Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shinichi Tomita
1,283 views
Ext js 20100526
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
クラウドを活かし、強みにするISVの可能性 桑原里恵
by
Sapporo Sparkle k.k.
PDF
TOUA M2M Solutions powered by Cloudian (Cloudian Summit 2012)
by
CLOUDIAN KK
PPTX
レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]
by
Insight Technology, Inc.
PDF
【2018年3月時点】Oracle Data Visualizaion ご紹介
by
オラクルエンジニア通信
PDF
DMBOKをベースにしたデータマネジメント
by
Kent Ishizawa
PDF
Hadoop Conference Japan 2011 Fall: マーケティング向け大規模ログ解析事例紹介
by
Kenji Hara
PDF
Oracle Analytics Cloud のご紹介【2021年3月版】
by
オラクルエンジニア通信
PDF
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
クラウドを活かし、強みにするISVの可能性 桑原里恵
by
Sapporo Sparkle k.k.
TOUA M2M Solutions powered by Cloudian (Cloudian Summit 2012)
by
CLOUDIAN KK
レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]
by
Insight Technology, Inc.
【2018年3月時点】Oracle Data Visualizaion ご紹介
by
オラクルエンジニア通信
DMBOKをベースにしたデータマネジメント
by
Kent Ishizawa
Hadoop Conference Japan 2011 Fall: マーケティング向け大規模ログ解析事例紹介
by
Kenji Hara
Oracle Analytics Cloud のご紹介【2021年3月版】
by
オラクルエンジニア通信
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
Similar to Ext js 20100526
PDF
C14_ひとつのdbでは夢を現実に変えられない!Human Dreams.Make IT Real by 石川太一
by
Insight Technology, Inc.
PDF
Net advantage 2012 volume2 最新情報 xaml プラットフォーム編
by
Daizen Ikehara
PDF
Qlik viewご紹介 v1.0
by
Yusuke-Ishii
PDF
第4回SIA研究会(例会)プレゼン資料1_ m2 soft 紹介資料
by
Tae Yoshida
PDF
ビッグデータ
by
Shigeru Kishikawa
PDF
IAチャンネル:自社サイト最適化講座 vol.1
by
Makoto Shimizu
PDF
ERPのデータをフロントシステムでどう活かすか
by
Ryuji Enoki
PDF
As-Isシステムをマクロなソース解析によって見える化しよう
by
Kent Ishizawa
PDF
Converting big data into big value
by
Yoshiyuki Ueda
PDF
ビジネスモデリングによる問題解決型アプローチ
by
Kent Ishizawa
PDF
市場動向並びに弊社製品の今後の展望について
by
Ken Azuma
PPTX
市場動向並びに弊社製品の今後の展望について
by
Ken Azuma
PDF
デブサミ2013 【15-E-1】 「DevPower: デベロッパーが創る日本の未来を語ろう」林氏分
by
Developers Summit
PDF
第3回SIA研究会(例会)プレゼン資料
by
Tae Yoshida
PDF
E-commerce企業におけるビッグデータへの挑戦と課題‐機械学習への期待について‐
by
Rakuten Group, Inc.
PDF
【ソフトウェアプロジェクトにおけるツールの活用を考える会】 ソフトウェア開発におけるツール活用 - Team Foundation Server をベース...
by
智治 長沢
PDF
Riaアーキテクチャー研究会 第3回 セッション3
by
Mami Shiino
PDF
About 4D 2013-01-15
by
kmiyako
PDF
AD-MAC (Marketing Consolidation Service)
by
Digital Intelligence Inc.
PDF
Mobile groundswell
by
Takashi Ohmoto
C14_ひとつのdbでは夢を現実に変えられない!Human Dreams.Make IT Real by 石川太一
by
Insight Technology, Inc.
