Download to read offline



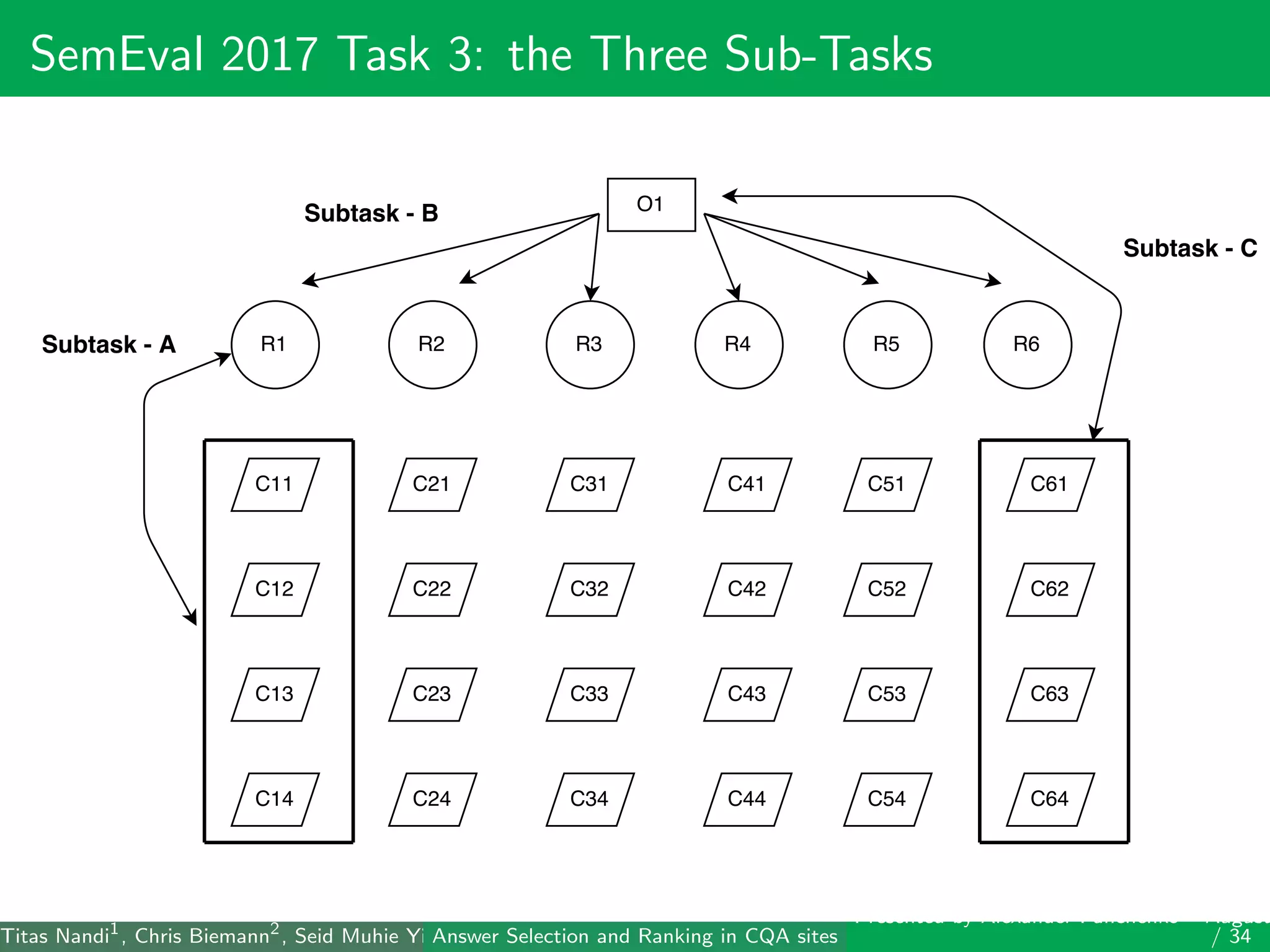


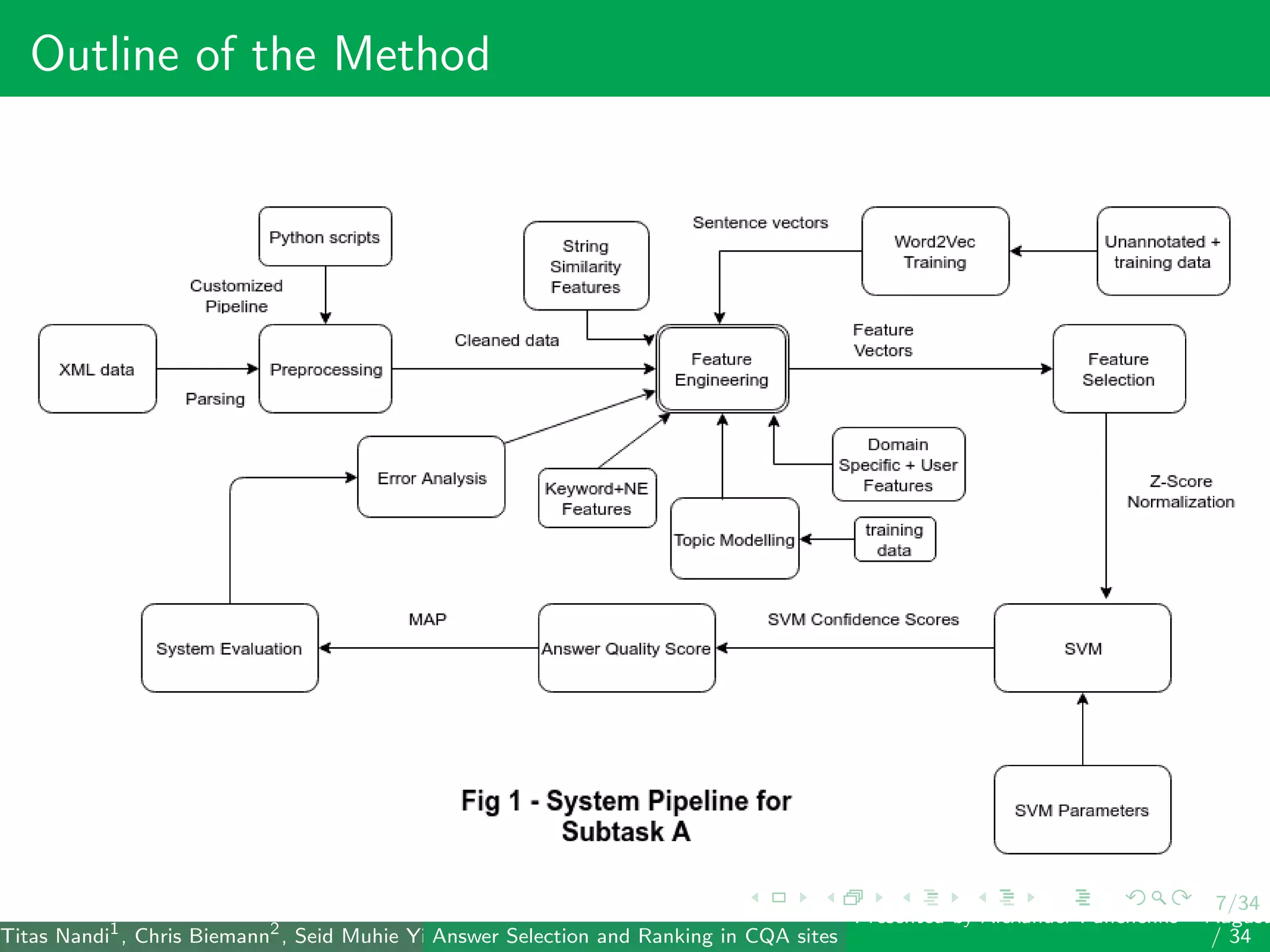









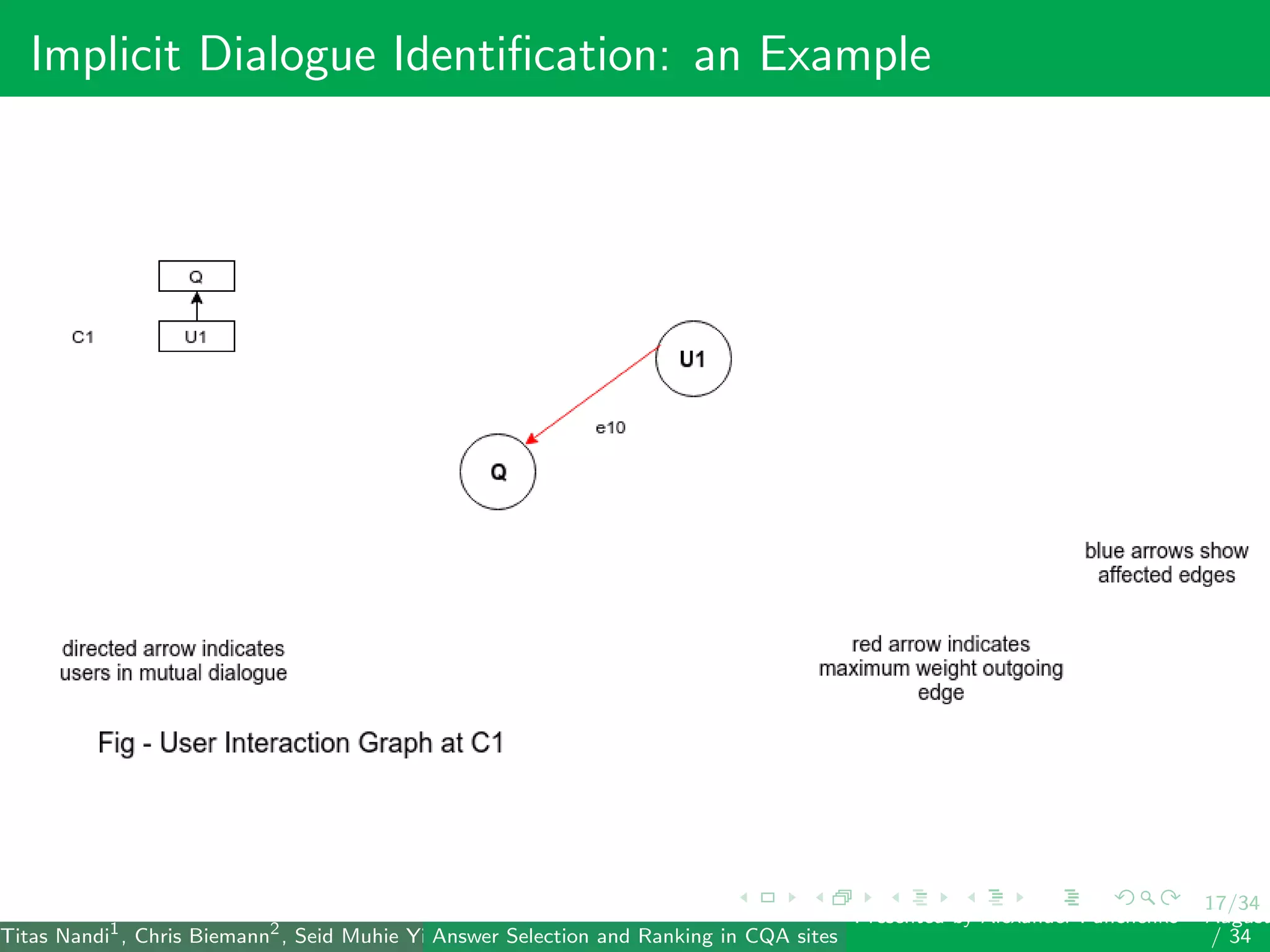
