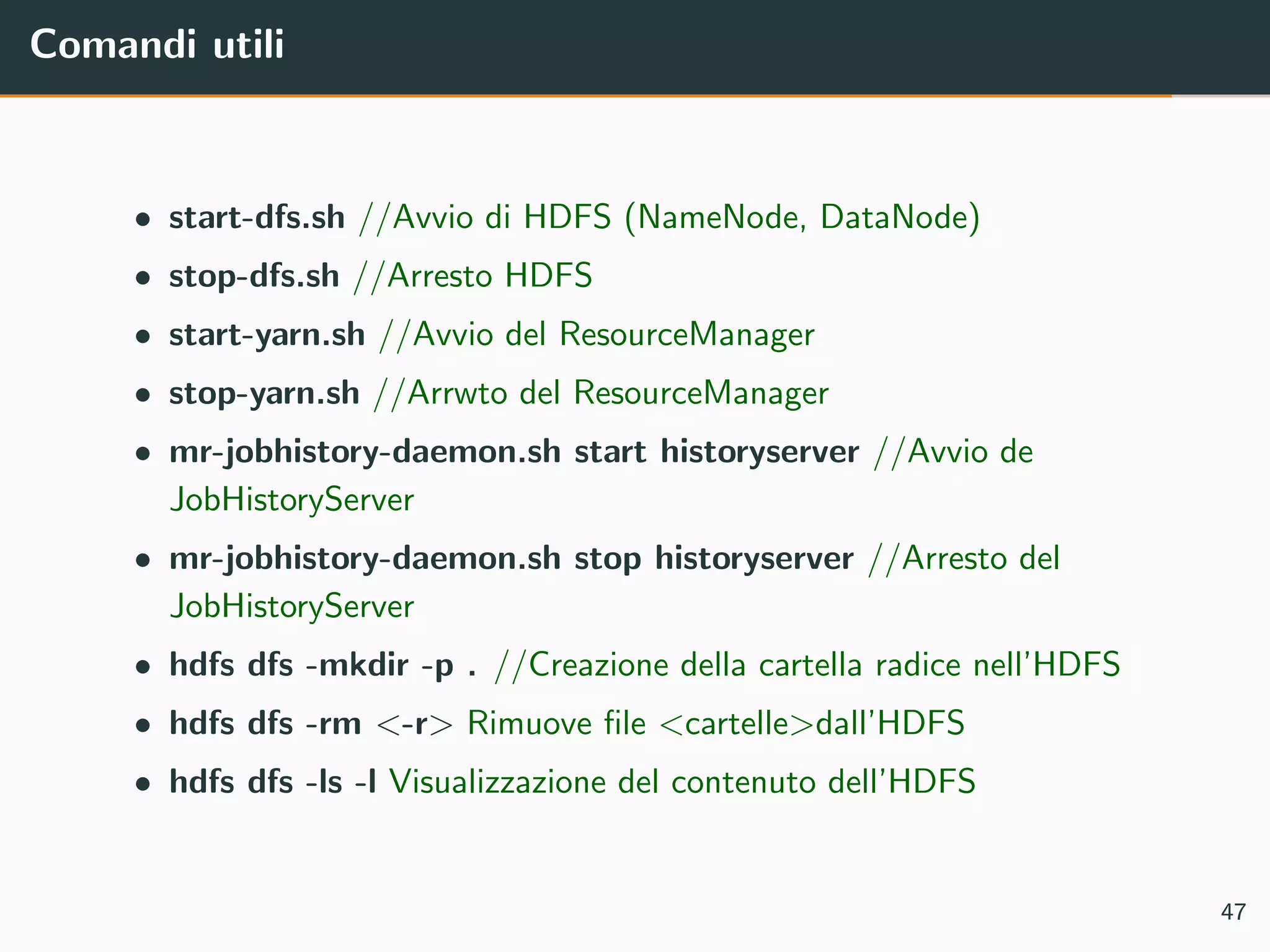
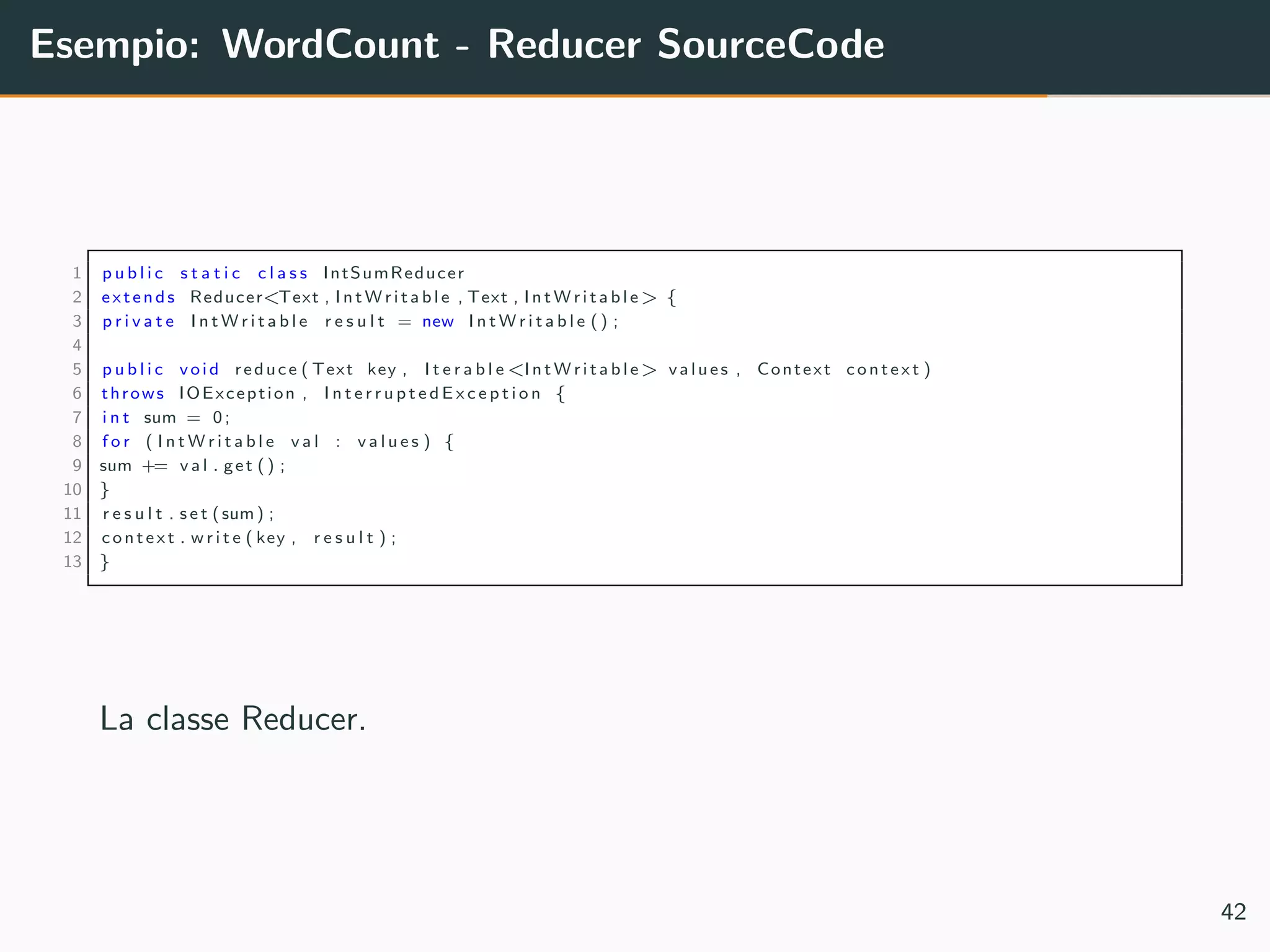
Il documento tratta di Apache Hadoop, un framework per l'elaborazione distribuita di big data che utilizza il modello di programmazione MapReduce. Vengono discusse le componenti principali di Hadoop, come HDFS e YARN, e viene fornito un esempio di implementazione del conteggio delle parole utilizzando MapReduce. Sono anche analizzati i miglioramenti apportati nella versione 2.x di Hadoop, comprese la federazione di HDFS e l'alta disponibilità del Namenode.




![Esempio: WordCount - Sequential Code
1
2 p u b l i c c l a s s SequentialWordCount {
3
4 p u b l i c s t a t i c void main ( S t r i n g [ ] args ) throws Exception {
5
6 F i l e I n p u t S t r e a m fstream = new F i l e I n p u t S t r e a m ( ”BIG FILE 8GB . t x t ” ) ;
7 DataInputStream i n = new DataInputStream ( fstream ) ;
8 BufferedReader br = new BufferedReader ( new InputStreamReader ( i n ) ) ;