Net advantage 2012 volume2 最新情報 xaml プラットフォーム編
by
Daizen Ikehara
Qlik viewご紹介 v1.0
by
Yusuke-Ishii
第4回SIA研究会(例会)プレゼン資料1_ m2 soft 紹介資料
by
Tae Yoshida
ビッグデータ
by
Shigeru Kishikawa
IAチャンネル:自社サイト最適化講座 vol.1
by
Makoto Shimizu
ERPのデータをフロントシステムでどう活かすか
by
Ryuji Enoki
As-Isシステムをマクロなソース解析によって見える化しよう
by
Kent Ishizawa
Converting big data into big value
by
Yoshiyuki Ueda
ビジネスモデリングによる問題解決型アプローチ
by
Kent Ishizawa
市場動向並びに弊社製品の今後の展望について
by
Ken Azuma
市場動向並びに弊社製品の今後の展望について
by
Ken Azuma
デブサミ2013 【15-E-1】 「DevPower: デベロッパーが創る日本の未来を語ろう」林氏分
by
Developers Summit
第3回SIA研究会(例会)プレゼン資料
by
Tae Yoshida
E-commerce企業におけるビッグデータへの挑戦と課題‐機械学習への期待について‐
by
Rakuten Group, Inc.
【ソフトウェアプロジェクトにおけるツールの活用を考える会】 ソフトウェア開発におけるツール活用 - Team Foundation Server をベース...
by
智治 長沢
Riaアーキテクチャー研究会 第3回 セッション3
by
Mami Shiino
About 4D 2013-01-15
by
kmiyako
AD-MAC (Marketing Consolidation Service)
by
Digital Intelligence Inc.
Mobile groundswell
by
Takashi Ohmoto
