Download as PDF, PPTX

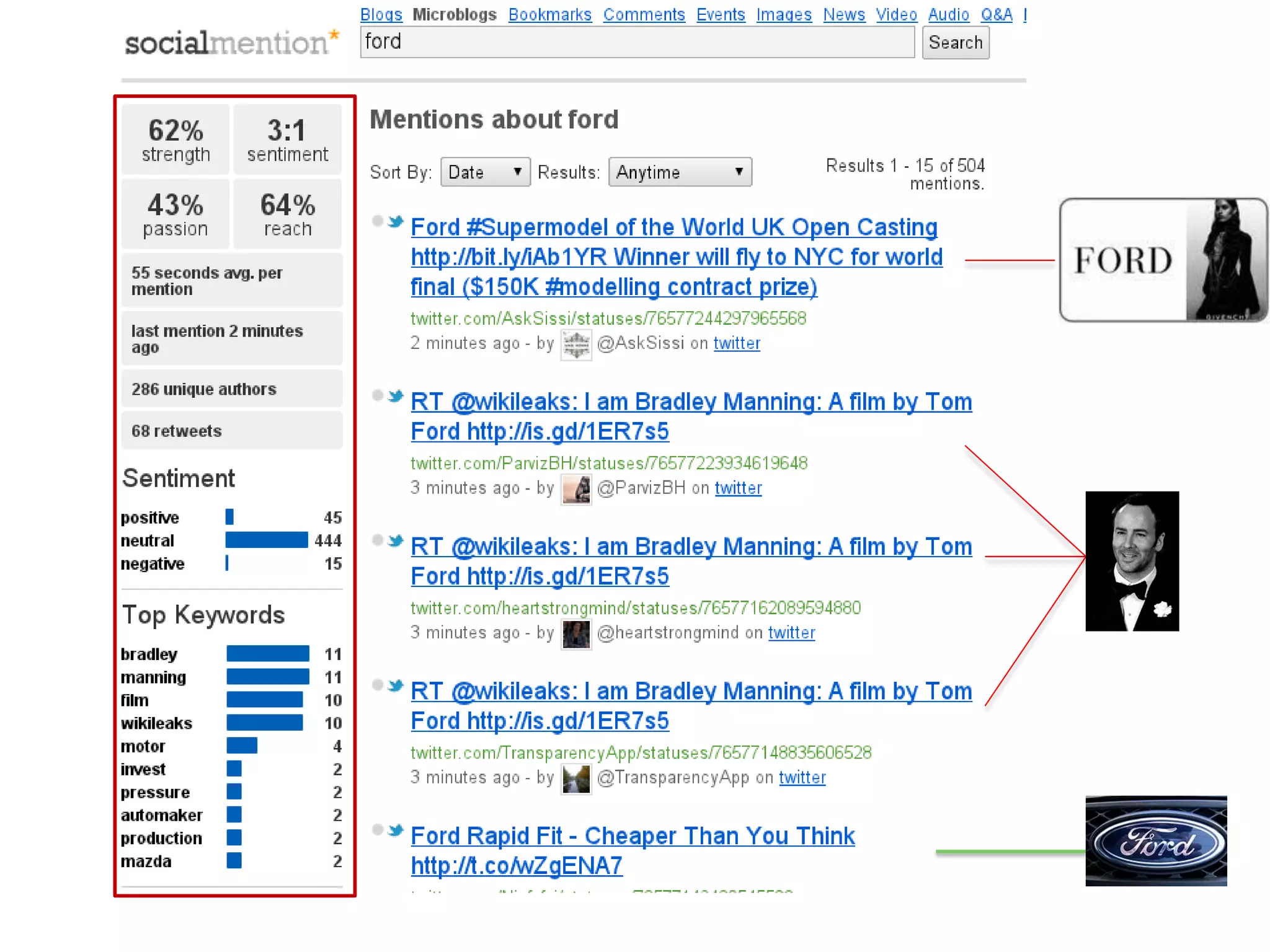


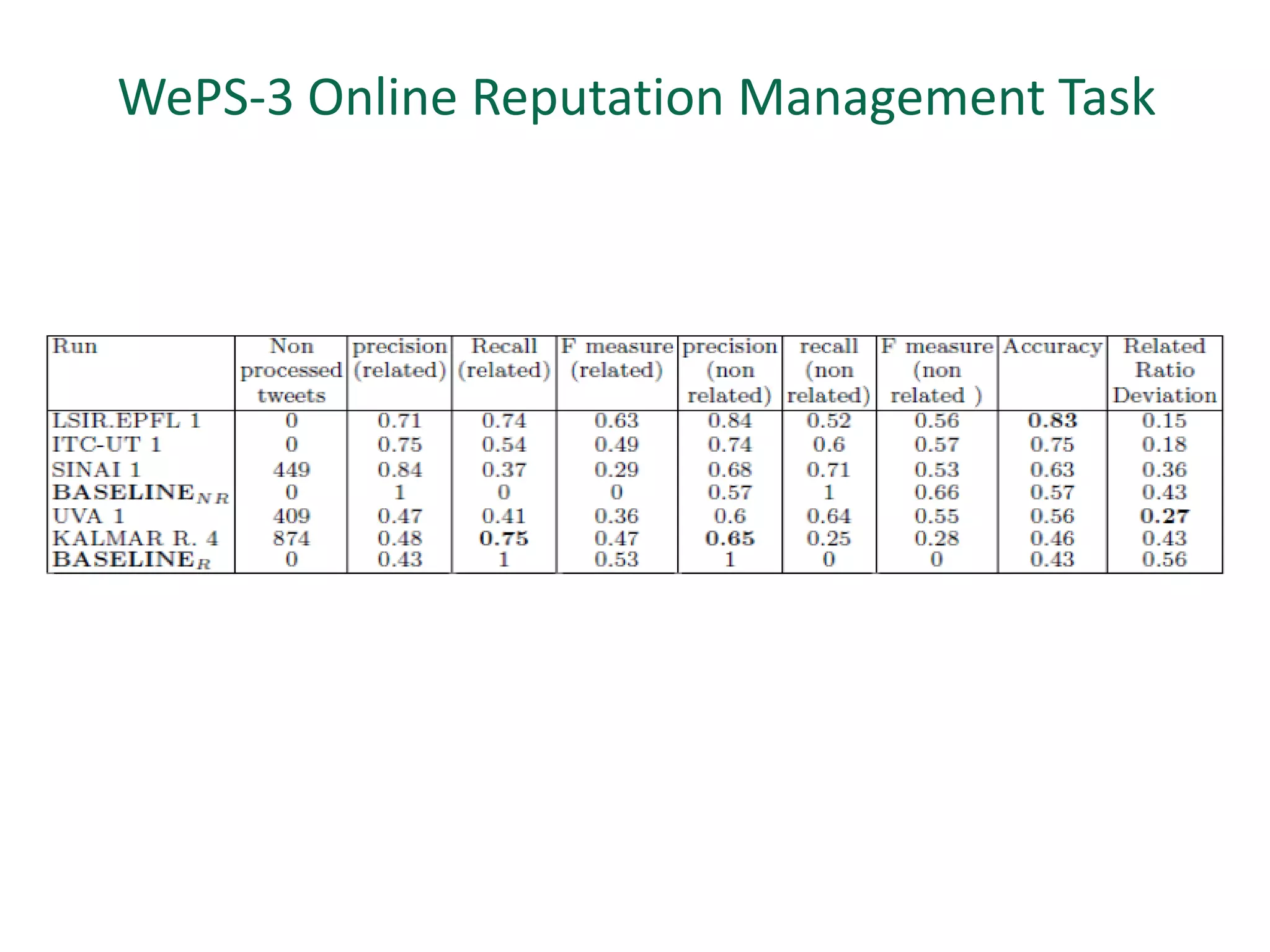
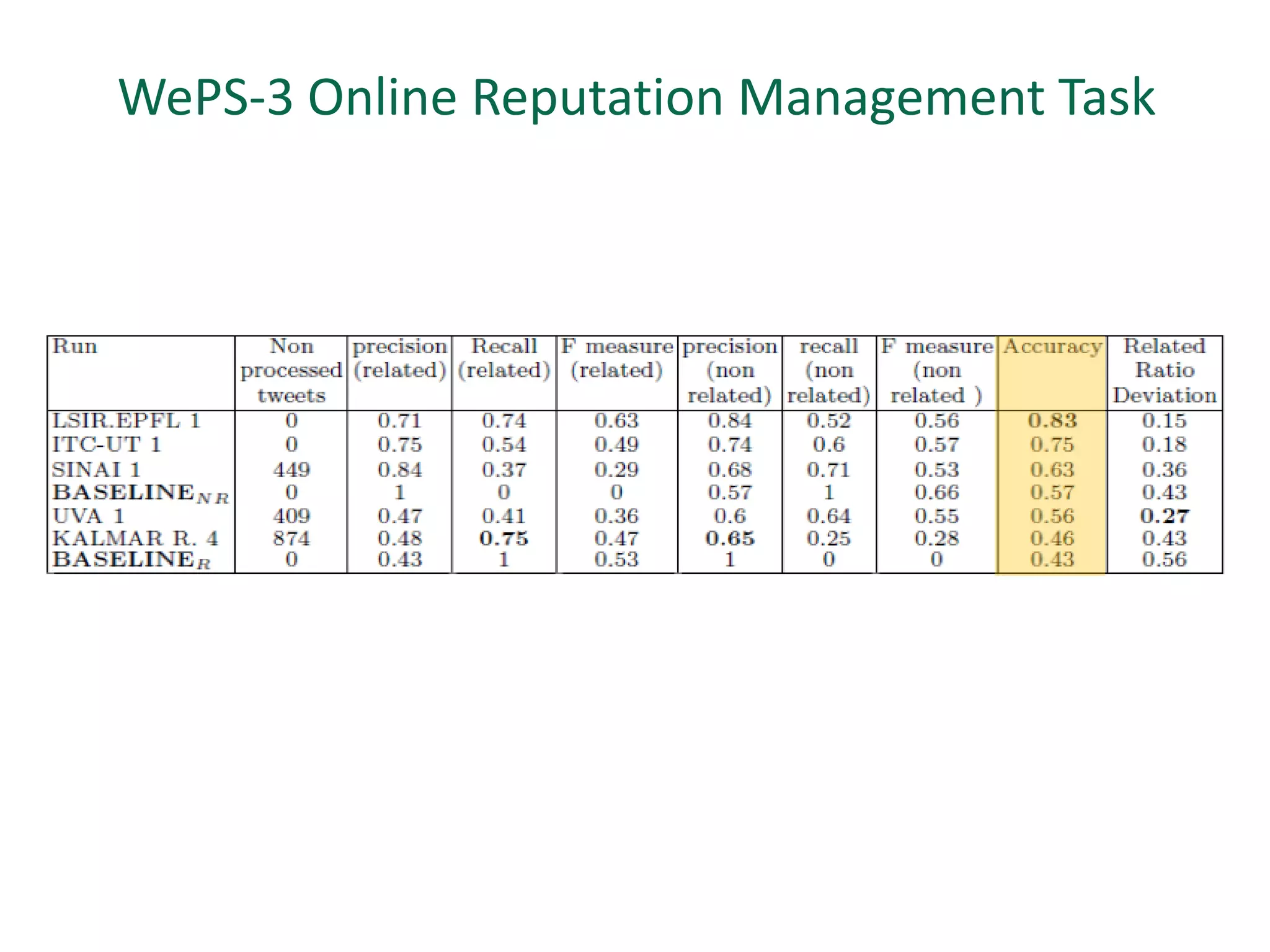
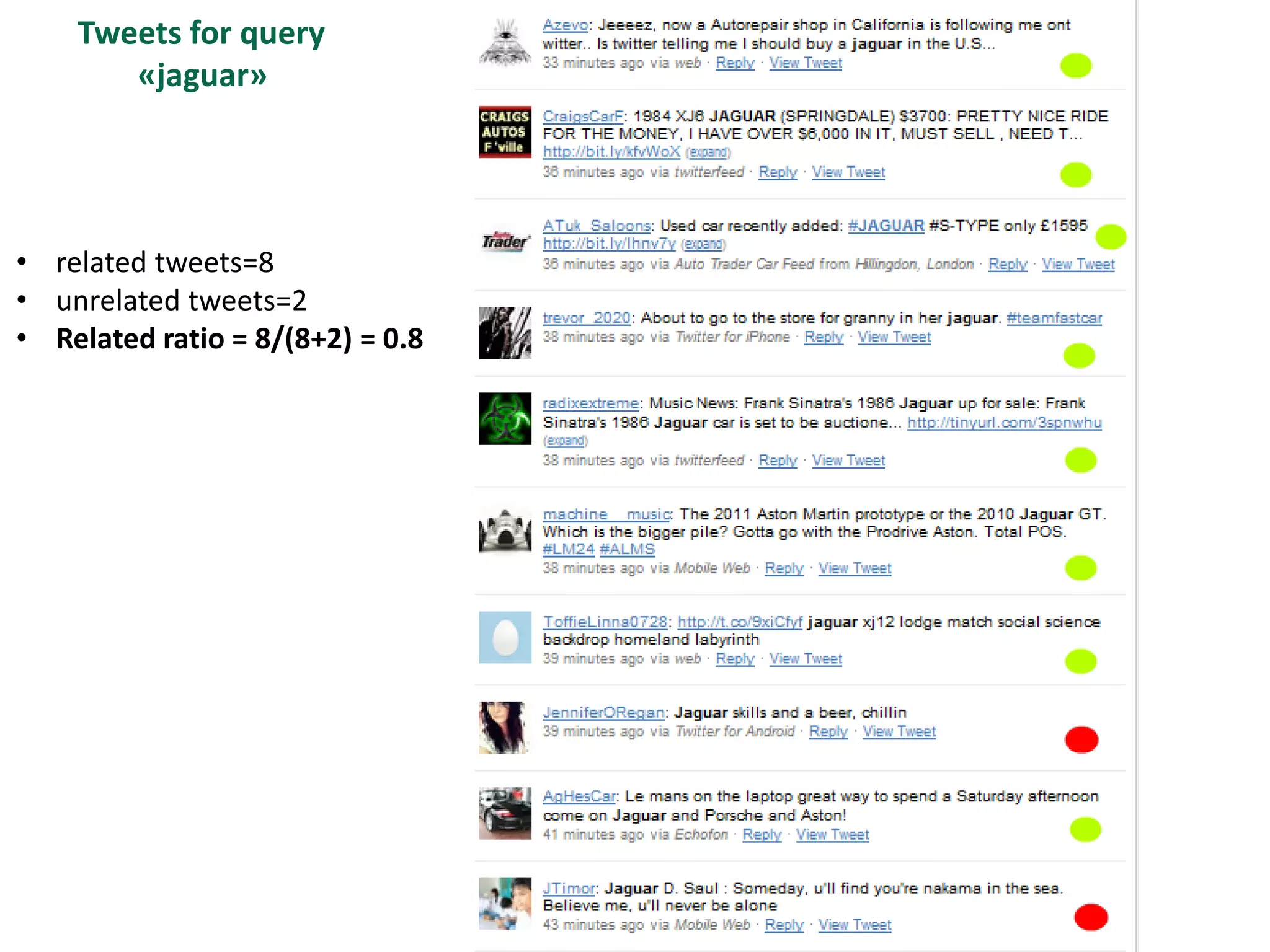
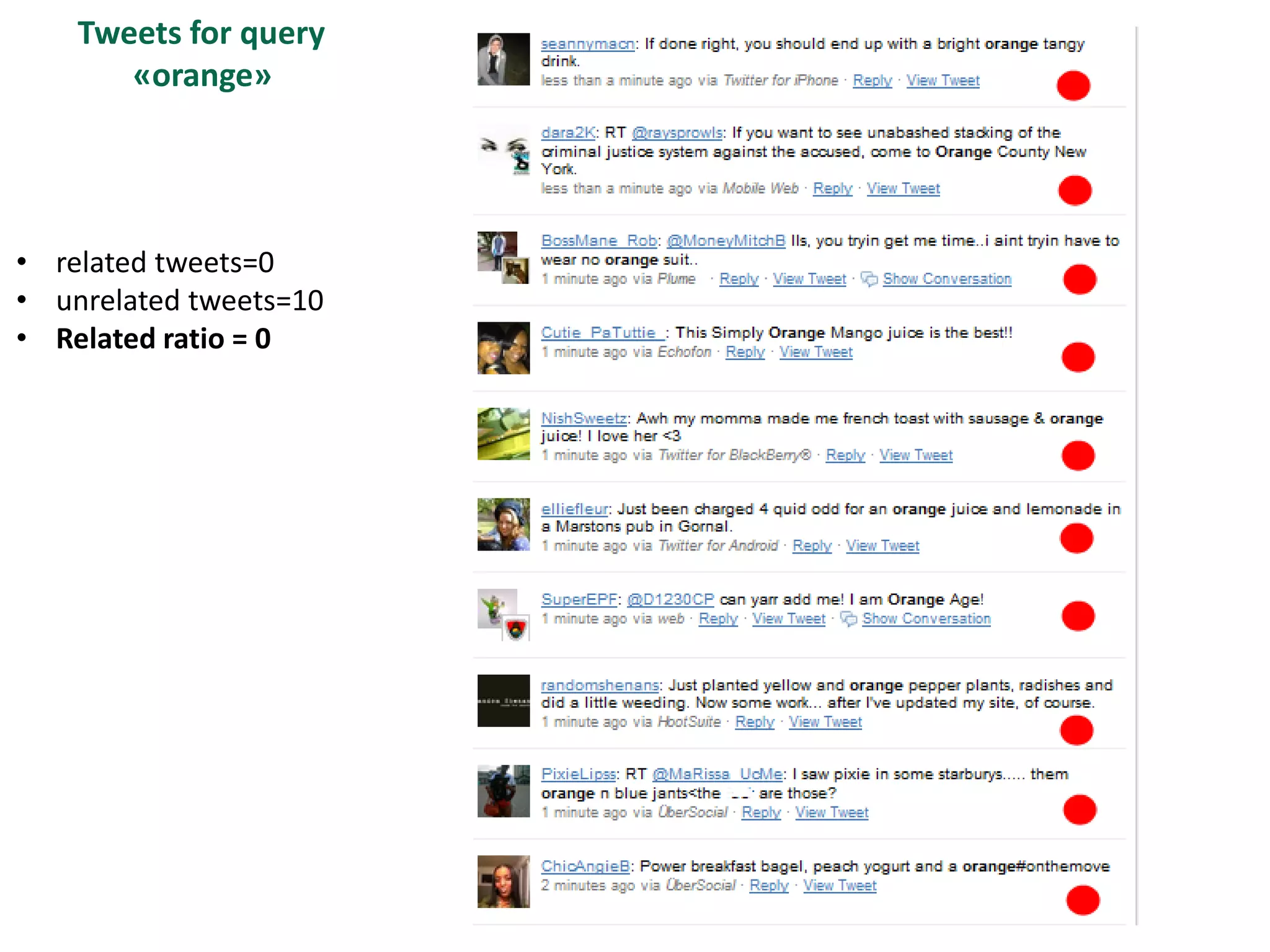
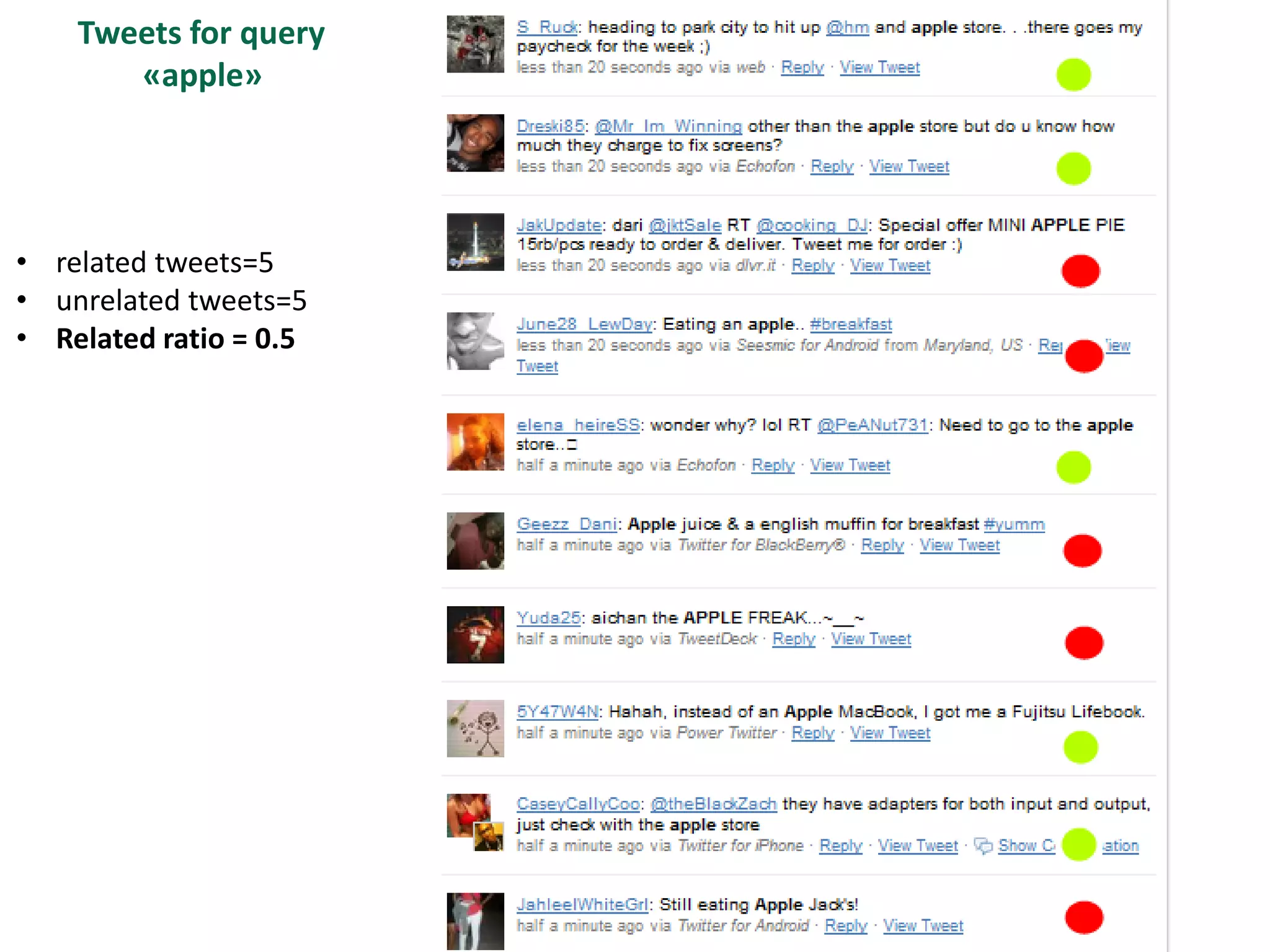
