Downloaded 31 times



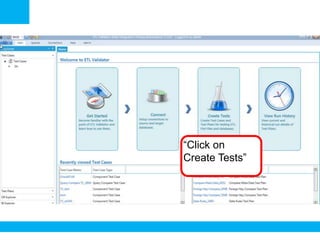

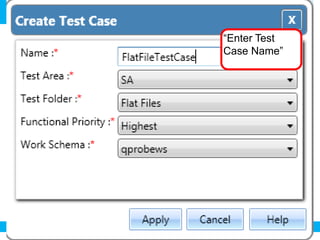
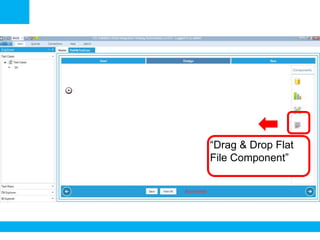
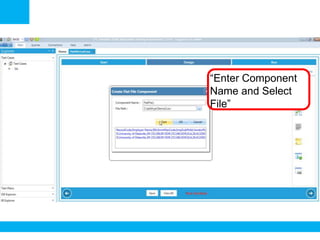
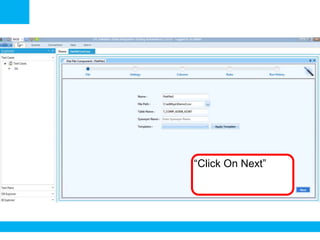
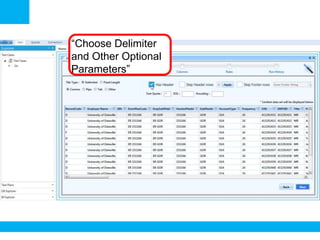
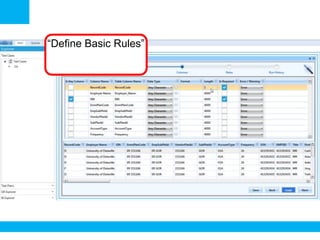
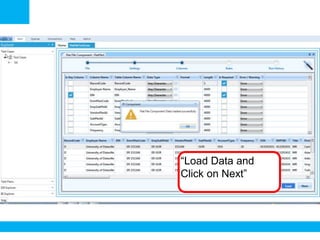
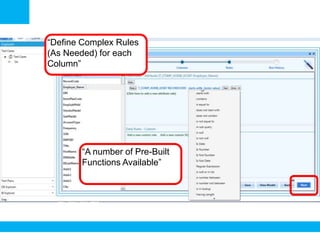
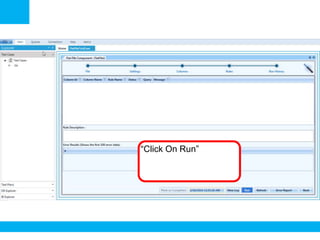
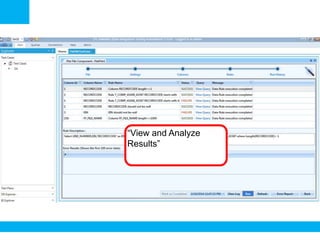


The document outlines a process for validating flat files using an ETL validator, specifically for QA engineers. It includes step-by-step instructions on how to create tests, define rules, and analyze results. Additionally, it mentions related tests for comparing various data formats.























































