More from Shinichi Tomita
PPTX
SalesforceでのモダンSPA開発(Mashmatrix ”Sheet"の場合)
by
Shinichi Tomita
PDF
SalesforceからAWSへの接続 using OIDC/SAML
by
Shinichi Tomita
PDF
Developing SLDS Apps with React.js
by
Shinichi Tomita
PDF
Spring'15 Update - Named Credential & Long Running Callout
by
Shinichi Tomita
PDF
スマートデバイス×HTML5で 企業情報システムはどう変わる? ~最新動向から考えるエンタープライズWebの現在と未来~
by
Shinichi Tomita
PDF
Summer'14 Update - What's new in Force.com Canvas -
by
Shinichi Tomita
PDF
アイデンティティ2.0とOAuth/OpenID Connect
by
Shinichi Tomita
PDF
モバイルBaaSの概観と最新動向(2014版)
by
Shinichi Tomita
PDF
シングルサインオンの歴史とSAMLへの道のり
by
Shinichi Tomita
PDF
Salesforce1最速経路
by
Shinichi Tomita
PDF
モバイルBaaSの概観と最新動向 (2013/6/7)
by
Shinichi Tomita
PDF
(M)BaaS and Enterprise Mobile Applications
by
Shinichi Tomita
PDF
モバイルHTML5サイトでの写真アップロードの最適化と業務アプリへの適用
by
Shinichi Tomita
PDF
クラウド・スマートデバイス事例調査報告
by
Shinichi Tomita
PDF
Cloud-to-Intranet messaging by Force.com Streaming API
