





















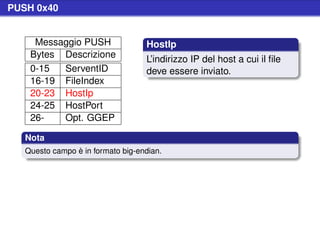
![Esempio di Handshake
Example
Client Server
-----------------------------------------------------------
GNUTELLA CONNECT/0.6<cr><lf>
User-Agent: BearShare/1.0<cr><lf>
Pong-Caching: 0.1<cr><lf>
GGEP: 0.5<cr><lf>
<cr><lf>
GNUTELLA/0.6 200 OK<cr><lf>
User-Agent: BearShare/1.0<cr><lf>
Pong-Caching: 0.1<cr><lf>
GGEP: 0.5<cr><lf>
Private-Data: 5ef89a<cr><lf>
<cr><lf>
GNUTELLA/0.6 200 OK<cr><lf>
Private-Data: a04fce<cr><lf>
<cr><lf>
[binary messages] [binary messages]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-23-320.jpg)








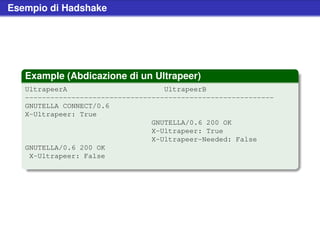
![Esempio di Handshake
Example (Una foglia si connette ad un Ultrapeer)
Leaf Ultrapeer
-----------------------------------------------------------
GNUTELLA CONNECT/0.6
User-Agent: LimeWire/1.0
X-Ultrapeer: False
X-Query-Routing: 0.1
GNUTELLA/0.6 200 OK
User-Agent: LimeWire/1.0
X-Ultrapeer: True
X-Ultrapeer-Needed: False
X-Query-Routing: 0.1
X-Try: 24.37.144:6346,
193.205.63.22:6346
X-Try-Ultrapeers: 23.35.1.7:6346,
18.207.63.25:6347
GNUTELLA/0.6 200 OK
[binary messages] [binary messages]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-32-320.jpg)

![Esempio di Handshake
Example (Una foglia si connette ad un’altra foglia)
Leaf1 Leaf2
-----------------------------------------------------------
GNUTELLA CONNECT/0.6
X-Ultrapeer: False
GNUTELLA/0.6 503 I am a leaf
X-Ultrapeer: False
X-Try: 24.37.144:6346
X-Try-Ultrapeers: 23.35.1.7:6346
[Terminates connection]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-34-320.jpg)

![Esempio di Hadshake
Foglia e Foglia
A volte i nodi possono essere entrambi non Ultrapeer e
incapaci di trovare un Ultrapeer. In questo caso, si comportano
esattamente come il vecchio protocollo 0.4 non strutturato.
Example (Una foglia si connette ad un’altra foglia)
Leaf1 Leaf2
--------------------------------------------------
GNUTELLA CONNECT/0.6
X-Ultrapeer: False
GNUTELLA/0.6 200 OK
X-Ultrapeer: False
GNUTELLA/0.6 200 OK
[binary messages] [binary messages]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-36-320.jpg)
![Esempio di Hadshake
Foglia e Foglia
Quando due Ultrapeer si incontrano entrambi hanno impostato
X-Ultrapeer: True. Se entrambi hanno nodi foglia, rimarranno
Ultrapeers dopo l’interazione.
Example (Connessione tra due Ultrapeer)
UltrapeerA UltrapeerB
------------------------------------------------------
GNUTELLA CONNECT/0.6
X-Ultrapeer: True
GNUTELLA/0.6 200 OK
X-Ultrapeer: True
GNUTELLA/0.6 200 OK
[binary messages] [binary messages]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-37-320.jpg)

















