Download to read offline




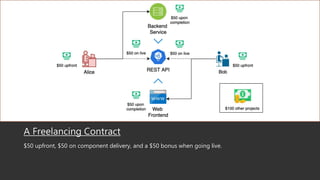

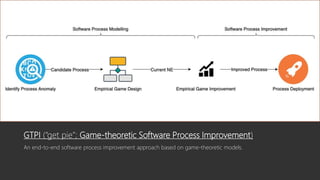

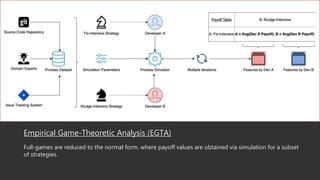
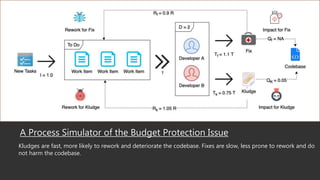
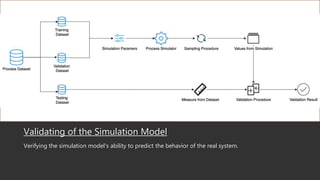

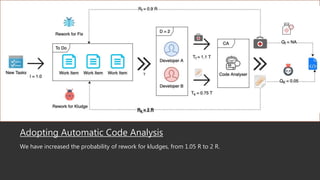

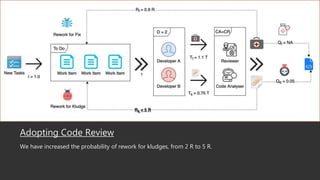
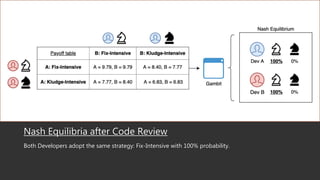



This document summarizes a research paper that uses game theory to analyze software development practices and processes. It describes how game theory can model conflicts and cooperation between decision makers. It then discusses several software development dilemmas, such as a freelancer's dilemma over work quality and a team's dilemma over quick fixes versus proper long term solutions. The researchers built simulation models of these dilemmas and analyzed how different development practices, like code reviews, affect the optimal strategies and outcomes. Their goal is to apply game theory to improve software processes and practices.
























