by
Shinichi Tomita
PDF
Sales Force Episode VI ~ Return of Ajax Toolkit ~
by
Shinichi Tomita
PDF
Intro to JFDG
by
Shinichi Tomita
PDF
Herokuで動かす スクリーンショットサーバ
by
Shinichi Tomita
PDF
Force.com とか @ PaaS祭り
by
Shinichi Tomita
PDF
Streaming API で実現する クラウド ⇔ イントラ連携
by
Shinichi Tomita
SalesforceでのモダンSPA開発(Mashmatrix ”Sheet"の場合)
by
Shinichi Tomita
SalesforceからAWSへの接続 using OIDC/SAML
by
Shinichi Tomita
Developing SLDS Apps with React.js
by
Shinichi Tomita
Spring'15 Update - Named Credential & Long Running Callout
by
Shinichi Tomita
スマートデバイス×HTML5で 企業情報システムはどう変わる? ~最新動向から考えるエンタープライズWebの現在と未来~
by
Shinichi Tomita
Summer'14 Update - What's new in Force.com Canvas -
by
Shinichi Tomita
アイデンティティ2.0とOAuth/OpenID Connect
by
Shinichi Tomita
モバイルBaaSの概観と最新動向(2014版)
by
Shinichi Tomita
シングルサインオンの歴史とSAMLへの道のり
by
Shinichi Tomita
Salesforce1最速経路
by
Shinichi Tomita
モバイルBaaSの概観と最新動向 (2013/6/7)
by
Shinichi Tomita