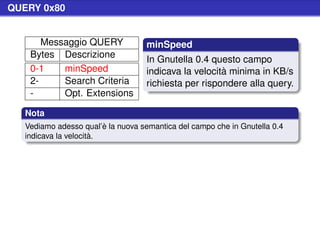





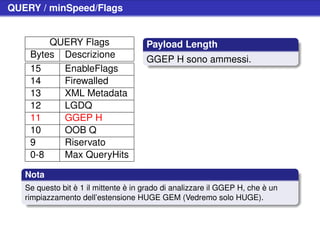





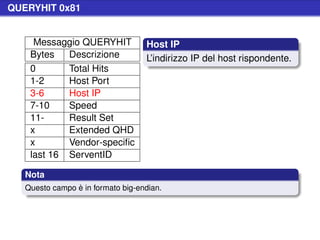



















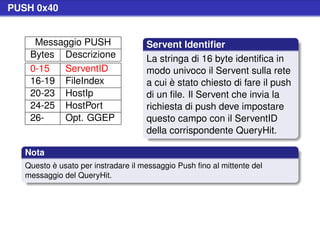






















































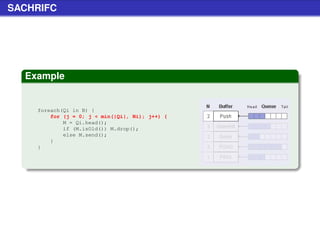



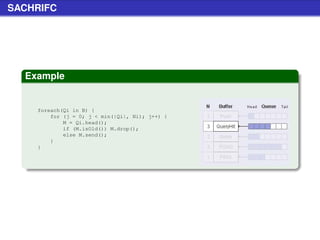
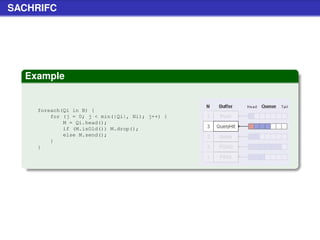
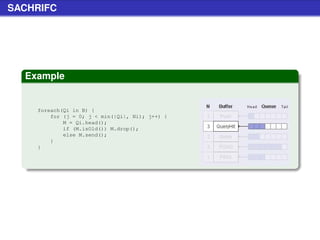











































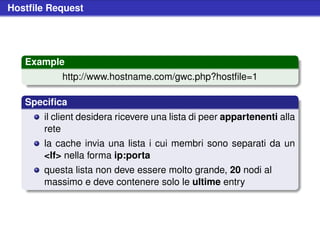





![Stat Request (cont.)
Example (Schema nuove query string)
[...]?client=ABCD&version=1.2.3&hostfile=1
Specifica
le due variabili aggiuntive permettono di avere dati più
accurati nelle statistiche
la variabile client è un codice di 4 bytes che identifica il client
(lo stesso utilizzato nelle QueryHit)
la variabile version identifica la versione del client](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-210-320.jpg)












![Crawler Headers (cont.)
Example (Reply HTTP Headers)
Leaves: ipleaf1 :port, [...]
Peers: ippeer1 :port, [...]
Protocollo
Leaves identifica le foglie connesse al peer interrogato se
esso è un Ultrapeer
Peers identifica tutti gli altri nodi connessi (ad esempio altri
Ultrapeer )
al termine di questa transazione la connessione viene
chiusa immediatamente](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-223-320.jpg)






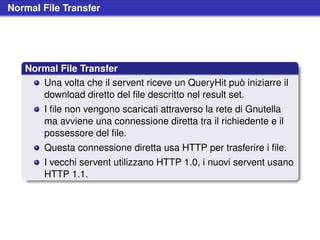
![Realizzazione di un browser
Implementazione di un pacchetto Gnutella
Un generico pacchetto Gnutella può essere implementato, se
si utilizza un linguaggio ad oggetti, come una classe aventi i
campi che lo caratterizzano
Example (Gnutella::Packet::Generic)
my $self = {
_accessible => {
debug => $parent->debug(),
timeout => $parent->timeout(),
msgid => [],
type => undef,
ttl => 0,
hops => 0,
size => 0,
payload => undef,
},
};$](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-232-320.jpg)


