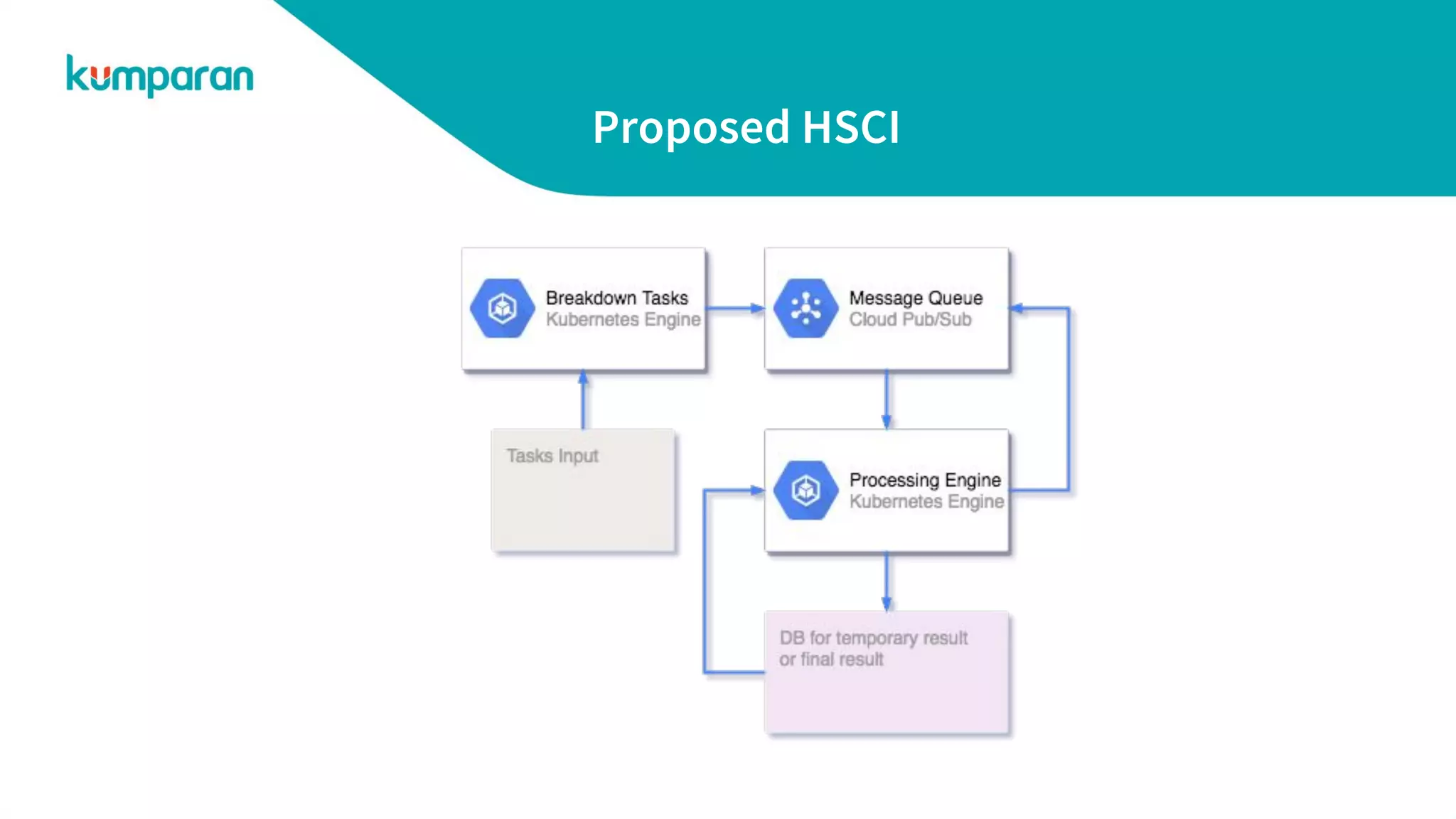
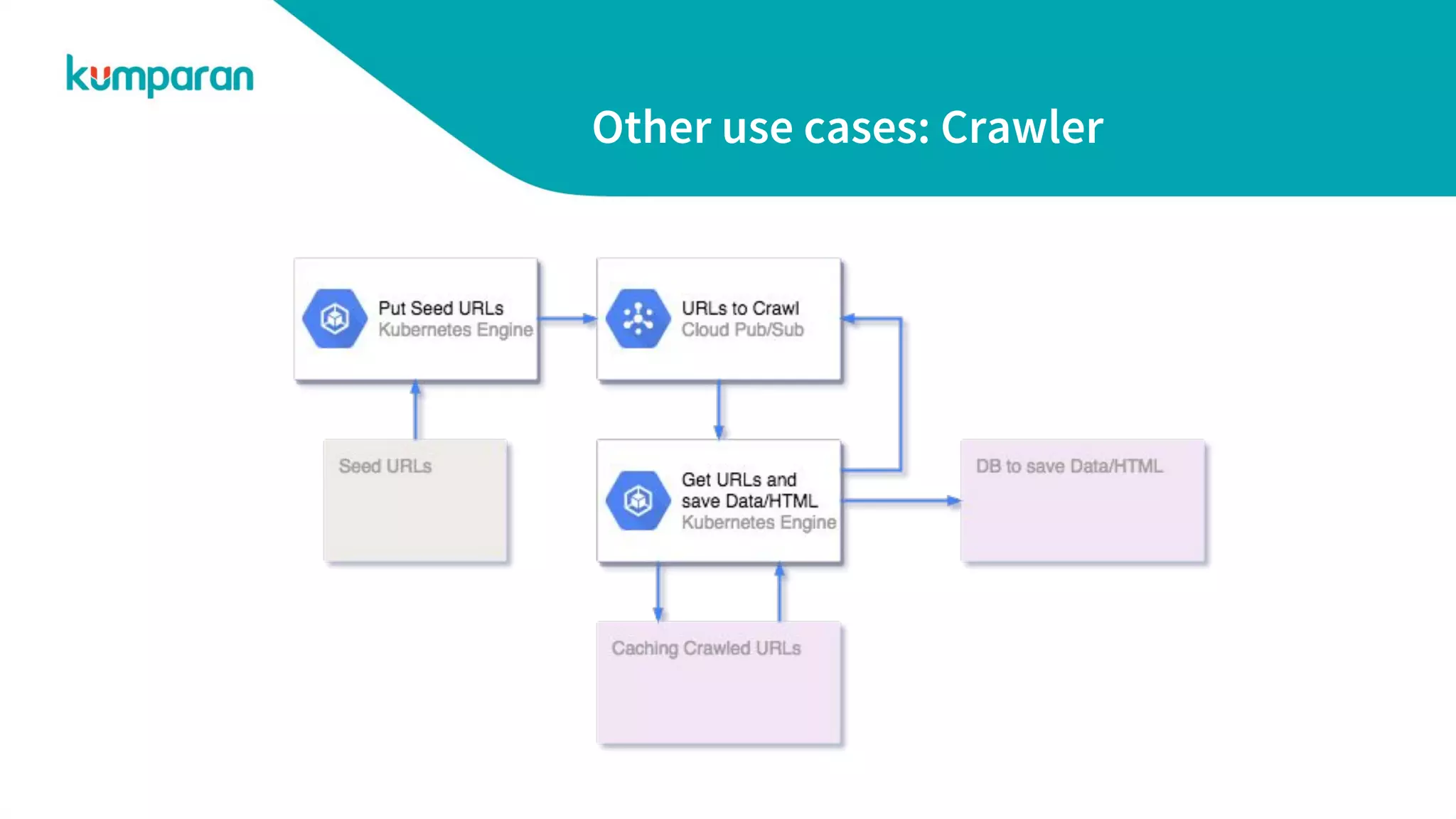
The document discusses horizontally scalable compute infrastructure (HSCI), which allows systems to increase capacity by adding more machines rather than relying solely on vertical scaling. It presents an example problem of word counting on large datasets by utilizing HSCI to distribute tasks via message queues, improving efficiency and scalability. Additionally, it touches on various use cases and invites applications for multiple engineering positions.