(M)BaaS and Enterprise Mobile Applications
by
Shinichi Tomita
モバイルHTML5サイトでの写真アップロードの最適化と業務アプリへの適用
by
Shinichi Tomita
クラウド・スマートデバイス事例調査報告
by
Shinichi Tomita
Cloud-to-Intranet messaging by Force.com Streaming API
by
Shinichi Tomita
Sales Force Episode VI ~ Return of Ajax Toolkit ~
by
Shinichi Tomita
Intro to JFDG
by
Shinichi Tomita
Herokuで動かす スクリーンショットサーバ
by
Shinichi Tomita
Force.com とか @ PaaS祭り
by
Shinichi Tomita
Streaming API で実現する クラウド ⇔ イントラ連携
by
Shinichi Tomita
Ext js 20100526
1.
事例で学ぶ Ext JSとクラウドのマッシュアップ
Shinichi Tomita stomita@mashmatrix.com twitter.com/stomita
2.
アジェンダ •
「mashmatrix Dashboard」のご紹介 • エンタープライズでの事例・ユースケースなど • 内部アーキテクチャ 2 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
3.
Mashmatrix Dashboard ご紹介
3 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
4.
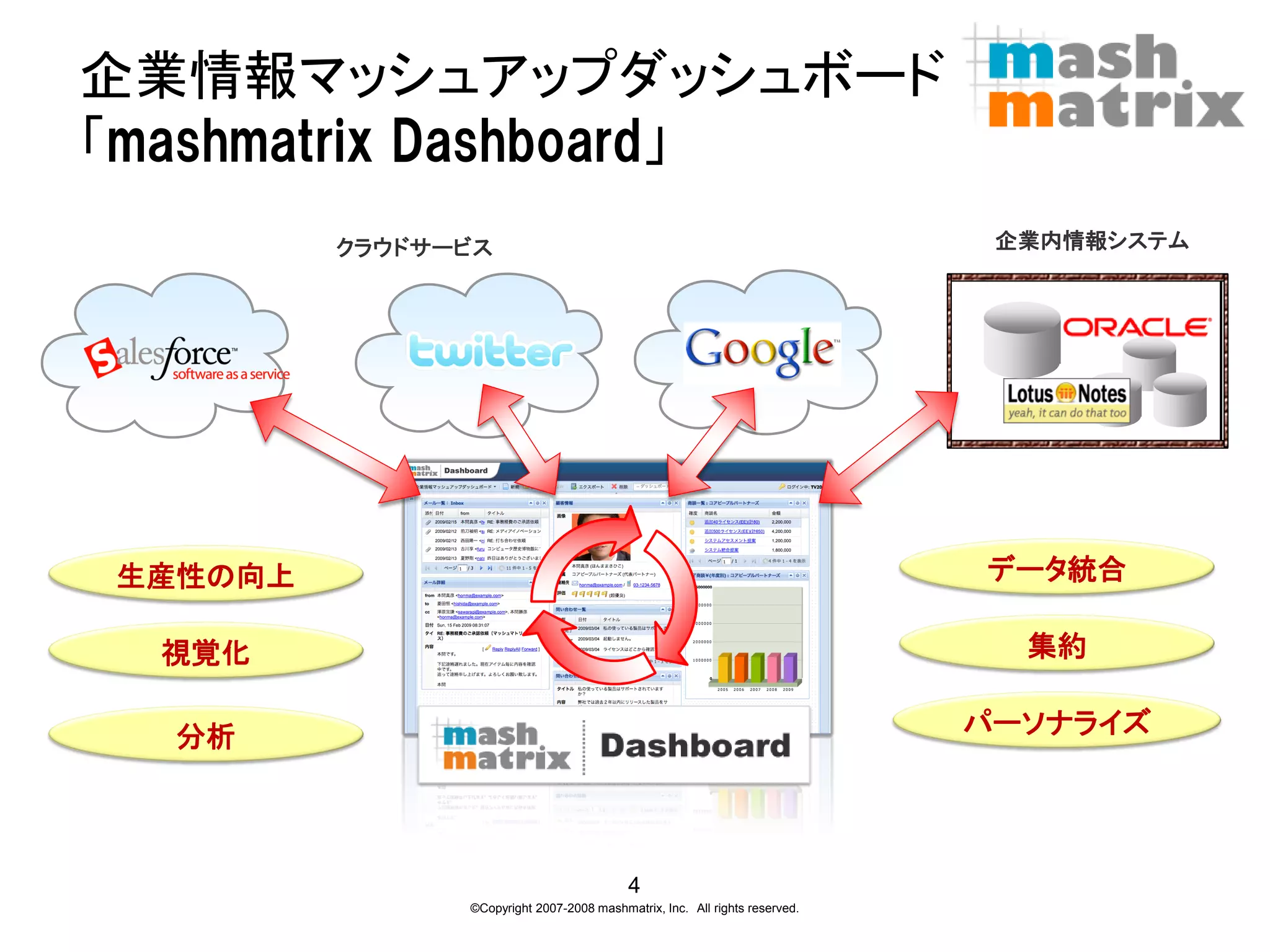
企業情報マッシュアップダッシュボード 「mashmatrix Dashboard」
