Download as PDF, PPTX









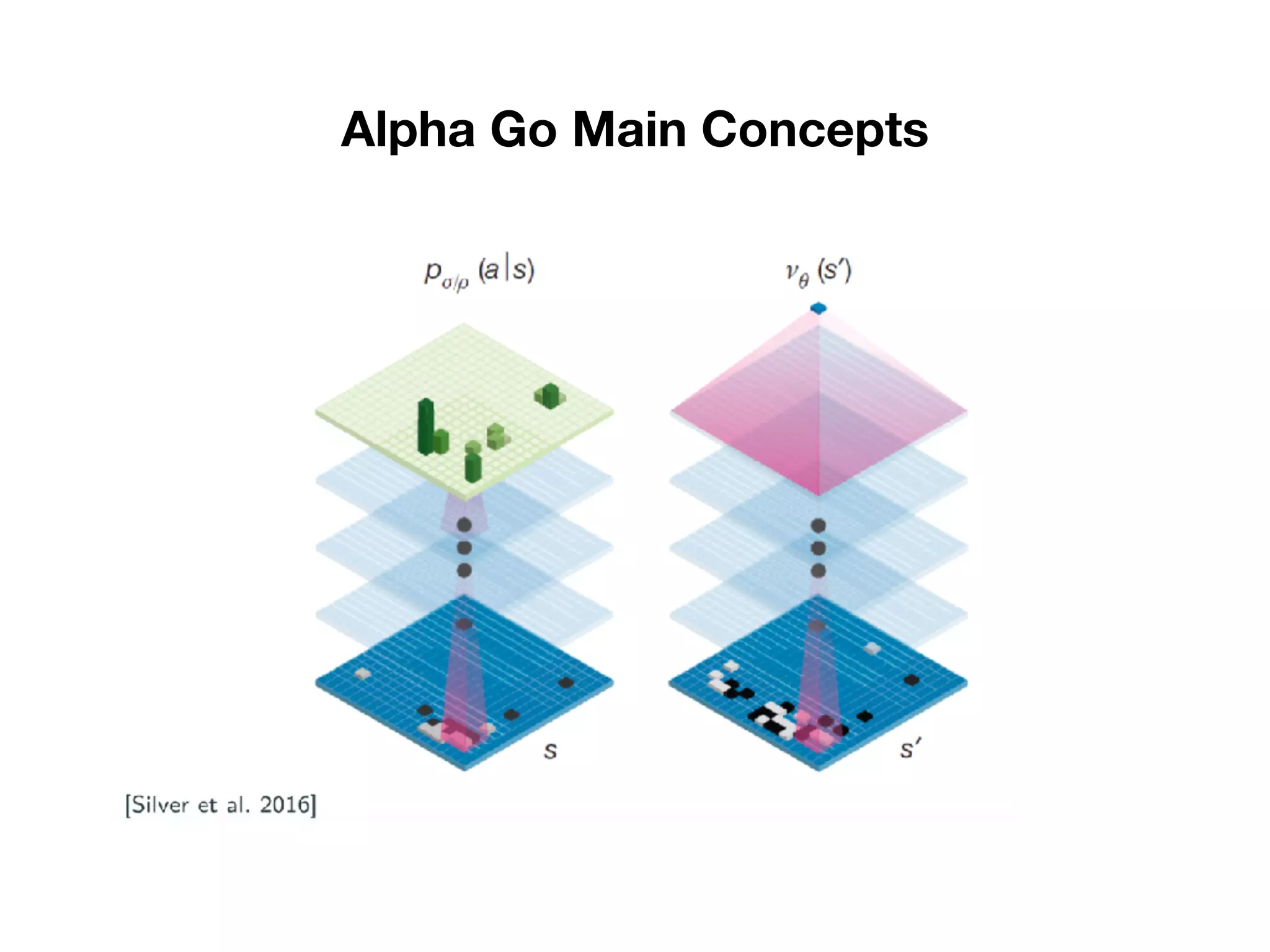

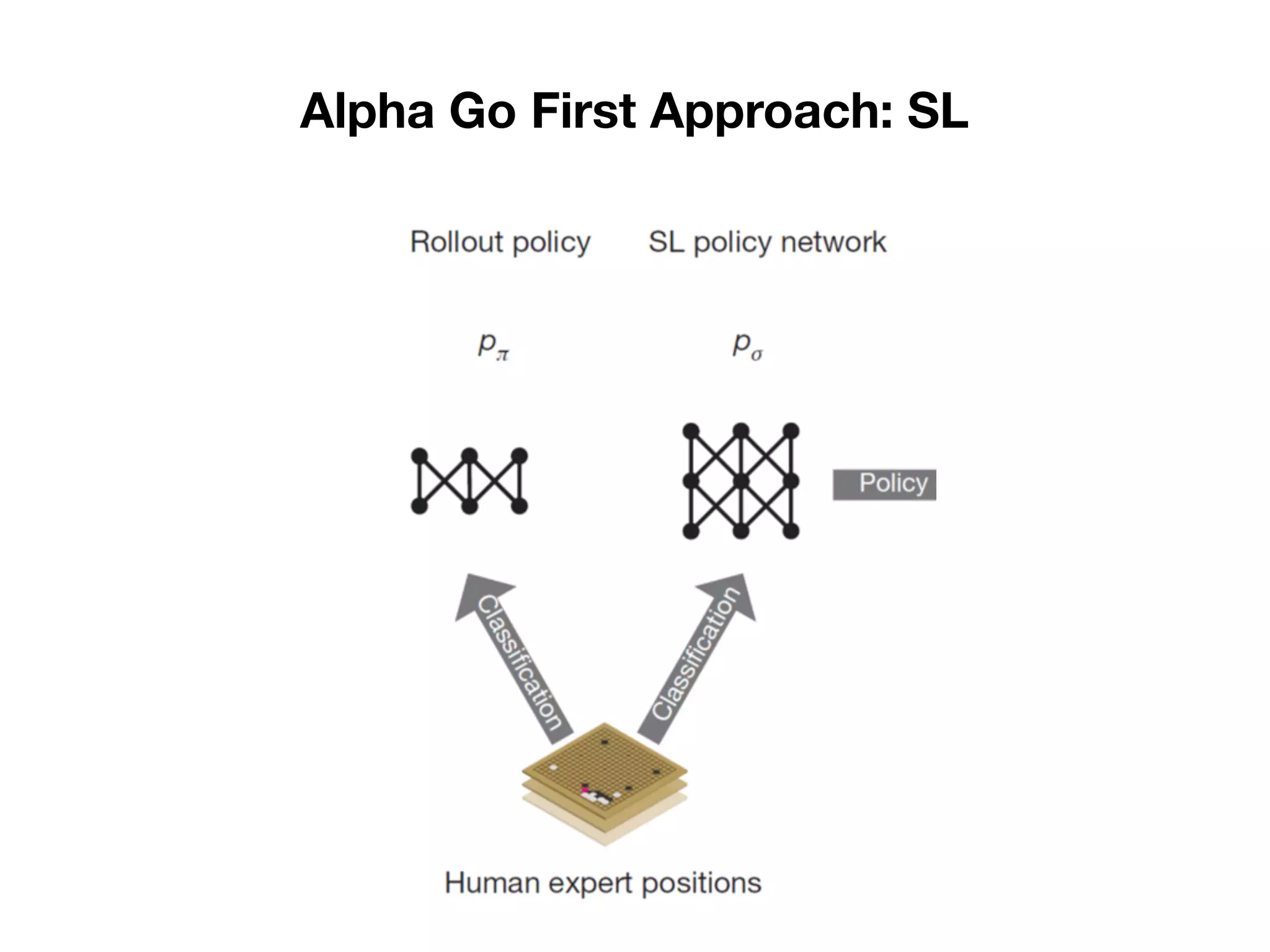
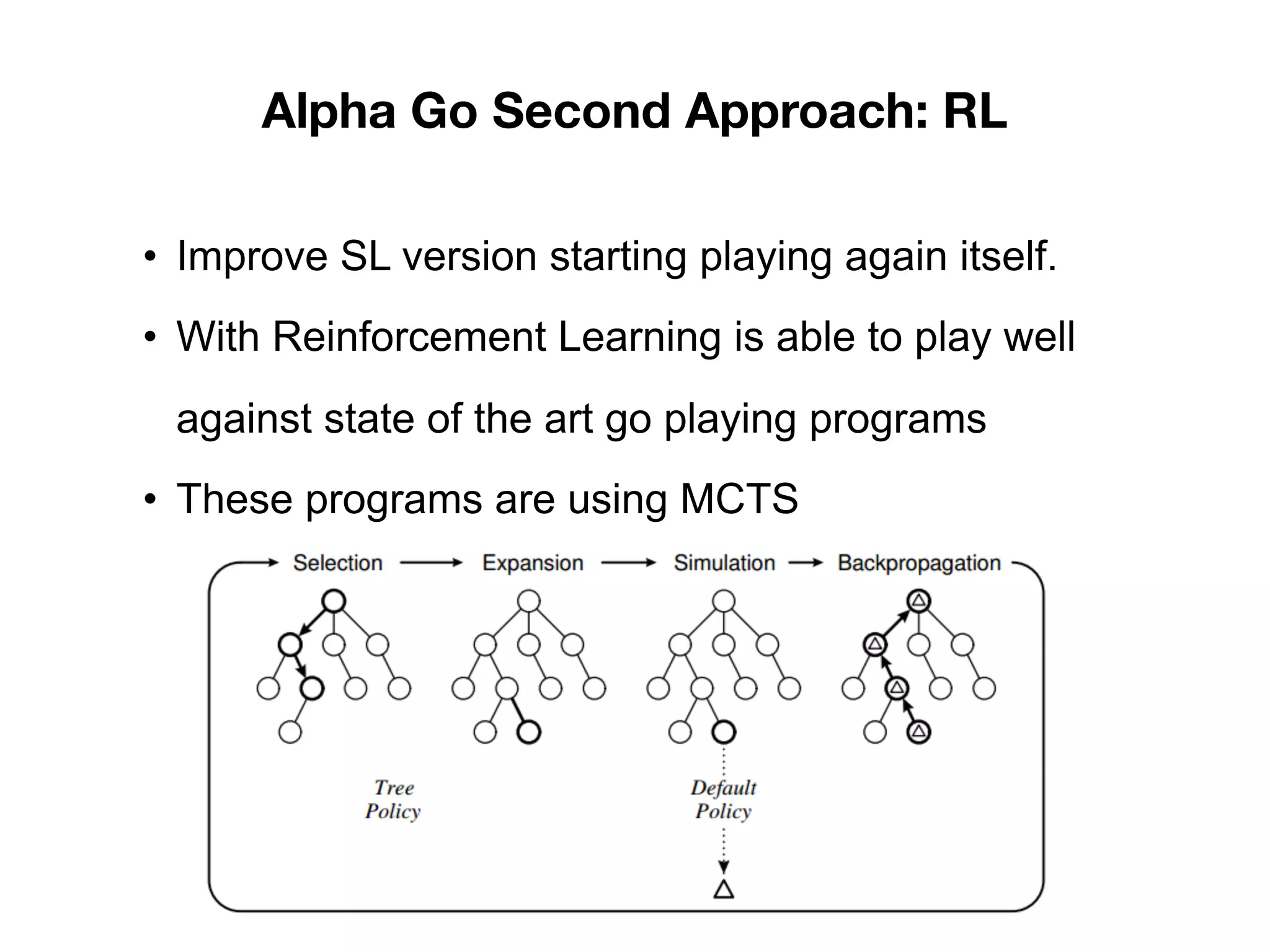










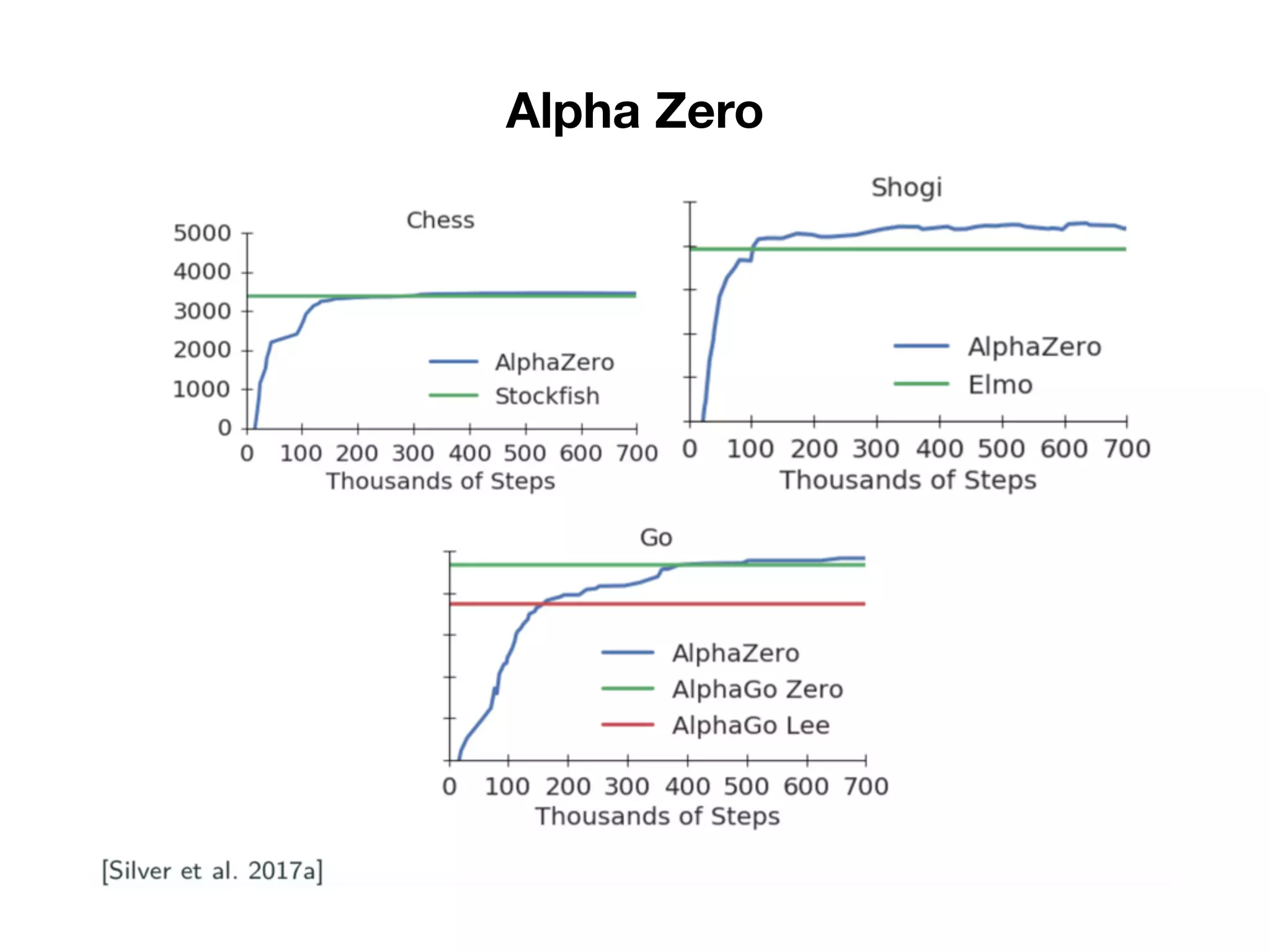








1) The document discusses the evolution of AlphaGo and related AI projects from Deep Blue, to AlphaGo, AlphaGo Zero, and AlphaZero. 2) It explains the key concepts behind AlphaGo including the policy and value neural networks, and how it was initially trained via supervised learning and then improved with reinforcement learning by playing against itself. 3) It summarizes the differences between AlphaGo Zero which was trained solely via reinforcement learning without human data, and AlphaZero which aims to solve games without specific tuning or data augmentation.





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