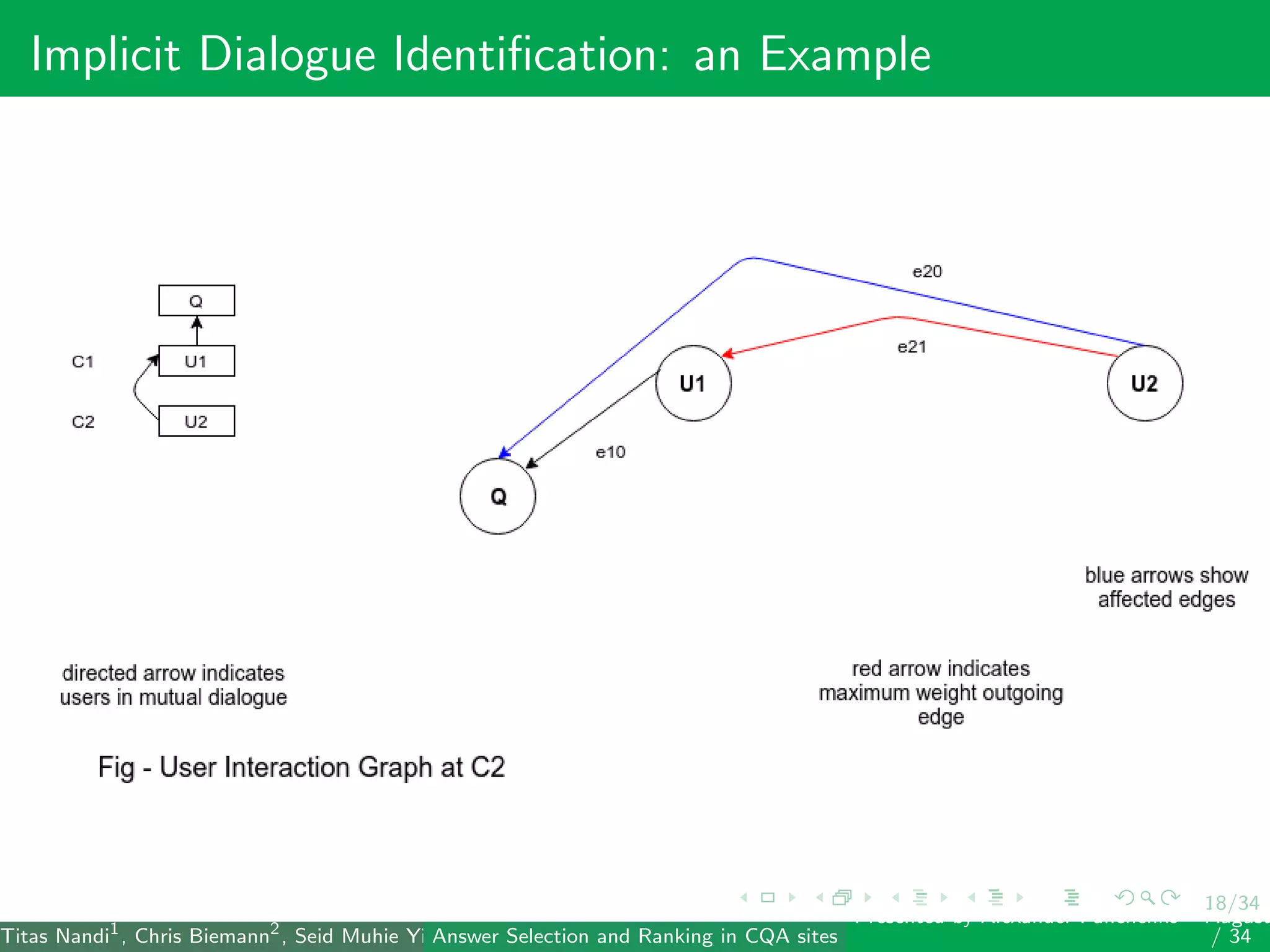
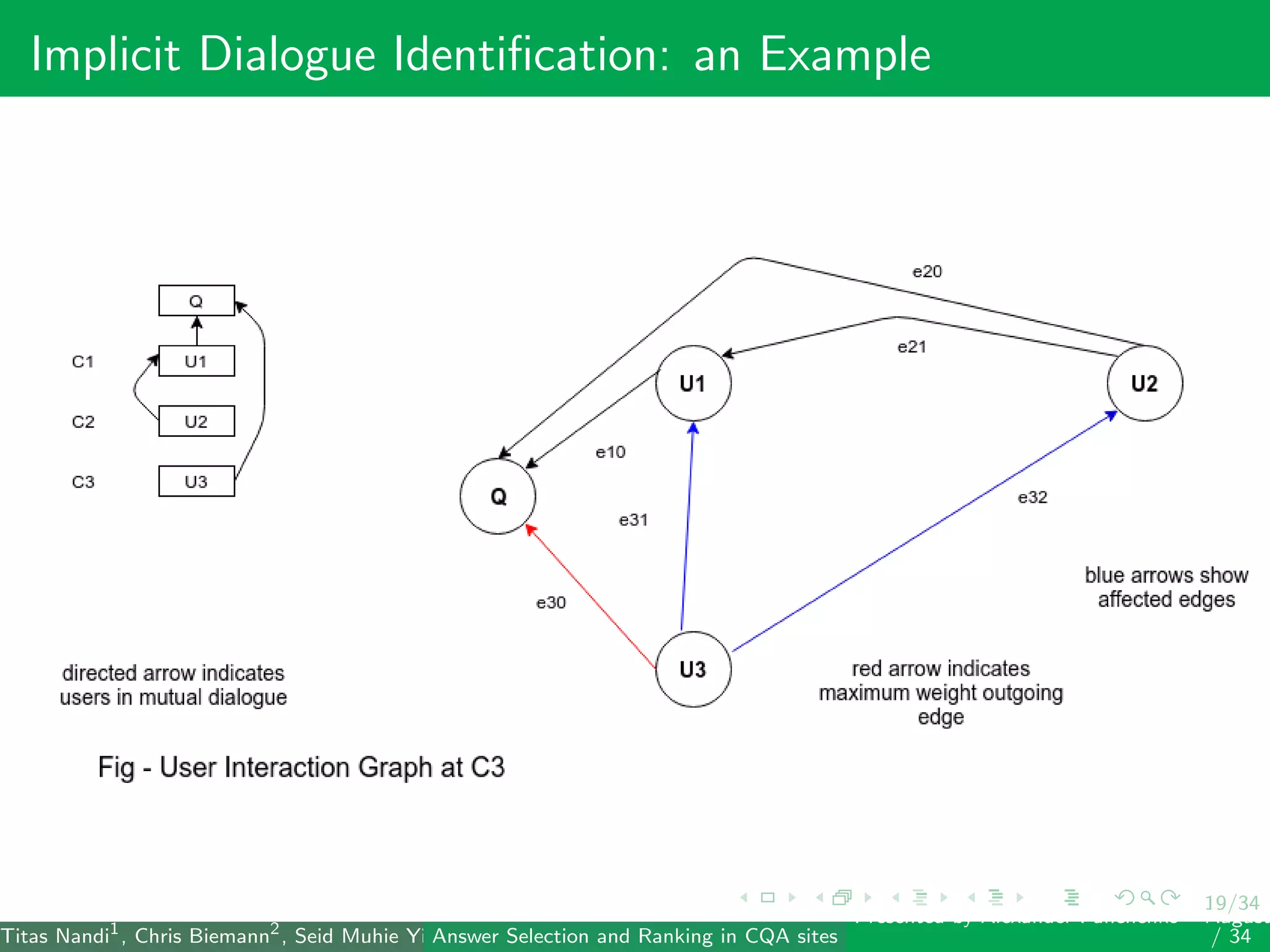
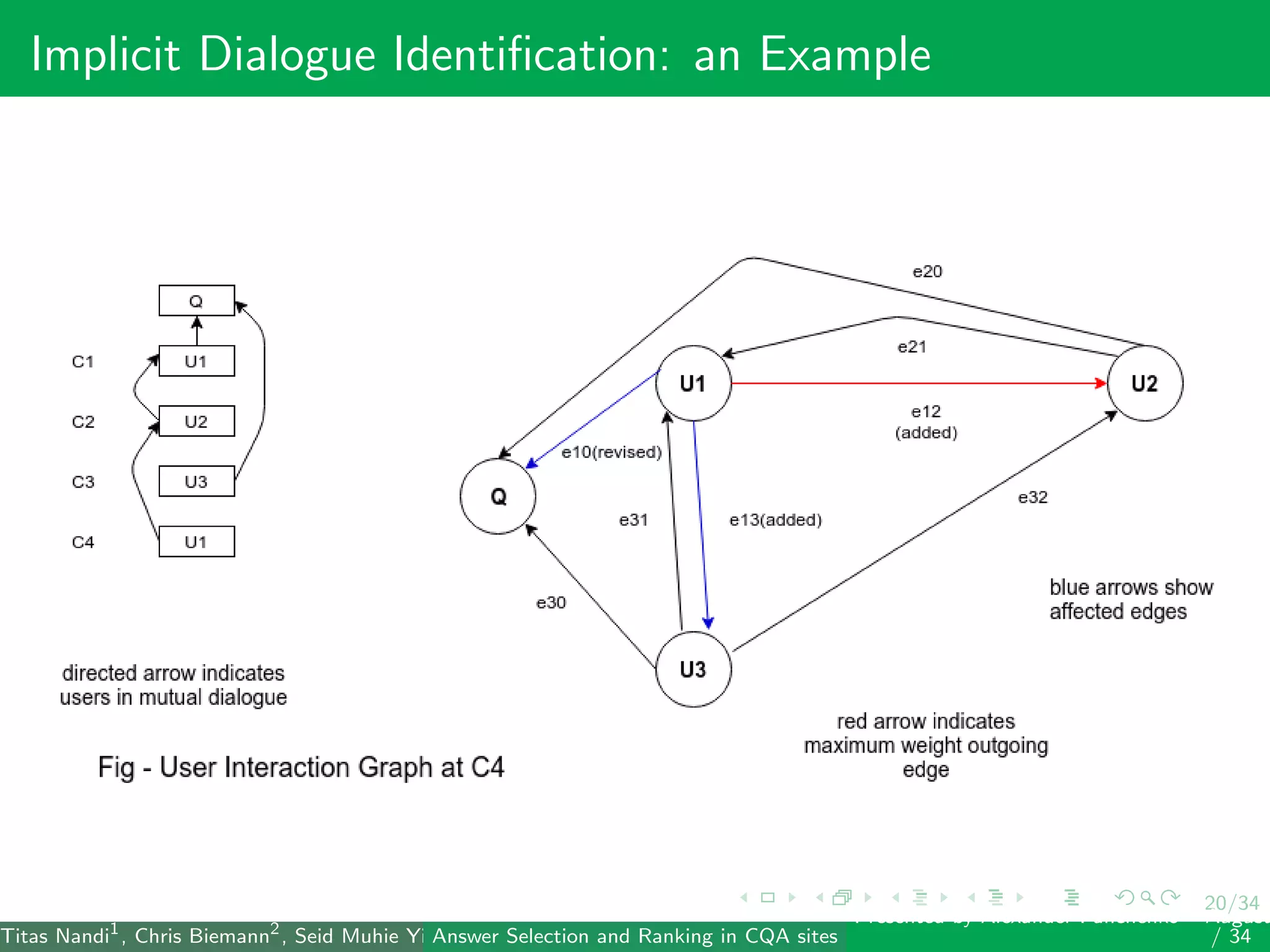