クラウドサービス 企業内情報システム 生産性の向上 データ統合 視覚化 集約 分析 パーソナライズ 4 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
5.
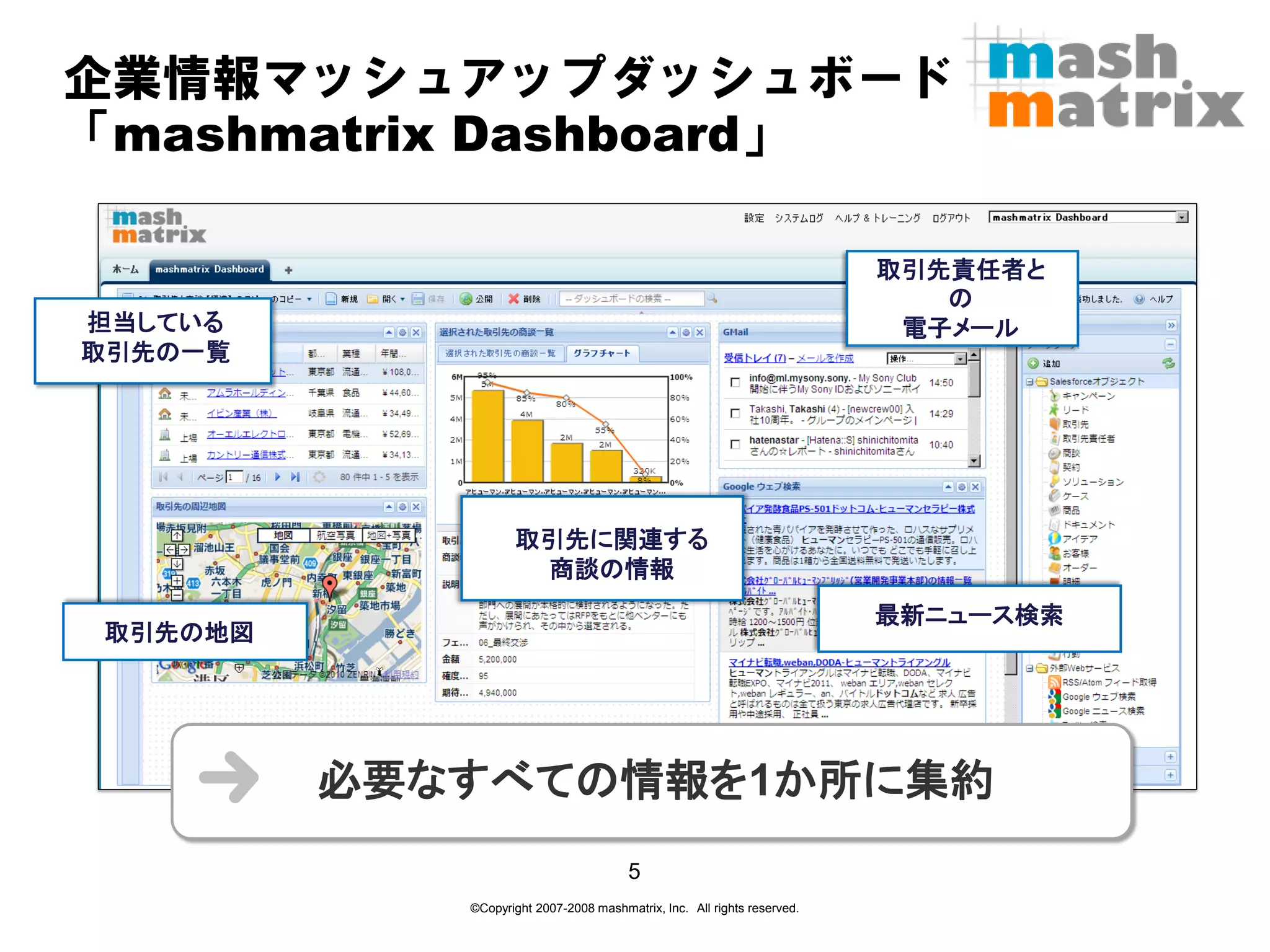
企業情報マッシュアップダッシュボード 「mashmatrix Dashboard」
取引先責任者と の 担当している 電子メール 取引先の一覧 取引先に関連する 商談の情報 最新ニュース検索 取引先の地図 必要なすべての情報を1か所に集約 5 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
6.
快適な操作感と柔軟なカスタマイズ性 ダイナミックなーコンポーネント連動
マウスクリックなどのイベントに応じて、ダッシュボード内の表示を切り替えたり、 データを関連付けておいて自動的に表示を更新させることができるため、 グラフからドリルダウンで詳細を分析、といったことも簡単に実現できます インタラクティブなデータ閲覧設定 表示選択 絞り込み 集計 並べ替え マウス操作で表示したいデータ、検索条件、集計条件、ソートなどを指定 可能。 6 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
7.
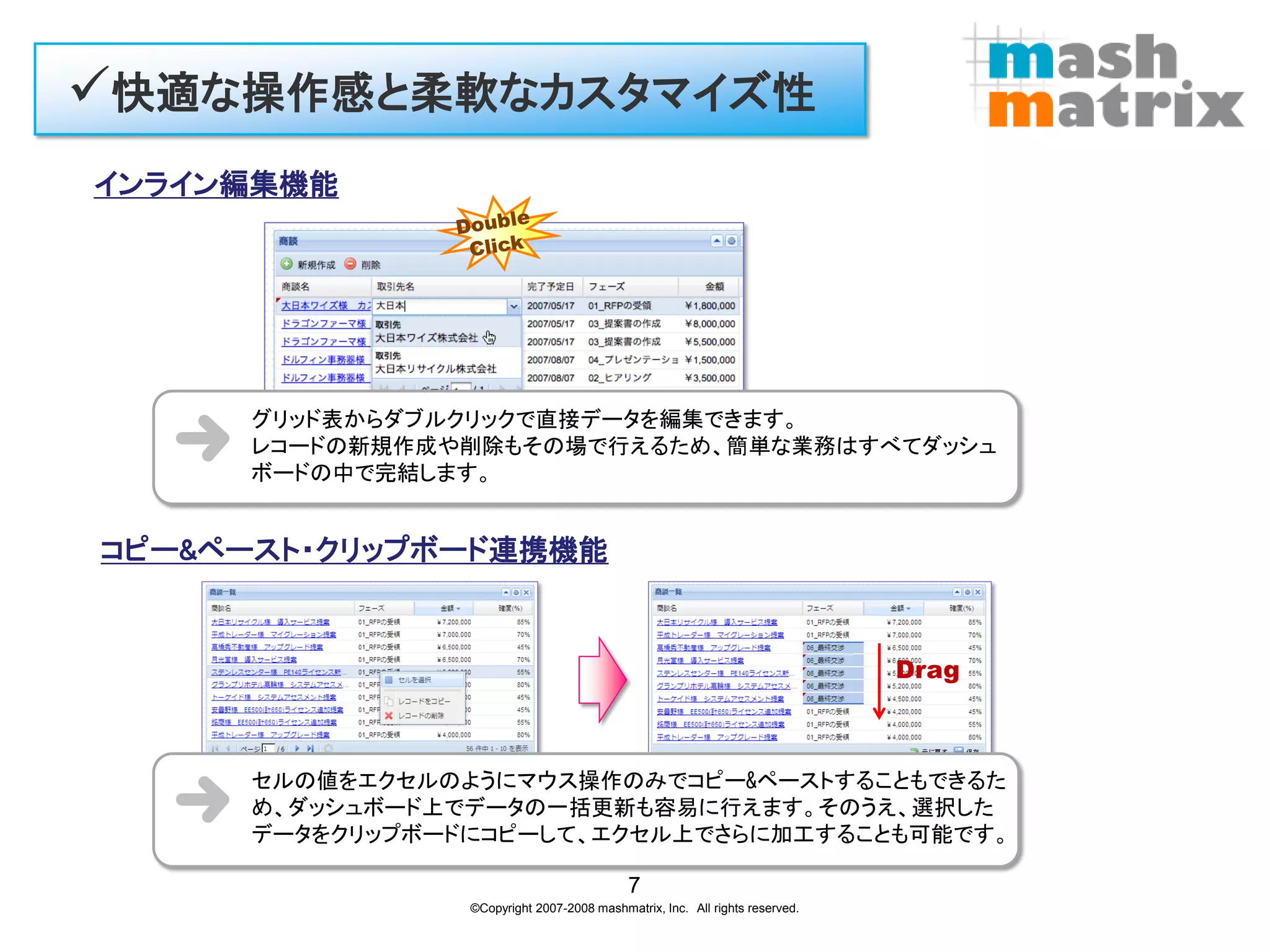
快適な操作感と柔軟なカスタマイズ性 インライン編集機能
グリッド表からダブルクリックで直接データを編集できます。 レコードの新規作成や削除もその場で行えるため、簡単な業務はすべてダッシュ ボードの中で完結します。 コピー&ペースト・クリップボード連携機能 Drag セルの値をエクセルのようにマウス操作のみでコピー&ペーストすることもできるた め、ダッシュボード上でデータの一括更新も容易に行えます。そのうえ、選択した データをクリップボードにコピーして、エクセル上でさらに加工することも可能です。 7 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
8.
