Download to read offline















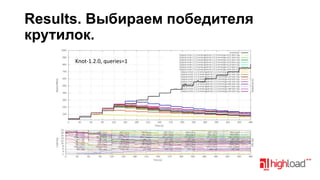
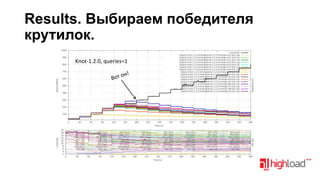
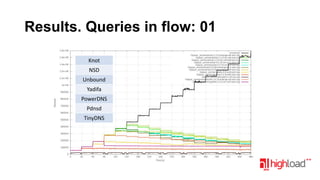
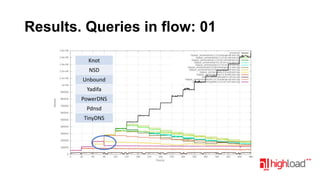
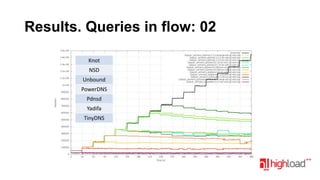
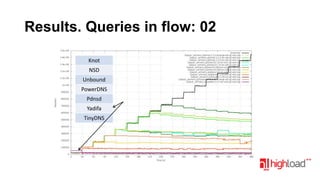
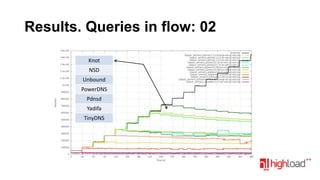
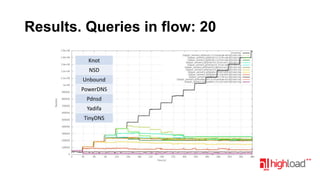







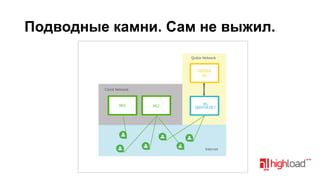
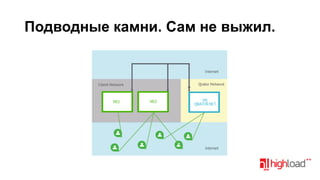
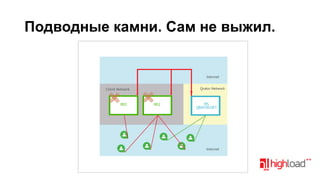


Документ посвящен тестированию производительности DNS-серверов и обсуждает различные аспекты, такие как скорость, устойчивость и производительность. Описаны используемые тестовые инструменты и результаты, а также подводные камни, связанные с работой DNS. Выделены победители тестирования, включая серверы Knot и Yadifa.











































