IJEEE - HEAVY VEHICLE FUEL EFFICIENCY PREDICTION USING MACHINE LEARNING.pdf
1.
A MAJOR PROJECTREPORT
ON
“HEAVY VEHICLE FUEL EFFICIENCY PREDICTION USING
MACHINE LEARNING”
Submitted to
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
In partial fulfillment of the requirements for the award of degree of
BACHELOR OF TECHNOLOGY
IN
COMPUTER SCIENCE AND ENGINEERING
Submitted
By
N. SOUJANYA [20D41A05E6]
P. JAGADEESH [20D41A05G5]
P. NARESH [20D41A05G3]
M.NAGARAJU [20D41A05C4]
Under the esteemed guidance of
Mr. K. VIJAY KUMAR
(Assistant Professor)
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
(An Autonomous Institution under UGC, Accredited by NBA, Affiliated to JNTUH)
Sheriguda (V), Ibrahimpatnam (M), Ranga Reddy Dist. – 501 510
(2023-2024)
2.
SRI INDU COLLEGEOF ENGINEERING AND TECHNOLOGY
(An Autonomous Institution under UGC, Accredited by NBA, Affiliated to JNTUH)
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
CERTIFICATE
Certified that the Major project entitled “HEAVY VEHICLE FUEL EFFICIENCY PREDICTION
USING MACHINE LEARNING” is a bonafide work carried out by N. SOUJANYA [20D41A05E6],
P.JAGADEESH [20D41A05G5], P.NARESH [20D41A05G3], M.NAGARAJU [20D41A05C4] in
partial fulfillment for the award of degree of Bachelor of Technology in Computer Science and
Engineering of SICET, Hyderabad for the academic year 2023-2024.The project has been approved as
it satisfies academic requirements in respect of the work prescribed for IV Year, II-Semester of B. Tech
course.
INTERNAL GUIDE HEAD OF THE DEPARTMENT
(Mr.K.VIJAY KUMAR) (Prof .CH.G.V.N.PRASAD)
(Assistant Professor)
EXTERNAL EXAMINER
3.
ACKNOWLEDGEMENT
The satisfaction thataccompanies the successful completion of the task would be put incomplete
without the mention of the people who made it possible, whose constant guidance and encouragement
crown all the efforts with success. We are thankful to Principal Dr. G. SURESH for giving us the
permission to carry out this project. We are highly indebted to Prof. CH.G.V.N.PRASAD, Head of
the Department of Computer Science and Engineering, for providing necessary infrastructure andlabs
and also valuable guidance at every stage of this project. We are grateful to our internal project guide
Mr.K.VIJAY KUMAR(Assistant Professor)for his constant motivation and guidance given by him
during the execution of this project work. We would like to thank the Teaching & Non-Teaching staff
of Department of ComputerScience and engineering for sharing their knowledge with us, last but not
least we express our sincere thanks to everyone who helped directly or indirectly for the completion of
this project.
N. SOUJANYA [20D41A05E6]
P. JAGADEESH [20D41A05G5]
P. NARESH [20D41A05G3]
M.NAGARAJU [20D41A05C4]
4.
iv
CONTENTS
S.NO CHAPTERS PAGENO
i. List of Figures ......................................................................... vii
ii. List of Screenshots.................................................................. viii
1. INTRODUCTION
1.1 INTRODUCTION TO PROJECT …………………..…... 2
1.2 LITERATURE SURVEY.................................................. 3
1.3 MODULES DESCRIPTION............................................. 4
2. SYSTEM ANALYSIS
2.1 EXISTING SYSTEM AND ITS DISADVANTAGES...... 5
2.2 PROPOSED SYSTEM AND ITS ADVANTAGES.......... 5
2.3 SYSTEM REQUIRMENTS
2.3.1 HARDWARE REQUIRMENTS………………….. 6
2.3.2 SOFTWARE REQUIRMENTS…………………… 7
3.SYSTEM STUDY
3.1 FEASIBILITY STUDY…………………………………… 8
4.SYSTEM DESIGN
4.1 SYSTEM ARCHITECHTURE............................................. 9
4.2 UML DIAGRAMS................................................................ 11
4.2.1 USECASE DIAGRAM................................................ 12
4.2.2 CLASS DIAGRAM.................................................... 13
4.2.3 SEQUENCE DIAGRAM............................................ 14
4.2.4 ACTIVITY DIAGRAM.............................................. 15
4.2.5 DEPLOYMENT DIAGRAM..................................... 16
4.2.6 DATA FLOW DIAGRAM………………………… 17
5. TECHONOLOGIES
5.1 INTRODUCTION TO PYTHON
5.1.1 ADVANTAGES AND DISADVANTAGES…….. 21
5.
v
5.2.1 HISTORY……………………………………… 22
5.2WHAT IS MACHINE LEARNING
5.2.1 CATEGORIES OF ML………………………….. 23
5.2.2 NEED FOR ML………………………………….. 23
5.2.3 CHALLENGES OF ML…………………………. 24
5.2.4 APPLICATIONS………………………………… 25
5.2.5 HOW TO START LEARNING ML…………….. 27
5.2.6 ADVANTAGES AND DISADVANTAGES…… 29
5.3 PYTHON DEVELOPMENT STEPS……………….. 30
5.4 MODULES USED IN PYTHON……………………. 33
5.5 INSTALLATION OF PYTHON……………………. 40
6 .IMPLEMENTATION
6.1 SOFTWARE ENVIRONMENT
6.1.1 PYTHON................................................................. 47
6.1.2 SOURCE CODE...................................................... 54
7. SYSTEM TESTNG
7.1 INTRODUCTION TO TESTING..................................... 56
7.2 TEST STRATEGIES......................................................... 58
8. SCREENSHOTS.................................................................... 66
9. CONCLUSION...................................................................... 67
10 REFERENCES..................................................................... 68
6.
vi
LIST OF FIGURES
FigNo Name Page No
4,2 Architecture diagram 11
4.2.1 Use case diagram 12
4.2.2 Class diagram 13
4.2.3 Sequence diagram 14
4.2.4 Activity Diagram 15
4.2.5 Deployment Diagram 16
4.2.6 Data Flow diagram 17
4.2.7 Installation of python 35
7.
LIST OF SCREENSHOTS
FigNo Name Page No
FIG-1 UPLOAD HEAVY VEHICLE DATA SET 62
FIG-2 READ DATASET AND GENERATE MODEL 63
FIG-3 RUN ANN ALGORITHM
63
FIG-4 UPLOAD TEST DATA
64
FIG-5 FUEL CONSUMPTION GRAPH
66
8.
ABSTRACT
This paper advocatesa data stigmatization approach based on distance rather than the traditional time
period when developing individualized machine learning models for fuel consumption. This approach is
used in conjunction with seven predictors derived from vehicle speed and road grade to produce a highly
predictive neural network model for average fuel consumption in heavy vehicles. The proposed model
can easily be developed and deployed for each individual vehicle in a fi fleet in order to optimize fuel
consumption over the entire fi fleet. The predictors of the model are aggregated over fi fixed window
sizes of distance traveled. Different window sizes are evaluated and the results show that a 1 km window
is able to predict fuel consumption with a 0.91 coefficient of determination and mean absolute peak-to-
peak percent error less than 4% for routes that include both city and highway duty cycle segments.
Ability to model and predict the fuel consumption is vital in enhancing fuel economy of vehicles and
preventing fraudulent activities in fleet management. Fuel consumption of a vehicle depends on several
internal factors such as distance, load, vehicle characteristics, and driver behavior, as well as external
factors such as road conditions, traffic, and weather. However, not all these factors may be measured or
available for the fuel consumption analysis. We consider a case where only a subset of the
aforementioned factors is available as a multi-variate time series from a long distance, public bus. Hence,
the challenge is to model and/or predict the fuel consumption only with the available data, while still
indirectly capturing as much as influences from other internal and external factors. Machine Learning
(ML) is suitable in such analysis, as the model can be developed by learning the patterns in data. In this
paper, we compare the predictive ability of three ML techniques in predicting the fuel consumption of
the bus, given all available parameters as a time series. Based on the analysis, it can be concluded that
the random forest technique produces a more accurate prediction compared to both the gradient boosting
and neural networks.
9.
1
1.INTRODUCTION
1.1 INTRODUCTION TOPROJECT
FUEL consumption models for vehicles are of interest to manufacturers, regulators, and consumers.They
are needed across all the phases of the vehicle life-cycle. In this paper, we focus on modeling average
fuel consumption for heavy vehicles during the operation and maintenance phase. In
general, techniques used to develop models for fuel consumption fall under three main
categories:Physics-based models, which are derived from an in-depth understanding of the physical
system. These models describe the dynamics of the components of the vehicle at each time step using
detailed mathematical equations.
Machine learning models, which are data-driven and represent an abstract mapping from an input space
consisting of a selected set of predictors to an output space that represents the target output, in this case
average fuel consumption Statistical models, which are also data-driven and establish a mapping between
the probability distribution of a selected set of predictors and the target outcomeTrade-offs among the
above techniques are primarily with respect to cost and accuracy as per the requirements of the intended
application.
In this paper, a model that can be easily developed for individual heavy vehicles in a large fleet is
proposed. Relying on accurate models of all of the vehicles in a fleet, a fleet manager can optimize the
route planning for all of the vehicles based on each unique vehicle predicted fuel consumption thereby
ensuring the route assignments are aligned to minimize overall fleet fuel consumption. These types of
fleets exist in various sectors including, road transportation of goods [7], public transportation [3],
construction trucks [8] and refuse trucks [9]. For each fleet, the methodology must apply and adapt to
many different vehicle technologies (including future ones) and configurations without detailed
knowledge of the vehicles specific physical characteristics and measurements. These requirements make
machine learning the technique of choice when taking into consideration the desired accuracy versus the
cost of the development and adaptation of an individualized model for each vehicle in the fleet.
Several previous models for both instantaneous and average fuel consumption have been proposed.
Physics-based models are best suited for predicting instantaneous fuel consumption [1], [2] because they
can capture the dynamics of the behavior of the system at different time steps. Machine learning models
are not able to predict instantaneous fuel consumption [3] with a high level of accuracy because of the
difficulty associated with identifying patterns in instantaneous data. However, these models are able to
identify and learn trends in average fuel consumption with an adequate level of accuracy
10.
2
reviously proposed machinelearning models for average fuel consumption use a set of predictors that are
collected over a time period to predict the corresponding fuel consumption in terms of either gallons per
mile or liters per kilometer. While still focusing on average fuel consumption, our proposed approach
differs from that used in previous models because the input space of the predictors is quantized with
respect to a fixed distance as opposed to a fixed time period. In the proposed model, all the predictors are
aggregated with respect to a fixed window that represents the distance traveled by the vehicle thereby
providing a better mapping from the input space to the output space of the model. In contrast, previous
machine learning models must not only learn the patterns in the input data but also perform a conversion
from the time-based scale of the input domain to the distance-based scale of the output domain (i.e.,
average fuel consumption). Using the same scale for both the input and output spaces of the model offers
several benefits:
Data is collected at a rate that is proportional to its impact on the outcome. When the input space is
sampled with respect to time, the amount of data collected from a vehicle at a stop is the same as the
amount of data collected when the vehicle is moving.
The predictors in the model are able to capture the impact of both the duty cycle and the environment on
the average fuel consumption of the vehicle (e.g., the number of stops in an urban traffic over a given
distance).
Data from raw sensors can be aggregated on-board into few predictors with lower storage and
transmission bandwidth requirements. Given the increase in computational capabilities of new vehicles,
data summarization is best performed on-board near the source of the data.
New technologies such as V2I and dynamic traffic management [10]–[12] can be leveraged for additional
fuel efficiency optimization at the level of each specific vehicle, route and time of day.
11.
3
1.2 LITERATURE SURVEY
"PredictiveModeling of Heavy-Duty Truck Fuel Consumption Using Road Grade and Engine
Load Data" by Wood et al. (2011):
This study focuses on predicting heavy-duty truck fuel consumption using machine learning techniques.
They employ data on road grade and engine load to build predictive models. Support Vector Regression
(SVR) and Artificial Neural Networks (ANN) were among the algorithms evaluated.
"Fuel Consumption Prediction of Heavy-Duty Vehicles Using Artificial Neural Network and
Genetic Algorithm" by Liu et al. (2015):
This paper proposes an approach based on Artificial Neural Networks (ANN) and Genetic Algorithms
(GA) to predict heavy-duty vehicle fuel consumption. They demonstrate the effectiveness of the
proposed method in accurately predicting fuel consumption under various operating conditions.
"Fuel Consumption Prediction of Heavy-Duty Vehicles Using Machine Learning Algorithms:
Gradient Boosting Decision Tree and Random Forest" by Li et al. (2017):
Li et al. compare the performance of Gradient Boosting Decision Tree (GBDT) and Random Forest (RF)
algorithms for predicting heavy-duty vehicle fuel consumption. They utilize data on vehicle speed, road
grade, and engine speed as input features. Their results show that both algorithms achieve high prediction
accuracy.
"Modeling of Heavy-Duty Vehicles Fuel Consumption Based on Support Vector Regression" by
Almeida et al. (2018):
Almeida et al. propose the use of Support Vector Regression (SVR) for modeling heavy-duty vehicle
fuel consumption. They experiment with different kernel functions and regularization parameters to
optimize the SVR model. Their results indicate that SVR performs well in predicting fuel consumption.
"Predicting Fuel Consumption of a Heavy-Duty Vehicle Using Artificial Neural Network" by Wan
et al. (2019):
This study investigates the application of Artificial Neural Networks (ANN) for predicting heavy-duty
vehicle fuel consumption. They analyze various factors such as vehicle speed, engine load, and road
gradient to develop an accurate prediction model. The ANN model demonstrates promising results.
12.