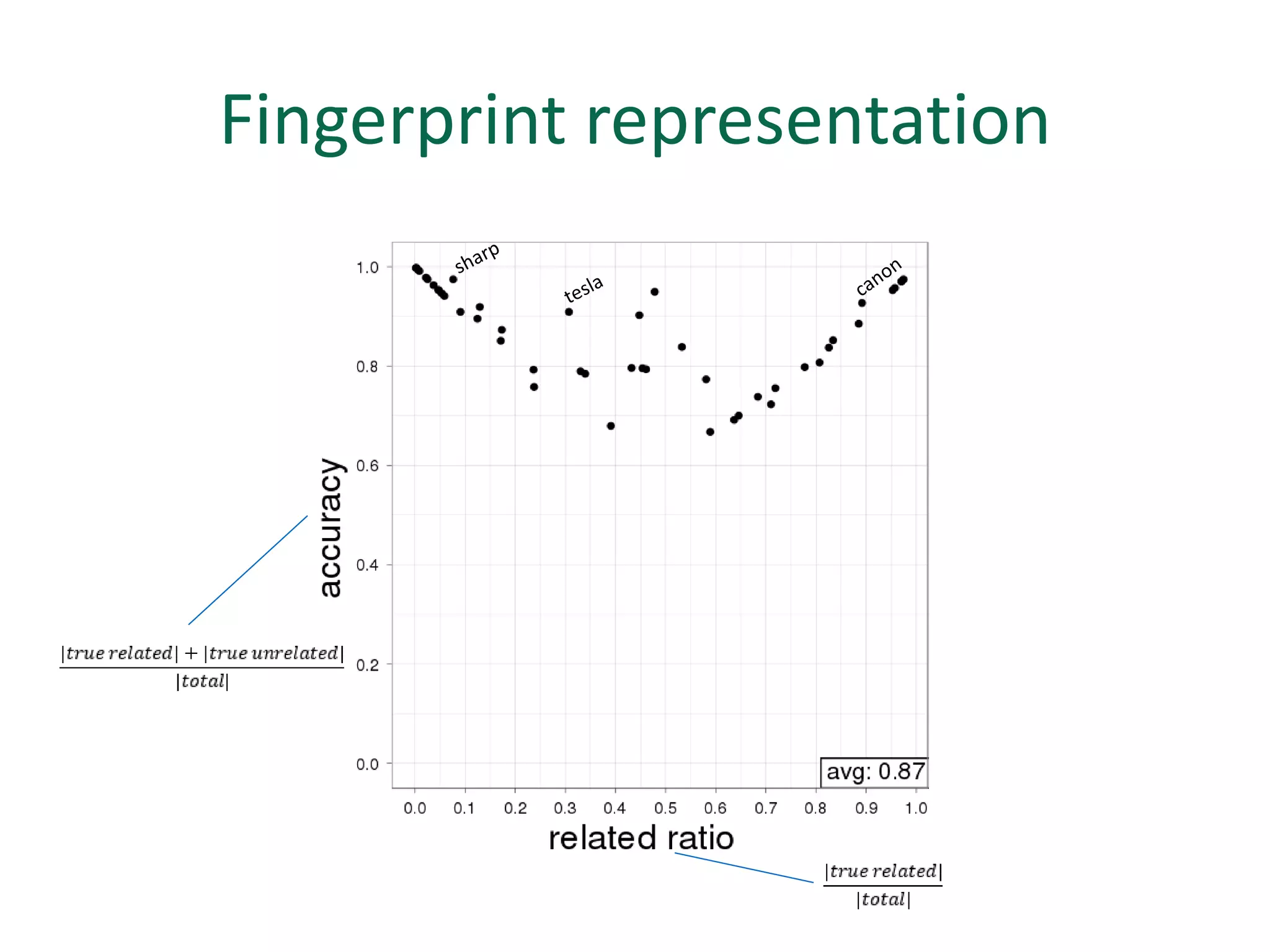
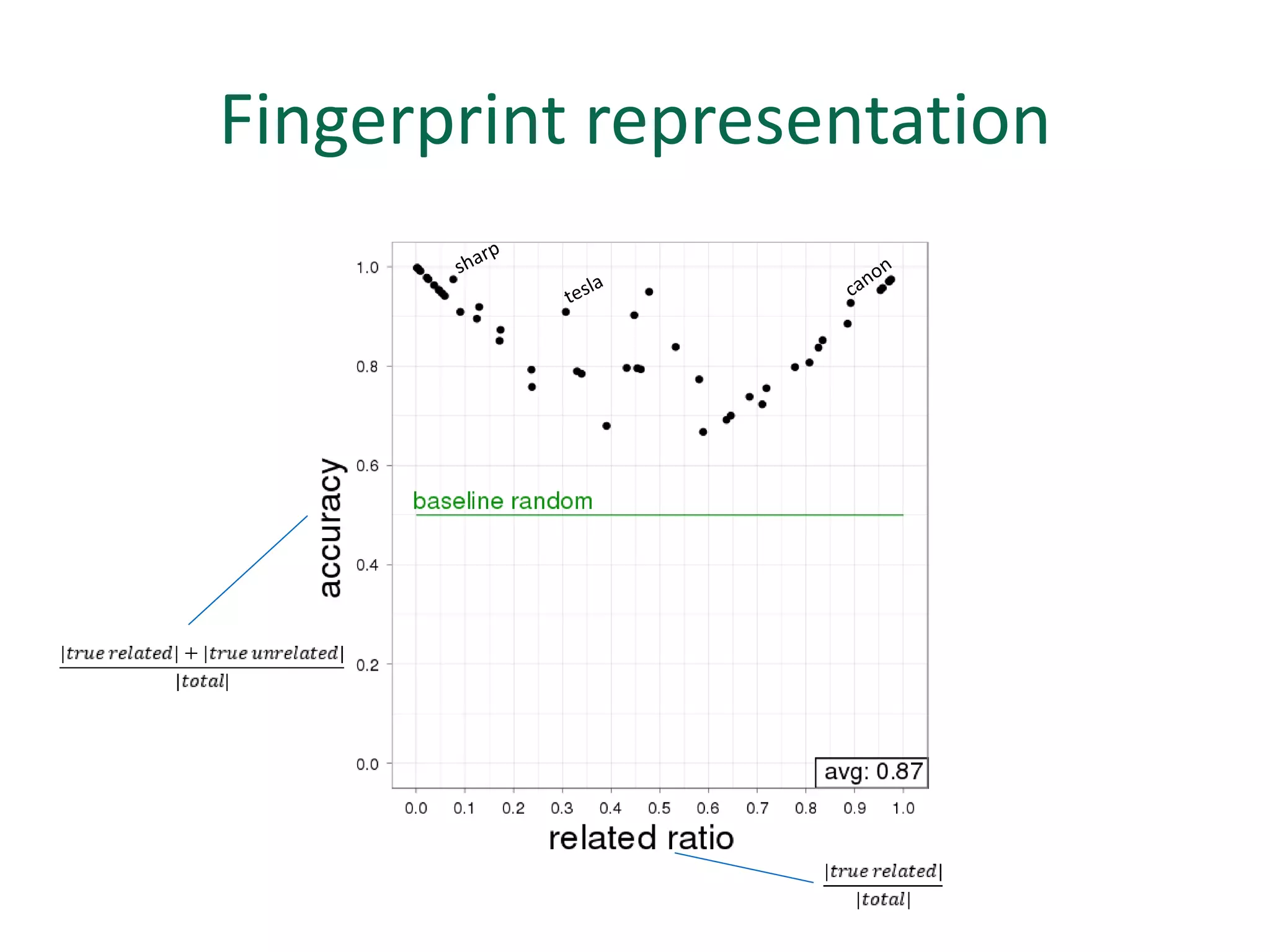
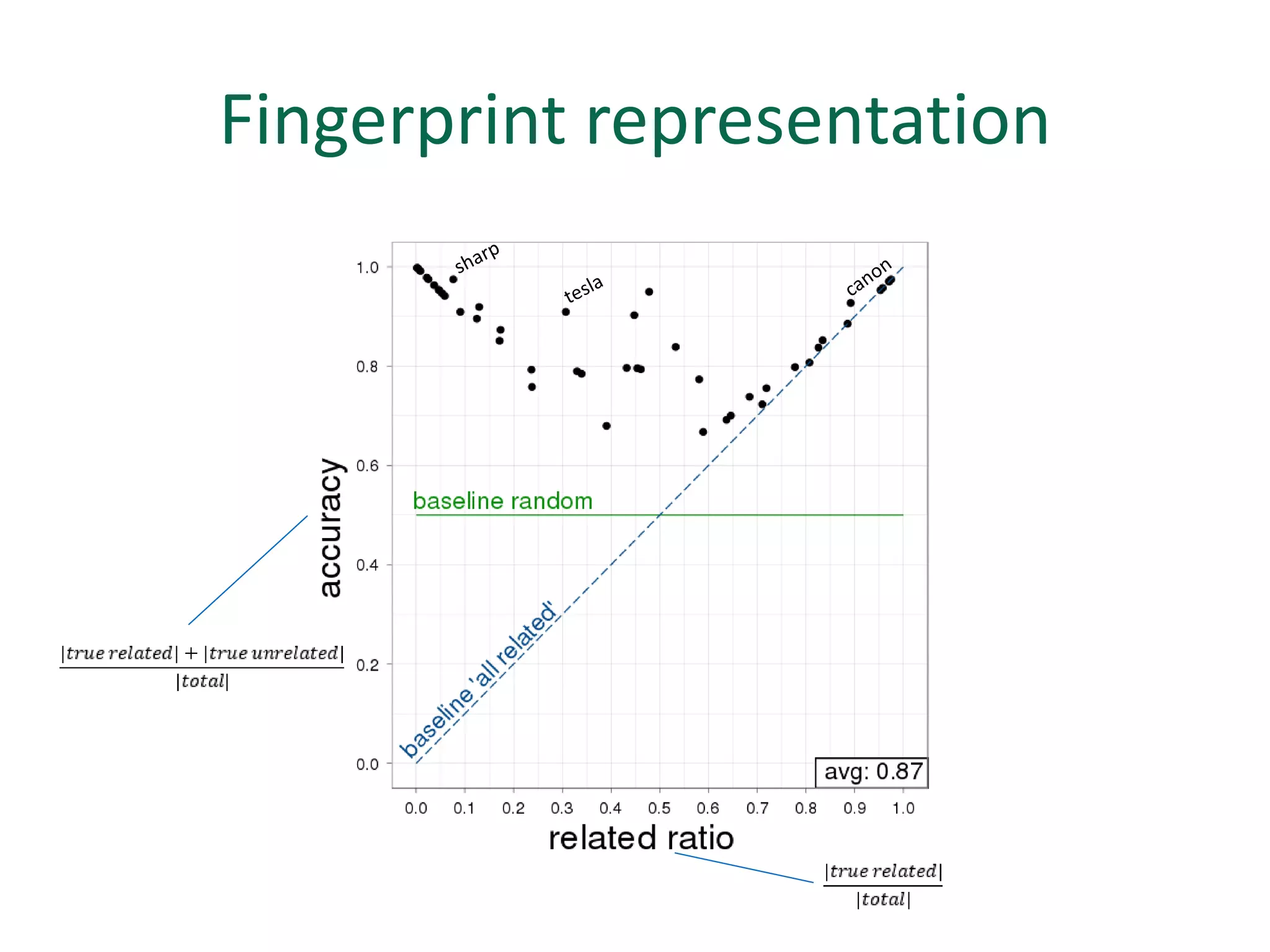
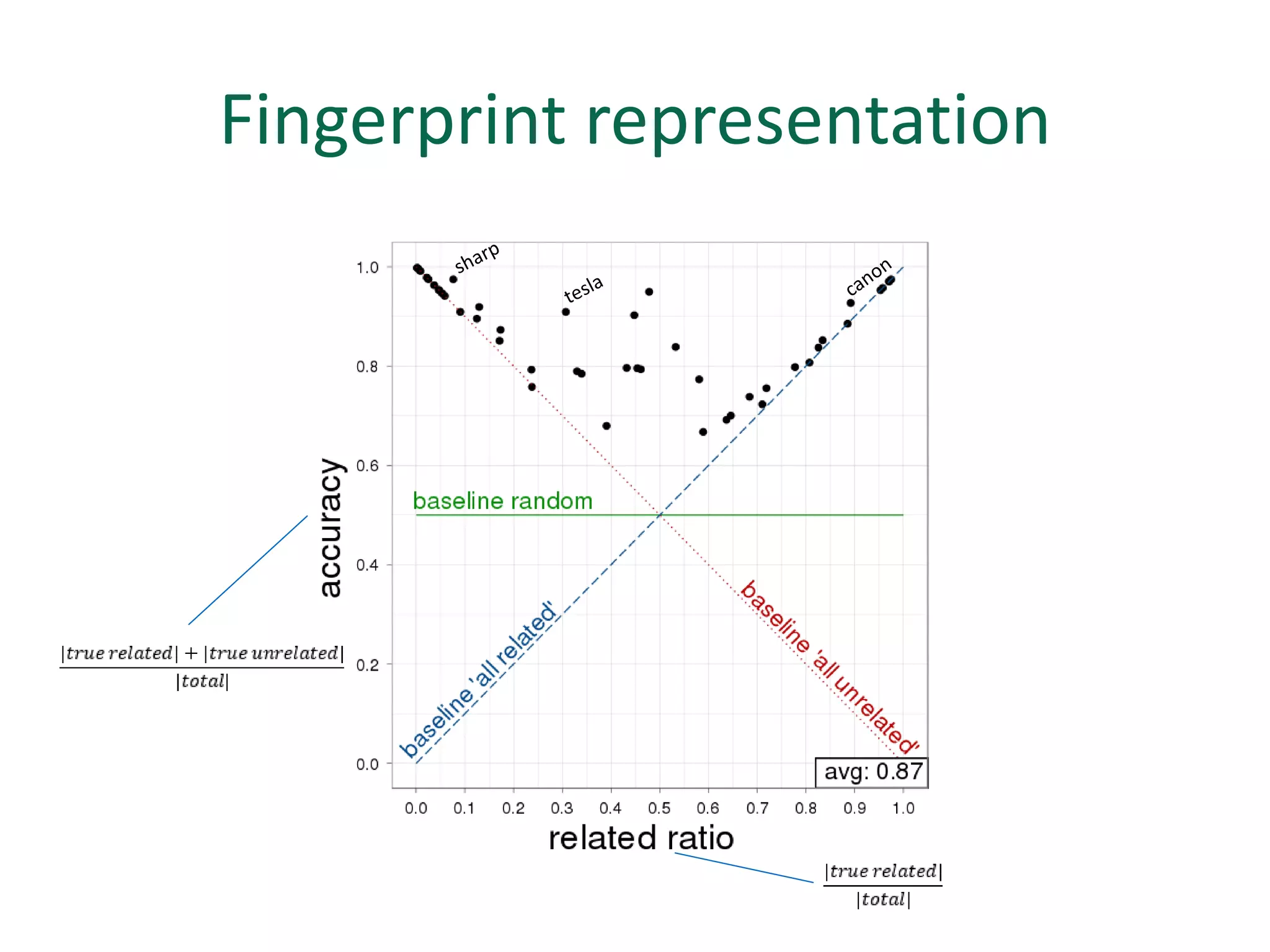
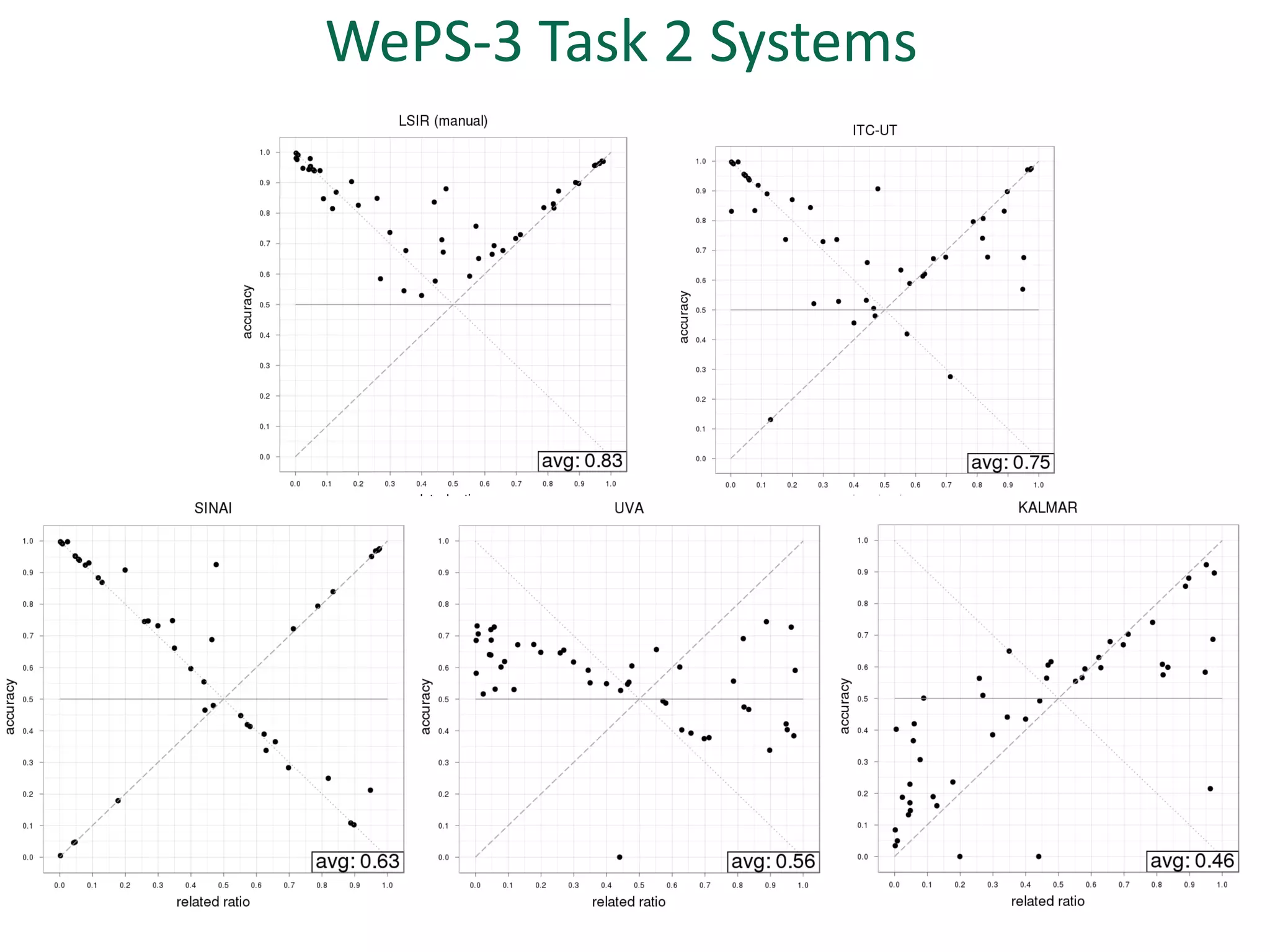
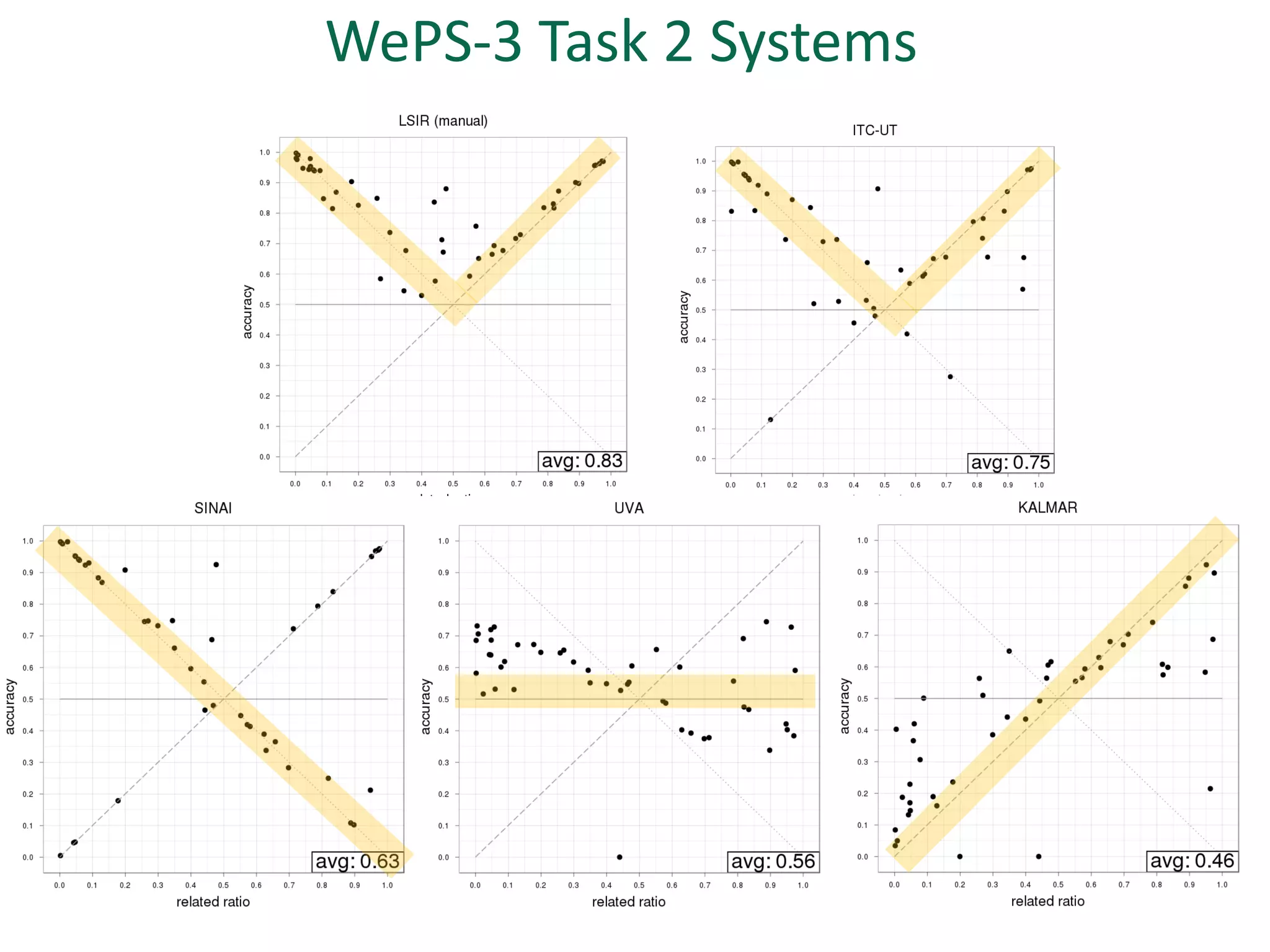

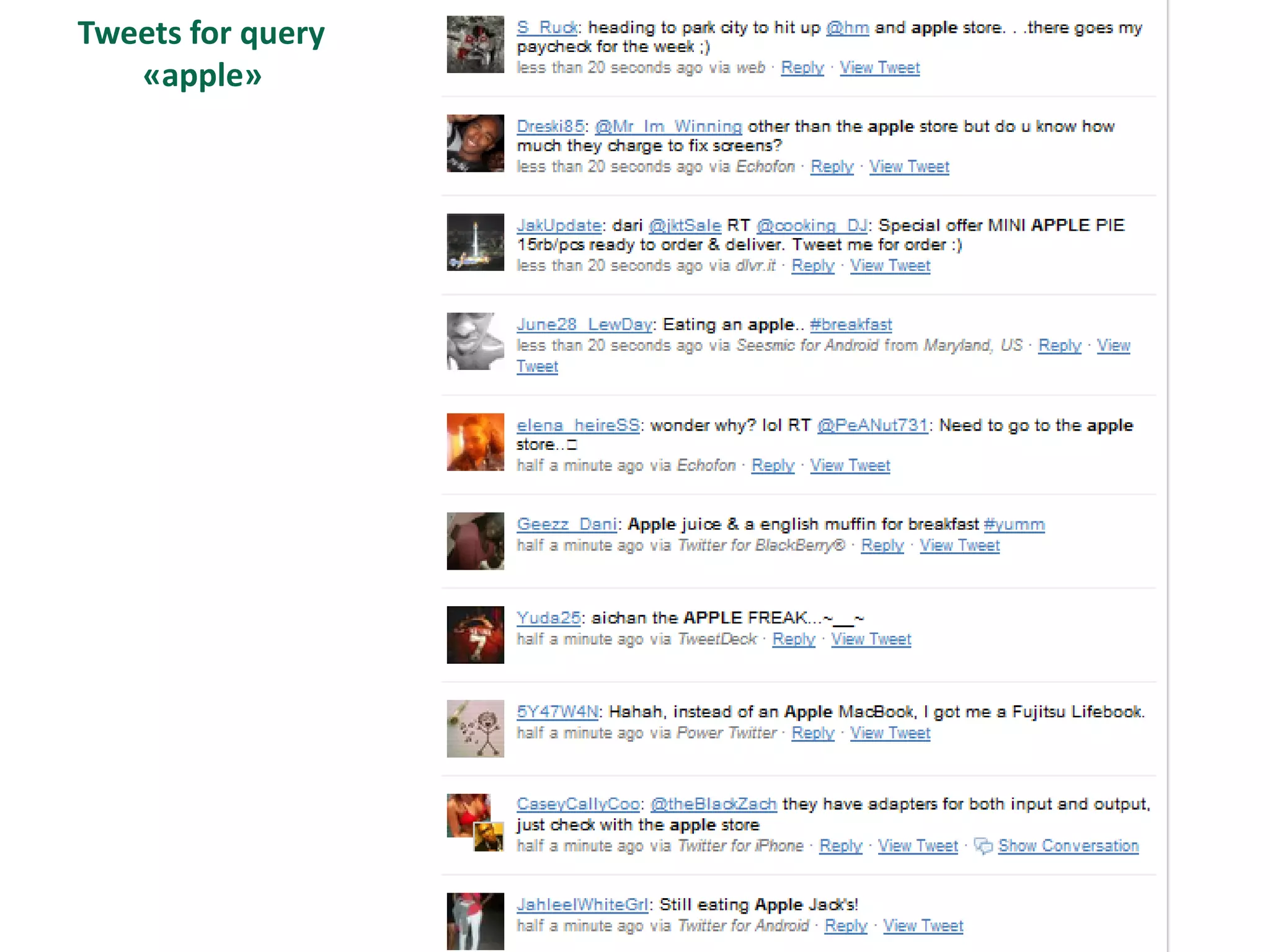
