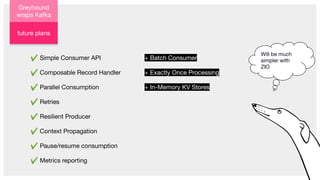
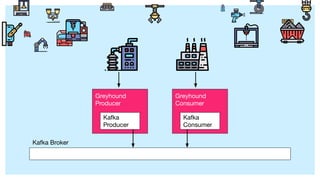
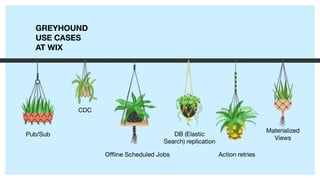
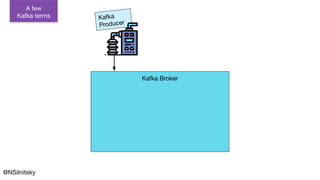
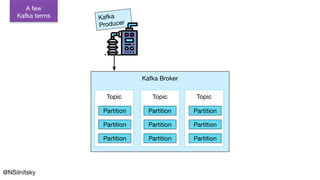
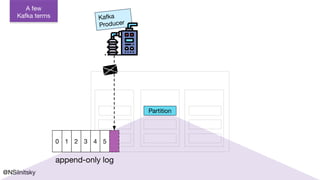
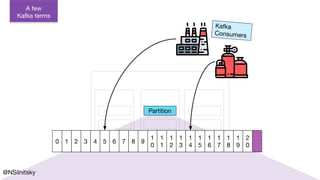
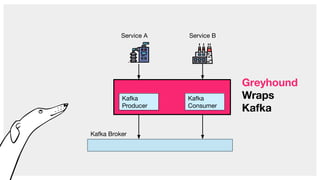
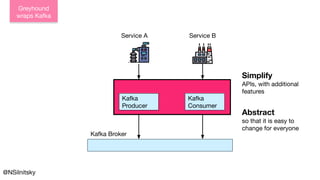
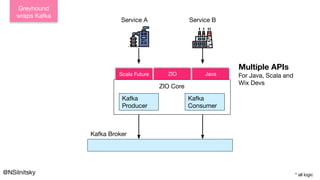
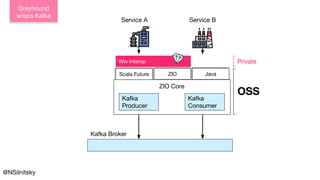
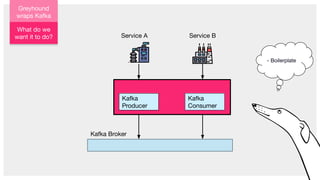
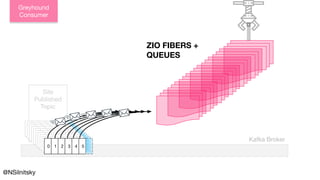
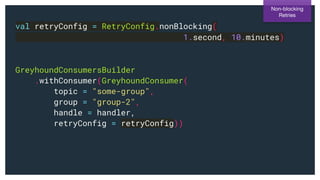
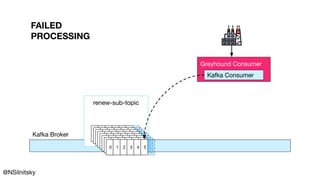
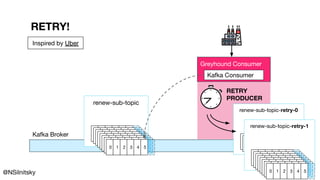
The document describes Greyhound, a Scala/Java SDK built for Apache Kafka, which simplifies Kafka API usage and enhances its functionalities. It elaborates on concepts such as Kafka producers, consumers, and brokers while providing code examples for various Kafka operations, including polling and committing records. Additionally, it emphasizes features like composable record handlers and parallel consumption through a dispatcher object.