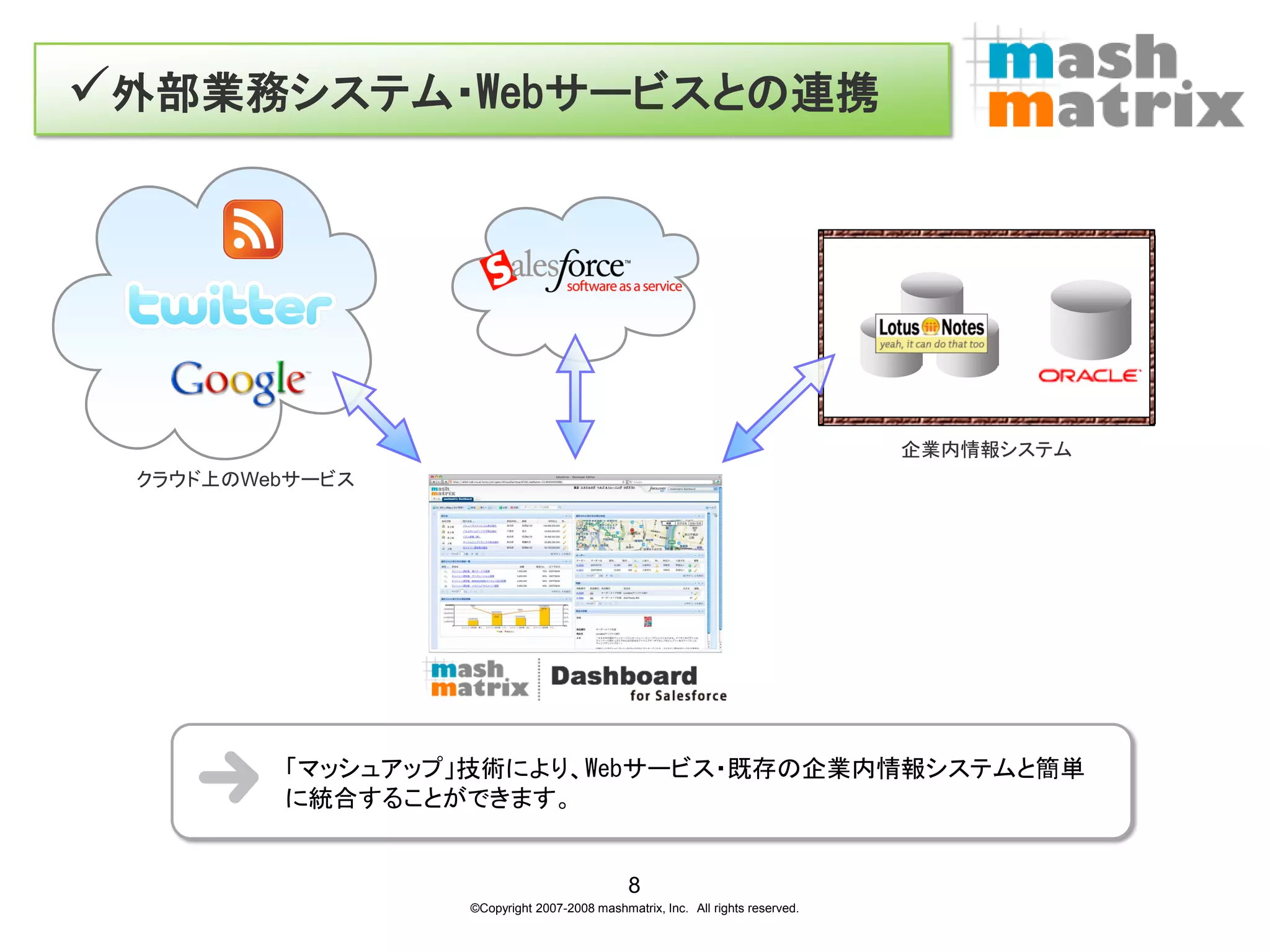
外部業務システム・Webサービスとの連携
企業内情報システム クラウド上のWebサービス 「マッシュアップ」技術により、Webサービス・既存の企業内情報システムと簡単 に統合することができます。 8 ©Copyright 2007-2008 mashmatrix, Inc. All rights reserved.
9.
利用事例・ユースケース
9 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
10.