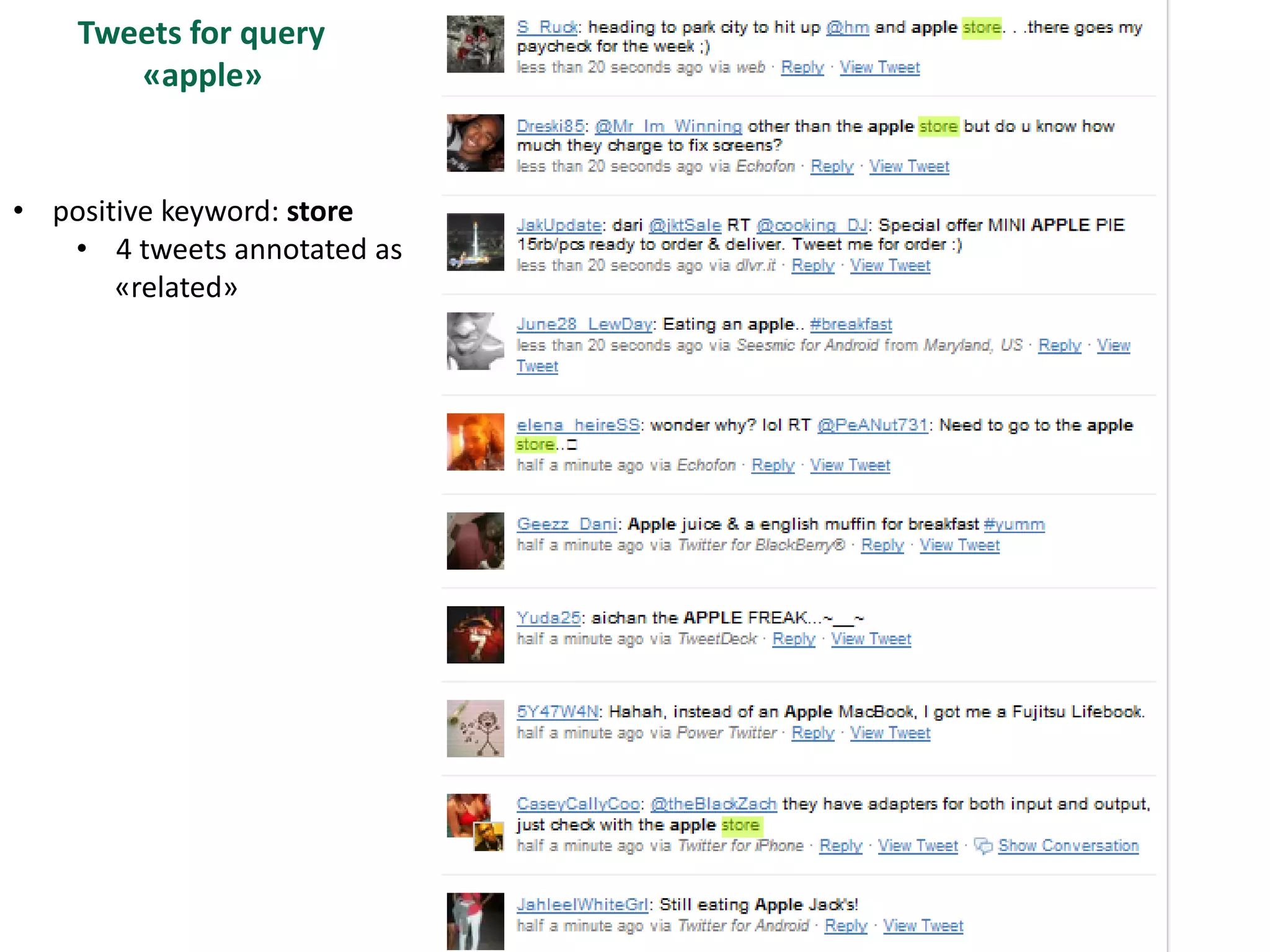
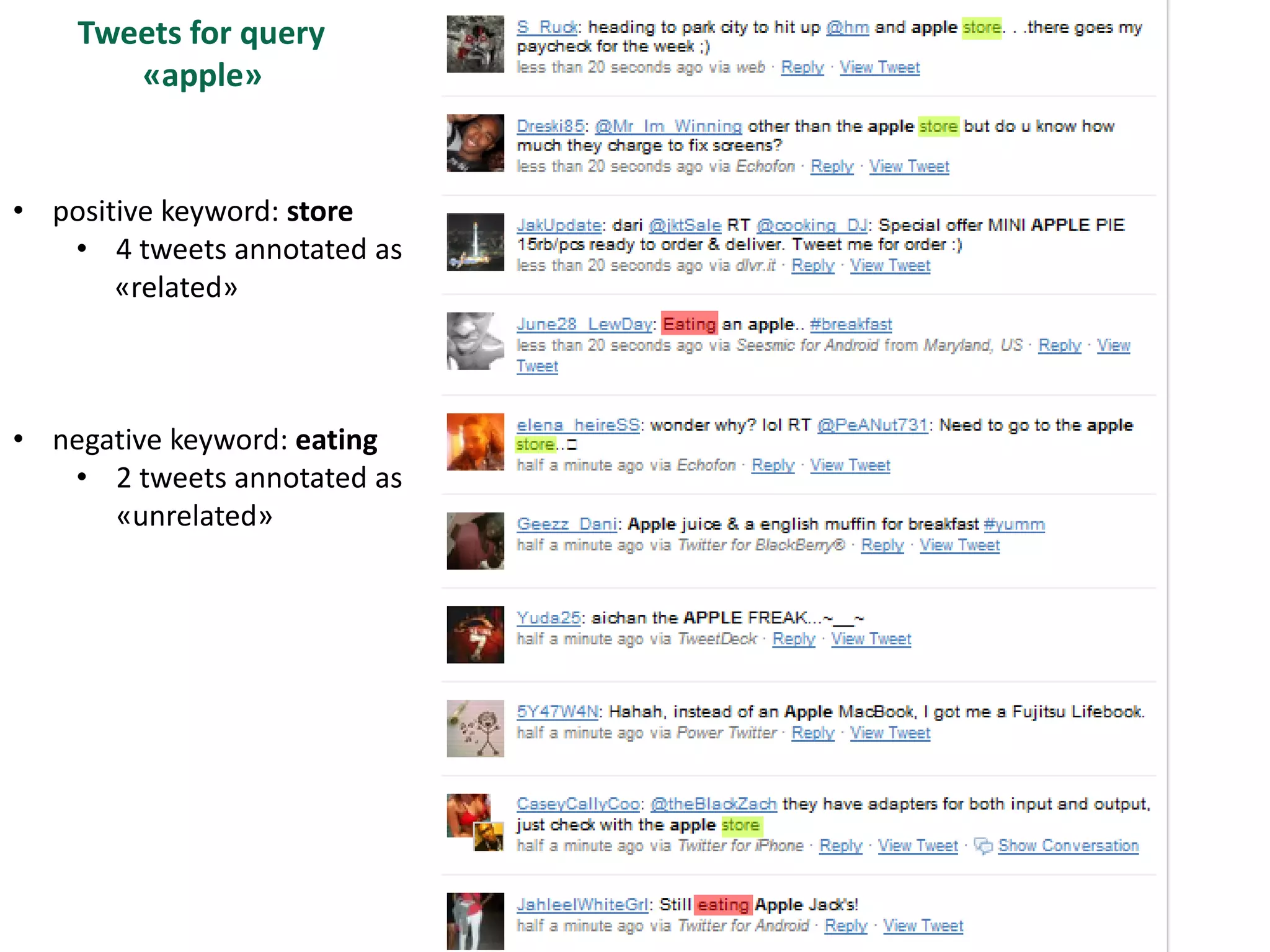
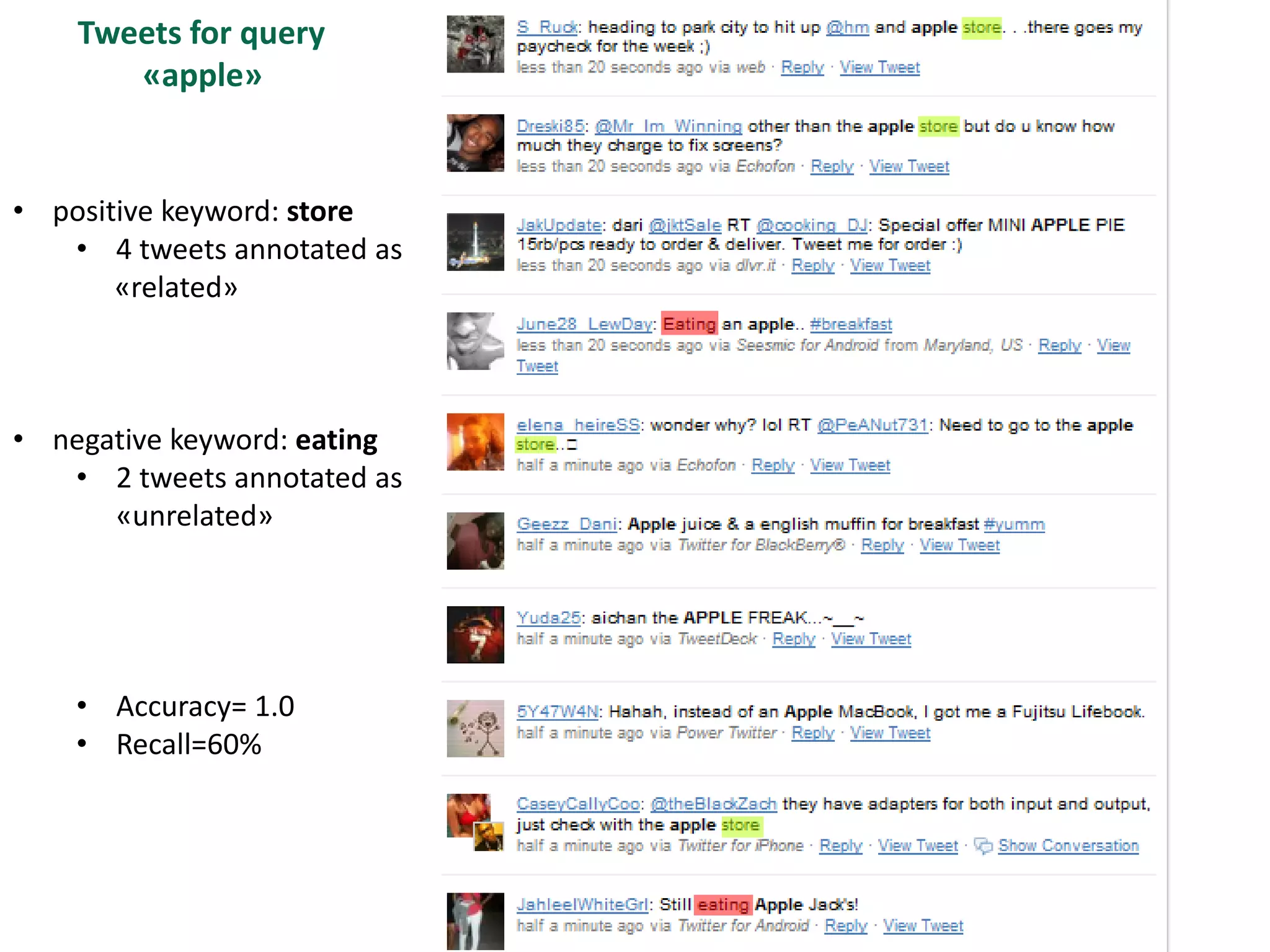
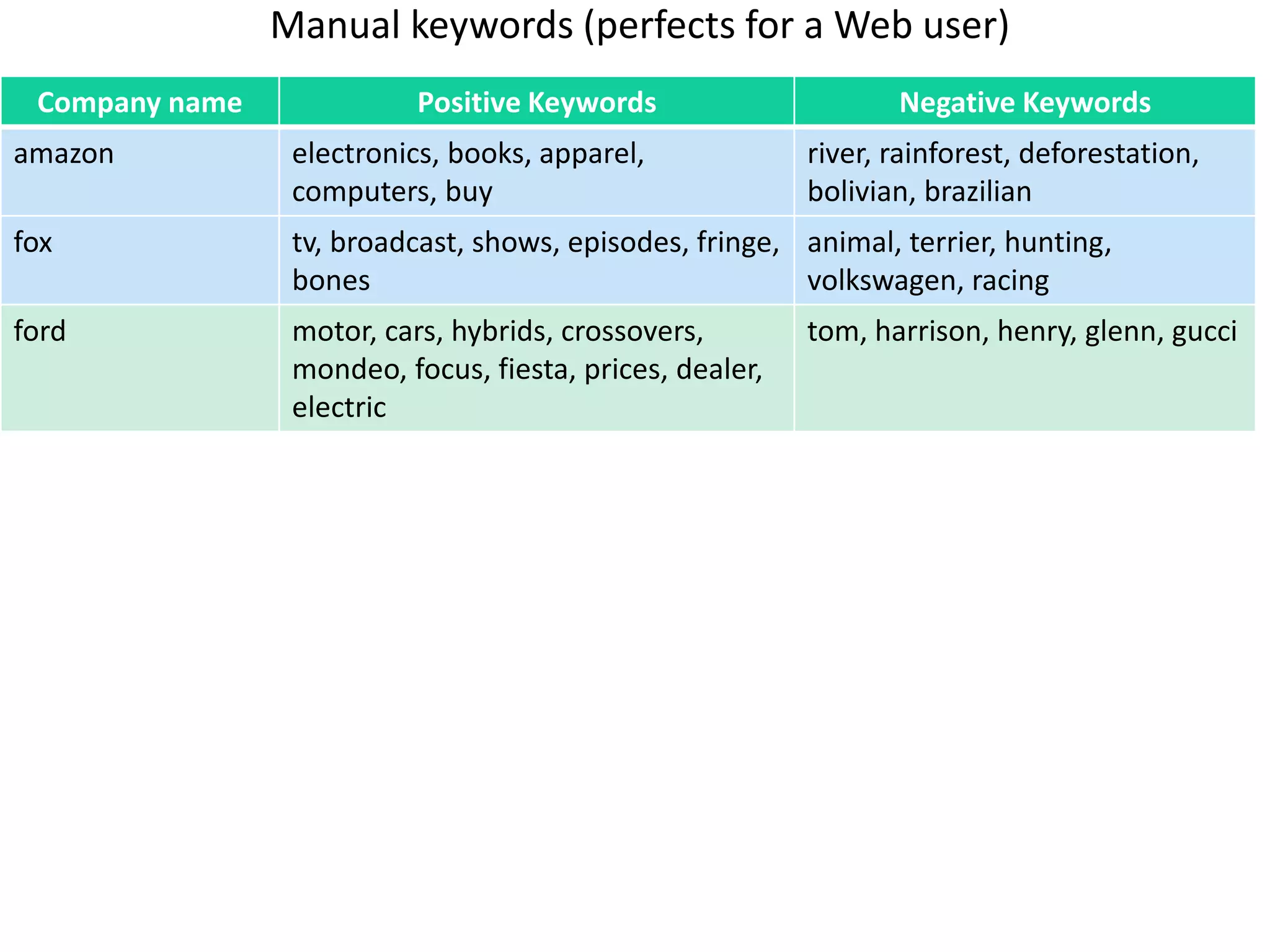
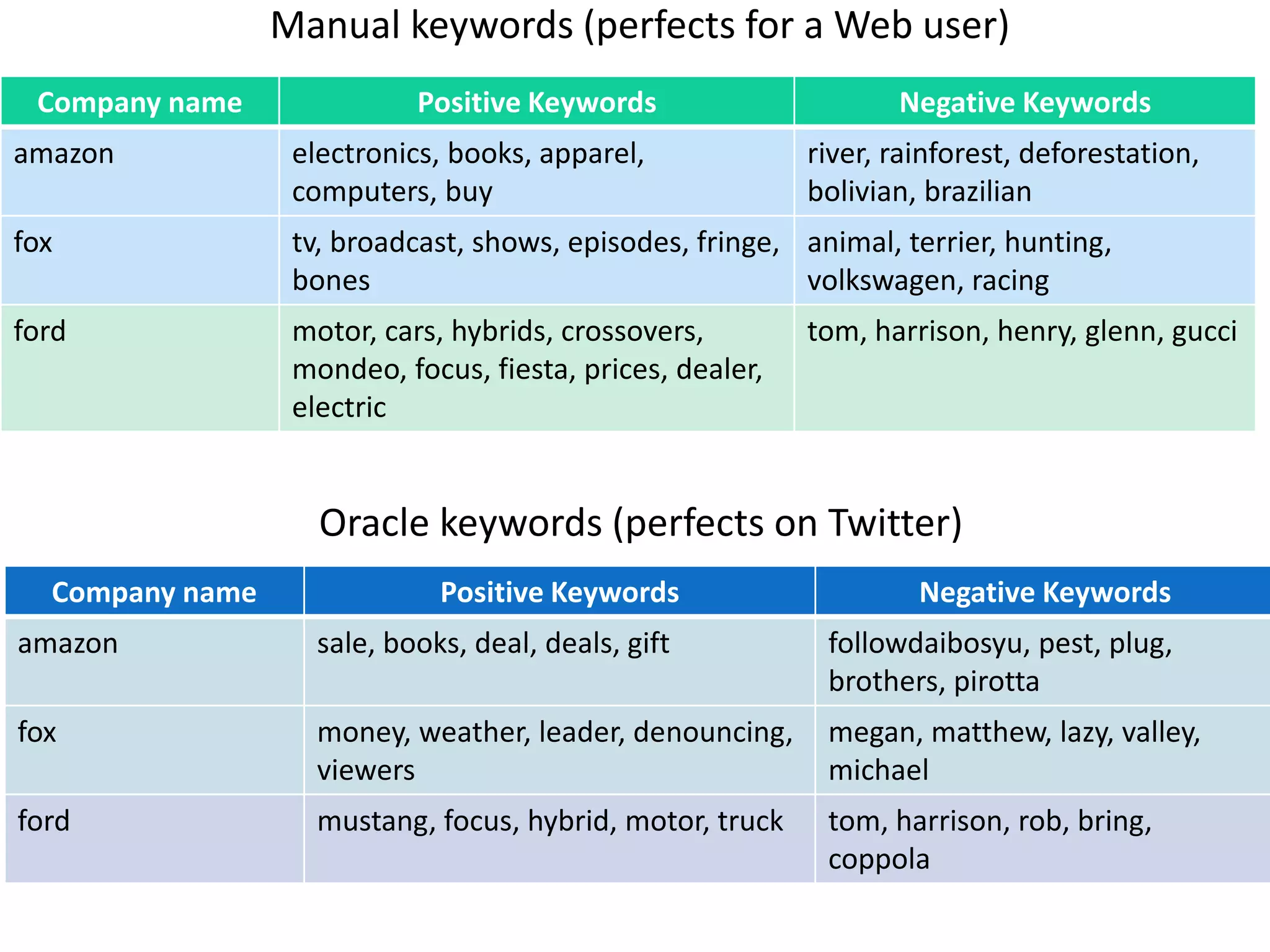
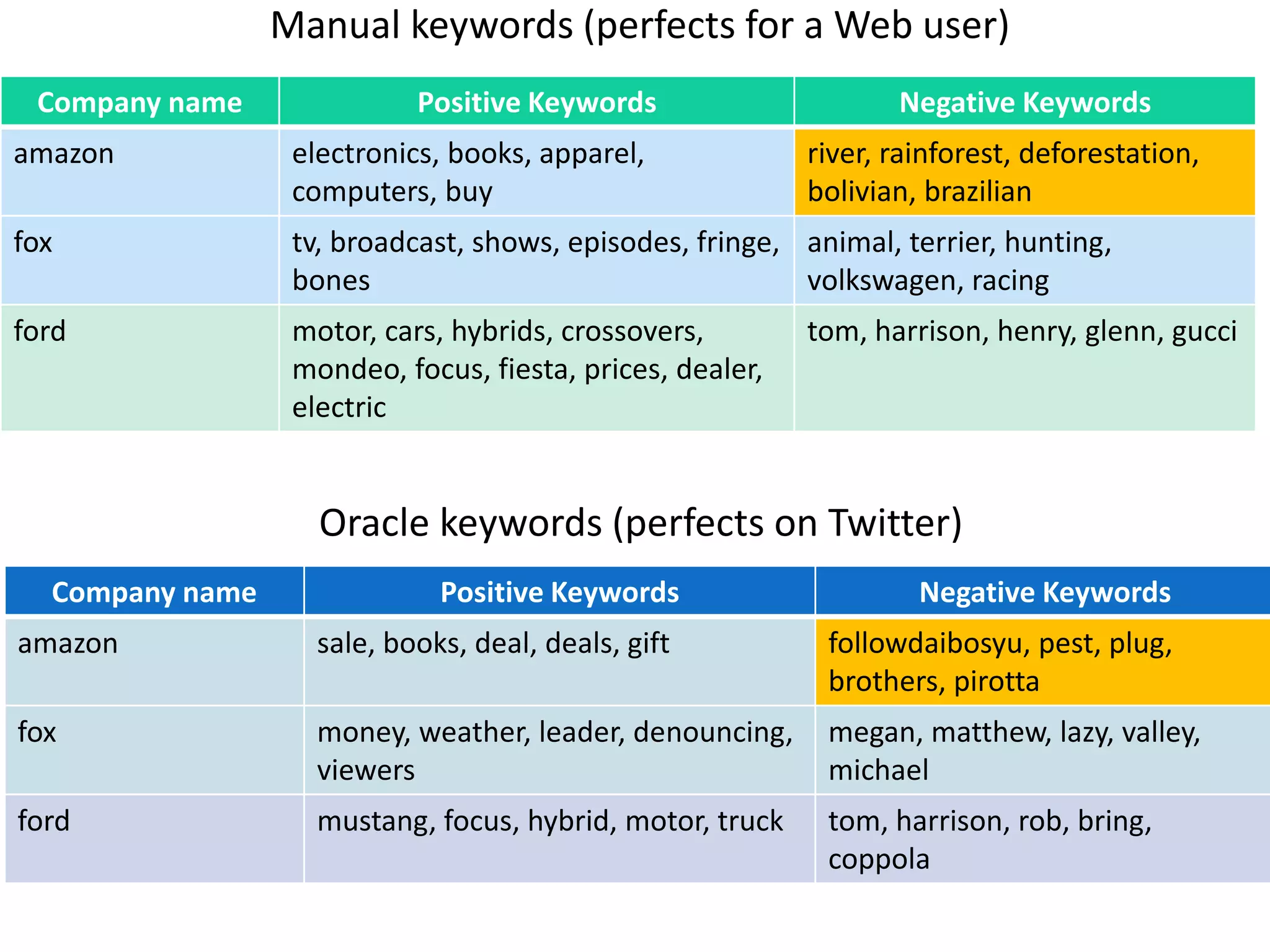
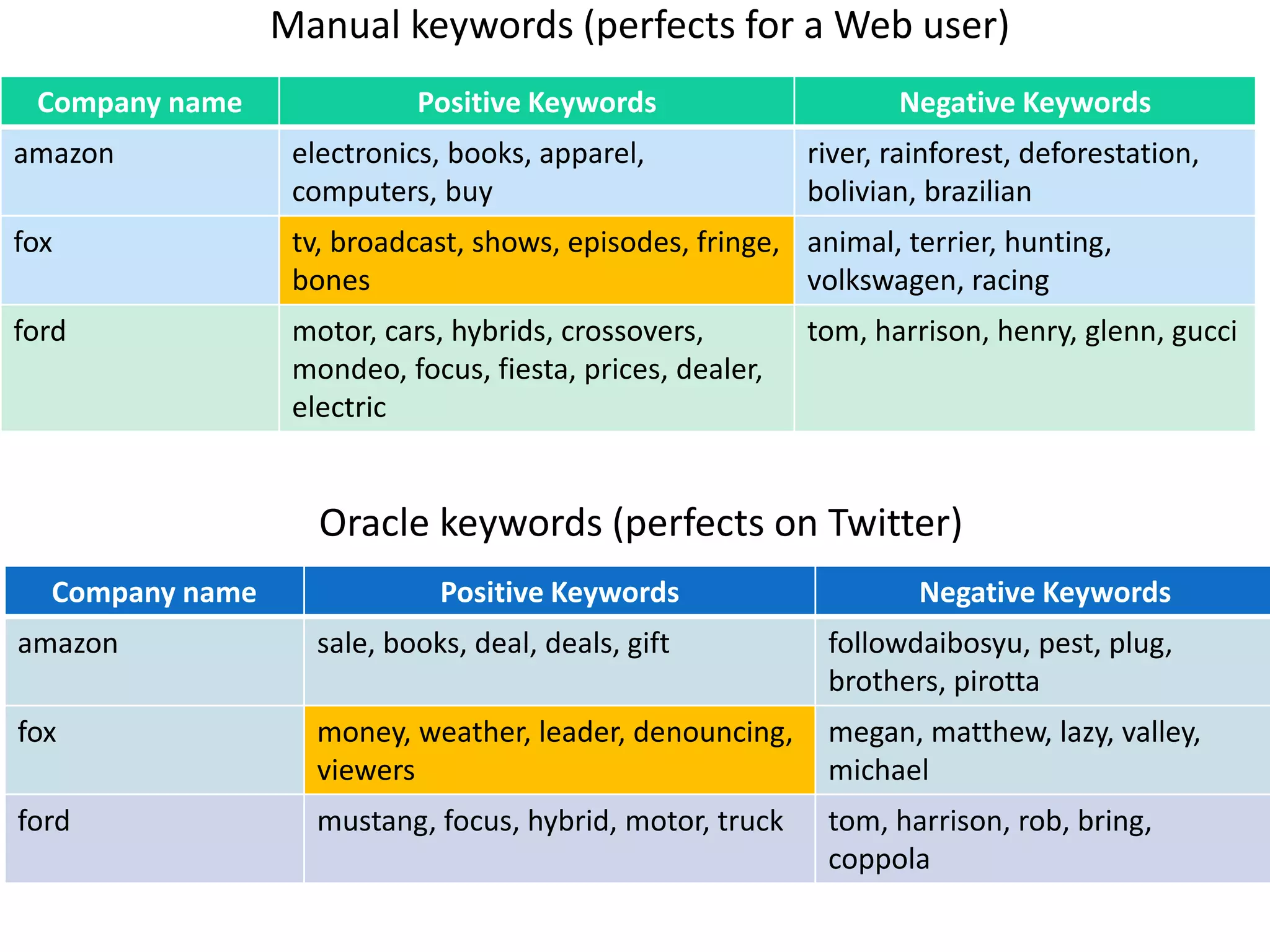