4
"Fuel Consumption Predictionfor Heavy-Duty Vehicles Based on Long Short-Term Memory
Neural Network" by Li et al. (2020):
Li et al. propose the use of Long Short-Term Memory (LSTM) neural networks for predicting fuel
consumption in heavy-duty vehicles. LSTM networks are well-suited for modeling sequential data,
making them effective for capturing temporal dependencies in fuel consumption patterns. Experimental
results show that LSTM-based models outperform traditional machine learning approaches.
"Predicting Fuel Consumption in Heavy-Duty Vehicles Using Machine Learning Techniques: A
Comparative Study" by Garcia et al. (2021):
Garcia et al. conduct a comparative study of various machine learning techniques for predicting fuel
consumption in heavy-duty vehicles. They compare the performance of algorithms such as Random
Forest, Gradient Boosting, and Support Vector Regression. Their findings provide insights into the
strengths and limitations of different approaches.
1.3 MODULES
Upload Heavy Vehicles Fuel Dataset:
Using this module we can upload train dataset to application. Dataset contains comma separated values.
Read Dataset & Generate Model:
Using this module we will parse comma separated dataset and then generate train and test model for ANN
from that dataset values. Dataset will be divided into 80% and 20% format, 80% will be used to train ANN
model and 20% will be used to test ANN model.
Run ANN Algorithm:
Using this model we can create ANN object and then feed train and test data to build ANN model.
Predict Average Fuel Consumption:
Using this module we will upload new test data and then ANN will apply train model on that test data to
predict average fuel consumption for that test records.
Fuel Consumption Graph
Using this module we will plot fuel consumption graph for each test
13.
5
2.SYSTEM ANALYSIS
2.1 ExistingSystem & its Disadvantages:
model that can be easily developed for individual heavy vehicles in a large fleet is proposed.
Relying on accurate models of all of the vehicles in a fleet, a fleet manager can optimize the route
planning for all of the vehicles based on each unique vehicle predicted fuel consumption thereby
ensuring the route assignments are aligned to minimize overall fleet fuel consumption.
This approach is used in conjunction with seven predictors derived from vehicle speed and road
grade to produce a highly predictive neural network model for average fuel consumption in heavy
vehicles. Different window sizes are evaluated and the results show that a 1 km window is able
to predict fuel consumption with a 0.91 coefficient of determination and mean absolute peak-to-
peak percent error less than 4% for routes that include both city and highway duty cycle
segments.
Disadvantages of existing system:
• Physics-based models, which are derived from an in-depth understanding of the physical system.
These models describe the dynamics of the components of the vehicle each time step using detailed
mathematical equations.
• Statistical models, which are also data-driven and establish a mapping between the probability
distribution of a selected set of predictors and the target outcome.
2.2 PROPOSED SYSTEM & IT’S ADVANTAGES:
As mentioned above Artificial Neural Networks (ANN) are often used to develop digital models for
complex systems. The models proposed in [15] highlight some of the difficulties faced by machine learning
models when the input and output have different domains. In this study, the input is aggregated in the time
domain over 10 minutes intervals and the output is fuel consumption over the distance traveled during the
same time period.The complex system is represented by a transfer function F(p) = o, where F(·) represents
the system, p refers to the input predictors and o is the response of the system or the output. The ANNs
used in this paper are Feed Forward Neural Networks (FNN).
Training is an iterative process and can be performed using multiple approaches including particle swarm
optimization [20] and back propagation.Other approaches will be considered in future work in order to
14.
6
evaluation their abilityto improve the model’s predictive accuracy.Each iteration in the training selects a
pair of (input, output) features from Ftr at random and updates the weights in the network.
ADVANTAGES OF PROPOSED SYSTEM:
• Data is collected at a rate that is proportional to its impact on the outcome. When the input space is
sampled with respect to time, the amount of data collected from a vehicle at a stop is the same as the
amount of data collected when the vehicle is moving.
• The predictors in the model are able to capture the impact of both the duty cycle and the environment on
the average fuel consumption of the vehicle (e.g., the number of stops in an urban traffic over a given
distance).
• Data from raw sensors can be aggregated on-board into few predictors with lower storage and
transmission bandwidth requirements. Given the increase in computational capabilities of new vehicles,
data summarization is best performed on-board near the source of the data.
2.3 SYSTEM REQUIREMENTS:
USER REQUIREMENTS :
Requirement Specification plays an important role to create quality software solution. Requirements
are refined and analysed to assess the clarity. Requirements are represented in a manner that ultimately
leads to successful software implementation.
2.3.1 HARDWARE REQUIREMENTS
This is an project so hardware plays an important role. Selection of hardware also plays an important
role in existence and performance of any software. The size and capacity are main requirements.
Processor intel core i3
Hard Disc 1TB
Speed 2.4 GHz
RAM 4GB
15.
7
2.3.2 SOFTWARE REQUIREMENTS:
The software requirements specification is produced at the end of the analysis task. Software
requirement difficult task, For developing the Application
.
Operating System Windows 11
Domain Image Processing and cloud computing
Programming Language Python
Front End Technologies HTML5 ,CSS JavaScript
Framework Django
Database (RDBMS) MySQL
Web server /Deployment Server Django Application Development server
16.
8
3. SYSTEM STUDY
3.1FEASIBILITY STUDY
The feasibility of the project is analyzed in this phase and business proposal is put forth with a very general
plan for the project and some cost estimates. During system analysis the feasibility study of the proposed
system is to be carried out. This is to ensure that the proposed system is not a burden to the company. For
feasibility analysis, some understanding of the major requirements for the system is essential.
Three key considerations involved in the feasibility analysis are,
ECONOMICAL FEASIBILITY
TECHNICAL FEASIBILITY
SOCIAL FEASIBILITY
ECONOMICAL FEASIBILITY
This study is carried out to check the economic impact that the system will have on the organization. The
amount of fund that the company can pour into the research and development of the system is limited.
The expenditures must be justified. Thus the developed system as well within the budget and this was
achieved because most of the technologies used are freely available. Only the customized products had to
be purchased.
TECHNICAL FEASIBILITY
This study is carried out to check the technical feasibility, that is, the technical requirements of the
system. Any system developed must not have a high demand on the available technical resources. This
will lead to high demands on the available technical resources. This will lead to high demands being
placed on the client. The developed system must have a modest requirement, as only minimal or null
changes are required for implementing this system.
SOCIAL FEASIBILITY
The aspect of study is to check the level of acceptance of the system by the user. This includes the process
of training the user to use the system efficiently. The user must not feel threatened by the system, instead
must accept it as a necessity. The level of acceptance by the users solely depends on the methods that are
employed to educate the user about the system and to make him familiar with it.
10
4.2 UML DIAGRAMS
UMLstands for Unified Modeling Language. UML is a standardized general-purpose modelinglanguage in
the field of object-oriented software engineering. The standard is managed, and was created by, the Object
Management Group. The goal is for UML to become a common language for creating models of object
oriented computer software. In its current form UML iscomprised of two major components: a Meta-model
and a notation. In the future, some form ofmethod or process may also be added to or associated with, UML.
The Unified Modeling Language is a standard language for specifying, Visualization, Constructing and
documentingthe artifacts of software system, as well as for business modeling and other nonsoftware
systems. The UML represents a collection of best engineering practices that have proven successful in the
modeling of large and complex systems. The UML is a very important part ofdeveloping objects oriented
software and the software development process. The UML uses mostly graphical notations to express the
design of software projects it is a standardized modeling language consisting of an integrated set of
diagrams, developed to help system and software developers for specifying, visualizing, constructing,
and documenting the artifacts of software systems, as well as for business modeling and other non-
software systems. The UML represents a collection of best engineering practices that have proven
successful in the modeling of large and complex systems. The UML is a very important part of developing
object oriented software and the software development process. The UML uses mostly graphical
notations to express the design of software projects. Using the UML helps project teams communicate,
explore potential designs, and validate the architectural design of the software. In this article, we will
give you detailed ideas about what is UML, the history of UML and a description of each UML diagram
type, along with UML examples.
GOALS:
The Primary goals in the design of the UML are as follows:
• Provide users a ready-to-use, expressive visual modeling Language so that they candevelop
and exchange meaningful models.
• Provide extendibility and specialization mechanisms to extend the core concepts.
• Be independent of particular programming languages and development process.
• Provide a formal basis for understanding the modeling language.
• Encourage the growth of OO tools market.
• Support higher level development concepts such as collaborations, frameworks,patterns and
19.
11
components.
• Integrate bestpractices.
• UML provides a standardized way to visualize systems, making it easier for stakeholders to
understand complex systems through diagrams like class diagrams, sequence diagrams, and
activity diagrams.
• Communication: UML serves as a common language for developers, designers, architects, and
stakeholders, facilitating communication and collaboration among team members who may come
from diverse backgrounds.
•
20.
12
4.2.1 USE CASEDIAGRAM:
A use case diagram in the Unified Modeling Language (UML) is a type of behavioral diagramdefined by
and created from a Use-case analysis. Its purpose is to present a graphical overviewof the functionality
provided by a system in terms of actors, their goals (represented as use cases), and any dependencies
between those use cases. The main purpose of a use case diagram is to show what system functions are
performed for which actor. Roles of the actors in thesystem can be depicted.
Fig1
21.
13
4.2.2. CLASS DIAGRAM:
Insoftware engineering, a class diagram in the Unified Modeling Language (UML) is a type of static
structure diagram that describes the structure of a system by showing the system's classes, their attributes,
operations (or methods), and the relationships among the classes. It explains which class contains
information.
FIG 2
22.
14
4.2.3 SEQUENCE DIAGRAM:
Asequence diagram in Unified Modeling Language (UML) is a kind of interaction diagram that shows
how processes operate with one another and in what order. It is a construct of a Message Sequence Chart.
Sequence diagrams are sometimes called event diagrams, event scenarios, and timing diagrams.
Fig.3
23.
15
4.2.4 ACTIVITY DIAGRAM
Anactivity diagram is a type of UML (Unified Modeling Language) diagram that visualizes the flow of
activities in a system or process. It's particularly useful for modeling workflows, business processes, or
software algorithms. Activity diagrams typically consist of nodes representing activities or actions, and
arrows representing the flow of control from one activity to another.
Key elements of an activity diagram include:
1. **Initial Node**: Represents the starting point of the activity diagram.
2. **Activities**: Represent actions or steps within the process. They can be depicted as rounded
rectangles.
3. **Decisions**: Represent points in the process where different paths or conditions can be taken. They
are usually depicted as diamonds.
4. **Arrows**: Show the flow of control between activities, decisions, and other nodes.
FIG-4
24.
16
4.2.5 DEPLOYMENT DIAGRAM
Thedeployment diagram visualizes the physical hardware on which the software will be deployed. It
portrays the static deployment view of a system. It involves the nodes and their relationships.
It ascertains how software is deployed on the hardware. It maps the software architecture created in
design to the physical system architecture, where the software will be executed as a node. Since it
involves many nodes, the relationship is shown by utilizing communication paths.
FIG-5
18
5.TECHNOLOGIES
5.1 WHAT ISPYTHON
Below are some facts about Python.
Python is currently the most widely used multi-purpose, high-level programming language. Python
allows programming in Object-Oriented and Procedural paradigms. Pythonprograms generally are
smaller than other programming languages like Java.
Programmers have to type relatively less and indentation requirement of the language,makes them
readable all the time.
Python language is being used by almost all tech-giant companies like – Google, Amazon,Facebook,
Instagram, Dropbox, Uber… etc.
The biggest strength of Python is huge collection of standard library which can be used forthe following
• Machine Learning
• GUI Applications (like Kivy, Tkinter, PyQt etc. )
• Web frameworks like Django (used by YouTube, Instagram, Dropbox)
• Image processing (like Opencv, Pillow)
• Web scraping (like Scrapy, BeautifulSoup, Selenium)
• Test frameworks
• Multimedia
5.1.1 ADVANTAGES & DIADVANTAGES OF PYTHON
ADVANTAGES OF PYTHON :-
Let’s see how Python dominates over other languages.
1. Extensive Libraries
Python downloads with an extensive library and it contain code for various purposes likeregular
expressions, documentation-generation, unit-testing, web browsers, threading,databases, CGI, email, i
mage manipulation, and more. So, we don’t have to write the completecode for that manually
As we have seen earlier, Python can be extended to other languages. You can write some of your
code in languages like C++ or C. This comes in handy, especially in projects This lets us add scripting
capabilities to our code in the other language.
27.
19
2. Embeddable
Complimentary toextensibility, Python is embeddable as well. You can put your Python code in your
source code of a different language, like C++. This lets us add scripting capabilities to our code in the
other language.
3. Improved Productivity
The language’s need to be in simplicity and extensive libraries render programmers more productive than
languages like Java and C++ do. Also, the fact that you need to write less andget more things done.
4. IOT Opportunities
Since Python forms the basis of new platforms like Raspberry Pi, it finds the future bright for the Internet
Of Things. This is a way to connect the language with the real world.
5. Simple and Easy8
When working with Java, you may have to create a class to print ‘Hello World’. But in Python, just a print
statement will do. It is also quite easy to learn, understand, and code.This is why when people pick up
Python, they have a hard time adjusting to other more verbose languages like Java.
6. Readable
Because it is not such a verbose language, reading Python is much like reading English. This is the reason
why it is so easy to learn, understand, and code. It also does not need curlybraces to define blocks, and
indentation is mandatory.
This further aids the readability ofthe code.
7. Object-Oriented
This language supports both the procedural and object-oriented programming paradigms. While
functions help us with code reusability, classes and objects let us modelthe real world. A class allows the
encapsulation of data and functions
Free and Open-Source
Like we said earlier, Python is freely available. But not only can you download Pythonfor free, but you can also
download its source code, make changes to it, and even distributeit.
28.