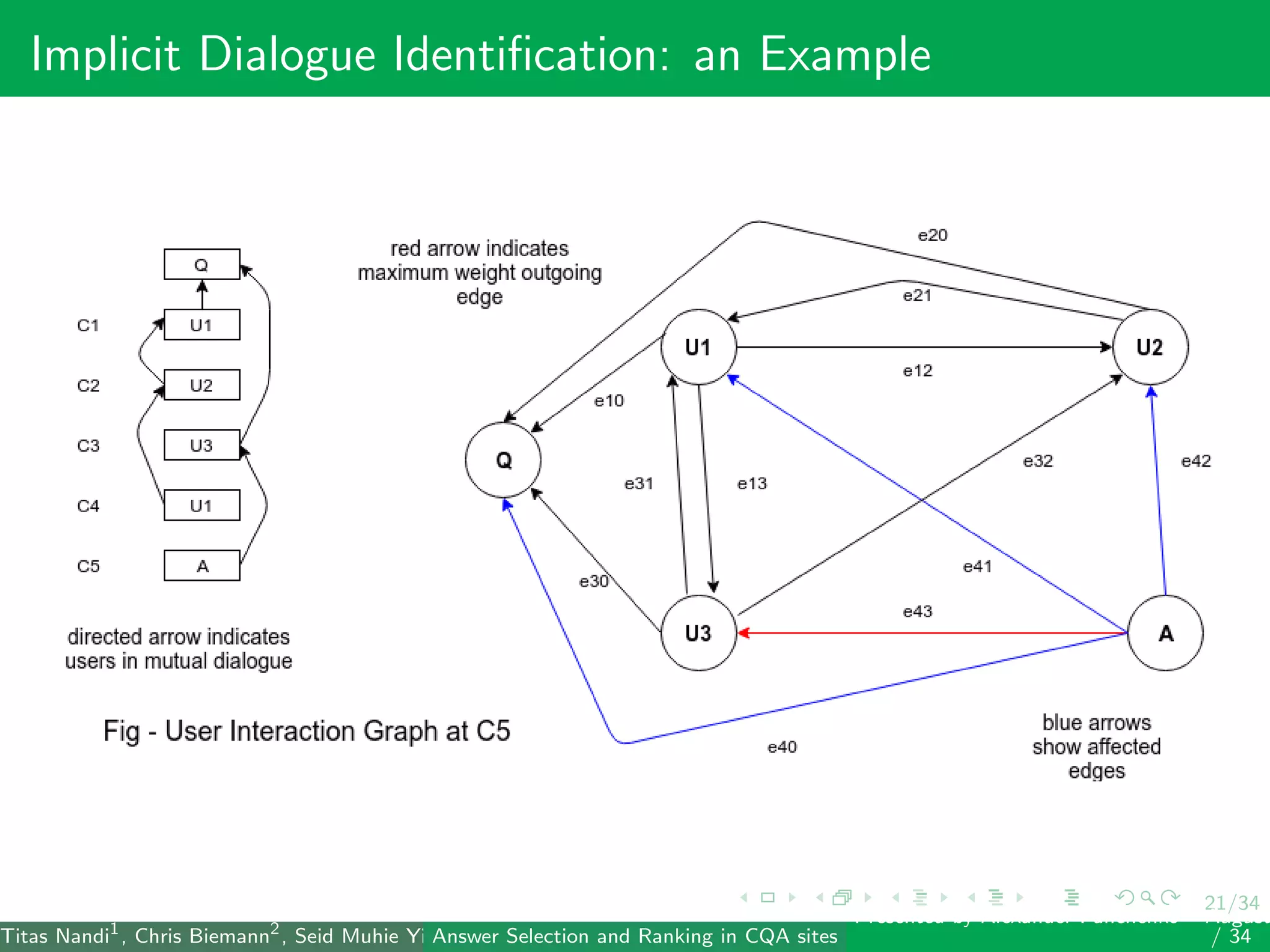
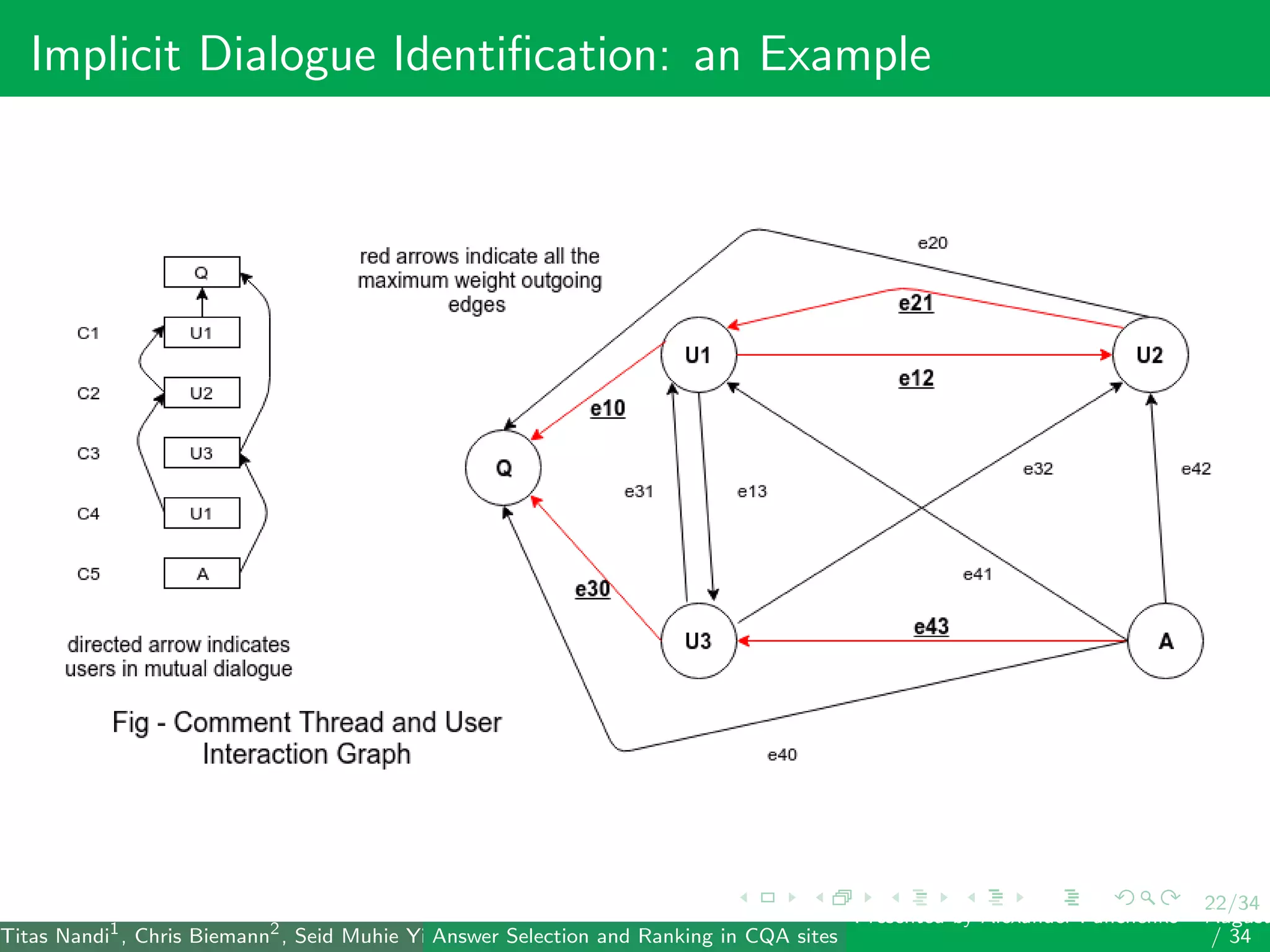

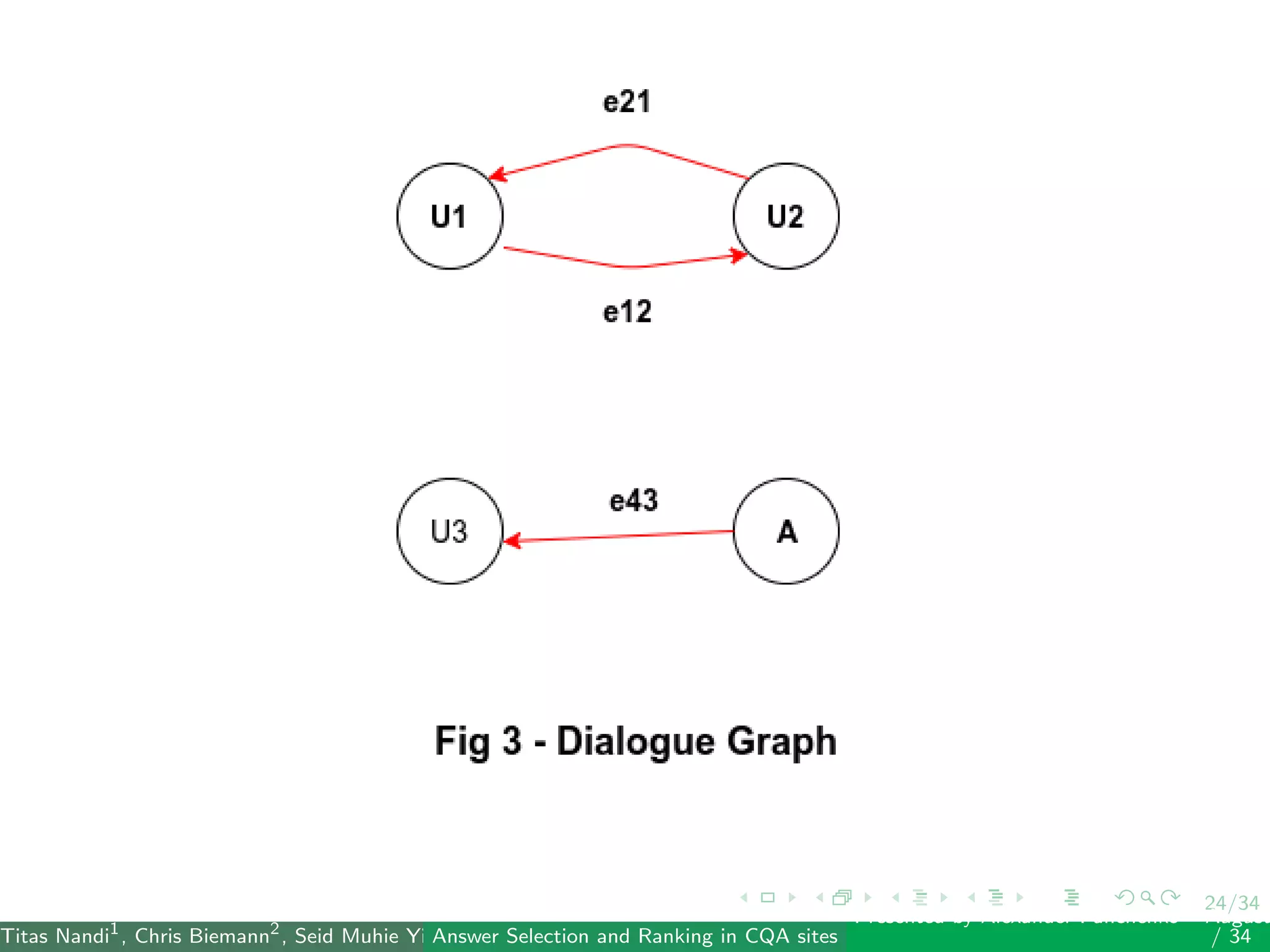




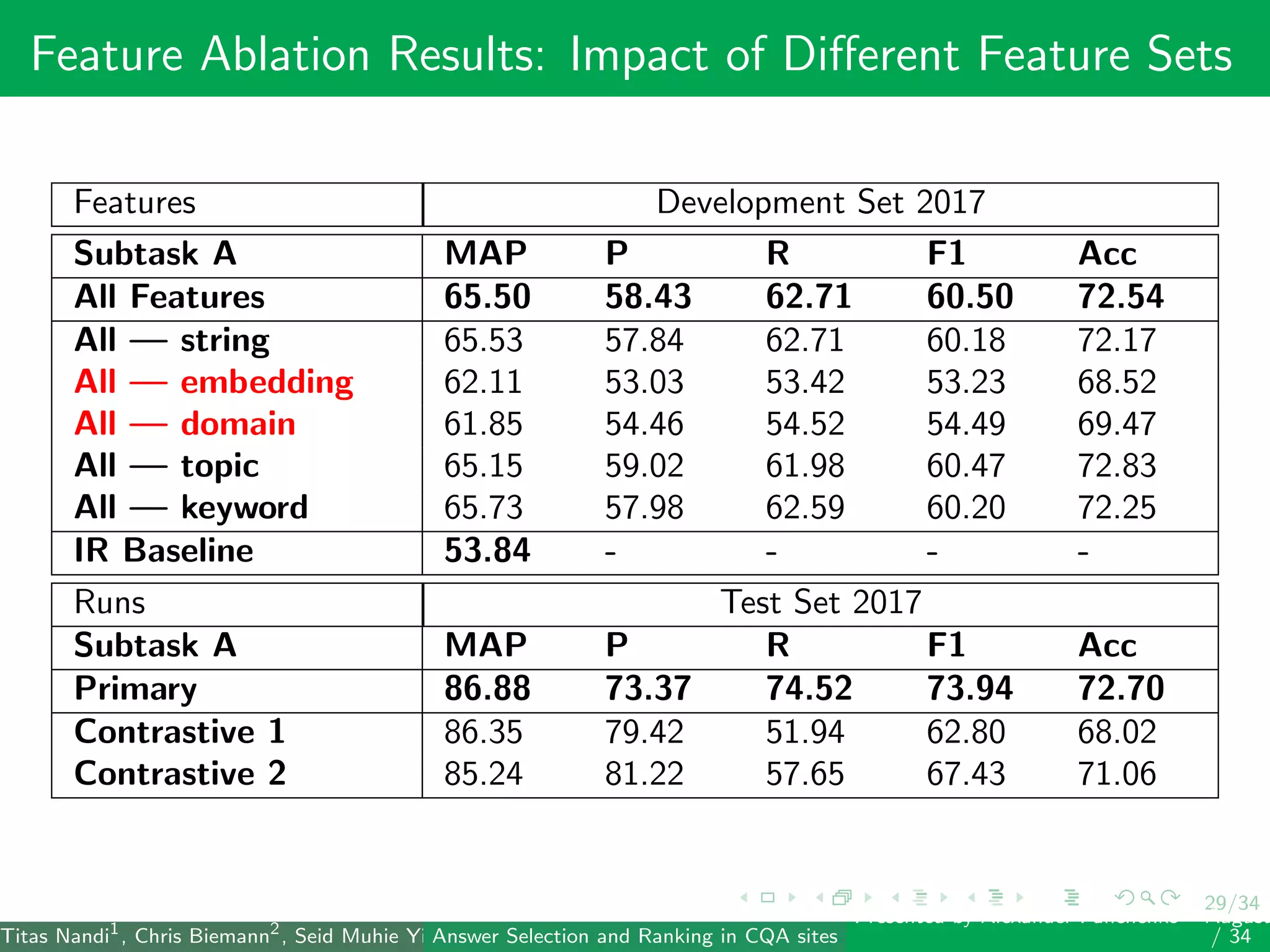