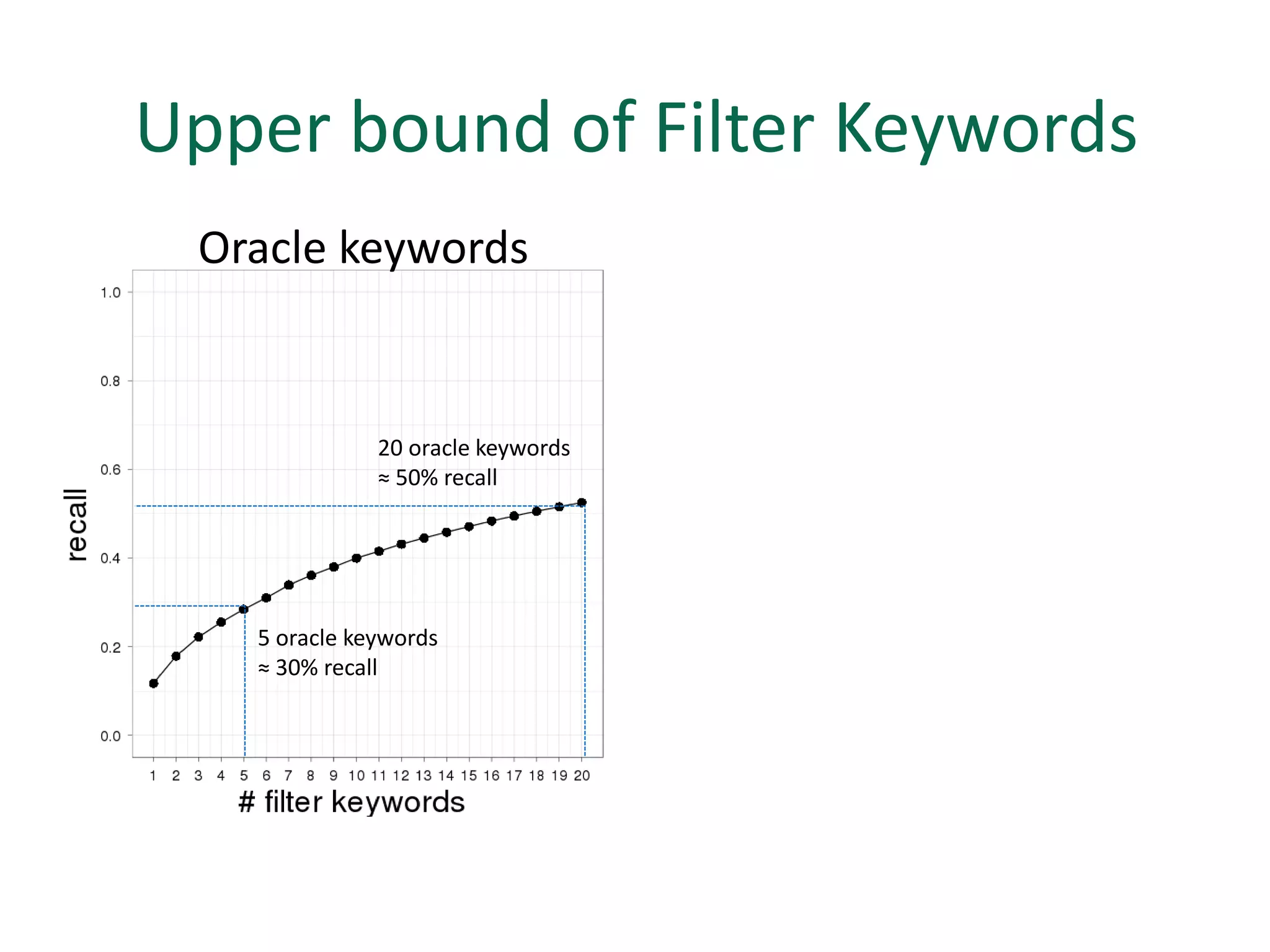
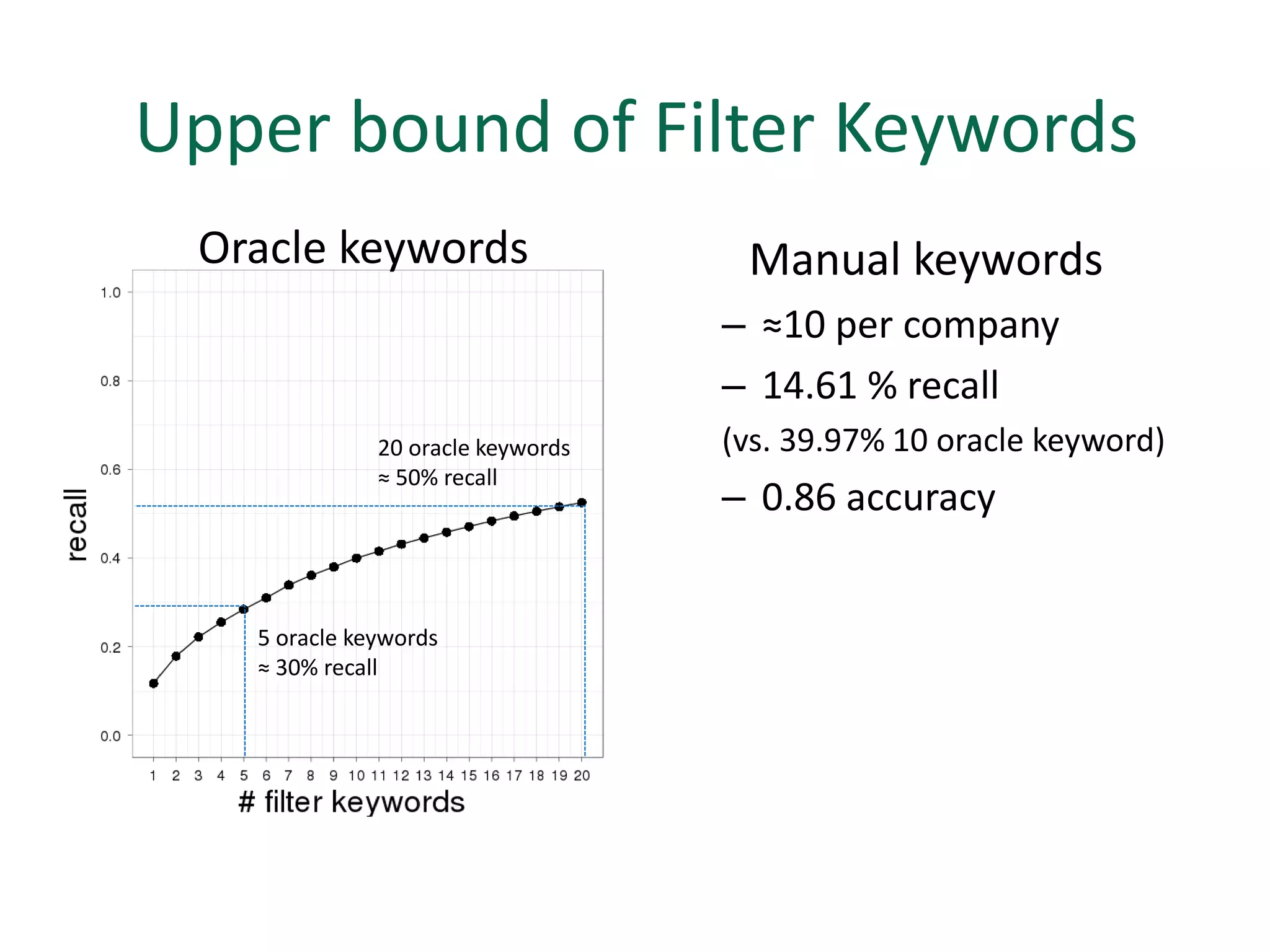


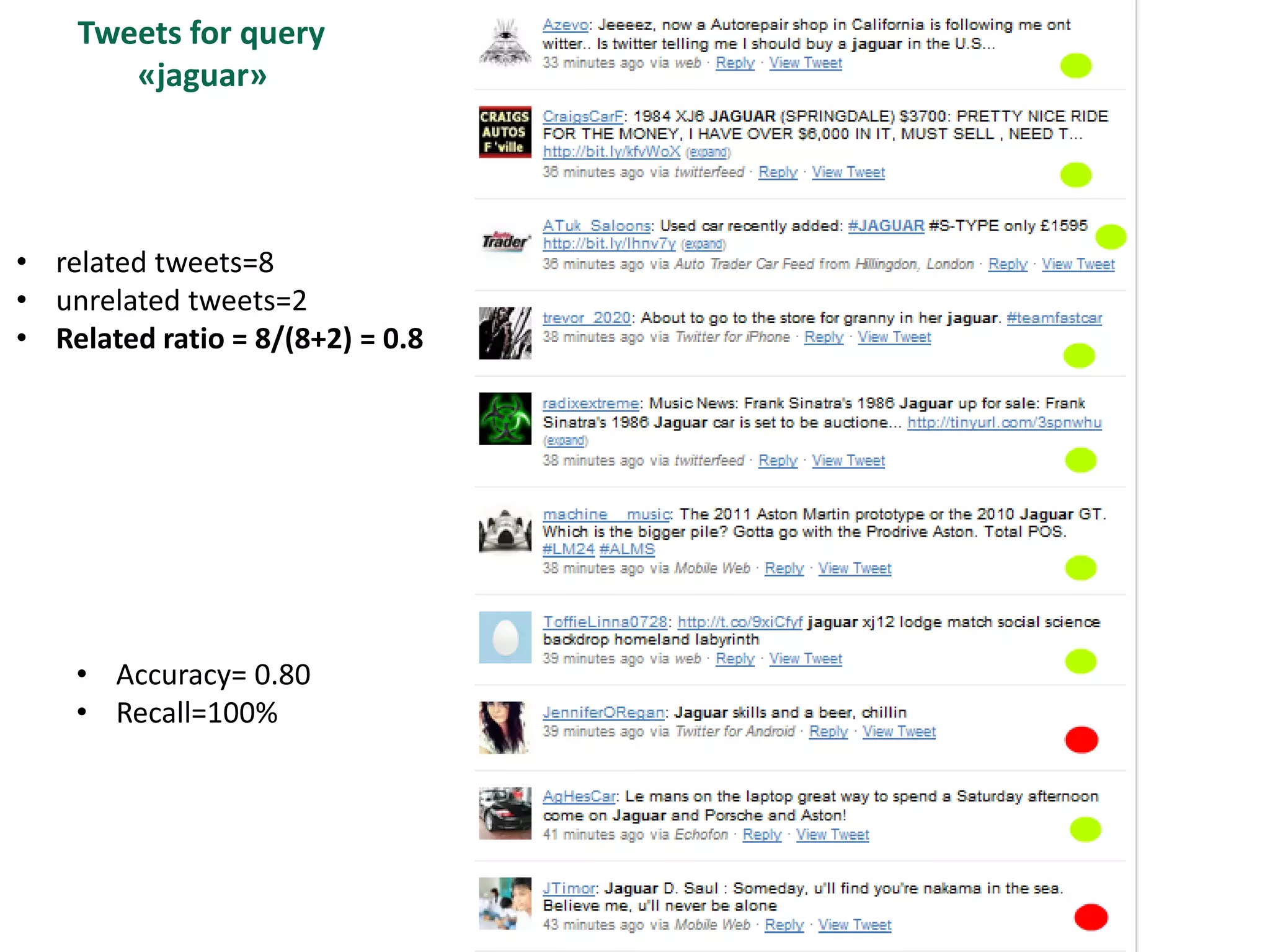
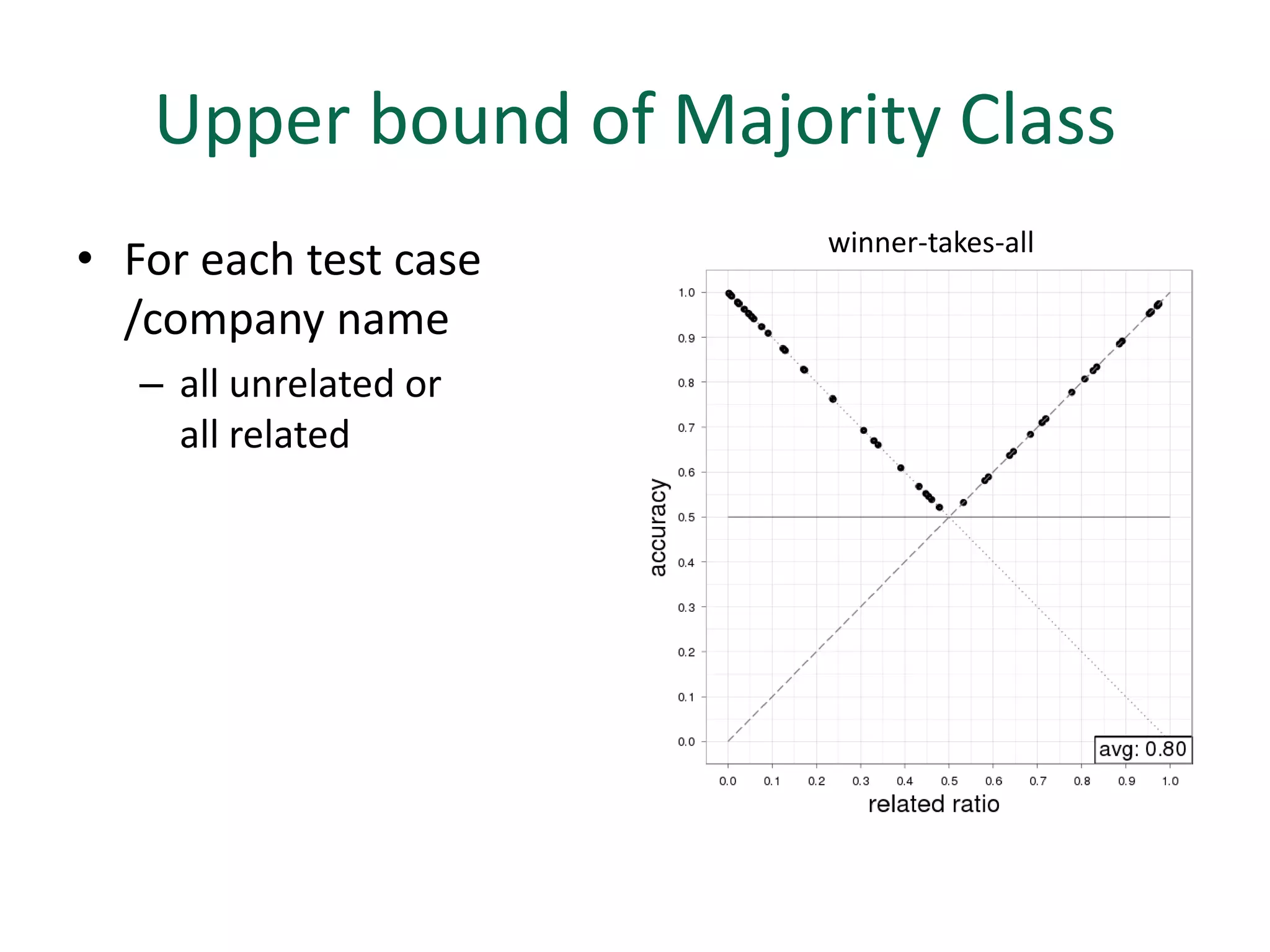
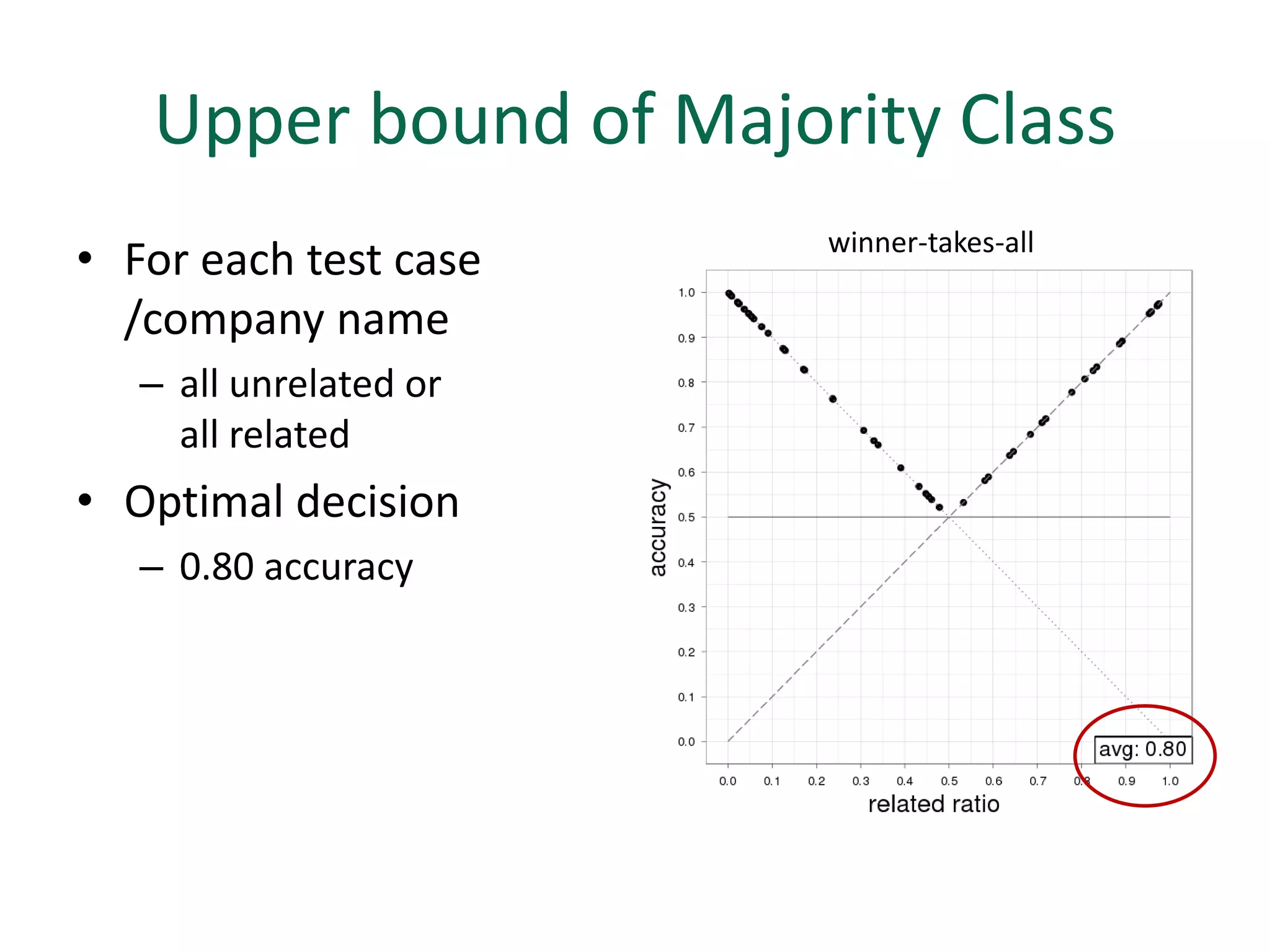
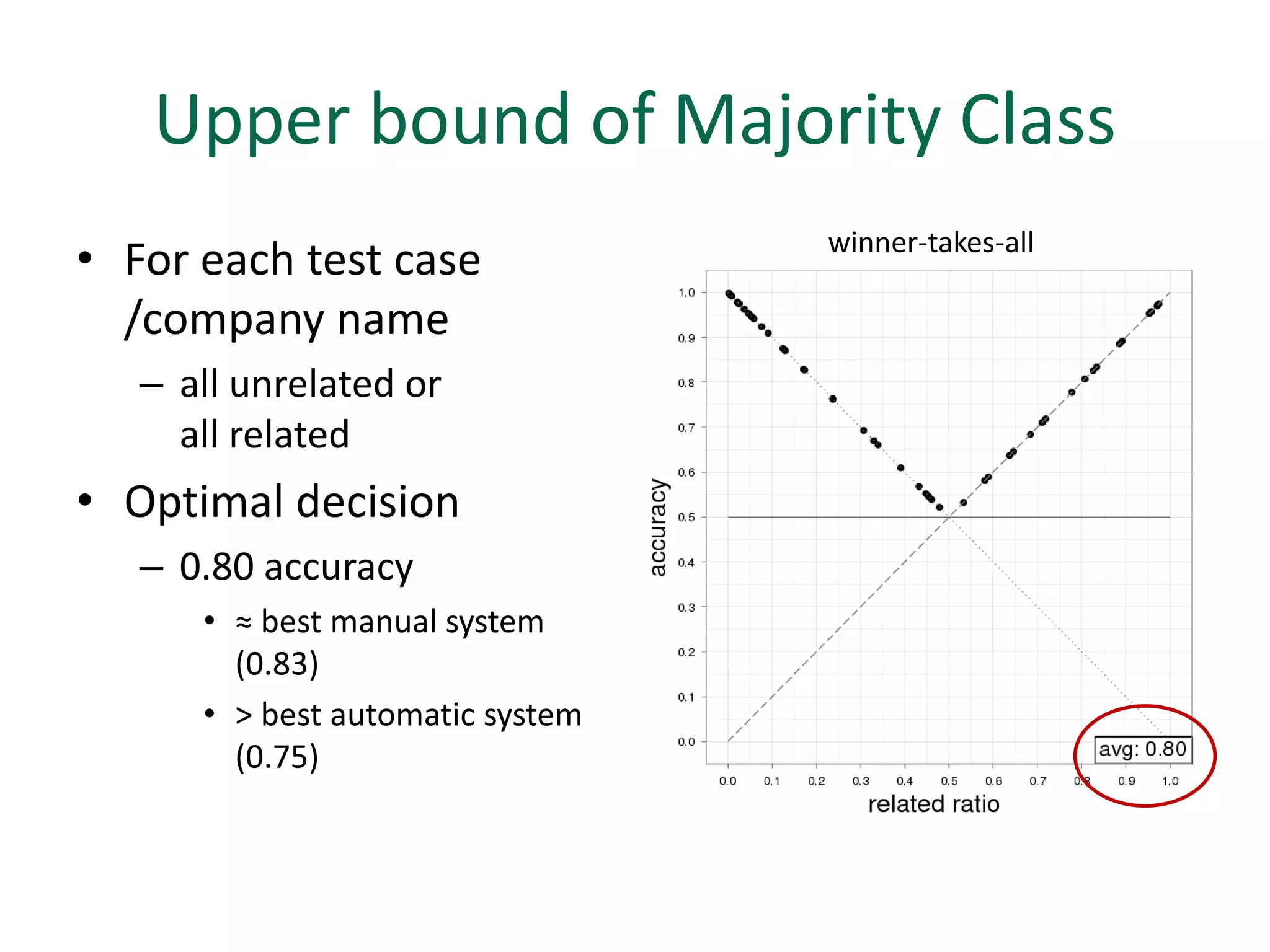
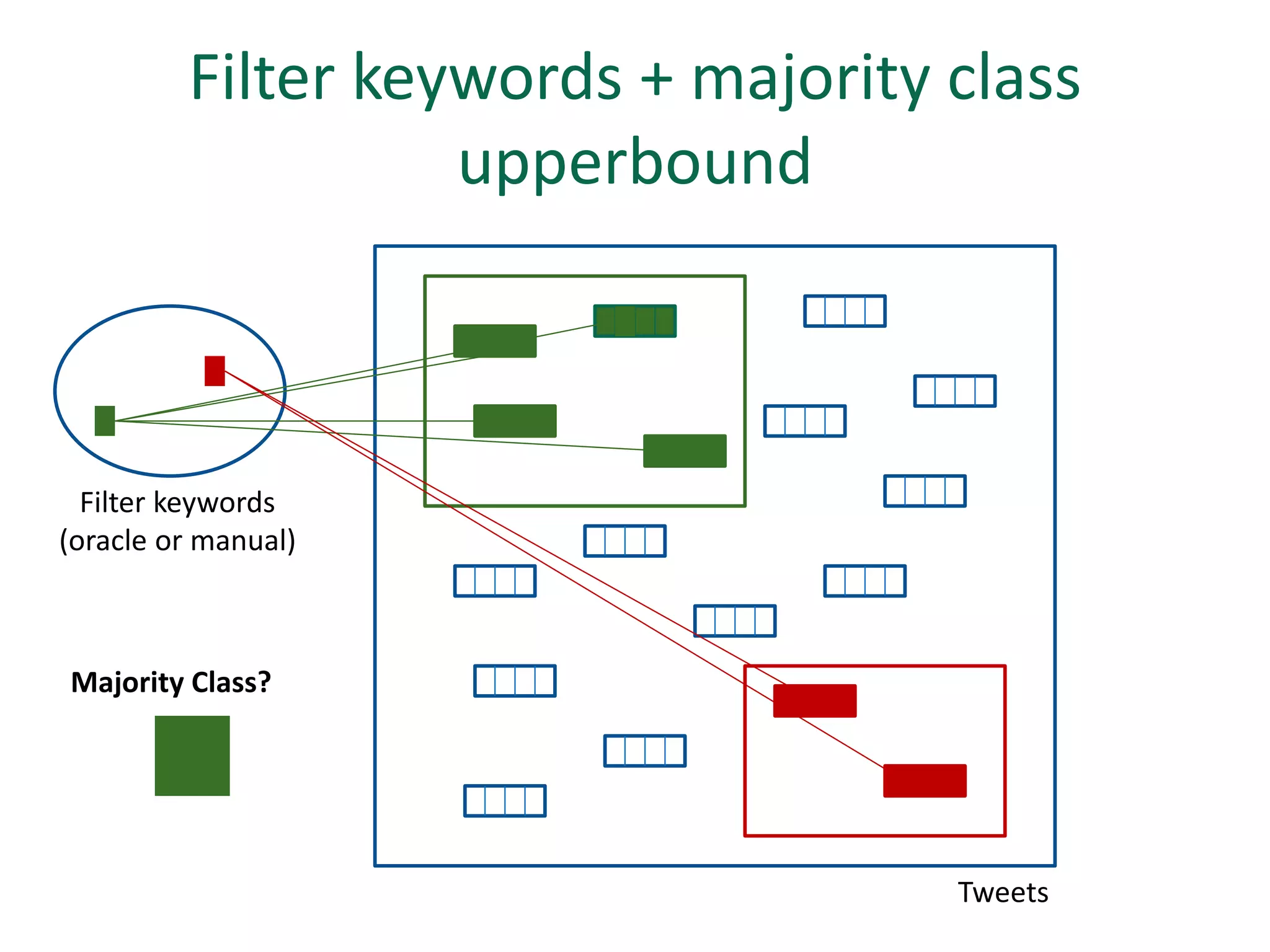