20
8. Portable
When youcode your project in a language like C++, you may need to make some changesto it if you want
to run it on another platform. But it isn’t the same with Python. Here, youneed to code only once, and you
can run it anywhere. This is called Write Once Run Anywhere (WORA). However, you need to be
careful enough not to include any systemdependent features.
9. Interpreted
Lastly, we will say that it is an interpreted language. Since statements are executed one byone,
debugging is easier than in compiled languages.
ADVANTAGES OF PYTHON OVER OTHER LANGUAGES
1. Less Coding
Almost all of the tasks done in Python requires less coding when the same task is done in other languages.
Python also has an awesome standard library support, so you don’t have tosearch for any third-party
libraries to get your job done. This is the reason that many peoplesuggest learning Python to beginners.
2. Affordable
Python is free therefore individuals, small companies or big organizations can leverage thefree available
resources to build applications. Python is popular and widely used so it givesyou better community
support.
The 2019 Github annual survey showed us that Python has overtaken Java in the most popular
programming language category
3. Python is for Everyone
Python code can run on any machine whether it is Linux, Mac or Windows. Programmers need to learn
different languages for different jobs but with Python, you can professionally build web apps, perform
data analysis and machine learning, automate things, do web scraping and also build games and
powerful visualizations. It is an all-rounder programminglanguage.
29.
21
DISADVANTAGES OF PYTHON
Sofar, we’ve seen why Python is a great choice for your project. But if you choose it, you should be
aware of its consequences as well. Let’s now see the downsides of choosing Pythonover another language.
1. Speed Limitations
We have seen that Python code is executed line by line. But since Python is interpreted, itoften results in
slow execution. This, however, isn’t a problem unless speed is a focal pointfor the project. In other words,
unless high speed is a requirement, the benefits offered byPython are enough to distract us from its speed
limitations.
2. Weak in Mobile Computing and Browsers
While it serves as an excellent server-side language, Python is much rarely seen on the client-side.
Besides that, it is rarely ever used to implement smartphone-based applications. One such application is
called Carbonnelle.The reason it is not so famous despite the existence of Brython is that it isn’t that
secure.
3. Design Restrictions
As you know, Python is dynamically-typed. This means that you don’t need to declare thetype of variable
while writing the code. It uses duck-typing. But wait, what’s that? Well, it just means that if it looks like
a duck, it must be a duck. While this is easy on the programmers during coding, it can raise run-time
errors.
4. Underdeveloped Database Access Layers
Compared to more widely used technologies like JDBC (Java DataBase
Connectivity) and ODBC (Open DataBase Connectivity), Python’s database access layersare a bit
underdeveloped. Consequently, it is less often applied in huge enterprises.
5. Simple
No, we’re not kidding. Python’s simplicity can indeed be a problem. Take my example. I don’t do Java,
I’m more of a Python person. To me, its syntax is so simple that the verbosityof Java code seems
unnecessary.
6. Underdeveloped Database Access Layers
Compared to more widely used technologies like JDBC (Java DataBase
Connectivity) and ODBC (Open DataBase Connectivity),
30.
22
HISTORY OF PYTHON
Whatdo the alphabet and the programming language Python have in common? Right, bothstart with ABC.
If we are talking about ABC in the Python context, it's clear that the programming language ABC is
meant. ABC is a general-purpose programming language and programming environment, which had been
developed in the Netherlands, Amsterdam,at the CWI (Centrum Wiskunde &Informatica). The greatest
achievement of ABC was toinfluence the design of Python. Python was conceptualized in the late 1980s.
Guido van Rossum worked that time in a project at the CWI, called Amoeba, a distributed operating
system. In an interview with Bill Venners1
, Guido van Rossum said: "In the early 1980s, Iworked as an
implementer on a team building a language called ABC at Centrum Wiskundeen Informatica (CWI). I
don't know how well people know ABC's influence on Python. I try to mention ABC's influence because
I'm indebted to everything I learned during that project and to the people who worked on it. Later on in
the same Interview, Guido van Rossum continued: "I remembered all my experience and some of my
frustration with ABC. I decided to try to design a simple scripting language that possessed some of ABC's
better properties, but without its problems. So I started typing. I created a simple virtual machine, a
simple parser, and a simple runtime. I made my own version of the various ABCparts that I liked. I
created a basic syntax, used indentation for statement grouping instead ofcurly braces or begin-end
blocks, and developed a small number of powerful data types: a hash table (or dictionary, as we call it),
a list, strings, and numbers."
5.2 WHAT IS MACHINE LEARNING
Before we take a look at the details of various machine learning methods, let's start by looking at what
machine learning is, and what it isn't. Machine learning is often categorizedas a subfield of artificial
intelligence, but I find that categorization can often be misleadingat first brush. The study of machine
learning certainly arose from research in this context,but in the data science application of machine
learning methods, it's more helpful to thinkof machine learning as a means of building models of data.
Fundamentally, machine learning involves building mathematical models to help understand data.
"Learning" enters the fray when we givethese models tunableparametersthat can be adapted to observed
data; in this way the program can be considered to be "learning" from the data. Once these models have
been fit to previously seen data, they canbe used to predict and understand aspects of newly observed
data. I'll leave to the reader the more philosophical digression regarding the extent to which this type of
mathematical,model-based "learning" is similar to the "learning" exhibited by the human brain.
Understanding the problem setting in machine learning is essential to using these tools effectively, and
so we will start with some broad categorizations of the types of approacheswe'll discuss here.
31.
23
5.2.1 CATEGORIES OFMACHINE LEANING
At the most fundamental level, machine learning can be categorized into two main types: supervised
learning and unsupervised learning.
Supervised learning involves somehow modeling the relationship between measuredfeatures of data
and some label associated with the data; once this model is determined, itcan be used to apply labels
to new, unknown data. This is further subdivided into
classification tasks and regression tasks: in classification, the labels are discrete categories,while in
regression, the labels are continuous quantities. We will see examples of both types of supervised
learning in the following section.
Unsupervised learning involves modeling the features of a dataset without reference to anylabel, and is
often described as "letting the dataset speak for itself." These models includetasks such as clustering
and dimensionality reduction. Clustering algorithms identify distinct groups of data, while
dimensionality reduction algorithms search for more succinctrepresentations of the data. We will see
examples of both types of unsupervised learning in the following section
5.2.2 Need for Machine Learning
Human beings, at this moment, are the most intelligent and advanced species on earth because they can
think, evaluate and solve complex problems. On the other side, AI is stillin its initial stage and haven’t
surpassed human intelligence in many aspects. Then the question is that what is the need to make
machine learn? The most suitable reason for doingthis is, “to make decisions, based on data, with
efficiency and scale” Lately, organizations are investing heavily in newer technologies like Artificial
Intelligence, Machine Learning and Deep Learning to get the key information from data toperform
several real-world tasks and solve problems. We can call it data-driven decisionstaken by machines,
particularly to automate the process. These data-driven decisions can be used, instead of using
programing logic, in the problems that cannot be programmed inherently. The fact is that we can’t do
without human intelligence, but other aspect is thatwe all need to solve real-world problems with
efficiency at a huge scale. That is why the need for machine learning aris
32.
24
5.2.3 Challenges inMachines Learning
While Machine Learning is rapidly evolving, making significant strides with cybersecurity and
autonomous cars, this segment of AI as whole still has a long way to go. The reason behind is that ML
has not been able to overcome number of challenges. The challenges that ML is facing currently are
Quality of data − Having good-quality data for ML algorithms is one of the biggest challenges. Use
of low-quality data leads to the problems related to data preprocessing andfeature extraction.
Time-Consuming task − Another challenge faced by ML models is the consumption of time
especially for data acquisition, feature extraction and retrieval.
Lack of specialist persons − As ML technology is still in its infancy stage, availability of expert
resources is a tough job.
No clear objective for formulating business problems − Having no clear objective and well
-defined goal for business problems is another key challenge for ML because this technology is not that
mature yet.
Issue of overfitting & underfitting − If the model is overfitting or underfitting, it cannot be
represented well for the problem.
Curse of dimensionality − Another challenge ML model faces is too many features of datapoints.
This can be a real hindrance.
Difficulty in deployment − Complexity of the ML model makes it quite difficult to be
deployed in real life.
Data Quality and Quantity: ML algorithms heavily rely on data. Poor quality data can lead to
biased or inaccurate models. Additionally, acquiring labeled data for supervised learning tasks can be
expensive and time-consuming.
Overfitting and Underfitting: Overfitting occurs when a model learns the training data too well,
capturing noise along with the underlying patterns, resulting in poor generalization to new data.
Underfitting, on the other hand, happens when a model is too simple to capture the underlying structure
of the data.
33.
25
5.2.4 APPLICATIONS OFMACHINE LEARNING :-
Machine Learning is the most rapidly growing technology and according to researchers weare in the
golden year of AI and ML. It is used to solve many real-world complex problemswhich cannot be solved
with traditional approach. Following are some real-world applications of ML −
• Emotion analysis
• Sentiment analysis
• Error detection and prevention
• Weather forecasting and prediction
• Stock market analysis and forecasting
• Speech synthesis
• Speech recognition
• Customer segmentation
• Object recognition
• Fraud detection
• Fraud prevention
5.2.5 How to Start Learning Machine Learning?
Arthur Samuel coined the term “Machine Learning” in 1959 and defined it as a “Field ofstudy that
gives computers the capability to learn without being explicitly programmed”.
And that was the beginning of Machine Learning! In modern times, Machine Learning is one
of the most popular (if not the most!) career choices. According to Indeed, Machine LearningEngineer Is
The Best Job of 2019 with a 344% growth and an average base salary of $146,085per year.
But there is still a lot of doubt about what exactly is Machine Learning and how to start learning it? So
this article deals with the Basics of Machine Learning and also the path you can follow to eventually
become a full-fledged Machine Learning Engineer. Now let’s get started!!!
How to start learning ML?
This is a rough roadmap you can follow on your way to becoming an insanely talented Machine Learning
Engineer. Of course, you can always modify the steps according to your needs to reach your desired end-
goal
34.
26
Step 1 –Understand the Prerequisites
In the case, you are a genius, you could start ML directly but normally, there are someprerequisites that
you need to know which include Linear Algebra, Multivariate Calculus, Statistics, and Python. And if
you don’t know these, never fear! You don’t need Ph.D.degreein these topics to get started but you do
need a basic understanding.
(a) Learn Linear Algebra and Multivariate Calculus
Both Linear Algebra and Multivariate Calculus are important in Machine Learning. However, the extent
to which you need them depends on your role as a data scientist. If you are more focused on application
heavy machine learning, then you will not be that heavily focused on maths as there are many common
libraries available. But if you want to focus onR&D in Machine Learning, then mastery of Linear Algebra
and Multivariate Calculus is veryimportant as you will have to implement many ML algorithms from
scratch.
(b) Learn Statistics
Data plays a huge role in Machine Learning. In fact, around 80% of your time as an ML expert will be
spent collecting and cleaning data. And statistics is a field that handles the collection, analysis, and
presentation of data. So it is no surprise that you need to learn it!!!Some of the key concepts in statistics
that are important are Statistical Significance, Probability Distributions, Hypothesis Testing, Regression,
etc. Also, Bayesian Thinking isalso a very important part of ML which deals with various concepts like
Conditional Probability, Priors, and Posteriors, Maximum Likelihood, etc.
(c) Learn Python
Some people prefer to skip Linear Algebra, Multivariate Calculus and Statistics and learn them as they
go along with trial and error. But the one thing that you absolutely cannot skipis Python! While there are
other languages you can use for Machine Learning like R, Scala,etc. Python is currently the most popular
language for ML. In fact, there are many Python libraries that are specifically useful for Artificial
Intelligence and Machine Learning such as Keras, TensorFlow, Scikit-learn, etc. So if you want to learn
ML, it’s best if you learn Python! You can do that using various online resources and courses such as
Fork Python available Free on GeeksforGeeks.
35.
27
Step 2 –Learn Various ML Concepts
Now that you are done with the prerequisites, you can move on to actually learning ML(Which is the
fun part!!!) It’s best to start with the basics and then move on to more complicated stuff. Some of the
basic concepts in ML are:
Terminologies of Machine Learning
• Model – A model is a specific representation learned from data by applying some machine
learning algorithm. A model is also called a hypothesis.
• Feature – A feature is an individual measurable property of the data. A set of numericfeatures
can be conveniently described by a feature vector. Feature vectors are fed as input to the model.
For example, in order to predict a fruit, there may be features like color, smell, taste, etc.
• Target (Label) – A target variable or label is the value to be predicted by our model. For the fruit
example discussed in the feature section, the label with each set of input would be the name of the
fruit like apple, orange, banana, etc.
• Training – The idea is to give a set of inputs(features) and it’s expected outputs(labels),so after
training, we will have a model (hypothesis) that will then map new data to oneof the categories
trained on.
• Prediction – Once our model is ready, it can be fed a set of inputs to which it will provide a
predicted output(label).
Types of Machine Learning
• Supervised Learning – This involves learning from a training dataset with labeled data using
classification and regression models. This learning process continues until the required level of
performance is achieved.
• Unsupervised Learning – This involves using unlabelled data and then finding the underlying structure
in the data in order to learn more and more about the data itself using factor and cluster analysis models.
• Semi-supervised Learning – This involves using unlabelled data like Unsupervised Learning with a
small amount of labeled data. Using labeled data vastly increases thelearning accuracy and is also more
cost-effective than Supervised Learning.
• Reinforcement Learning – This involves learning optimal actions through trial and error. So the next
action is decided by learning behaviors that are based on the currentstate and that will maximize the
•
36.