9
10 HashMap<String , I n t e g e r> map = new HashMap<>();
11
12 S t r i n g word ;
13 w h i l e (( word = br . re adL in e () ) != n u l l ){
14
15 S t r i n g T o k e n i z e r t o k e n i z e r = new S t r i n g T o k e n i z e r ( word , ” tnrf . , ; : ’ ” ” ) ;
16
17 w h i l e ( t o k e n i z e r . hasMoreTokens () ) {
18 S t r i n g word now = t o k e n i z e r . nextToken () ;
19 I n t e g e r count = map . get ( word now ) ;
20
21 map . put ( word now , count == n u l l ? 1 : ++count ) ;
22 }
23 }
24
25 f o r ( Entry<String , I n t e g e r> e n t r y : map . e n t r y S e t () ) System . out . p r i n t l n ( e n t r y . getKey () + ” : ” +
e n t r y . getValue () ) ;
26 }
27
28 }
5](https://image.slidesharecdn.com/hadoopinaction-160711121910/75/Hadoop-in-action-5-2048.jpg)










































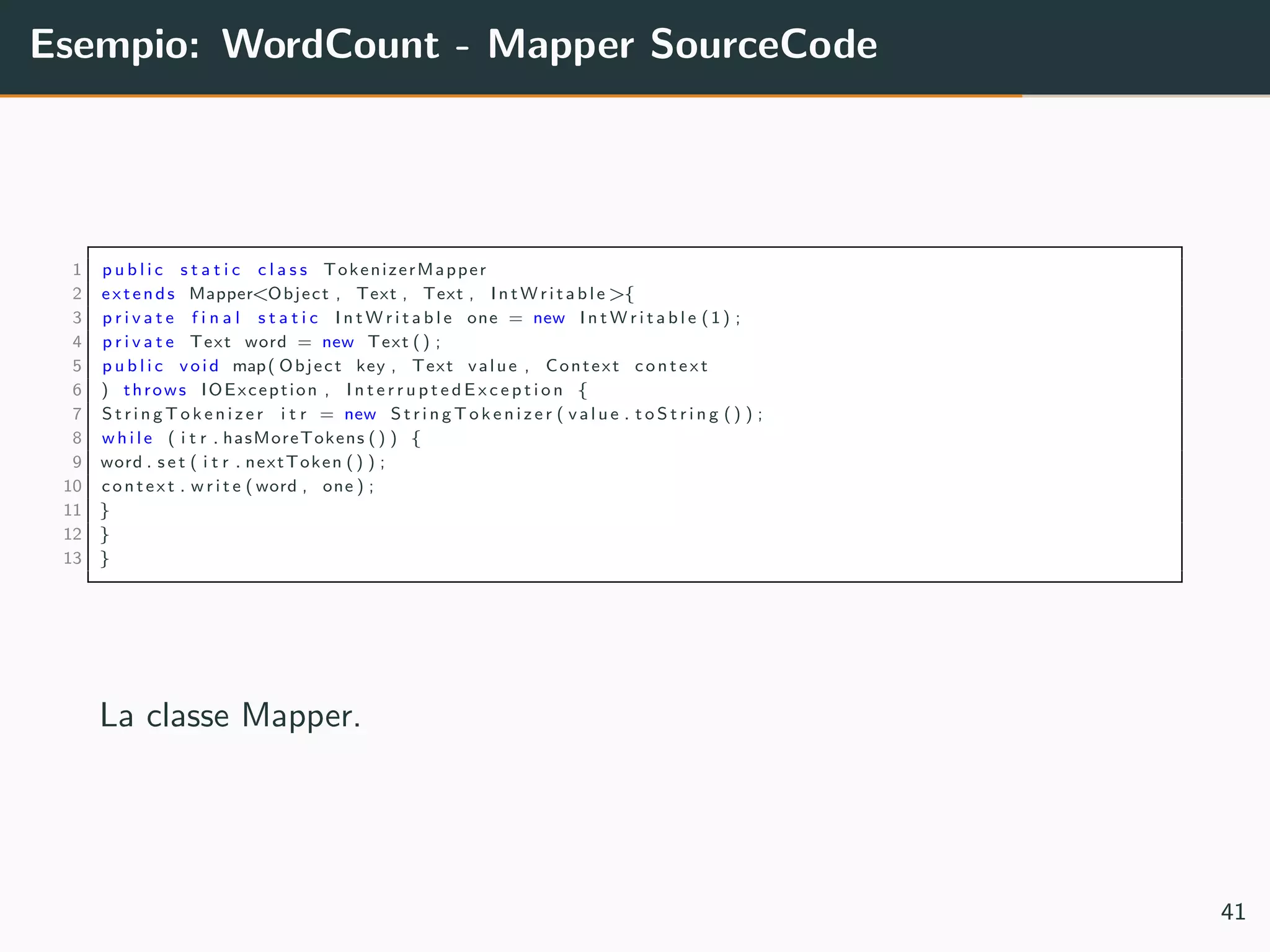
![Esempio: WordCount - Main SourceCode
1 p u b l i c s t a t i c void main ( S t r i n g [ ] args ) throws Exception {
2 C o n f i g u r a t i o n conf = new C o n f i g u r a t i o n () ;
3 Job job = Job . g e t I n s t a n c e ( conf , ”word count ” ) ;
4 job . s e t J a r B y C l a s s ( WordCount . c l a s s ) ;
5 job . setMapperClass ( TokenizerMapper . c l a s s ) ;
6 job . setCombinerClass ( IntSumReducer . c l a s s ) ;
7 job . s e t R e d u c e r C l a s s ( IntSumReducer . c l a s s ) ;
8 job . setOutputKeyClass ( Text . c l a s s ) ;
9 job . setOutputValueClass ( I n t W r i t a b l e . c l a s s ) ;
10 F il e In p u tF o r ma t . addInputPath ( job , new Path ( args [ 0 ] ) ) ;
11 FileOutputFormat . setOutputPath ( job , new Path ( args [ 1 ] ) ) ;
12 System . e x i t ( job . waitForCompletion ( t r u e ) ? 0 : 1) ;
13 }
14
Main method.
43](https://image.slidesharecdn.com/hadoopinaction-160711121910/75/Hadoop-in-action-68-2048.jpg)