![val consumer: KafkaConsumer[String, SomeMessage] =
createConsumer()
def pollProcessAndCommit(): Unit = {
val consumerRecords = consumer.poll(1000).asScala
consumerRecords.foreach(record => {
println(s"Record value: ${record.value.messageValue}")
})
consumer.commitAsync()
pollProcessAndCommit()
}
pollProcessAndCommit()
Kafka
Consumer API
* Broker location, serde](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-13-320.jpg)
![val consumer: KafkaConsumer[String, SomeMessage] =
createConsumer()
def pollProcessAndCommit(): Unit = {
val consumerRecords = consumer.poll(1000).asScala
consumerRecords.foreach(record => {
println(s"Record value: ${record.value.messageValue}")
})
consumer.commitAsync()
pollProcessAndCommit()
}
pollProcessAndCommit()
Kafka
Consumer API](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-14-320.jpg)
![val consumer: KafkaConsumer[String, SomeMessage] =
createConsumer()
def pollProcessAndCommit(): Unit = {
val consumerRecords = consumer.poll(1000).asScala
consumerRecords.foreach(record => {
println(s"Record value: ${record.value.messageValue}")
})
consumer.commitAsync()
pollProcessAndCommit()
}
pollProcessAndCommit()
Kafka
Consumer API](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-15-320.jpg)
![val handler: RecordHandler[Console, Nothing,
String, SomeMessage] =
RecordHandler { record =>
zio.console.putStrLn(record.value.messageValue)
}
GreyhoundConsumersBuilder
.withConsumer(RecordConsumer(
topic = "some-group",
group = "group-2",
handle = handler))
Greyhound
Consumer API
* No commit, wix broker location](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-16-320.jpg)
![trait RecordHandler[-R, +E, K, V] {
def handle(record: ConsumerRecord[K, V]): ZIO[R, E, Any]
def contramap: RecordHandler
def contramapM: RecordHandler
def mapError: RecordHandler
def withErrorHandler: RecordHandler
def ignore: RecordHandler
def provide: RecordHandler
def andThen: RecordHandler
def withDeserializers: RecordHandler
}
Composable
Handler
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-19-320.jpg)
![trait RecordHandler[-R, +E, K, V] {
def handle(record: ConsumerRecord[K, V]): ZIO[R, E, Any]
def contramap: RecordHandler
def contramapM: RecordHandler
def mapError: RecordHandler
def withErrorHandler: RecordHandler
def ignore: RecordHandler
def provide: RecordHandler
def andThen: RecordHandler
def withDeserializers: RecordHandler
}
Composable
Handler
@NSilnitsky * change type](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-20-320.jpg)

: RecordHandler[R, E, K2, V2] =
new RecordHandler[R, E, K2, V2] {
override def handle(record: ConsumerRecord[K2, V2]): ZIO[R, E, Any] =
f(record).flatMap(self.handle)
}
def withDeserializers(keyDeserializer: Deserializer[K],
valueDeserializer: Deserializer[V])
: RecordHandler[R, Either[SerializationError, E], Chunk[Byte], Chunk[Byte]] =
mapError(Right(_)).contramapM { record =>
record.bimapM(
key => keyDeserializer.deserialize(record.topic, record.headers, key),
value => valueDeserializer.deserialize(record.topic, record.headers, value)
).mapError(e => Left(SerializationError(e)))
}
Composable
Handler
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-21-320.jpg)

: RecordHandler[R, E, K2, V2] =
new RecordHandler[R, E, K2, V2] {
override def handle(record: ConsumerRecord[K2, V2]): ZIO[R, E, Any] =
f(record).flatMap(self.handle)
}
def withDeserializers(keyDeserializer: Deserializer[K],
valueDeserializer: Deserializer[V])
: RecordHandler[R, Either[SerializationError, E], Chunk[Byte], Chunk[Byte]] =
mapError(Right(_)).contramapM { record =>
record.bimapM(
key => keyDeserializer.deserialize(record.topic, record.headers, key),
value => valueDeserializer.deserialize(record.topic, record.headers, value)
).mapError(e => Left(SerializationError(e)))
}
Composable
Handler
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-22-320.jpg)
![RecordHandler(
(r: ConsumerRecord[String, Duration]) =>
putStrLn(s"duration: ${r.value.toMillis}"))
.withDeserializers(StringSerde, DurationSerde)
=>
RecordHandler[Console, scala.Either[SerializationError, scala.RuntimeException],
Chunk[Byte], Chunk[Byte]]
Composable
Handler
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-23-320.jpg)
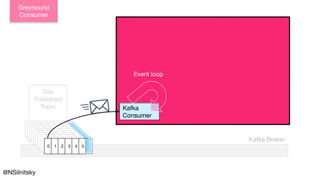
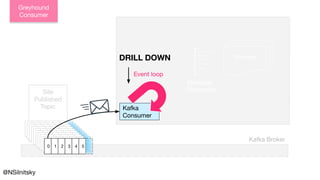
: RManaged[Env, EventLoop[...]] = {
val start = for {
running <- Ref.make(true)
fiber <- pollLoop(running, consumer/*...*/).forkDaemon
} yield (fiber, running /*...*/)
start.toManaged {
case (fiber, running /*...*/) => for {
_ <- running.set(false)
// ...
} yield ()
}
}
EventLoop
Polling](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-28-320.jpg)
: RManaged[Env, EventLoop[...]] = {
val start = for {
running <- Ref.make(true)
fiber <- pollLoop(running, consumer/*...*/).forkDaemon
} yield (fiber, running /*...*/)
start.toManaged {
case (fiber, running /*...*/) => for {
_ <- running.set(false)
// ...