28
• 5.2.6 ADVANTAGES& DISADVANTAGES OF MACHINE
LEARNING
ADVANTAGES OF MACHINE LEARNING :-
1.Easily identifies trends and patterns -
Machine Learning can review large volumes of data and discover specific trends and patterns that would
not be apparent to humans. For instance, for an e-commerce website like Amazon,it serves to understand
the browsing behaviors and purchase histories of its users to help caterto the right products, deals, and
reminders relevant to them. It uses the results to reveal relevantadvertisements to them.
2.No human intervention needed (automation)
With ML, you don’t need to babysit your project every step of the way. Since it means givingmachines
the ability to learn, it lets them make predictions and also improve the algorithms ontheirown.Acommon
example of this is anti-virus softwares. they learn to filter new threatsas they are recognized. ML is also
good at recognizing spam.
3. Continuous Improvement
As ML algorithms gain experience, they keep improving in accuracy and efficiency. This lets them
make better decisions. Say you need to make a weather forecast model. As the amount of data you have
keeps growing, your algorithms learn to make more accurate predictions faster.
4. Handling multi-dimensional and multi-variety data
Machine Learning algorithms are good at handling data that are multi-dimensional andmultivariety, and
they can do this in dynamic or uncertain environments.
5. Wide Applications
You could be an e-tailer or a healthcare provider and make ML work for you. Where it does apply, it
holds the capability to help deliver a much more personal experience to customers while also targeting
the right customers.
37.
29
DISADVANTAGES OF MACHINELEARNING :-
1.Data Acquisition
Machine Learning requires massive data sets to train on, and these should be inclusive/unbiased, and of
good quality. There can also be times where they must wait for new data to be generated.
2. Time and Resources
ML needs enough time to let the algorithms learn and develop enough to fulfill their purposewith a
considerable amount of accuracy and relevancy. It also needs massive resources to function. This can
mean additional requirements of computer power for you.
3. Interpretation of Results
Another major challenge is the ability to accurately interpret results generated by the algorithms. You
must also carefully choose the algorithms for your purpose.
4. High error-susceptibility
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with
data sets small enough to not be inclusive. You end up with biased predictionscoming from a biased
training set. This leads to irrelevant advertisements being displayed tocustomers. In the case of ML, such
blunders can set off a chain of errors that can go undetectedfor long periods of time. And when they do
get noticed, it takes quite some time to recognizethe source of the issue, and even longer to correct it.
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with
data sets small enough to not be inclusive. You end up with biased predictionscoming from a biased
training set. This leads to irrelevant advertisements being displayed tocustomers. In the case of ML, such
blunders can set off a chain of errors that can go undetectedfor long periods of time. And when they do
get noticed, it takes quite some time to recognizethe source of the issue, and even longer to correct it.
38.
30
5.3 PYTHON DEVELOPMENTSTEPS
Guido Van Rossum published the first version of Python code (version 0.9.0) at alt.sources in
February 1991. This release included already exception handling, functions, and the coredata types of
list, dict, str and others. It was also object oriented and had a module system. Python version 1.0 was
released in January 1994. The major new features included in this release were the functional
programming tools lambda, map, filter and reduce, which GuidoVan Rossum never liked.Six and a
half years later in October 2000, Python 2.0 was introduced. This release included list
comprehensions, a full garbage collector and it was supporting Unicode Python flourished for another 8
years in the versions 2.x before the nextmajor release as Python 3.0 (also known as "Python 3000" and
"Py3K") was released. Python3 is not backwards compatible with Python 2.x. The emphasis in Python 3
had been on the removal of duplicate programming constructs and modules, thus fulfilling or coming
close to fulfilling the 13th law of the Zen of Python: "There should be one -- and preferably only one --
obvious way to do it. Some changes in Python 7.3:
• Print is now a function
• Views and iterators instead of lists
• The rules for ordering comparisons have been simplified. E.g. a heterogeneous list cannot be
sorted, because all the elements of a list must be comparable to each other.
• There is only one integer type left, i.e. int. long is int as well.
• The division of two integers returns a float instead of an integer. "//" can be used to have the "old"
behaviour.
• Text Vs. Data Instead Of Unicode Vs. 8-bit
PURPOSE
We demonstrated that our approach enables successful segmentation of intra-retinallayers—even with
low-quality images containing speckle noise, low contrast, and differentintensity ranges throughout—
with the assistance of the ANIS feature.
PYTHON
Python is an interpreted high-level programming language for general-purpose programming. Created
by Guido van Rossum and first released in 1991, Python has a design philosophy that emphasizes code
readability, notably using significant whitespace.
Python features a dynamic type system and automatic memory management. It supports multiple
programming paradigms, including object-oriented, imperative, functional and procedural,
39.
31
• Python isInterpreted − Python is processed at runtime by the interpreter. You do not need to compile
your program before executing it. This is similar to PERL and PHP.
• Python is Interactive − you can actually sit at a Python prompt and interact with the interpreter directly
to write your programs.
• Python also acknowledges that speed of development is important. Readable and tersecode is part of
this, and so is access to powerful constructs that avoid tedious repetitionof code. Maintainability also
ties into this may be an all but useless metric, but it does say something about how much code you
have to scan, read and/or understand to troubleshoot problems or tweak behaviors. This speed of
development, the ease with which a programmer of other languages can pick up basic Python skills
and the huge standard library is key to another area where Python excels. All its tools have been quick
to implement, saved a lot of time, and several of them have later been patched and updated by people
with no Python background - without breaking.
5.4 MODULES USED IN PYTHON
TENSORFLOW:
TensorFlow is a free and open-source software library for dataflow and differentiable programming
across a range of tasks. It is a symbolic math library, and is also used for machine learning applications
such as neural networks. It is used for both research and production at Google.
TensorFlow was developed by the Google Brain team for internal Google use. It was releasedunder the
Apache 2.0 open-source license on November 9, 2015.
NUMPY:
Numpy is a general-purpose array-processing package. It provides a high-performance
multidimensional array object, and tools for working with these arrays.
It is the fundamental package for scientific computing with Python. It contains variousfeatures
including these important ones:
• A powerful N-dimensional array object
• Sophisticated (broadcasting) functions
• Tools for integrating C/C++ and Fortran code
• Useful linear algebra, Fourier transform, and random number capabilities
• Besides its obvious scientific uses, Numpy can also be used as an efficient multidimensional
40.
32
container of genericdata. Arbitrary data-types can be defined using Numpy which allows Numpy
to seamlessly and speedily integrate with a wide varieties.
PANDAS
Pandas is an open-source Python Library providing high-performance data manipulation and analysis
tool using its powerful data structures. Python was majorly used for data munging and preparation. It
had very little contribution towards data analysis. Pandas solved this problem. Using Pandas, we can
accomplish five typical steps in the processingand analysis of data, regardless of the origin of data load,
prepare, manipulate, model, andanalyze. Python with Pandas is used in a wide range of fields including
academic and commercial domains including finance, economics, Statistics, analytics, etc.
MATPLOTLIB
Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of
hardcopy formats and interactive environments across platforms. Matplotlib canbe used in Python scripts,
the Python and IPython shells, the Jupyter Notebook, web application servers, and four graphical user
interface toolkits. Matplotlib tries to make easythings easy and hard things possible. You can generate
plots, histograms, power spectra, bar charts, error charts, scatter plots, etc., with just a few lines of code.
For examples, see the sample plots and thumbnail gallery.
For simple plotting the pyplot module provides a MATLAB-like interface, particularly when combined
with IPython. For the power user, you have full control of line styles, fontproperties, axes properties, etc.
via an object oriented interface or via a set of functions familiar to MATLAB users.
SCIKIT – LEARN
Scikit-learn provides a range of supervised and unsupervised learning algorithms via a consistent
interface in Python. It is licensed under a permissive simplified BSD license andis distributed under many
Linux distributions, encouraging academic and commercial use.Python
Python is an interpreted high-level programming language for general-purpose programming. Created
by Guido van Rossum and first released in 1991, Python has a design philosophy that emphasizes code
readability, notably using significant whitespace.
Python features a dynamic type system and automatic memory management. It supports multiple
programming paradigms, including object-oriented, imperative, functional and procedural, and has a
large and comprehensive standard library.
• Python is Interpreted − Python is processed at runtime by the interpreter. You do not need to
compile your program before executing it. This is similar to PERL and PHP.
41.
33
• Python isInteractive − you can actually sit at a Python prompt and interact with the interpreter
directly to write your programs.
Python also acknowledges that speed of development is important. Readable and terse codeis part of this,
and so is access to powerful constructs that avoid tedious repetition of code.Maintainability also ties into
this may be an all but useless metric, but it does say somethingabout how much code you have to scan,
read and/or understand to troubleshoot problems or tweak behaviors. This speed of development, the ease
with which a programmer of otherlanguages can pick up basic Python skills and the huge standard library
is key to another area where Python excels. All its tools have been quick to implement, saved a lot of
time,and several of them have later been patched .
Scikit-learn is a popular open-source machine learning library for Python. It provides a wide range of
tools for building and deploying machine learning models efficiently. Here are some key aspects of
scikit-learn:
Simple and Consistent API: Scikit-learn offers a simple and consistent API, making it easy to use and
understand for both beginners and experienced users. The API design follows a common pattern across
different algorithms, which simplifies the learning curve.
Comprehensive Algorithms: Scikit-learn includes a vast collection of machine learning algorithms for
various tasks such as classification, regression, clustering, dimensionality reduction, and more. These
algorithms are implemented efficiently and are well-documented, allowing users to experiment with
different techniques easily.
Model Evaluation and Selection: The library provides tools for evaluating and selecting models,
including metrics for assessing model performance, techniques for cross-v alidation, and hyperparameter
tuning methods like grid search and randomized search.
Preprocessing and Feature Engineering: Scikit-learn offers utilities for preprocessing data and
engineering features, such as scaling, normalization, encoding categorical variables, handling missing
values, and feature selection.
Integration with NumPy and SciPy: Scikit-learn seamlessly integrates with other popular Python
libraries like NumPy and SciPy, leveraging their computational capabilities for efficient data processing
and numerical operations.
42.
34
5.5 INSTALL PYTHONSTEP-BY-STEP IN WINDOWS AND MAC
Python a versatile programming language doesn’t come pre-installed on your computerdevices.
Python was first released in the year 1991 and until today it is a very popular high-level programming
language. Its style philosophy emphasizes code readability with its notable use of great whitespace.
The object-oriented approach and language construct provided by Python enables programmers to
write both clear and logical code for projects. This software does not come pre-packaged with
Windows.
HOW TO INSTALL PYTHON ON WINDOWS AND MAC :
There have been several updates in the Python version over the years. The question is how to install
Python? It might be confusing for the beginner who is willing to start learningPython but this tutorial will
solve your query. The latest or the newest version of Python isversion 3.7.4 or in other words, it is
Python 3.
Note: The python version 3.7.4 cannot be used on Windows XP or earlier devices.
Before you start with the installation process of Python. First, you need to know about yourSystem
Requirements. Based on your system type i.e. operating system and based processor, you must
download the python version. My system type is a Windows 64-bit operating system. So the steps
below are to install python version 3.7.4 on Windows 7 device or to install Python 3. Download the
Python Cheats heet here. The steps on how to install Python on Windows 10, 8 and 7 are divided into 4
parts to help understand better.
Download the Correct version into the system
Step 1: Go to the official site to download and install python using Google Chrome orany other
web browser. OR Click on the following link: https://www.python.org
43.
35
Now, check forthe latest and the correct version for your operating system.
Step 2: Click on the Download Tab
44.
36
Step 3: Youcan either select the Download Python for windows 3.7.4 button in Yellow Color or you can
scroll further down and click on download with respective to their version.Here, we are downloading the
most recent python version for windows 3.7.4
Step 4: Scroll down the page until you find the Files option.
Step 5: Here you see a different version of python along with the operating system.
• To download Windows 32-bit python, you can select any one from the three options: Windows
x86 embeddable zip file, Windows x86 executable installer or Windows x86 web-based installer.
•To download Windows 64-bit python, you can select any one from the three options: Windows x86-64
embeddable zip file, Windows x86-64 executable installer or Windows x8664 web-based installer.
Here we will install Windows x86-64 web-based installer. Here your first part regarding which version
of python is to be downloaded is completed. Now we move ahead with thesecond part in installing python
i.e. Installation
45.
37
Note: To knowthe changes or updates that are made in the version you can click on theRelease
Note Option.
Installation of Python
Step 1: Go to Download and Open the downloaded python version to carry out theinstallation process.
Step 2: Before you click on Install Now, Make sure to put a tick on Add Python 3.7 to PATH.
46.
38
Step 3: Clickon Install NOW After the installation is successful. Click on Close.
With these above three steps on python installation, you have successfully and correctly installed Python.
Now is the time to verify the installation. Note: The installation processmight take a couple of minutes.
Verify the Python Installation
Step 1: Click on Start
Step 2: In the Windows Run Command, t
47.
39
Step 3: Openthe Command prompt option.
Step 4: Let us test whether the python is correctly installed. Type python –V and press
Step 5: You will get the answer as 3.7.4
Note: If you have any of the earlier versions of Python already installed. You must firstuninstall the
earlier version and then install the new one.
Check how the Python IDLE works
Step 1: Click on Start
Step 2: In the Windows Run command, type “python idle”.
Step 3: Click on IDLE (Python 3.7 64-bit) and launch the program
Step 4: To go ahead with working in IDLE you must first save the file. Click on File > Clickon Save
48.
40
Step 5: Namethe file and save as type should be Python files. Click on SAVE. Here I havenamed the files
as Hey World.
Step 6: Now for e.g. enter print
49.
