Download to read offline







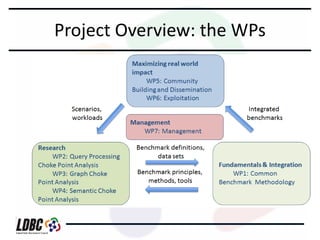
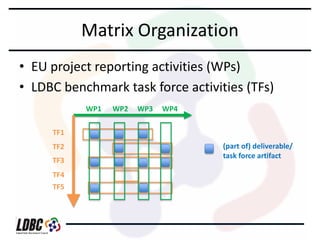





The document discusses an agenda for a meeting on benchmarking RDF and graph databases. It provides an overview of the LDBC benchmarking project including its objectives to create standardized benchmarks, spur industry cooperation, and push technological improvements. It outlines the working groups and task forces that will focus on specific types of benchmarks. It also discusses common issues to be addressed like suitable use cases, benchmark methodologies, and benchmark workloads for querying, updating, and integrating RDF and graph data. Open questions are raised about benchmark realism, benchmark rules, and technological convergence of RDF and graph databases.




























































