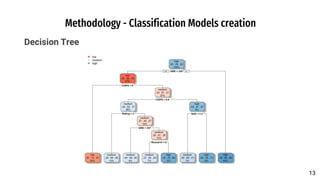
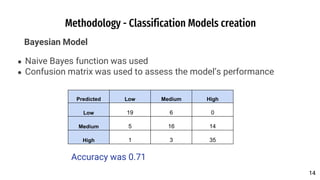
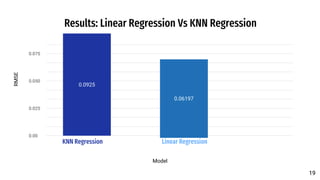
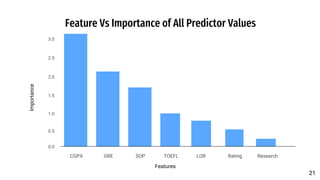
The document discusses a predictive model developed to assess the chances of graduate admission using two regression models (linear regression and KNN) and three classification models (decision tree, Bayesian, KNN). The model utilizes a dataset containing various academic metrics such as GRE scores, TOEFL scores, GPA, and recommendation strength, aiming to provide prospective students with insights on their admission probabilities. Results indicate linear regression outperforms KNN, with CGPA being the most influential factor in admission chances.



























![[DSC Europe 22] Machine learning algorithms as tools for student success pred...](https://cdn.slidesharecdn.com/ss_thumbnails/dijanaoreski-machinelearningalgorithmsastoolsforstudentsuccessprediction-221130080709-c0f224ba-thumbnail.jpg?width=640&height=640&fit=bounds)

