41
6. IMPLEMENTATIONS
6.1 SOFTWAREENVIRONMENT
6.1.1 PYTHON
Python is a general-purpose interpreted, interactive, object-oriented, and high-level programming
language. An interpreted language, Python has a design philosophy that emphasizes
code readability (notably using whitespace indentation to delimit code blocks rather than curly brackets
or keywords), and a syntax that allows programmers to express concepts in fewer lines of code than
might be used in languages such as C++or Java. It provides constructs that enable clear programming on
both small and large scales. Python interpreters are available for many operating systems. CPython,
the reference implementation of Python, is open source software and has a community-based
development model, as do nearly all of its variant implementations. CPython is managed by the non-
profit Python Software Foundation. Python features a dynamic type system and automatic memory
management. It supports multiple programming paradigms, including object-
oriented, imperative, functional and procedural, and has a large and comprehensive standard library.
WHAT CAN PYHON DO?
• Python can be used on a server to create web applications.
• Python can be used alongside software to create workflows.
• Python can connect to database systems. It can also read and modify files.
• Python can be used to handle big data and perform complex mathematics.
• Python can be used for rapid prototyping, or for production-ready software development.
Introduction to Python
Python is a widely used general-purpose, high level programming language. It was created by Guido
van Rossum in 1991 and further developed by the Python Software Foundation. It was designed with
an emphasis on code readability, and its syntax allows programmers to express their concepts in fewer
lines of code.
Python is a programming language that lets you work quickly and integrate systems more efficiently.
There are two major Python versions: Python 2 and Python 3. Both are quite different.
REASON FOR INCREASING POPULARITY
Emphasis on code readability, shorter codes, ease of writing
Programmers can express logical concepts in fewer lines of code in comparison to languages such as
C++ or Java.
50.
42
Python supports multipleprogramming paradigms, like object-oriented, imperative and functional
programming or procedural.
There exists inbuilt functions for almost all of the frequently used concepts.
Philosophy is “Simplicity is the best”.
LANGUAGE FEATURES
Interpreted
There are no separate compilation and execution steps like C and C++.
Directly run the program from the source code.
Internally, Python converts the source code into an intermediate form called bytecodes which is then
translated into native language of specific computer to run it.
No need to worry about linking and loading with libraries, etc.
Platform Independent
Python programs can be developed and executed on multiple operating system platforms.
Python can be used on Linux, Windows, Macintosh, Solaris and many more.
Free and Open Source; Redistributable
High-level Language
In Python, no need to take care about low-level details such as managing the memory used by the
program.
Simple
Closer to English language;Easy to Learn
More emphasis on the solution to the problem rather than the syntax
Embeddable
Python can be used within C/C++ program to give scripting capabilities for the program’s users.
Robust:
Exceptional handling features
Memory management techniques in built
Rich Library Support
The Python Standard Library is very vast.
Known as the “batteries included” philosophy of Python ;It can help do various things involving
regular expressions, documentation generation, unit testing, threading, databases, web browsers, CGI,
email, XML, HTML, WAV files, cryptography, GUI and many more.
Besides the standard library, there are various other high-quality libraries such as the Python Imaging
Library which is an amazingly simple image manipulation library.
51.
43
DJANGO
Django is ahigh-level Python Web framework that encourages rapid development and clean, pragmatic
design. Built by experienced developers, it takes care of much of the hassle of Web development, so you
can focus on writing your app without needing to reinvent the wheel. It’s free and open source.
Django's primary goal is to ease the creation of complex, database-driven websites. Django
emphasizes reusabilityand "pluggability" of components, rapid development, and the principle of don't
repeat yourself. Python is used throughout, even for settings files and data models.
Django is a Python-based web framework that allows you to create efficient web applications quickly. It
is also called batteries included framework because Django provides built-in features for everything
including Django Admin Interface, default database – SQLlite3, etc.
This free Django tutorial is built for beginners looking to build web applications, and can also be used
by experts to brush up their Django skills. Covering all topics from basic to advanced, this Django tutorial
is your one-stop destination to learn Django.
Django is a high-level Python web framework that encourages rapid development and clean, pragmatic
design. It follows the "Don't Repeat Yourself" (DRY) principle and emphasizes reusability and
pluggability of components. Developed by Adrian Holovaty and Simon Willison, Django was first
released in 2005 and has since become one of the most popular web frameworks for building dynamic
web applications.
Here are some key aspects of Django:
52.
44
1. **MVC Architecture**:Django follows the Model-View-Controller (MVC) architectural pattern,
although it refers to it as the "Model-View-Template" (MVT). Models represent the data structure, views
handle the presentation logic, and templates define the user interface. This separation of concerns
facilitates modular and maintainable code.
2. **ORM (Object-Relational Mapping)**: Django includes a built-in ORM that abstracts away the
complexities of database interaction. Developers can define database models using Python classes, and
Django handles the translation of these models into database tables and SQL queries. This simplifies
database access and reduces the amount of boilerplate code.
3. **Admin Interface**: Django provides a powerful administrative interface automatically generated
from the database models. This admin interface allows administrators to manage site content, users, and
other aspects of the application without writing custom code. It is highly customizable and extensible.
4. **URL Routing**: Django's URL dispatcher allows developers to map URLs to view functions or
class-based views. This enables clean and flexible URL routing, making it easy to design RESTful APIs
and user-friendly URLs.
5. **Template Engine**: Django comes with a template engine that allows developers to define the
presentation layer using HTML templates with embedded Python code. Templates support inheritance,
template inheritance, and template tags, making it easy to create dynamic and reusable HTML content.
6. **Security Features**: Django includes built-in security features to help developers build secure
web applications. These features include protection against common security threats such as SQL
injection, cross-site scripting (XSS), cross-site request forgery (CSRF), and clickjacking.
7. **Authentication and Authorization**: Django provides robust authentication and authorization
mechanisms out of the box. Developers can easily integrate user authentication, permission management,
and user sessions into their applications.
8. **Internationalization and Localization**: Django supports internationalization (i18n) and
localization (l10n) features, allowing developers to build applications that support multiple languages
and locales.
9. **Community and Ecosystem**: Django has a large and active community of developers who
contribute to its development, provide support, and create reusable packages and extensions (e.g.,
53.
45
reusable apps, middleware,and utilities) that further extend Django's functionality.
ADVANTAGES OF DJANGO
Rapid Development: Django follows the "Don't Repeat Yourself" (DRY) principle and provides a lot
of built-in functionalities and conventions, allowing developers to build web applications quickly and
efficiently. Its batteries-included approach means that developers don't have to reinvent the wheel for
common web development tasks.
Built-in Admin Interface: Django comes with a powerful admin interface that is automatically
generated based on the application's models. This admin interface allows developers to manage site
content, users, and permissions without writing any additional code. It's highly customizable and
provides a convenient way for administrators to interact with the application.
ORM (Object-Relational Mapping): Django's ORM abstracts away the complexities of database
interaction by allowing developers to define database models as Python classes. Django takes care of
translating these models into database tables and managing database queries, making database operations
easy and intuitive.
Security Features: Django takes security seriously and provides built-in protection against common
security threats such as SQL injection, cross-site scripting (XSS), cross-site request forgery (CSRF), and
clickjacking. It also provides tools for user authentication, authorization, and session management,
making it easier for developers to build secure web applications.
Scalability: Django is designed to scale with the needs of the application. It provides tools and best
practices for optimizing database queries, caching, and handling high traffic loads. Many large-scale
websites and web applications, including Instagram and Pinterest, have been built using Django
Versatility: Django is a versatile framework that can be used to build a wide range of web applications,
from simple websites to complex, high-traffic platforms. It provides support for various types of web
development tasks, including content management systems (CMS), e-commerce platforms, social
Community and Ecosystem: Django has a large and active community of developers who contribute
to its development, provide support, and create reusable packages and extensions that extend Django's
functionality. The Django ecosystem includes a vast collection of third-party libraries, reusable apps, and
resources that make it easier for developers to build web applications.
54.
46
DISADVANTAGES OF DJANGO
Hereare some of the common drawbacks associated with Django:
Learning Curve: Django has a relatively steep learning curve, especially for beginners with limited
experience in web development or Python programming. Its extensive feature set and conventions may
take some time to master, leading to a longer ramp-up period for new developers.
Opinionated Framework: Django is an opinionated framework, meaning it imposes certain design
patterns and conventions on developers. While these conventions can promote consistency and best
practices, they may also limit flexibility and creative freedom, especially for developers who prefer more
customizable or lightweight solutions.
Monolithic Architecture: Django follows a monolithic architecture, which means that all components
of the application (e.g., models, views, templates) are tightly coupled within a single framework. While
this can simplify development in many cases, it may not be suitable for projects that require
microservices or a more modular architecture.
Performance Overhead: Django's extensive feature set and abstractions may introduce some
performance overhead compared to more lightweight frameworks. In some cases, developers may need
to optimize Django applications to achieve better performance, especially for high-traffic or resource-
intensive applications.
Limited Real-Time Capabilities: Django is not well-suited for real-time applications or applications
requiring bidirectional communication between the client and server (e.g., chat applications, real-time
collaborative editing). While it's possible to integrate real-time features using third-party libraries or
services, it's not a native strength of the framework.
Dependency on Django ORM: While Django's ORM simplifies database interactions, it may not be
suitable for all projects or database requirements. In some cases, developers may prefer to use a different
ORM or interact with the database directly, which can be challenging within the Django ecosystem.
Upgrades and Maintenance: Upgrading Django versions or maintaining older projects can sometimes
be challenging, especially if the project relies heavily on deprecated features or third-party libraries with
55.
47
limited support. Keepingup with Django's release cycle and ensuring compatibility with newer versions
may require additional effort.
Scalability Challenges: While Django is designed to scale with the needs of the application, scaling
Django applications to handle extremely high traffic or complex architectures may require careful
planning and optimization. Developers may need to implement caching, database sharding, or other
scalability techniques to address performance bottlenecks.
56.
48
6.1.2 SAMPLE CODE
Main.py
fromtkinter import messagebox
from tkinter import *
from tkinter import simpledialog
import tkinter
from tkinter import filedialog
import matplotlib.pyplot as plt
import numpy as np
from tkinter.filedialog import askopenfilename
import pandas as pd
from sklearn import *
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers.core import Dense,Activation,Dropout
from keras.callbacks import EarlyStopping
from sklearn.preprocessing import OneHotEncoder
from keras.optimizers import Adam
import os
main = tkinter.Tk()
main.title("Average Fuel Consumption") #designing main screen
main.geometry("1300x1200")
global filename
global train_x, test_x, train_y, test_y
global balance_data
global model
global ann_acc
global testdata
global predictdata
def importdata():
global balance_data
balance_data = pd.read_csv(filename)
balance_data = balance_data.abs()
return balance_data
57.
49
def splitdataset(balance_data):
global train_x,test_x, train_y, test_y
X = balance_data.values[:, 0:7]
y_ = balance_data.values[:, 7]
print(y_)
y_ = y_.reshape(-1, 1)
encoder = OneHotEncoder(sparse=False)
Y = encoder.fit_transform(y_)
print(Y)
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2)
text.insert(END,"Dataset Length : "+str(len(X))+"n");
return train_x, test_x, train_y, test_y
def upload(): #function to upload tweeter profile
global filename
filename = filedialog.askopenfilename(initialdir="dataset")
text.delete('1.0', END)
text.insert(END,filename+" loadednn");
def generateModel():
global train_x, test_x, train_y, test_y
data = importdata()
train_x, test_x, train_y, test_y = splitdataset(data)
text.insert(END,"Splitted Training Length : "+str(len(train_x))+"n");
text.insert(END,"Splitted Test Length : "+str(len(test_x))+"n");
def ann():
global model
global ann_acc
model = Sequential()
model.add(Dense(200, input_shape=(7,), activation='relu', name='fc1'))
model.add(Dense(200, activation='relu', name='fc2'))
model.add(Dense(19, activation='softmax', name='output'))
optimizer = Adam(lr=0.001)
model.compile(optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
print('CNN Neural Network Model Summary: ')
print(model.summary())
model.fit(train_x, train_y, verbose=2, batch_size=5, epochs=200)
58.
50
train_x, test_x, train_y,test_y = train_test_split(X, Y, test_size=0.2)
text.insert(END,"Dataset Length : "+str(len(X))+"n");
return train_x, test_x, train_y, test_y
def upload(): #function to upload tweeter profile
global filename
filename = filedialog.askopenfilename(initialdir="dataset")
text.delete('1.0', END)
text.insert(END,filename+" loadednn");
def generateModel():
global train_x, test_x, train_y, test_y
data = importdata()
train_x, test_x, train_y, test_y = splitdataset(data)
text.insert(END,"Splitted Training Length : "+str(len(train_x))+"n");
text.insert(END,"Splitted Test Length : "+str(len(test_x))+"n");
def ann():
global model
global ann_acc
model = Sequential()
model.add(Dense(200, input_shape=(7,), activation='relu', name='fc1'))
model.add(Dense(200, activation='relu', name='fc2'))
model.add(Dense(19, activation='softmax', name='output'))
optimizer = Adam(lr=0.001)
model.compile(optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
print('CNN Neural Network Model Summary: ')
print(model.summary())
model.fit(train_x, train_y, verbose=2, batch_size=5, epochs=200)
results = model.evaluate(test_x, test_y)
text.insert(END,"ANN Accuracy for dataset "+filename+"n");
text.insert(END,"Accuracy Score : "+str(results[1]*100)+"nn")
ann_acc = results[1] * 100
def predictFuel():
global testdata
global predictdata
text.delete('1.0', END)
59.
