
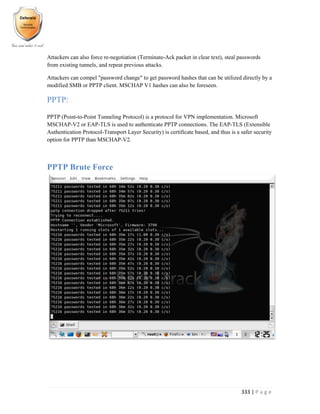
VPN PPTP User Enumeration
Allow remote user access through the use of the PPTP VPN service. When enabled this can
normally be detected remotely through the presence of an open TCP port (1723) and the device s
acceptance of the GRE protocol (IP protocol number 47).
The PPTP VPN service uses MS-CHAPv2 for authentication. This relies on a challenge/response
mechanism in order to successfully authenticate users. When a remote user attempts to
authenticate with the PPTP VPN service, an MS-CHAPv2 packet should be returned indicating
success or failure. Failure is indicated by the return of a code 4 MS-CHAPv2 packet. This packet
will additionally contain a value in the form E=<error_number> which indicates the type of error
that occurred. A list of common error codes is given below: -
646 ERROR_RESTRICTED_LOGON_HOURS
647 ERROR_ACCT_DISABLED
648 ERROR_PASSWD_EXPIRED
649 ERROR_NO_DIALIN_PERMISSION
691 ERROR_AUTHENTICATION_FAILURE
709 ERROR_CHANGING_PASSWORD
The vulnerability occurs as a consequence of differences in the error codes returned in the failure
packet which are dependent on whether or not the username supplied is valid. When a valid
username is given with an incorrect password the following response is returned: -
sent [LCP ConfReq id=0x1 <asyncmap 0x0> <magic 0x444fc9b9> <accomp>]
rcvd [LCP ConfReq id=0x1 <mru 338> <auth chap MS-v2> <magic 0xfa52b227> <pcomp>
<accomp>]
sent [LCP ConfRej id=0x1 <pcomp>]
rcvd [LCP ConfRej id=0x1 <asyncmap 0x0>]
sent [LCP ConfReq id=0x2 <magic 0x444fc9b9> <accomp>]
rcvd [LCP ConfReq id=0x2 <mru 338> <auth chap MS-v2> <magic 0xfa52b227> <accomp>]
sent [LCP ConfAck id=0x2 <mru 338> <auth chap MS-v2> <magic 0xfa52b227> <accomp>]
rcvd [LCP ConfAck id=0x2 <magic 0x444fc9b9> <accomp>]
sent [LCP EchoReq id=0x0 magic=0x444fc9b9]
rcvd [CHAP Challenge id=0x1 <d15340ea7112ac46f240e4f18fe2a278>, name = "watchguard"]
sent [CHAP Response id=0x1
<73469ca9bed04ea6f0e5d1be49b47a1a0000000000000000f424ac68e12
31f756e1657a2bc25efcd3b7ba78110bcf48201>, name = "valid_username"]
rcvd [LCP EchoRep id=0x0 magic=0xfa52b227]
rcvd [CHAP Failure id=0x1 "E=691 R=1 Try again"]
MS-CHAP authentication failed: E=691 Authentication failure
CHAP authentication failed](https://image.slidesharecdn.com/implementingandauditingsecuritycontrols-part2-170328164334/85/Implementing-and-auditing-security-controls-part-2-159-320.jpg)
![332 | P a g e
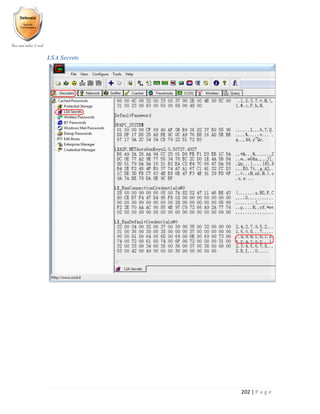
However, when an invalid username is supplied, the following response is received: -
sent [LCP ConfReq id=0x1 <asyncmap 0x0> <magic 0x9689f323> <accomp>]
rcvd [LCP ConfReq id=0x1 <mru 338> <auth chap MS-v2> <magic 0x245cdcee> <pcomp>
<accomp>]
sent [LCP ConfRej id=0x1 <pcomp>]
rcvd [LCP ConfRej id=0x1 <asyncmap 0x0>]
sent [LCP ConfReq id=0x2 <magic 0x9689f323> <accomp>]
rcvd [LCP ConfReq id=0x2 <mru 338> <auth chap MS-v2> <magic 0x245cdcee> <accomp>]
sent [LCP ConfAck id=0x2 <mru 338> <auth chap MS-v2> <magic 0x245cdcee> <accomp>]
rcvd [LCP ConfAck id=0x2 <magic 0x9689f323> <accomp>]
sent [LCP EchoReq id=0x0 magic=0x9689f323]
rcvd [CHAP Challenge id=0x1 <d15340ea7112ac46f240e4f18fe2a278>, name = "watchguard"]
sent [CHAP Response id=0x1
<73469ca9bed04ea6f0e5d1be49b47a1a0000000000000000f424ac68e12
31f756e1657a2bc25efcd3b7ba78110bcf48201>, name = "invalid_username"]
rcvd [LCP EchoRep id=0x0 magic=0x245cdcee]
rcvd [CHAP Failure id=0x1 "E=649 R=1 Try again"]
MS-CHAP authentication failed: E=649
CHAP authentication failed
VPN Clients Man-In-The-Middle Downgrade Attacks
Downgrade Attacks - IPSEC Failure
MITM attackers may impede the key material exchanged on UDP Port 500 to deceive the victims
into thinking that an IPSEC connection cannot start on the other side. That would result in the
clear text stream over the connection without being noticed if the victim host is configured in
rollback mode.
Downgrade Attacks – PPTP
During the protocol negotiation phase at the beginning of a PPTP session, MITM attackers may
force the victims to use the less secure PAP authentication, MSCHAP V1 (i.e., downgrading from
MSCHAP V2), and even no encryption at all.](https://image.slidesharecdn.com/implementingandauditingsecuritycontrols-part2-170328164334/85/Implementing-and-auditing-security-controls-part-2-160-320.jpg)











This document describes the main functionalities and benefits of a network inventory management system. The key functionalities include real-time tracking of unmanaged devices, detailed hardware and software inventory information, history tracking of changes to inventory objects, auto-discovery and reconciliation to keep inventory up-to-date, network planning capabilities, and inventory-based billing. Benefits include an end-to-end view of networks, reduced operating costs, improved resource utilization, efficient change management, and seamless integration.