1. Game playing is an important domain for artificial intelligence research as games provide formal reasoning problems that allow direct comparison between computer programs and humans.
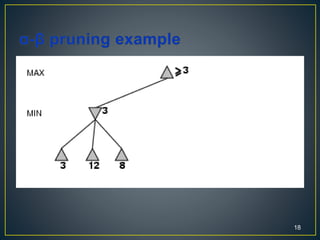
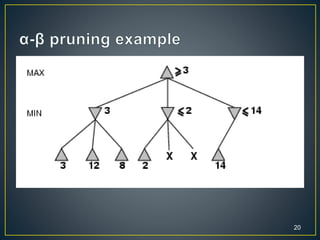
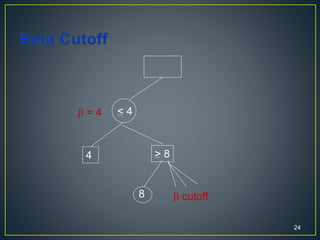
2. Alpha-beta pruning can speed up minimax search in game trees by pruning branches that cannot alter the outcome. It works by maintaining lower and upper bounds on the score.
3. Evaluating leaf nodes is challenging. For chess, linear evaluation functions combining weighted features like material and position are commonly used, and reinforcement learning can help tune the weights.