51
filename = filedialog.askopenfilename(initialdir="dataset")
testdata= pd.read_csv(filename)
testdata = testdata.values[:, 0:7]
predictdata = model.predict_classes(testdata)
print(predictdata)
for i in range(len(testdata)):
text.insert(END,str(testdata[i])+" Average Fuel Consumption : "+str(predictdata[i])+"n");
def graph():
x = []
y = []
for i in range(len(testdata)):
x.append(i)
y.append(predictdata[i])
plt.plot(x, y)
plt.xlabel('Vehicle ID')
plt.ylabel('Fuel Consumption/10KM')
plt.title('Average Fuel Consumption Graph')
plt.show()
font = ('times', 16, 'bold')
title = Label(main, text='A Machine Learning Model for Average Fuel Consumption in Heavy Vehicles')
title.config(bg='greenyellow', fg='dodger blue')
title.config(font=font)
title.config(height=3, width=120)
title.place(x=0,y=5)
font1 = ('times', 12, 'bold')
text=Text(main,height=20,width=150)
scroll=Scrollbar(text)
text.configure(yscrollcommand=scroll.set)
text.place(x=50,y=120)
text.config(font=font1)
font1 = ('times', 14, 'bold')
uploadButton = Button(main, text="Upload Heavy Vehicles Fuel Dataset", command=upload)
uploadButton.place(x=50,y=550)
uploadButton.config(font=font1)
55
7.SYSTEM TESTING
7.1 INTRODUCTIONTO TESTNG
The purpose of testing is to discover errors. Testing is the process of trying to discover every conceivable
fault or weakness in a work product. It provides a way to check the functionality of components, sub
assemblies, assemblies and/or a finished product It is the process of exercising software with the intent
of ensuring that the Software system meets its requirementsand user expectations and does not fail in an
unacceptable manner. There are various types of test. Each test type addresses a specific testing
requirement.
TYPES OF TESTS
Unit testing
Unit testing involves the design of test cases that validate that the internal program logic is functioning
properly, and that program inputs produce valid outputs. All decision branches andinternal code flow
should be validated. It is the testing of individual software units of the application .it is done after the
completion of an individual unit before integration. This is a structural testing, that relies on knowledge
of its construction and is invasive. Unit tests performbasic tests at component level and test a specific
business process, application, and/or system configuration. Unit tests ensure that each unique path of a
business process performs accuratelyto the documented specifications and contains clearly defined inputs
and expected results.
Integration testing
Integration tests are designed to test integrated software components to determine if they actually run as
one program. Testing is event driven and is more concerned with the basic outcome of screens or fields.
Integration tests demonstrate that although the components wereindividually satisfaction, as shown by
successfully unit testing, the combination of componentsis correct and consistent. Integration testing is
specifically aimed at exposing the problems that arise from the combination of components.
Functional test
Functional tests provide systematic demonstrations that functions tested are available asspecified by the
business and technical requirements, system documentation, and user manuals.Functional testing is
centered on the following items:
Valid Input : identified classes of valid input must be accepted. Invalid Input
identified classes of invalid input must be rejected.Functions
64.
56
Output : identifiedclasses of application outputs must be exercised.
Systems/Procedures : interfacing systems or procedures must be invoked.
Organization and preparation of functional tests is focused on requirements, key functions, or special test
cases. In addition, systematic coverage pertaining to identify Business process flows; data fields,
predefined processes, and successive processes must be considered for testing. Before functional testing
is complete, additional tests are identified and the effective value of current tests is determined.
System Test
System testing ensures that the entire integrated software system meets requirements. It tests a
configuration to ensure known and predictable results. An example of system testing is the configuration
oriented system integration test. System testing is based on process descriptionsand flows, emphasizing
pre-driven process links and integration points.
White Box Testing
White Box Testing is a testing in which in which the software tester has knowledge of the innerworkings,
structure and language of the software, or at least its purpose. It is purpose. It is usedto test areas that
cannot be reached from a black box level.
Black Box Testing
Black Box Testing is testing the software without any knowledge of the inner workings, structure or
language of the module being tested. Black box tests, as most other kinds of tests,must be written from
a definitive source document, such as specification or requirements document, such as specification or
requirements document. It is a testing in which the software
under test is treated, as a black box .you cannot “see” into it. The test provides inputs andresponds
to outputs without considering how the software works.
Unit Testing
Unit testing is usually conducted as part of a combined code and unit test phase of the softwarelifecycle,
although it is not uncommon for coding and unit testing to be conducted as two distinct phases.
65.
57
7.2 TESTING STRATEGIES
Fieldtesting will be performed manually and functional tests will be written in detail.
Test objectives
• All field entries must work properly.
• Pages must be activated from the identified link.
• The entry screen, messages and responses must not be delayed.
Features to be tested
• Verify that the entries are of the correct format
• No duplicate entries should be allowed
• All links should take the user to the correct page.
•
Integration Testing
Software integration testing is the incremental integration testing of two or more integratedsoftware
components on a single platform to produce failures caused by interface defects.
The task of the integration test is to check that components or software applications, e.g.components
in a software system or – one step up – software applications at the company level
– interact without error.
Test Results: All the test cases mentioned above passed successfully. No defects encountered.
Acceptance Testing
User Acceptance Testing is a critical phase of any project and requires significant participationby the
end user. It also ensures that the system meets the functional requirements.
Test Results: All the test cases mentioned above passed successfully. No defects encountered
59
8.SCREENSHOTS
A MACHINE LEARNINGMODEL FOR AVERAGE FUEL CONSUMPTION IN
HEAVY VEHICLES
In this paper author is describing concept to predict average fuel consumption in heavy vehicles using
Machine Learning Algorithm such as ANN (Artificial Neural Networks). To predict fuel consumption
author has extracted 7 predictor features from heavy vehicle dataset such as
num_stops, time_stopped, average_moving_speed, characteristic_acceleration,
aerodynamic_speed_squared, change_ in_kinetic_energy, change_in_potential_energy, class
Above seven features are recorded from each vehicle travel up to 100 kilo meters like number of times
vehicle stop, total stopped time taken etc. All this values are collected from heavy vehicle and use as
dataset to train ANN model. Below are some value from above seven predictor features.
num_stops, time_stopped, average_moving_speed, characteristic_acceleration,
aerodynamic_speed_squared, change_ in_kinetic_energy, change_in_potential_energy, class
7.0, 7.0, 93.0, 34, 8.4, 4, 25.6, 9
7.0, 7.0, 91.0, 34, 8.3, 4, 25.7, 9
8.9, 8.9, 151.0, 26, 10.9, 6, 15.1, 12
9.3, 9.3, 160.0, 25, 11.3, 6, 13.7, 13
8.4, 8.4, 158.0, 25, 11.2, 6, 13.8, 13
All bold names are the dataset column names and all double values are the dataset values for each vehicle.
Last column will be consider as class name which represents fuel consumption for that vehicle. Entire
dataset will be used to train ANN model and whenever we give new record then ANN algorithm will
apply train model on that test record to predict it average fuel consumption.
Below are some test records
num_stops, time_stopped, average_moving_speed, characteristic_acceleration,
aerodynamic_speed_squared, change_ in_kinetic_energy, change_in_potential_energy
7.0, 7.0, 93.0, 34, 8.4, 4, 25.6
7.0, 7.0, 91.0, 34, 8.3, 4, 25.7
68.
60
8.9, 8.9, 151.0,26, 10.9, 6, 15.1
9.3, 9.3, 160.0, 25, 11.3, 6, 13.7
8.4, 8.4, 158.0, 25, 11.2, 6, 13.8
In above test data class value as fuel consumption is not there and when we applied this test record on
ANN model then ANN will predict fuel consumption class value for that test record. Entire train and test
data available inside ‘dataset’ folder.
The ANN model is developed by using duty cycle’s dataset collected from a single truck, with an
approximate mass of 8, 700kg exposed to a variety of transients including both urban and highway traffic
in the Indianapolis area. Data was collected using the SAE J1939 standard for serial control and
communications in heavy duty vehicle networks.
ANN WORKING PROCEDURE
To demonstrate how to build an ANN neural network based image classifier, we shall build a 6 layer
neural network that will identify and separate one image from other. This network that we shall build is
a very small network that we can run on a CPU as well. Traditional neural networks that are very good
at doing image classification have many more parameters and take a lot of time if trained on normal
CPU. However, our objective is to show how to build a real-world convolutional neural network using
tensor flow.
Neural Networks are essentially mathematical models to solve an optimization problem. They are made
of neurons, the basic computation unit of neural networks. A neuron takes an input (say x), do some
computation on it (say: multiply it with a variable w and adds another variable b) to produce a value (say;
z= wx + b). This value is passed to a non-linear function called activation function (f) to produce the
final output (activation) of a neuron. There are many kinds of activation functions. One of the popular
activation function is Sigmoid. The neuron which uses sigmoid function as an activation function will
be called sigmoid neuron. Depending on the activation functions, neurons are named and there are many
kinds of them like RELU, TanH.
If you stack neurons in a single line, it’s called a layer; which is the next building block of neural
networks. See below image with layers
69.
61
To predict imageclass multiple layers operate on each other to get best match layer and this process
continues till no more improvement left.
Modules Information
This project consists of following modules
Upload Heavy Vehicles Fuel Dataset: Using this module we can upload train dataset to application.
Dataset contains comma separated values.
Read Dataset & Generate Model: Using this module we will parse comma separated dataset and then
generate train and test model for ANN from that dataset values. Dataset will be divided into 80% and
20% format, 80% will be used to train ANN model and 20% will be used to test ANN model.
Run ANN Algorithm: Using this model we can create ANN object and then feed train and test data to
build ANN model.
Predict Average Fuel Consumption: Using this module we will upload new test data and then ANN will
apply train model on that test data to predict average fuel consumption for that test records.
Fuel Consumption Graph: Using this module we will plot fuel consumption graph for each test record.
Screen shots
To run this project double click on ‘run.bat’ file to get below screen
70.
62
SCREENSHOT-1
In above screenclick on ‘Upload Heavy Vehicles Fuel Dataset’ button to upload train
dataset
FIG-1
SCREENSHOT-2
In above screen uploading ‘Fuel_Dataset.txt’ which can be used to train model. After
uploading dataset will get below screen
71.
63
SCREENSHOT-3
FIG-2
Now in abovescreen click on ‘Read Dataset & Generate Model’ button to read uploaded
dataset and to generate train and test data
SCREENSHOT-4
FIG-3
In above screen we can see total number of records in dataset, number of records used for
training and number for records used for testing. Now click on ‘Run ANN Algorithm’
button to input train and test data to ANN to build ANN model
72.
64
SCREENSHOT-6
In above blackconsole we can see all ANN processing details, After building model will
get below screen
SCREENSHOT-7
In above screen we got ANN prediction accuracy upto 86%. Now click on ‘Predict
Average Fuel Consumption’ button to upload test data and to predict consumption for test
data
FIG-4
73.
65
SCREENSHOT-8
After uploading testdata will get fuel consumption prediction result in below screen
SCREENSHOT-9
In above screen we got average fuel consumption for each test record per 100 kilo meter.
Now click on ‘Fuel Consumption Graph’ to view below graph
74.
66
SCREENSHOT-10
FIG-5
In above graphx-axis represents test record number as vehicle id and y-axis represents
fuel consumption for that record.
Conclusion: Using this paper and ANN algorithm we are predicting fuel consumption for
test data
75.
67
9.CONCLUSION
This paper presenteda machine learning model that can be conveniently developed for each heavy
vehicle in a fleet. The model relies on seven predictors: number of stops, stop time, average moving
speed, characteristic acceleration, aerodynamic speed squared, change in kinetic energy and change in
potential energy. The last two predictors are introduced in this paper to help capture the average dynamic
behavior of the vehicle. All of the predictors of the model are derived from vehicle speed and road grade.
These variables are readily available from telematics devices that are becoming an integral part of
connected vehicles. Moreover, the predictors can be easily computed on-board from these two variables.
The model predictors are aggregated over a fixed distance traveled (i.e., window) instead of a fixed time
interval. This mapping of the input space to the distance domain aligns with the domain of the target
output, and produced a machine learning model for fuel consumption with an RMSE < 0.015 l/100 km.
Different model configurations with 1, 2, and 5 km window sizes were evaluated. The results show that
the 1 km window has the highest accuracy. This model is able to predict the actual fuel consumption on
a per 1 km-basis with a CD of 0.91. This performance is closer to that of physics-based models and the
proposed model improves upon previous machine learning models that show comparable results only for
entire long-distance trips.
Selecting an adequate window size should take into consideration the cost of the model in terms of data
collection and onboard computation. Moreover, the window size is likely to be application-dependent.
For fleets with short trips (e.g., construction vehicles within a site) or urban traffic routes, a 1 km window
size is recommended. For long-haul fleets, a 5 km window size may be sufficient. In this study, the duty
cycles consisted of both highway and city traffic and therefore, the 1 km window was more adequate
than the 5 km window. Future work includes understanding these differentiating factors and the selection
of the appropriate window size. Expanding the model to other vehicles with different characteristics such
as varying masses and aging vehicles is being studied. Predictors for these characteristics will be added
in order to allow for the same model to capture the impact on fuel consumption due to changes in vehicle
mass and wear.
76.
68
10.REFERENCES
[1] B. Lee,L. Quinones, and J. Sanchez, “Development of greenhouse gas emissions model for 2014-2017 heavy-
and medium-duty vehicle compliance,” SAE Technical Paper, Tech. Rep., 2011.
[2] G. Fontaras, R. Luz, K. Anagnostopoulus, D. Savvidis, S. Hausberger, and M. Rexeis, “Monitoring co2
emissions from hdv in europe-an experimental proof of concept of the proposed methodolgical approach,” in 20th
International Transport and Air Pollution Conference, 2014.
[3] S. Wickramanayake and H. D. Bandara, “Fuel consumption prediction of fleet vehicles using machine learning:
A comparative study,” in Moratuwa Engineering Research Conference (MERCon), 2016. IEEE, 2016, pp. 90–95.
[4] L. Wang, A. Duran, J. Gonder, and K. Kelly, “Modeling heavy/mediumduty fuel consumption based on drive
cycle properties,” SAE Technical Paper, Tech. Rep., 2015.