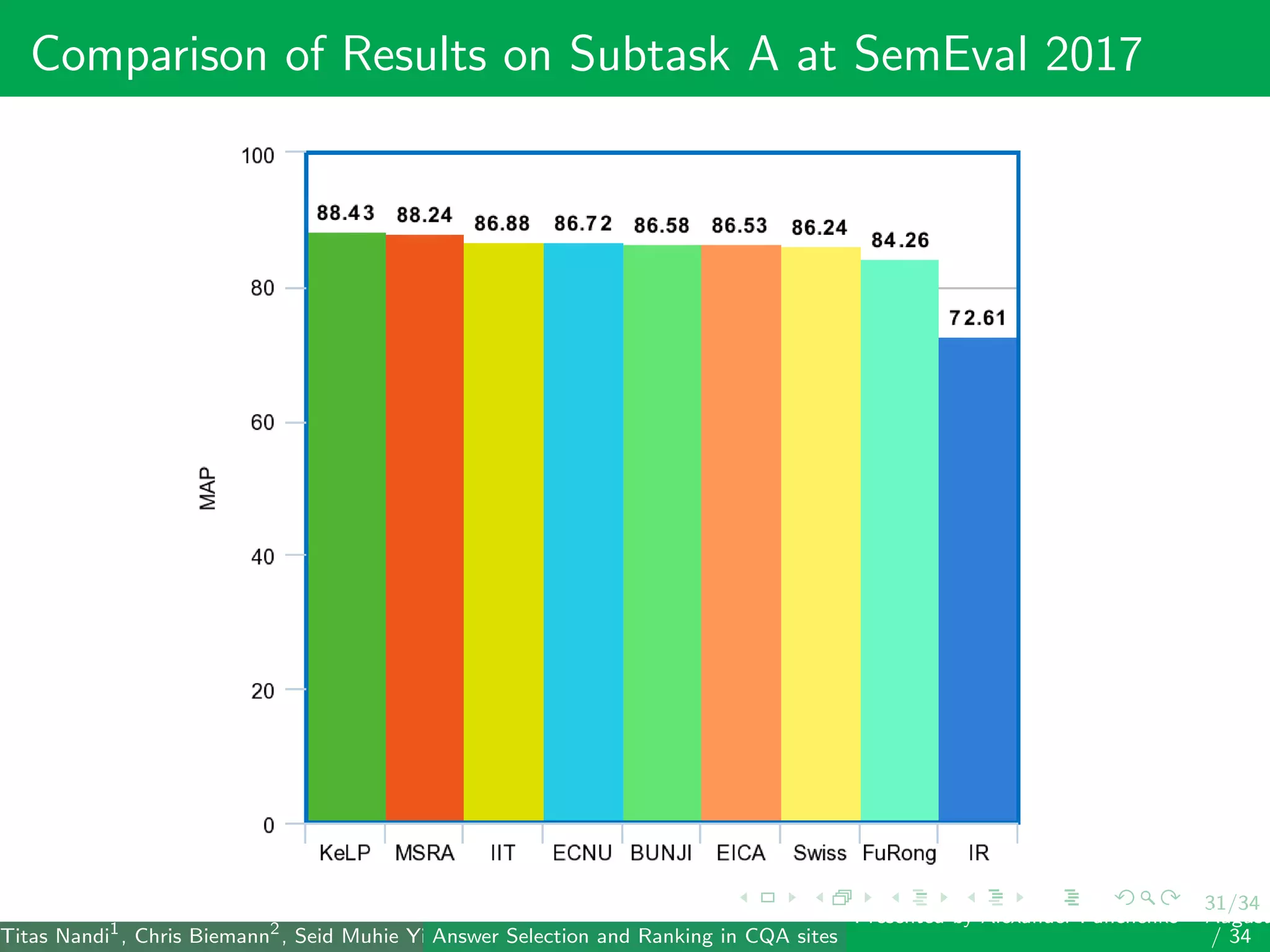
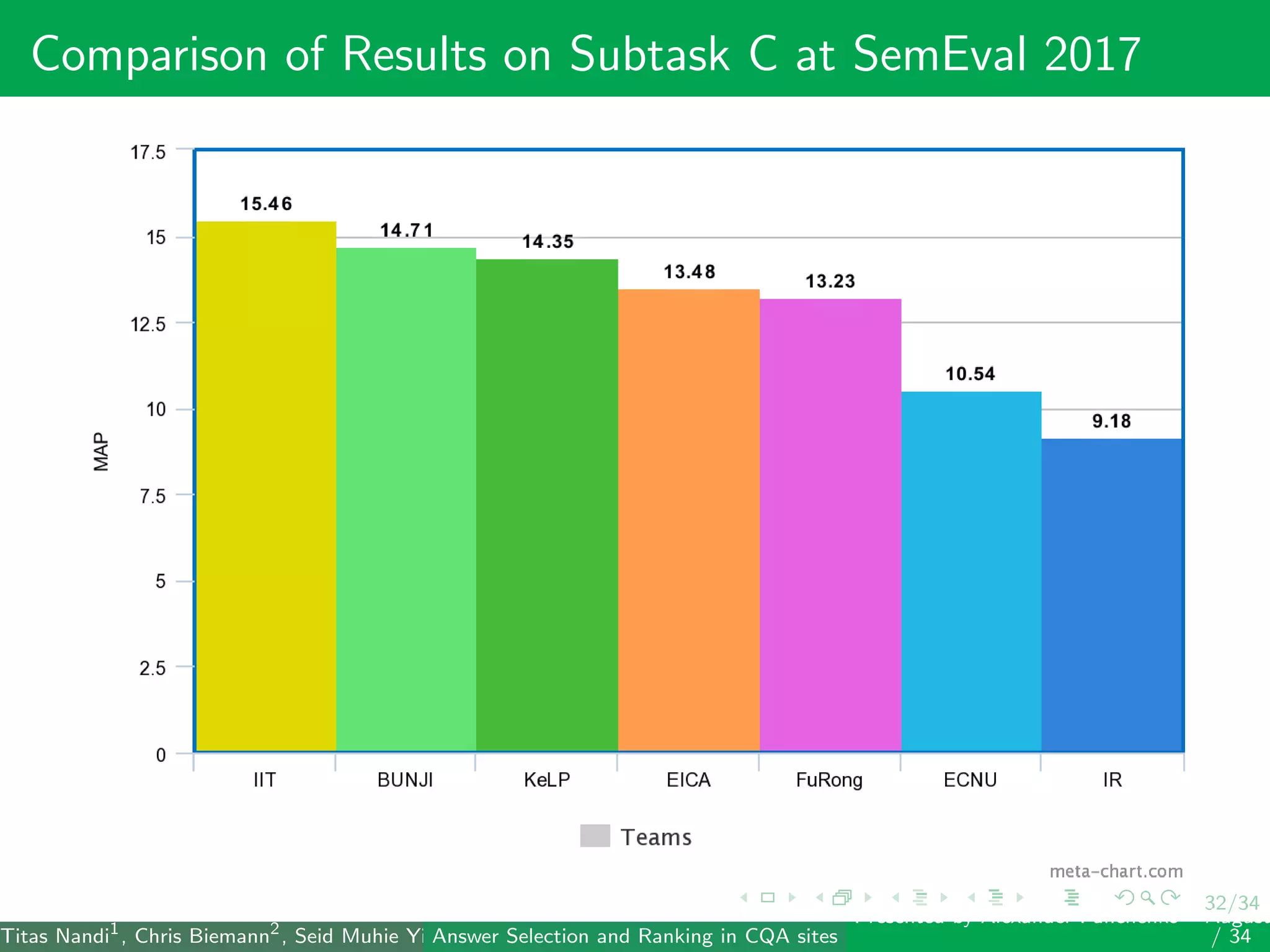



The document describes a system for identifying answers and implicit dialogues in community question answering sites. It examines multiple feature types, including string similarity, word embeddings, topic modeling and keyword features. An SVM classifier is used to rank answers for three subtasks: comment classification, question-comment similarity and question-external comment similarity. Evaluation on the SemEval 2017 Task 3 dataset shows the full feature set performs best, with string and embedding features also providing significant contributions to performance.



































