} yield ()
}
}
EventLoop
Polling
@NSilnitsky * dispatcher.shutdown](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-29-320.jpg)
: RManaged[Env, EventLoop[...]] = {
val start = for {
running <- Ref.make(true)
fiber <- pollLoop(running, consumer/*...*/).forkDaemon
} yield (fiber, running /*...*/)
start.toManaged {
case (fiber, running /*...*/) => for {
_ <- running.set(false)
// ...
} yield ()
}
}
EventLoop
Polling
* mem leak@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-30-320.jpg)
: RManaged[Env, EventLoop[...]] = {
val start = for {
running <- Ref.make(true)
fiber <- pollLoop(running, consumer/*...*/).forkDaemon
} yield (fiber, running /*...*/)
start.toManaged {
case (fiber, running /*...*/) => for {
_ <- running.set(false)
// ...
} yield ()
}
}
EventLoop
Polling
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-31-320.jpg)
: URIO[R1 with GreyhoundMetrics, Unit] =
running.get.flatMap {
case true => for {
//...
_ <- pollAndHandle(consumer /*...*/)
//...
result <- pollLoop(running, consumer /*...*/)
} yield result
case false => ZIO.unit
}
TailRec in ZIO
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-32-320.jpg)
: URIO[R1 with GreyhoundMetrics, Unit] =
running.get.flatMap {
case true => // ...
pollAndHandle(consumer /*...*/)
// ...
.flatMap(_ =>
pollLoop(running, consumer /*...*/)
.map(result => result)
)
case false => ZIO.unit
}
TailRec in ZIO
https://github.com/oleg-py/better-monadic-for
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-33-320.jpg)
: RManaged[Env, EventLoop[...]] = {
val start = for {
running <- Ref.make(true)
fiber <- pollOnce(running, consumer/*, ...*/)
.doWhile(_ == true).forkDaemon
} yield (fiber, running /*...*/)
start.toManaged {
case (fiber, running /*...*/) => for {
_ <- running.set(false)
// ...
} yield ()
}
TailRec in ZIO
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-34-320.jpg)
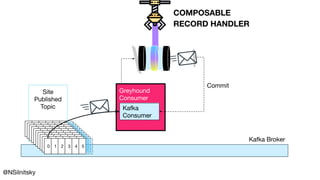
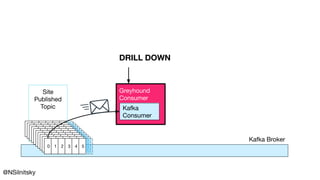
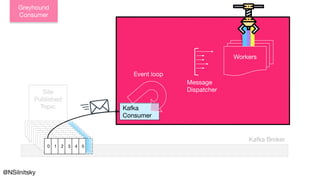
![object EventLoop {
type Handler[-R] = RecordHandler[R, Nothing, Chunk[Byte], Chunk[Byte]]
def make[R](handler: Handler[R] /*...*/): RManaged[Env, EventLoop[...]] = {
val start = for {
// ...
handle = handler.andThen(offsets.update).handle(_)
dispatcher <- Dispatcher.make(handle, /**/)
// ...
} yield (fiber, running /*...*/)
}
def pollOnce(/*...*/) = {
// poll and handle...
_ <- offsets.commit
Commit Offsets
@NSilnitsky
* old -> pass down](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-35-320.jpg)
![val consumer: KafkaConsumer[String, SomeMessage] =
createConsumer()
def pollProcessAndCommit(): Unit = {
val consumerRecords = consumer.poll(1000).asScala
consumerRecords.foreach(record => {
println(s"Record value: ${record.value.messageValue}")
})
consumer.commitAsync()
pollProcessAndCommit()
}
pollProcessAndCommit()
Kafka
Consumer API](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-37-320.jpg)
: UIO[Dispatcher[R]] = for {
// ...
workers <- Ref.make(Map.empty[TopicPartition, Worker])
} yield new Dispatcher[R] {
override def submit(record: Record): URIO[..., SubmitResult] =
for {
// ...
worker <- workerFor(TopicPartition(record))
submitted <- worker.submit(record)
} yield // …
}
}
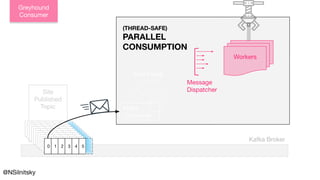
Parallel
Consumption
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-40-320.jpg)
: UIO[Dispatcher[R]] = for {
// ...
workers <- Ref.make(Map.empty[TopicPartition, Worker])
} yield new Dispatcher[R] {
override def submit(record: Record): URIO[..., SubmitResult] =
for {
// ...