[5] Fuel Economy and Greenhouse gas exhaust emissions of motor vehicles Subpart B - Fuel Economy and
Carbon-Related Exhaust Emission Test Procedures, Code of Federal Regulations Std. 600.111-08, Apr 2014.
[6] SAE International Surface Vehicle Recommended Practice, Fuel Consumption Test Procedure - Type II,
Society of Automotive Engineers Std., 2012.
[7] F. Perrotta, T. Parry, and L. C. Neves, “Application of machine learning for fuel consumption modelling of
trucks,” in Big Data (Big Data), 2017 IEEE International Conference on. IEEE, 2017, pp. 3810–3815.
[8] S. F. Haggis, T. A. Hansen, K. D. Hicks, R. G. Richards, and R. Marx, “In-use evaluation of fuel economy and
emissions from coal haul trucks using modified sae j1321 procedures and pems,” SAE International Journal of
Commercial Vehicles, vol. 1, no. 2008-01-1302, pp. 210–221, 2008.
[9] A. Ivanco, R. Johri, and Z. Filipi, “Assessing the regeneration potential for a refuse truck over a real-world
duty cycle,” SAE International Journal of Commercial Vehicles, vol. 5, no. 2012-01-1030, pp. 364–370, 2012.
[10] A. A. Zaidi, B. Kulcsr, and H. Wymeersch, “Back-pressure traffic signal control with fixed and adaptive
routing for urban vehicular networks.
![A MAJOR PROJECT REPORT
ON
“HEAVY VEHICLE FUEL EFFICIENCY PREDICTION USING
MACHINE LEARNING”
Submitted to
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
In partial fulfillment of the requirements for the award of degree of
BACHELOR OF TECHNOLOGY
IN
COMPUTER SCIENCE AND ENGINEERING
Submitted
By
N. SOUJANYA [20D41A05E6]
P. JAGADEESH [20D41A05G5]
P. NARESH [20D41A05G3]
M.NAGARAJU [20D41A05C4]
Under the esteemed guidance of
Mr. K. VIJAY KUMAR
(Assistant Professor)
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
(An Autonomous Institution under UGC, Accredited by NBA, Affiliated to JNTUH)
Sheriguda (V), Ibrahimpatnam (M), Ranga Reddy Dist. – 501 510
(2023-2024)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-1-320.jpg)
![A MAJOR PROJECT REPORT
ON
“HEAVY VEHICLE FUEL EFFICIENCY PREDICTION USING
MACHINE LEARNING”
Submitted to
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
In partial fulfillment of the requirements for the award of degree of
BACHELOR OF TECHNOLOGY
IN
COMPUTER SCIENCE AND ENGINEERING
Submitted
By
N. SOUJANYA [20D41A05E6]
P. JAGADEESH [20D41A05G5]
P. NARESH [20D41A05G3]
M.NAGARAJU [20D41A05C4]
Under the esteemed guidance of
Mr. K. VIJAY KUMAR
(Assistant Professor)
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
(An Autonomous Institution under UGC, Accredited by NBA, Affiliated to JNTUH)
Sheriguda (V), Ibrahimpatnam (M), Ranga Reddy Dist. – 501 510
(2023-2024)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/75/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-1-2048.jpg)
![SRI INDU COLLEGE OF ENGINEERING AND TECHNOLOGY
(An Autonomous Institution under UGC, Accredited by NBA, Affiliated to JNTUH)
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
CERTIFICATE
Certified that the Major project entitled “HEAVY VEHICLE FUEL EFFICIENCY PREDICTION
USING MACHINE LEARNING” is a bonafide work carried out by N. SOUJANYA [20D41A05E6],
P.JAGADEESH [20D41A05G5], P.NARESH [20D41A05G3], M.NAGARAJU [20D41A05C4] in
partial fulfillment for the award of degree of Bachelor of Technology in Computer Science and
Engineering of SICET, Hyderabad for the academic year 2023-2024.The project has been approved as
it satisfies academic requirements in respect of the work prescribed for IV Year, II-Semester of B. Tech
course.
INTERNAL GUIDE HEAD OF THE DEPARTMENT
(Mr.K.VIJAY KUMAR) (Prof .CH.G.V.N.PRASAD)
(Assistant Professor)
EXTERNAL EXAMINER](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-2-320.jpg)
![ACKNOWLEDGEMENT
The satisfaction that accompanies the successful completion of the task would be put incomplete
without the mention of the people who made it possible, whose constant guidance and encouragement
crown all the efforts with success. We are thankful to Principal Dr. G. SURESH for giving us the
permission to carry out this project. We are highly indebted to Prof. CH.G.V.N.PRASAD, Head of
the Department of Computer Science and Engineering, for providing necessary infrastructure andlabs
and also valuable guidance at every stage of this project. We are grateful to our internal project guide
Mr.K.VIJAY KUMAR(Assistant Professor)for his constant motivation and guidance given by him
during the execution of this project work. We would like to thank the Teaching & Non-Teaching staff
of Department of ComputerScience and engineering for sharing their knowledge with us, last but not
least we express our sincere thanks to everyone who helped directly or indirectly for the completion of
this project.
N. SOUJANYA [20D41A05E6]
P. JAGADEESH [20D41A05G5]
P. NARESH [20D41A05G3]
M.NAGARAJU [20D41A05C4]](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-3-320.jpg)



![1
1.INTRODUCTION
1.1 INTRODUCTION TO PROJECT
FUEL consumption models for vehicles are of interest to manufacturers, regulators, and consumers.They
are needed across all the phases of the vehicle life-cycle. In this paper, we focus on modeling average
fuel consumption for heavy vehicles during the operation and maintenance phase. In
general, techniques used to develop models for fuel consumption fall under three main
categories:Physics-based models, which are derived from an in-depth understanding of the physical
system. These models describe the dynamics of the components of the vehicle at each time step using
detailed mathematical equations.
Machine learning models, which are data-driven and represent an abstract mapping from an input space
consisting of a selected set of predictors to an output space that represents the target output, in this case
average fuel consumption Statistical models, which are also data-driven and establish a mapping between
the probability distribution of a selected set of predictors and the target outcomeTrade-offs among the
above techniques are primarily with respect to cost and accuracy as per the requirements of the intended
application.
In this paper, a model that can be easily developed for individual heavy vehicles in a large fleet is
proposed. Relying on accurate models of all of the vehicles in a fleet, a fleet manager can optimize the
route planning for all of the vehicles based on each unique vehicle predicted fuel consumption thereby
ensuring the route assignments are aligned to minimize overall fleet fuel consumption. These types of
fleets exist in various sectors including, road transportation of goods [7], public transportation [3],
construction trucks [8] and refuse trucks [9]. For each fleet, the methodology must apply and adapt to
many different vehicle technologies (including future ones) and configurations without detailed
knowledge of the vehicles specific physical characteristics and measurements. These requirements make
machine learning the technique of choice when taking into consideration the desired accuracy versus the
cost of the development and adaptation of an individualized model for each vehicle in the fleet.
Several previous models for both instantaneous and average fuel consumption have been proposed.
Physics-based models are best suited for predicting instantaneous fuel consumption [1], [2] because they
can capture the dynamics of the behavior of the system at different time steps. Machine learning models
are not able to predict instantaneous fuel consumption [3] with a high level of accuracy because of the
difficulty associated with identifying patterns in instantaneous data. However, these models are able to
identify and learn trends in average fuel consumption with an adequate level of accuracy](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-9-320.jpg)
![2
reviously proposed machine learning models for average fuel consumption use a set of predictors that are
collected over a time period to predict the corresponding fuel consumption in terms of either gallons per
mile or liters per kilometer. While still focusing on average fuel consumption, our proposed approach
differs from that used in previous models because the input space of the predictors is quantized with
respect to a fixed distance as opposed to a fixed time period. In the proposed model, all the predictors are
aggregated with respect to a fixed window that represents the distance traveled by the vehicle thereby
providing a better mapping from the input space to the output space of the model. In contrast, previous
machine learning models must not only learn the patterns in the input data but also perform a conversion
from the time-based scale of the input domain to the distance-based scale of the output domain (i.e.,
average fuel consumption). Using the same scale for both the input and output spaces of the model offers
several benefits:
Data is collected at a rate that is proportional to its impact on the outcome. When the input space is
sampled with respect to time, the amount of data collected from a vehicle at a stop is the same as the
amount of data collected when the vehicle is moving.
The predictors in the model are able to capture the impact of both the duty cycle and the environment on
the average fuel consumption of the vehicle (e.g., the number of stops in an urban traffic over a given
distance).
Data from raw sensors can be aggregated on-board into few predictors with lower storage and
transmission bandwidth requirements. Given the increase in computational capabilities of new vehicles,
data summarization is best performed on-board near the source of the data.
New technologies such as V2I and dynamic traffic management [10]–[12] can be leveraged for additional
fuel efficiency optimization at the level of each specific vehicle, route and time of day.](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-10-320.jpg)


![5
2.SYSTEM ANALYSIS
2.1 Existing System & its Disadvantages:
model that can be easily developed for individual heavy vehicles in a large fleet is proposed.
Relying on accurate models of all of the vehicles in a fleet, a fleet manager can optimize the route
planning for all of the vehicles based on each unique vehicle predicted fuel consumption thereby
ensuring the route assignments are aligned to minimize overall fleet fuel consumption.
This approach is used in conjunction with seven predictors derived from vehicle speed and road
grade to produce a highly predictive neural network model for average fuel consumption in heavy
vehicles. Different window sizes are evaluated and the results show that a 1 km window is able
to predict fuel consumption with a 0.91 coefficient of determination and mean absolute peak-to-
peak percent error less than 4% for routes that include both city and highway duty cycle
segments.
Disadvantages of existing system:
• Physics-based models, which are derived from an in-depth understanding of the physical system.
These models describe the dynamics of the components of the vehicle each time step using detailed
mathematical equations.
• Statistical models, which are also data-driven and establish a mapping between the probability
distribution of a selected set of predictors and the target outcome.
2.2 PROPOSED SYSTEM & IT’S ADVANTAGES:
As mentioned above Artificial Neural Networks (ANN) are often used to develop digital models for
complex systems. The models proposed in [15] highlight some of the difficulties faced by machine learning
models when the input and output have different domains. In this study, the input is aggregated in the time
domain over 10 minutes intervals and the output is fuel consumption over the distance traveled during the
same time period.The complex system is represented by a transfer function F(p) = o, where F(·) represents
the system, p refers to the input predictors and o is the response of the system or the output. The ANNs
used in this paper are Feed Forward Neural Networks (FNN).