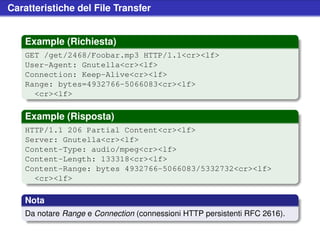
![Realizzazione di un browser
Example (Gnutella::Packet::QueryReply::$parsePayload)
[...]
for (my $i = 0; $i < $count; $i++) {
my @extra;
my $index = unpack("L", substr($data, 0, 4, ’’));
my $size = unpack("L", substr($data, 0, 4, ’’));
my $name = substr($data, 0, index($data, "x00"), ’’);
substr($data, 0, 1, ’’);
while(1) {
if(substr($data, 0, 1) =~ /^(?:x00|xC3)$/) {
last; # no more extensions or GGEP found
}
my $text = substr($data, 0, index($data, "x1C"));
$text = substr($text, 4) if $text =~ /^urn:/;
push @extra, $text;
substr($data, 0, index($data, "x1C") + 1, ’’);
}
substr($data, 0, index($data, "x00") + 1, ’’);
push @set, [ $index, $size, $name, @extra ];
}
[...]](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-235-320.jpg)
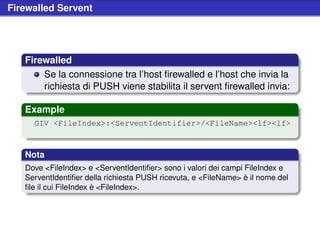
![Realizzazione di un browser
Example (Gnutella::ConnectionBinary::read)
sub read {
# [...]
return undef
unless read( $self->socket(), $header, 23) == 23;
# parse header
@msgid = unpack("L4", substr($header, 0, 16));
$type = unpack("C", substr($header, 16, 1));
$ttl = unpack("C", substr($header, 17, 1));
$hops = unpack("C", substr($header, 18, 1));
$size = unpack("L", substr($header, 19, 4));
# read payload
return undef
unless $self->isReadable();
return undef
unless read( $self->socket(), $payload, $size ) == $size;
return $self->$classType( $type )->new($self,
’msgid’ => @msgid, ’type’ => $type, ’ttl’ => $ttl,
’hops’ => $hops, ’size’ => $size, ’payload’ => $payload
);
}$](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-236-320.jpg)






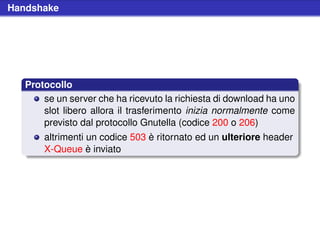





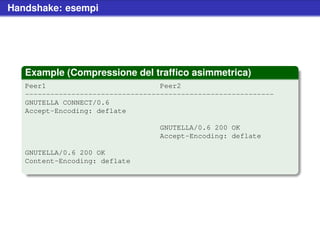
![Handshake
Example (Disponibilità a ricevere)
Accept-Encoding: encoding1 [, ...]
Example (Disponibilità ad inviare)
Content-Encoding: encoding1 [, ...]
HTTP Headers
il peer disposto a comprimere il traffico deve scegliere uno
e uno solo tra gli algoritmi supportati dalla controparte
questo implica che la compressione può essere anche
asimmetrica; un utente può anche accettare dati
compressi ma spedire del plain text](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-249-320.jpg)






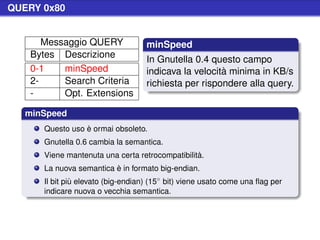
![Vendor Messages
Example (HTTP Headers)
Vendor-Message: <max_Version>.<min_Version>
Handshake
i peer che supportano questa estensione devono dichiararlo
alla controparte durante handshake
la versione attuale del protocollo è la 0.1
con supportare qui si intende che un peer semplicemente
legge i messaggi di tipo 0x3[12] senza terminare la con-
nessione e non necessariamente che sia capace di capire
il messaggio in sè
siccome l’insieme di questi messaggi non ha una
dimensione fissata e può essere molto grande questo non
viene dichiarato](https://image.slidesharecdn.com/seminariop2pprint-13152245057701-phpapp02-110905071327-phpapp02/85/Gnutella-Italian-Printable-257-320.jpg)























Il documento tratta il protocollo Gnutella, un sistema decentralizzato per la ricerca e la distribuzione di file, dove ogni partecipante agisce sia come client che come server. Vengono analizzate le varie versioni del protocollo, con particolare attenzione alle funzionalità degli ultrapeer, la gestione delle connessioni e l'estensibilità del protocollo. Infine, si discutono il bootstraping, la formattazione degli header e i meccanismi di handshaking tra i nodi della rete.




