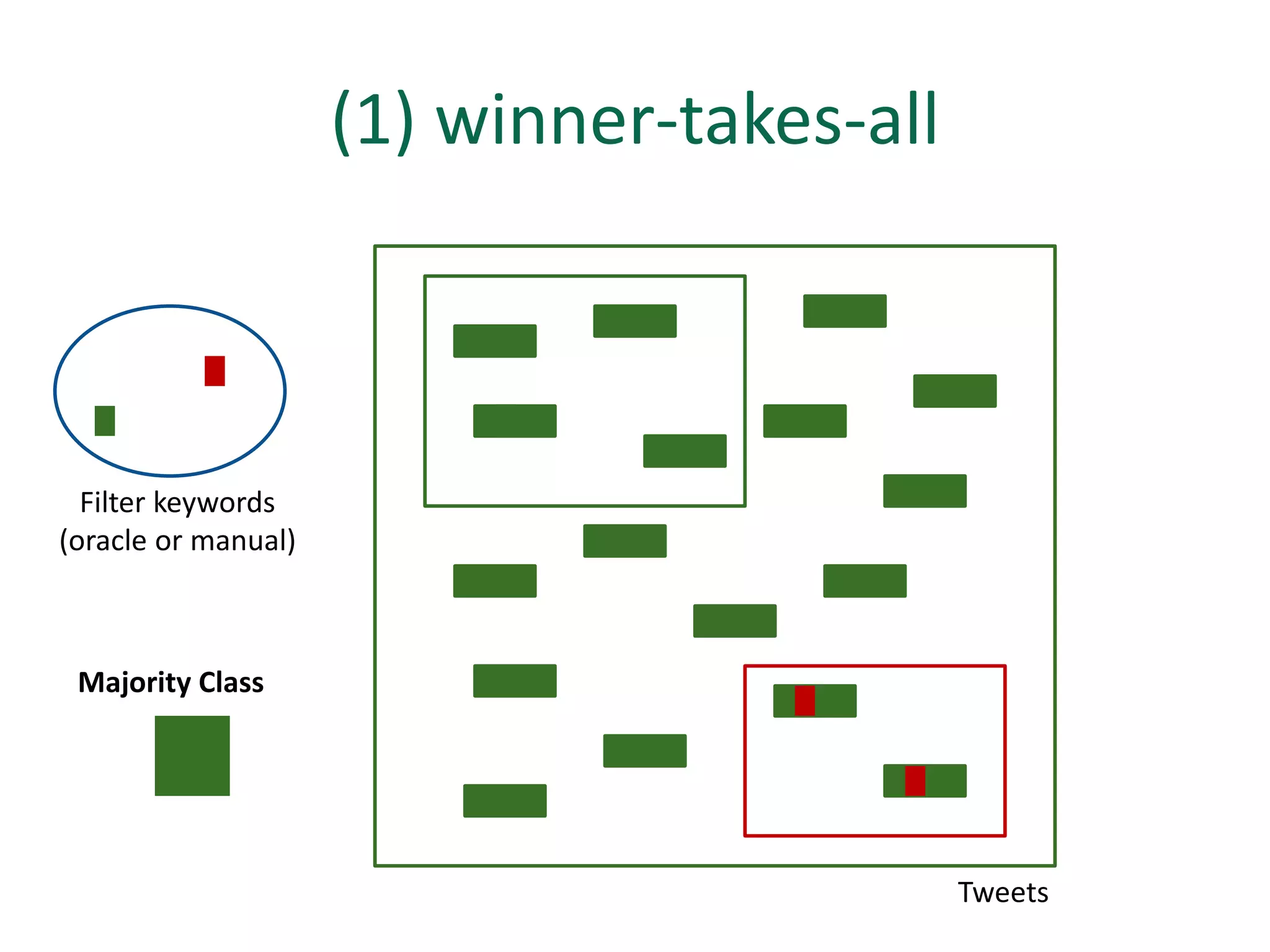
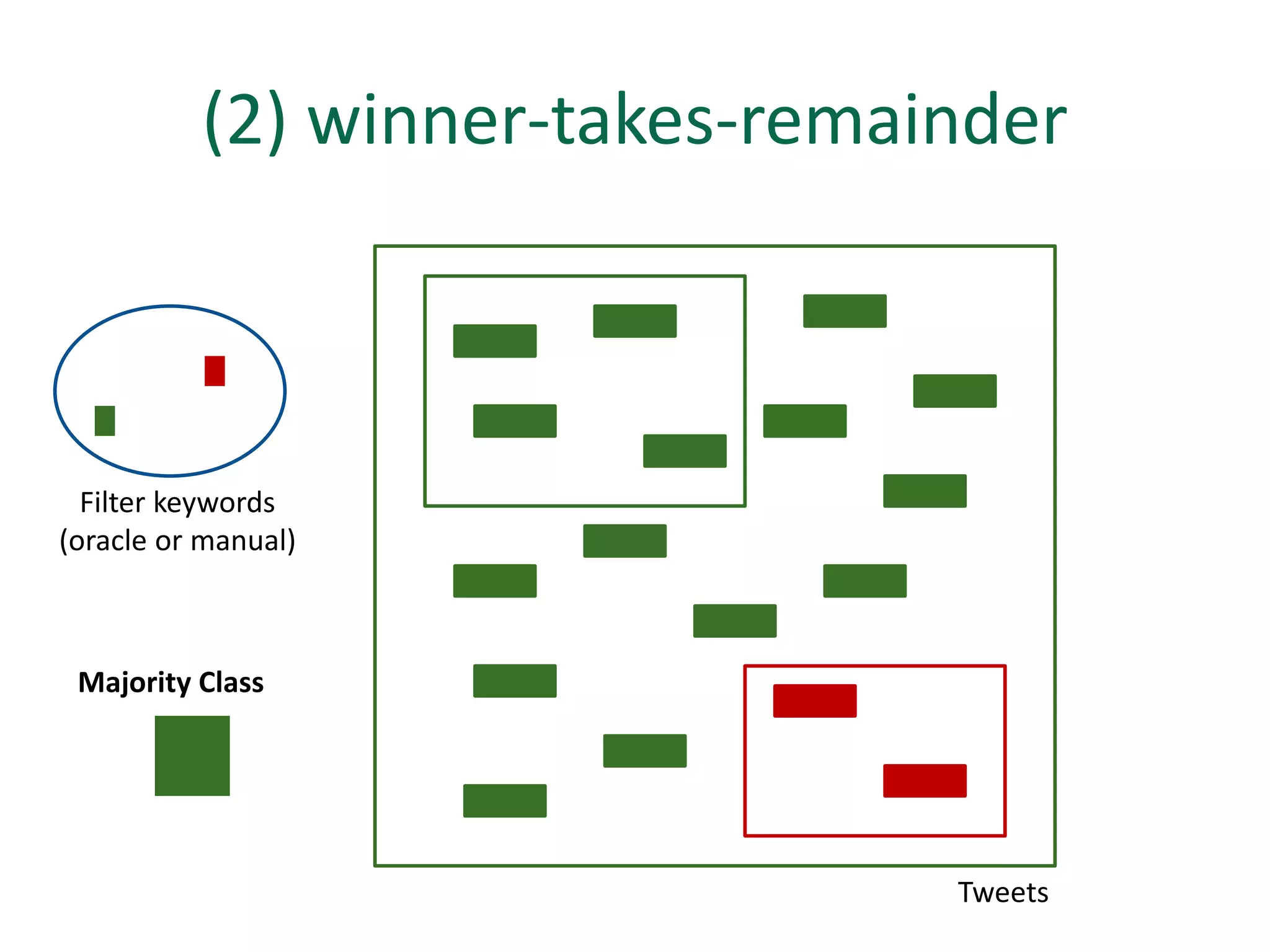
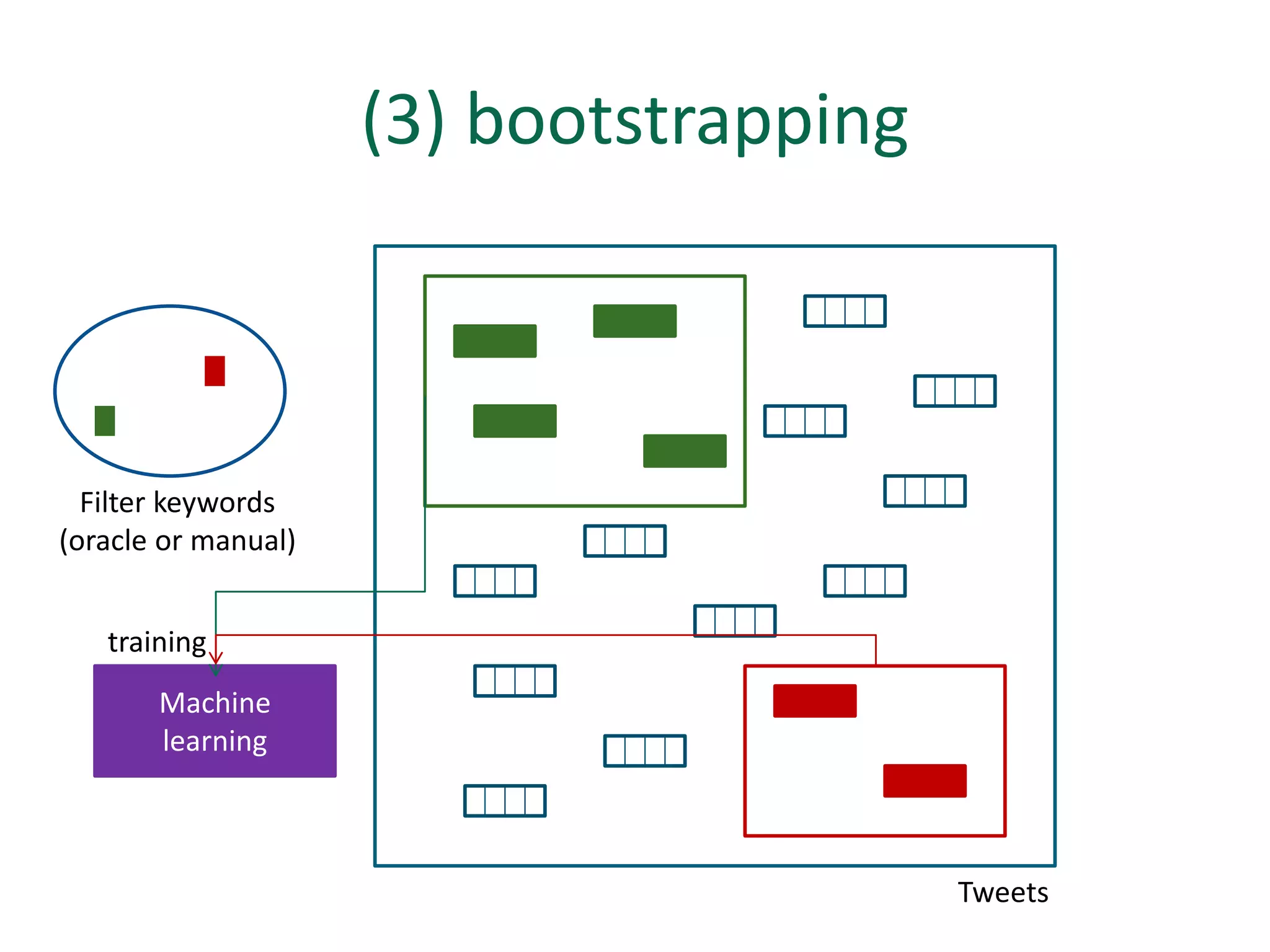
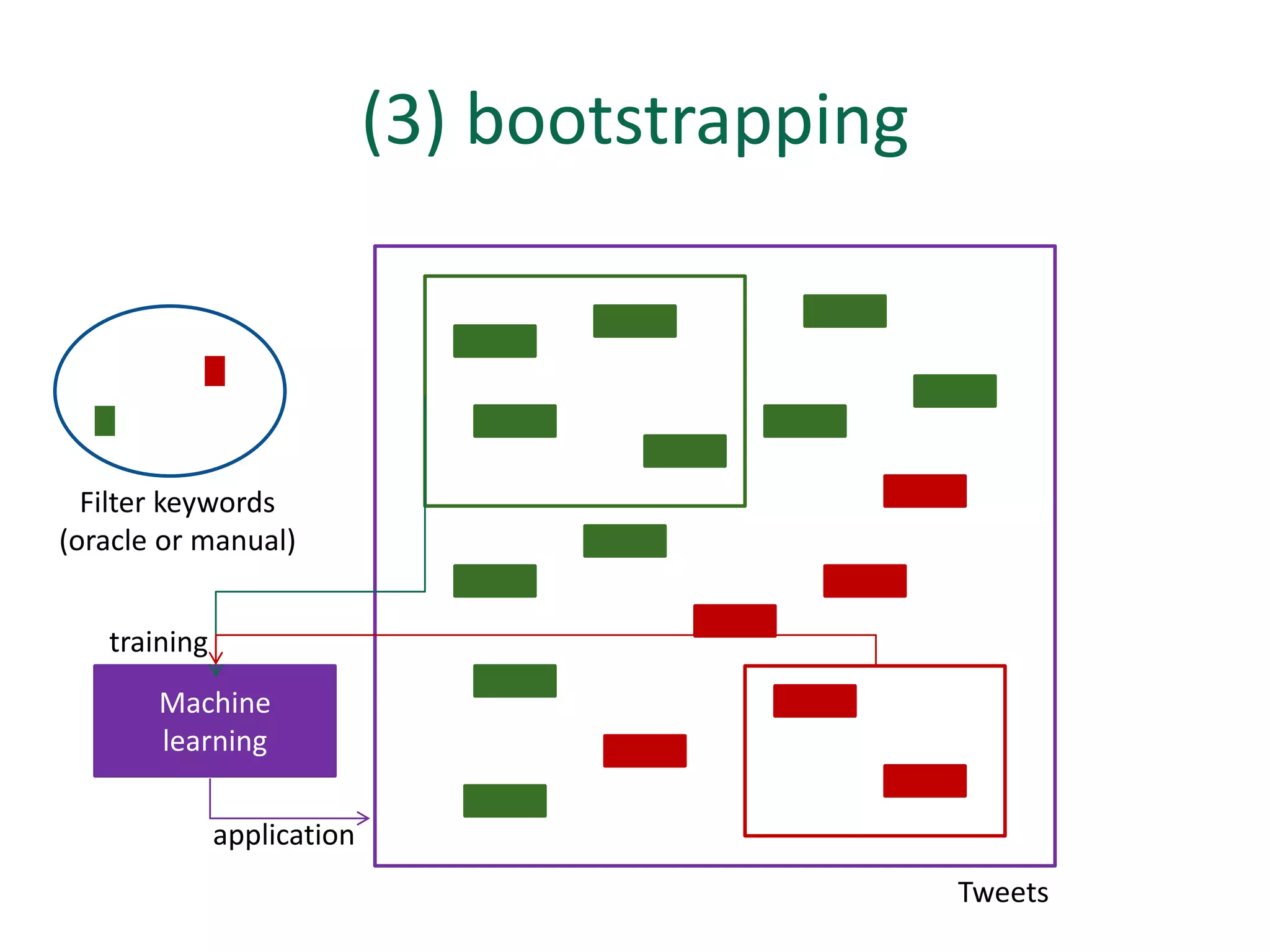
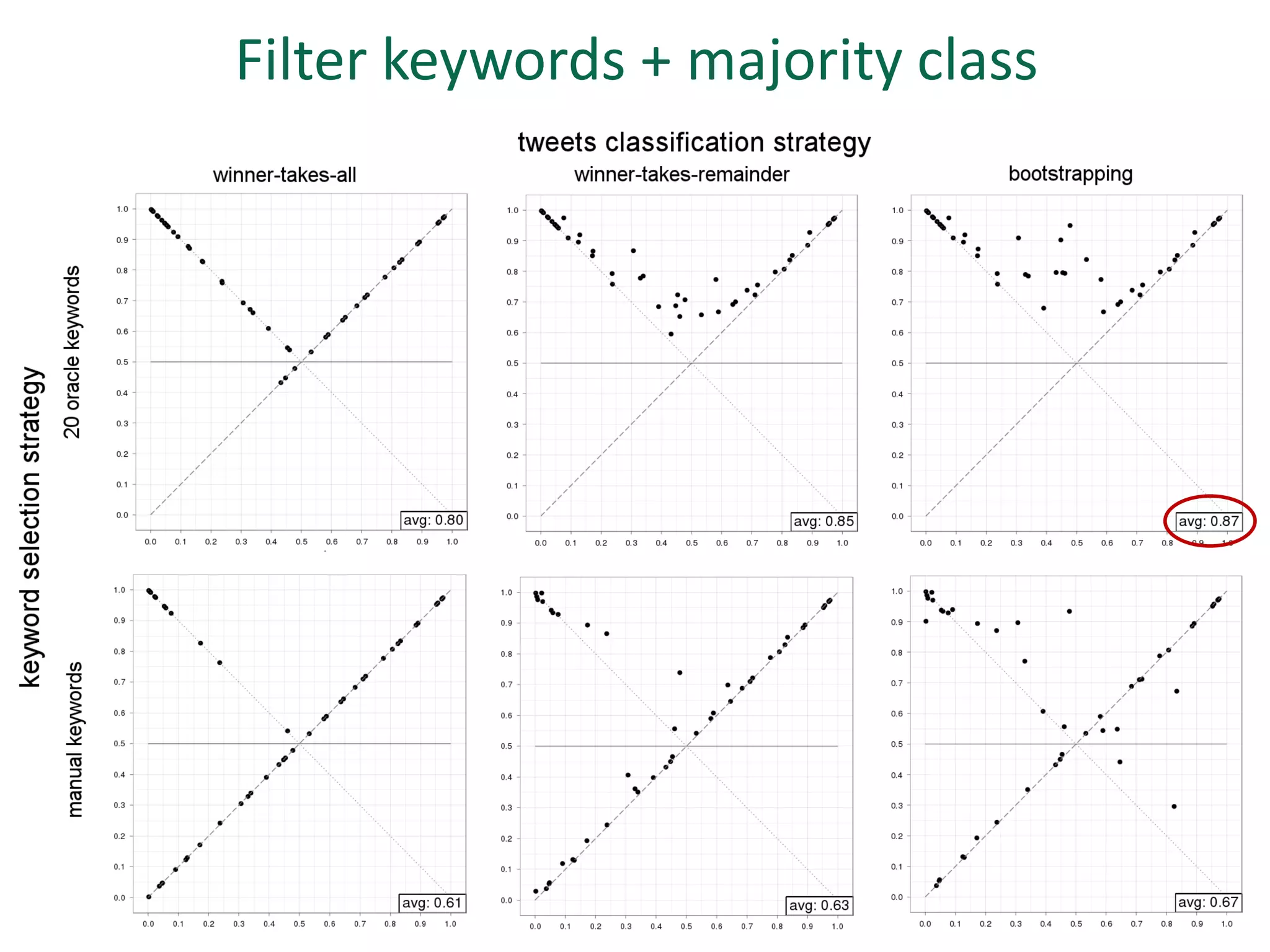
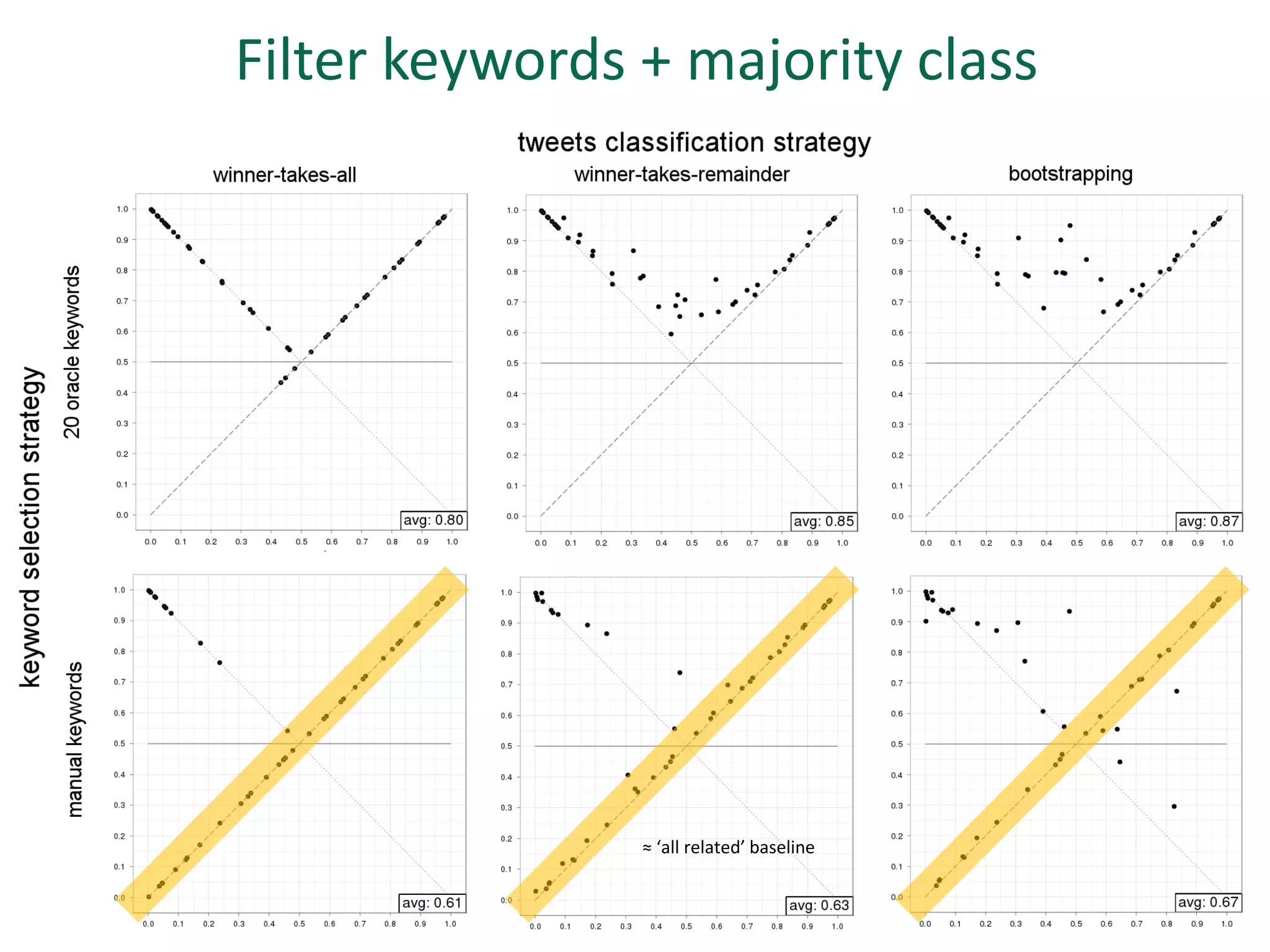

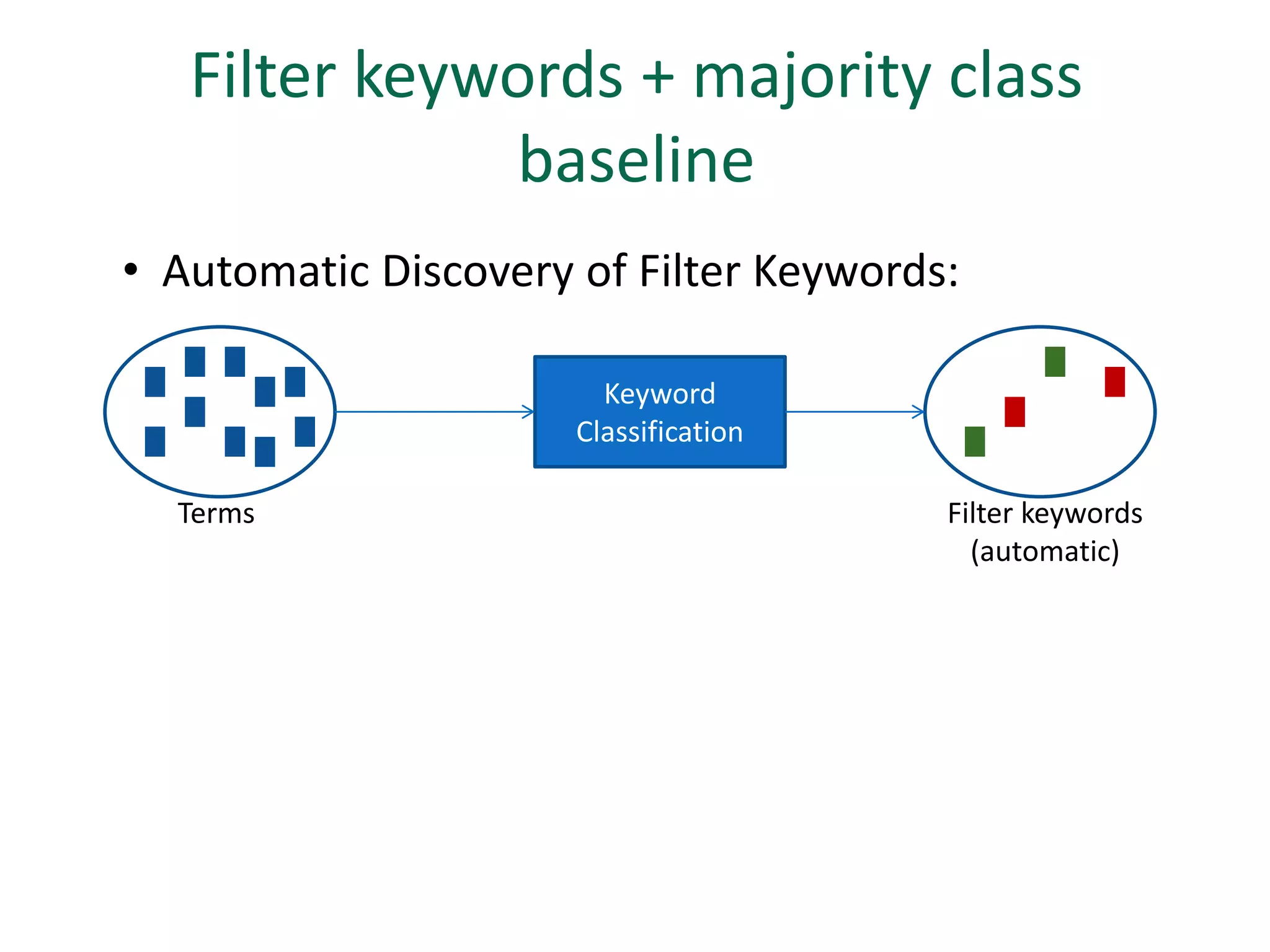