Training is an iterative process and can be performed using multiple approaches including particle swarm
optimization [20] and back propagation.Other approaches will be considered in future work in order to](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-13-320.jpg)


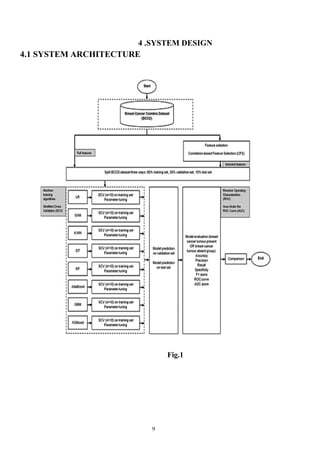


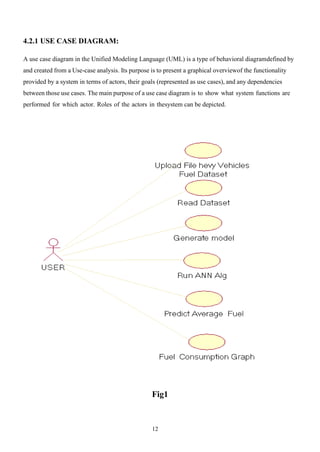



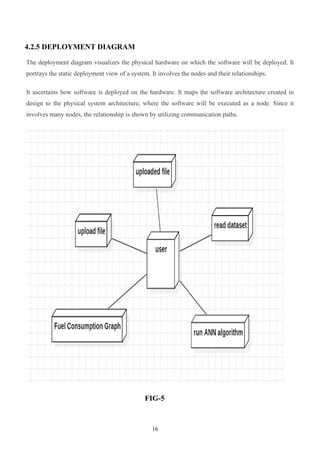
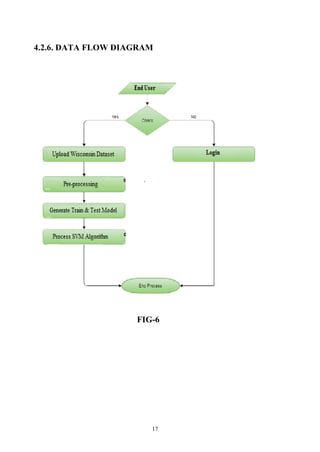


















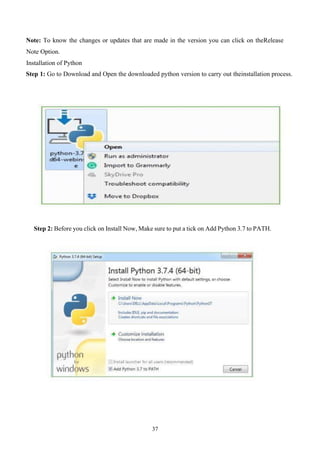
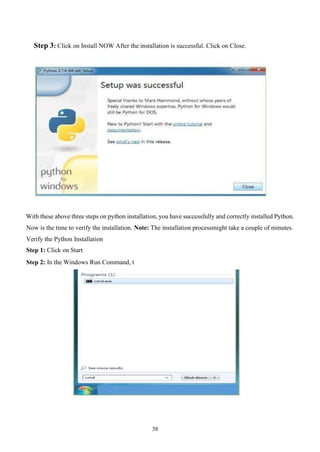
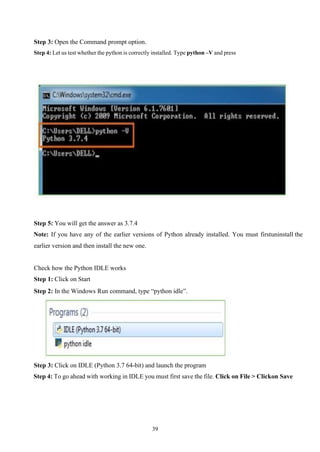
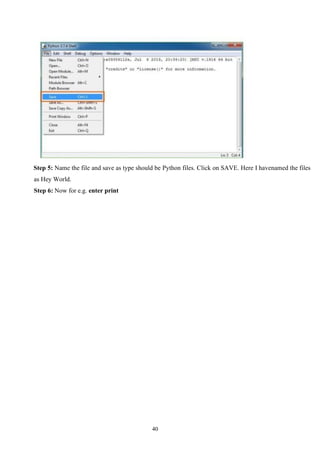








![49
def splitdataset(balance_data):
global train_x, test_x, train_y, test_y
X = balance_data.values[:, 0:7]
y_ = balance_data.values[:, 7]
print(y_)
y_ = y_.reshape(-1, 1)
encoder = OneHotEncoder(sparse=False)
Y = encoder.fit_transform(y_)
print(Y)
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2)
text.insert(END,"Dataset Length : "+str(len(X))+"n");
return train_x, test_x, train_y, test_y
def upload(): #function to upload tweeter profile
global filename
filename = filedialog.askopenfilename(initialdir="dataset")
text.delete('1.0', END)
text.insert(END,filename+" loadednn");
def generateModel():
global train_x, test_x, train_y, test_y
data = importdata()
train_x, test_x, train_y, test_y = splitdataset(data)
text.insert(END,"Splitted Training Length : "+str(len(train_x))+"n");
text.insert(END,"Splitted Test Length : "+str(len(test_x))+"n");
def ann():
global model
global ann_acc
model = Sequential()
model.add(Dense(200, input_shape=(7,), activation='relu', name='fc1'))
model.add(Dense(200, activation='relu', name='fc2'))
model.add(Dense(19, activation='softmax', name='output'))
optimizer = Adam(lr=0.001)
model.compile(optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
print('CNN Neural Network Model Summary: ')
print(model.summary())
model.fit(train_x, train_y, verbose=2, batch_size=5, epochs=200)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-57-320.jpg)
![50
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2)
text.insert(END,"Dataset Length : "+str(len(X))+"n");
return train_x, test_x, train_y, test_y
def upload(): #function to upload tweeter profile
global filename
filename = filedialog.askopenfilename(initialdir="dataset")
text.delete('1.0', END)
text.insert(END,filename+" loadednn");
def generateModel():
global train_x, test_x, train_y, test_y
data = importdata()
train_x, test_x, train_y, test_y = splitdataset(data)
text.insert(END,"Splitted Training Length : "+str(len(train_x))+"n");
text.insert(END,"Splitted Test Length : "+str(len(test_x))+"n");
def ann():
global model
global ann_acc
model = Sequential()
model.add(Dense(200, input_shape=(7,), activation='relu', name='fc1'))
model.add(Dense(200, activation='relu', name='fc2'))
model.add(Dense(19, activation='softmax', name='output'))
optimizer = Adam(lr=0.001)
model.compile(optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
print('CNN Neural Network Model Summary: ')
print(model.summary())
model.fit(train_x, train_y, verbose=2, batch_size=5, epochs=200)
results = model.evaluate(test_x, test_y)
text.insert(END,"ANN Accuracy for dataset "+filename+"n");
text.insert(END,"Accuracy Score : "+str(results[1]*100)+"nn")
ann_acc = results[1] * 100
def predictFuel():
global testdata
global predictdata
text.delete('1.0', END)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-58-320.jpg)
![51
filename = filedialog.askopenfilename(initialdir="dataset")
testdata = pd.read_csv(filename)
testdata = testdata.values[:, 0:7]
predictdata = model.predict_classes(testdata)
print(predictdata)
for i in range(len(testdata)):
text.insert(END,str(testdata[i])+" Average Fuel Consumption : "+str(predictdata[i])+"n");
def graph():
x = []
y = []
for i in range(len(testdata)):
x.append(i)
y.append(predictdata[i])
plt.plot(x, y)
plt.xlabel('Vehicle ID')
plt.ylabel('Fuel Consumption/10KM')
plt.title('Average Fuel Consumption Graph')
plt.show()
font = ('times', 16, 'bold')
title = Label(main, text='A Machine Learning Model for Average Fuel Consumption in Heavy Vehicles')
title.config(bg='greenyellow', fg='dodger blue')
title.config(font=font)
title.config(height=3, width=120)
title.place(x=0,y=5)
font1 = ('times', 12, 'bold')
text=Text(main,height=20,width=150)
scroll=Scrollbar(text)
text.configure(yscrollcommand=scroll.set)
text.place(x=50,y=120)
text.config(font=font1)
font1 = ('times', 14, 'bold')
uploadButton = Button(main, text="Upload Heavy Vehicles Fuel Dataset", command=upload)
uploadButton.place(x=50,y=550)
uploadButton.config(font=font1)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-59-320.jpg)
![52
modelButton = Button(main, text="Read Dataset & Generate Model", command=generateModel)
modelButton.place(x=420,y=550)
modelButton.config(font=font1)
annButton = Button(main, text="Run ANN Algorithm", command=ann)
annButton.place(x=760,y=550)
annButton.config(font=font1)
predictButton = Button(main, text="Predict Average Fuel Consumption", command=predictFuel)
predictButton.place(x=50,y=600)
predictButton.config(font=font1)
graphButton = Button(main, text="Fuel Consumption Graph", command=graph)
graphButton.place(x=420,y=600)
graphButton.config(font=font1)
exitButton = Button(main, text="Exit", command=exit)
exitButton.place(x=760,y=600)
exitButton.config(font=font1)
main.config(bg='LightSkyBlue')
main.mainloop()
results = model.evaluate(test_x, test_y)
text.insert(END,"ANN Accuracy for dataset "+filename+"n");
text.insert(END,"Accuracy Score : "+str(results[1]*100)+"nn")
ann_acc = results[1] * 100
def predictFuel():
global testdata
global predictdata
text.delete('1.0', END)
filename = filedialog.askopenfilename(initialdir="dataset")
testdata = pd.read_csv(filename)
testdata = testdata.values[:, 0:7]
predictdata = model.predict_classes(testdata)
print(predictdata)
for i in range(len(testdata)):](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-60-320.jpg)
![53
text.insert(END,str(testdata[i])+" Average Fuel Consumption : "+str(predictdata[i])+"n");
def graph():
x = []
y = []
for i in range(len(testdata)):
x.append(i)
y.append(predictdata[i])
plt.plot(x, y)
plt.xlabel('Vehicle ID')
plt.ylabel('Fuel Consumption/10KM')
plt.title('Average Fuel Consumption Graph')
plt.show()
font = ('times', 16, 'bold')
title = Label(main, text='A Machine Learning Model for Average Fuel Consumption in Heavy Vehicles')
title.config(bg='greenyellow', fg='dodger blue')
title.config(font=font)
title.config(height=3, width=120)
title.place(x=0,y=5)
font1 = ('times', 12, 'bold')
text=Text(main,height=20,width=150)
scroll=Scrollbar(text)
text.configure(yscrollcommand=scroll.set)
text.place(x=50,y=120)
text.config(font=font1)
font1 = ('times', 14, 'bold')
uploadButton = Button(main, text="Upload Heavy Vehicles Fuel Dataset", command=upload)
uploadButton.place(x=50,y=550)
uploadButton.config(font=font1)
modelButton = Button(main, text="Read Dataset & Generate Model", command=generateModel)
modelButton.place(x=420,y=550)
modelButton.config(font=font1)
annButton = Button(main, text="Run ANN Algorithm", command=ann)
annButton.place(x=760,y=550)](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-61-320.jpg)




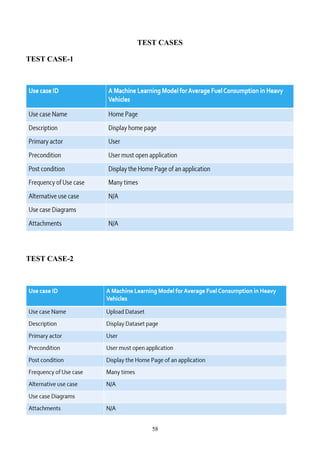



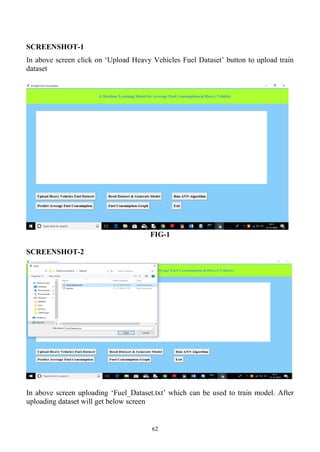

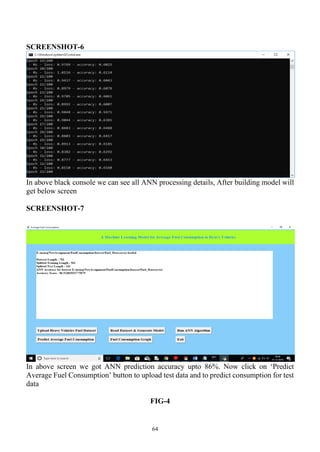
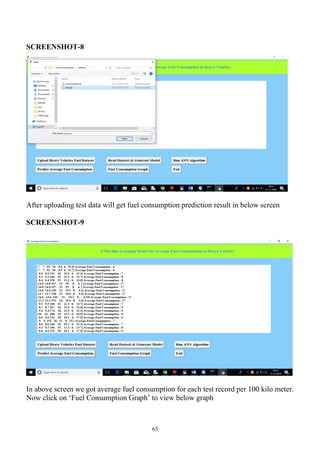
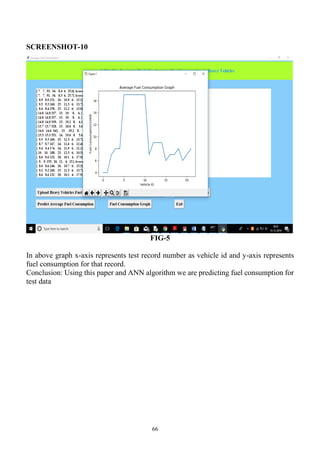

![68
10.REFERENCES
[1] B. Lee, L. Quinones, and J. Sanchez, “Development of greenhouse gas emissions model for 2014-2017 heavy-
and medium-duty vehicle compliance,” SAE Technical Paper, Tech. Rep., 2011.
[2] G. Fontaras, R. Luz, K. Anagnostopoulus, D. Savvidis, S. Hausberger, and M. Rexeis, “Monitoring co2
emissions from hdv in europe-an experimental proof of concept of the proposed methodolgical approach,” in 20th
International Transport and Air Pollution Conference, 2014.
[3] S. Wickramanayake and H. D. Bandara, “Fuel consumption prediction of fleet vehicles using machine learning:
A comparative study,” in Moratuwa Engineering Research Conference (MERCon), 2016. IEEE, 2016, pp. 90–95.
[4] L. Wang, A. Duran, J. Gonder, and K. Kelly, “Modeling heavy/mediumduty fuel consumption based on drive
cycle properties,” SAE Technical Paper, Tech. Rep., 2015.
[5] Fuel Economy and Greenhouse gas exhaust emissions of motor vehicles Subpart B - Fuel Economy and
Carbon-Related Exhaust Emission Test Procedures, Code of Federal Regulations Std. 600.111-08, Apr 2014.
[6] SAE International Surface Vehicle Recommended Practice, Fuel Consumption Test Procedure - Type II,
Society of Automotive Engineers Std., 2012.
[7] F. Perrotta, T. Parry, and L. C. Neves, “Application of machine learning for fuel consumption modelling of
trucks,” in Big Data (Big Data), 2017 IEEE International Conference on. IEEE, 2017, pp. 3810–3815.
[8] S. F. Haggis, T. A. Hansen, K. D. Hicks, R. G. Richards, and R. Marx, “In-use evaluation of fuel economy and
emissions from coal haul trucks using modified sae j1321 procedures and pems,” SAE International Journal of
Commercial Vehicles, vol. 1, no. 2008-01-1302, pp. 210–221, 2008.
[9] A. Ivanco, R. Johri, and Z. Filipi, “Assessing the regeneration potential for a refuse truck over a real-world
duty cycle,” SAE International Journal of Commercial Vehicles, vol. 5, no. 2012-01-1030, pp. 364–370, 2012.
[10] A. A. Zaidi, B. Kulcsr, and H. Wymeersch, “Back-pressure traffic signal control with fixed and adaptive
routing for urban vehicular networks.](https://image.slidesharecdn.com/ijeee-heavyvehiclefuelefficiencypredictionusingmachinelearning-250225055800-f85ac649/85/IJEEE-HEAVY-VEHICLE-FUEL-EFFICIENCY-PREDICTION-USING-MACHINE-LEARNING-pdf-76-320.jpg)












































![FAKE SOCIAL MEDIA ACCOUNT DETECTION DOCUMENTATION[6][1] (1).docx](https://cdn.slidesharecdn.com/ss_thumbnails/fakesocialmediaaccountdetectiondocumentation611-250830044225-8915adf4-thumbnail.jpg?width=640&height=640&fit=bounds)





