worker <- workerFor(TopicPartition(record))
submitted <- worker.submit(record)
} yield // …
}
}
Parallel
Consumption
* lazily
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-41-320.jpg)
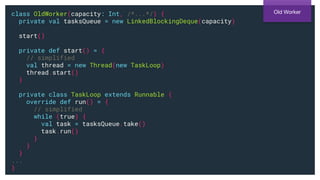
: URIO[...,Worker] = for {
queue <- Queue.dropping[Record](capacity)
_ <- // simplified
queue.take.flatMap { record =>
handle(record).as(true)
}.doWhile(_ == true).forkDaemon
} yield new Worker {
override def submit(record: Record): UIO[Boolean] =
queue.offer(record)
// ...
}
}
Parallel
Consumption
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-42-320.jpg)
: URIO[...,Worker] = for {
queue <- Queue.dropping[Record](capacity)
_ <- // simplified
queue.take.flatMap { record =>
handle(record).as(true)
}.doWhile(_ == true).forkDaemon
} yield new Worker {
override def submit(record: Record): UIO[Boolean] =
queue.offer(record)
// ...
}
}
Parallel
Consumption
* semaphore
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-43-320.jpg)
: URIO[...,Worker] = for {
queue <- Queue.dropping[Record](capacity)
_ <- // simplified
queue.take.flatMap { record =>
handle(record).as(true)
}.doWhile(_ == true).forkDaemon
} yield new Worker {
override def submit(record: Record): UIO[Boolean] =
queue.offer(record)
// ...
}
}
Parallel
Consumption
@NSilnitsky](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-44-320.jpg)

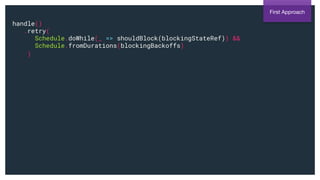
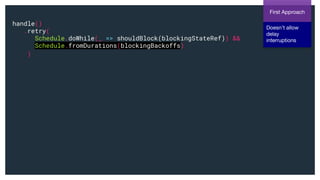
(f: A => ZIO[R, E, Boolean]):
ZIO[R, E, Unit] =
ZIO.effectTotal(as.iterator).flatMap { i =>
def loop: ZIO[R, E, Unit] =
if (i.hasNext) f(i.next).flatMap(result => if(result) loop else
ZIO.unit)
else ZIO.unit
loop
}](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-60-320.jpg)
(f: A => ZIO[R, E, Boolean]):
ZIO[R, E, Unit] =
ZIO.effectTotal(as.iterator).flatMap { i =>
def loop: ZIO[R, E, Unit] =
if (i.hasNext) f(i.next).flatMap(result => if(result) loop else
ZIO.unit)
else ZIO.unit
loop
}
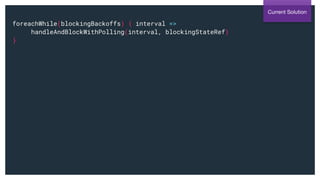
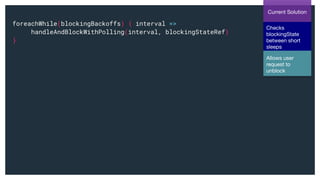
Stream.fromIterable(blockingBackoffs).foreachWhile(...)](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-61-320.jpg)

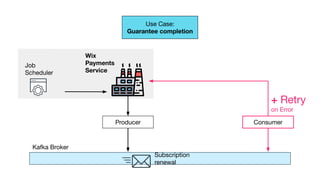
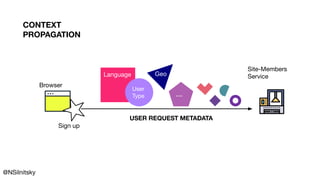
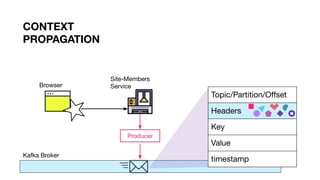
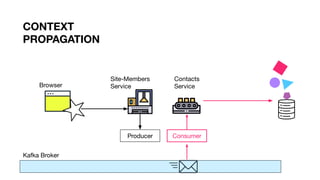
)
Context
Propagation](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-72-320.jpg)
)
RecordHandler((r: ConsumerRecord[String, Contact]) => for {
context <- Context.retrieve
_ <- ContactsDB.write(r.value, context)
} yield ()
=>
RecordHandler[ContactsDB with Context, Throwable, Chunk[Byte], Chunk[Byte]]
Context
Propagation](https://image.slidesharecdn.com/greyhound-powerfulpurefunctionalkafkalibrary-200728110626/85/Greyhound-Powerful-Pure-Functional-Kafka-Library-73-320.jpg)