Download as PDF, PPTX








![Approach I: Pooling aspects
• Pooling methodology
– 4 Ranking Methods:
• TF.IDF [Salton and Buckley, 1988]
• Log-Likelihood Ratio [Dunning, 1993]
• Parsimonious Language Model [Hiemstra et al. 2004]
• Opinion target extraction using topic-specific subjective
lexicons [Jijkoun et al. 2010]
– Top 10 terms
• Manual annotation](https://image.slidesharecdn.com/spina2012corpus-slides-120528074453-phpapp01/75/A-Corpus-for-Entity-Profiling-in-Microblog-Posts-10-2048.jpg)





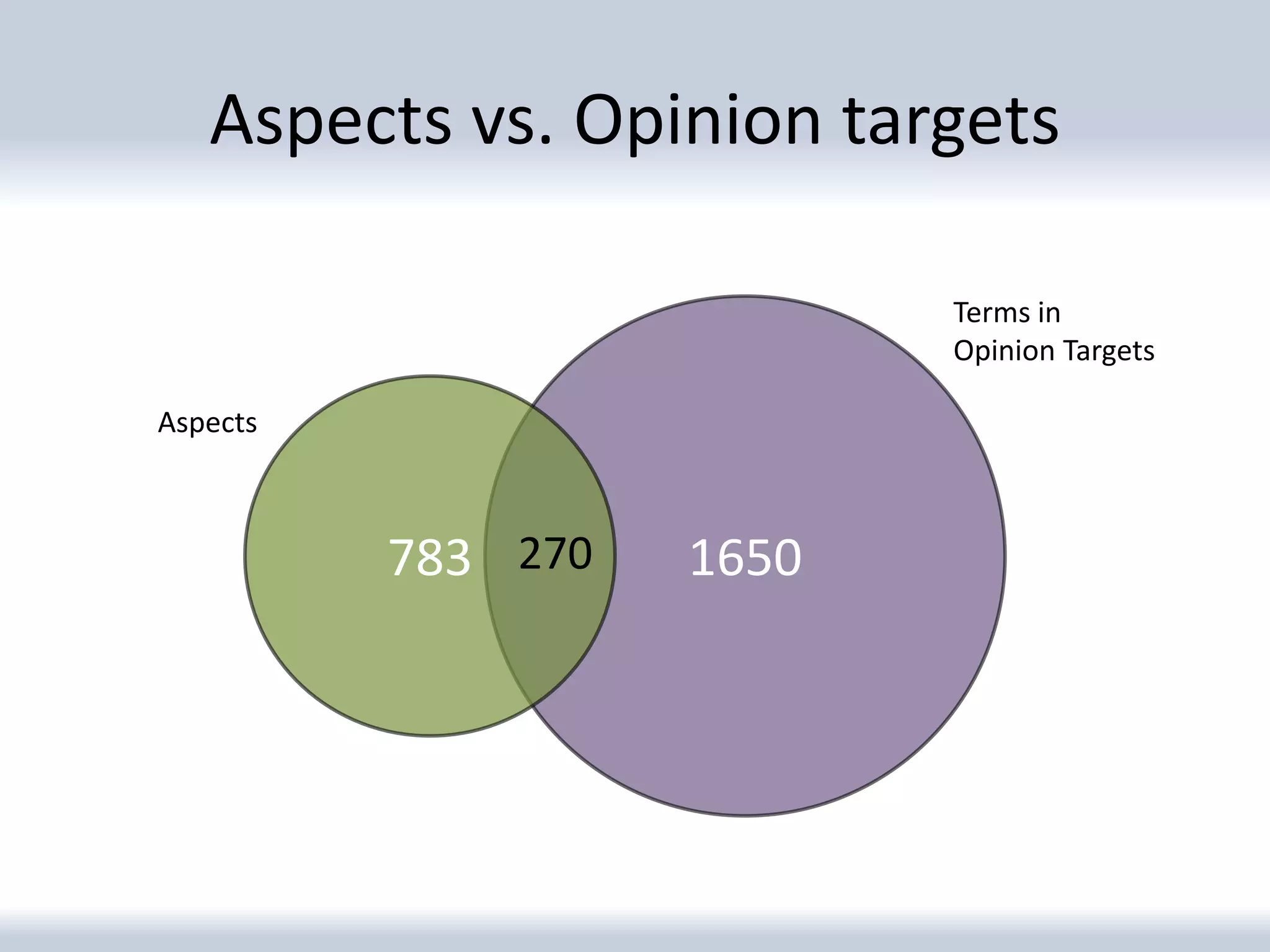
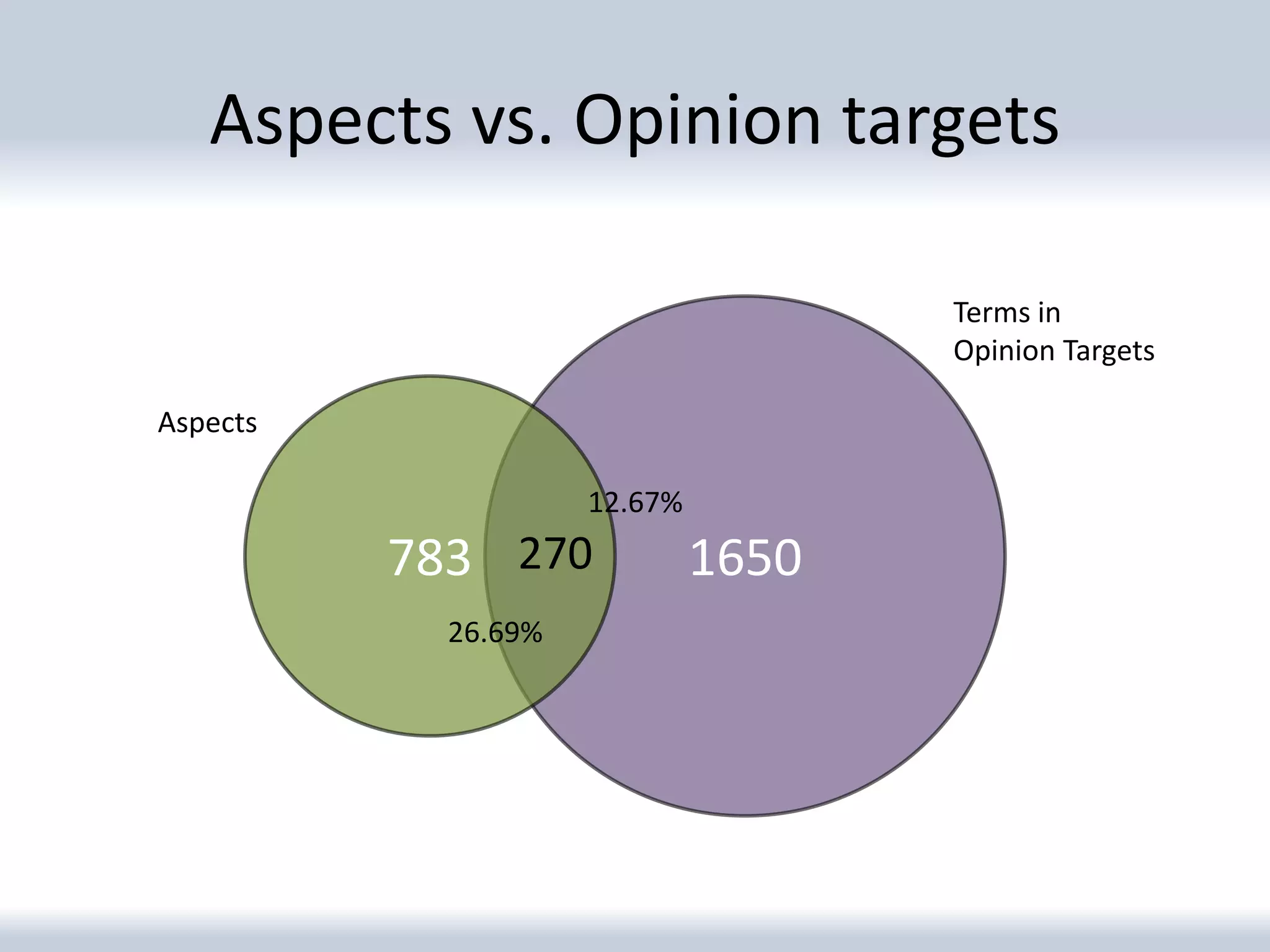


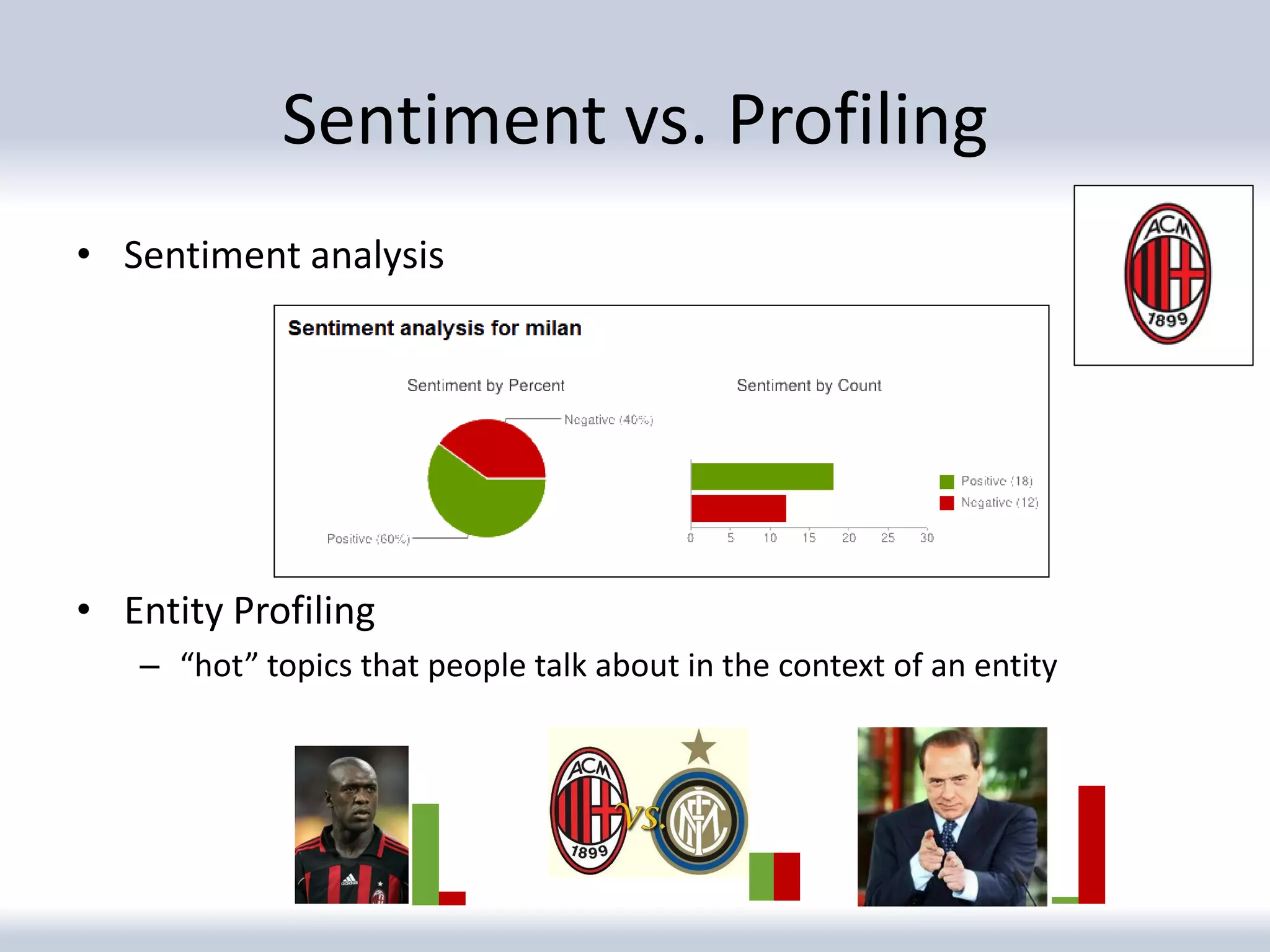
The document discusses a corpus created for entity profiling in microblog posts, focusing on the public image of various entities such as brands and organizations. It outlines the methodology for collecting and annotating tweets, including aspect identification and opinion target extraction from microblogging services. The resulting dataset includes 94 entities with over 17,000 tweets, providing insights into sentiment and topics associated with each entity.













































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