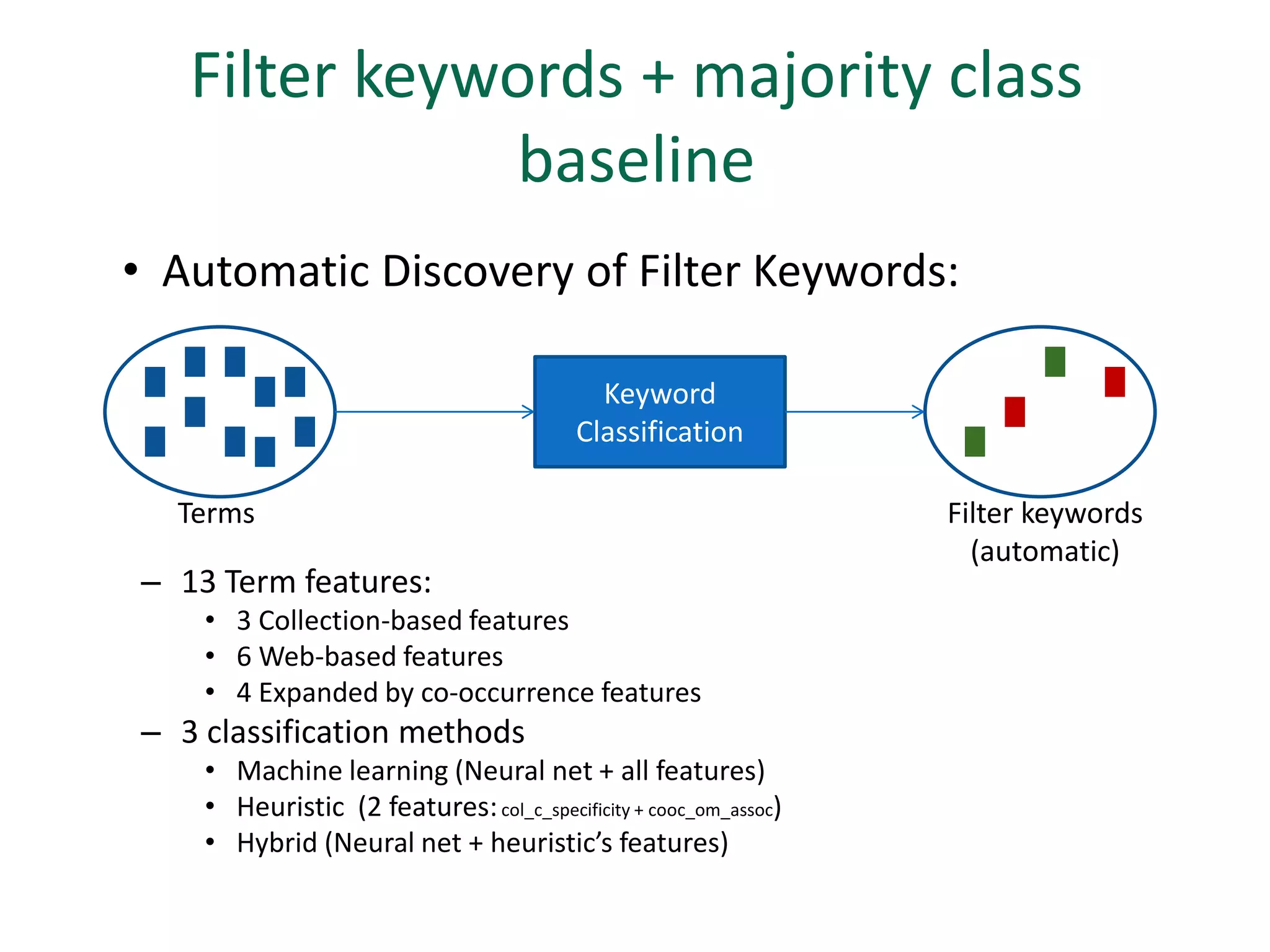
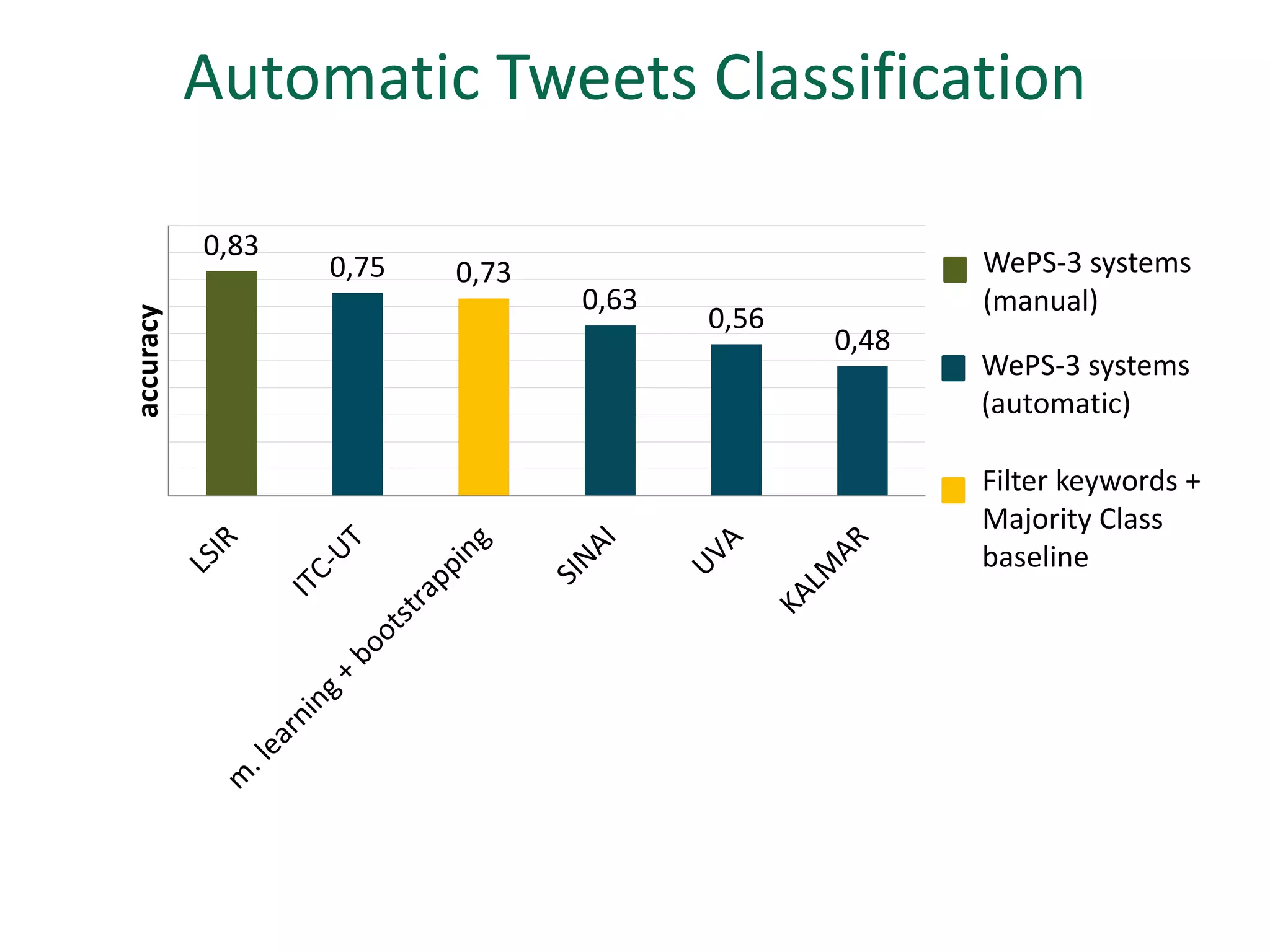





The document discusses strategies for disambiguating company names on Twitter, including using filter keywords and majority class approaches. It finds that using oracle/manual filter keywords can achieve recall of 50% and 30% respectively, outperforming the best automatic system from a previous task. Considering tweets as all related or unrelated based on majority class ratio achieves an optimal accuracy of 80%, comparable to the best manual system. The document proposes automatically discovering filter keywords using term classification and combining it with majority class approaches or machine learning to improve disambiguation.





































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