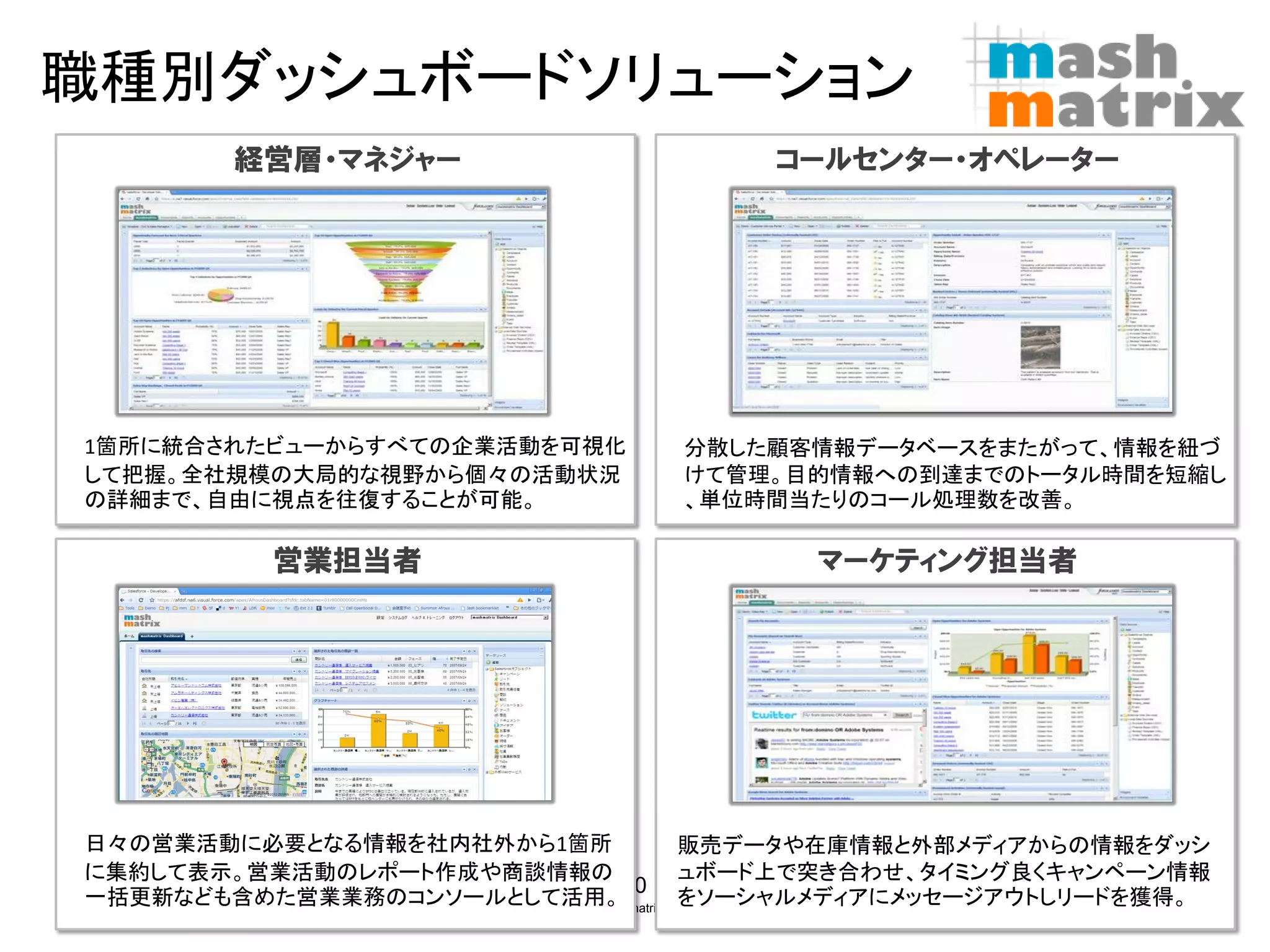
職種別ダッシュボードソリューション
経営層・マネジャー コールセンター・オペレーター 1箇所に統合されたビューからすべての企業活動を可視化 分散した顧客情報データベースをまたがって、情報を紐づ して把握。全社規模の大局的な視野から個々の活動状況 けて管理。目的情報への到達までのトータル時間を短縮し の詳細まで、自由に視点を往復することが可能。 、単位時間当たりのコール処理数を改善。 営業担当者 マーケティング担当者 日々の営業活動に必要となる情報を社内社外から1箇所 販売データや在庫情報と外部メディアからの情報をダッシ に集約して表示。営業活動のレポート作成や商談情報の ュボード上で突き合わせ、タイミング良くキャンペーン情報 10 一括更新なども含めた営業業務のコンソールとして活用。 をソーシャルメディアにメッセージアウトしリードを獲得。 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
11.
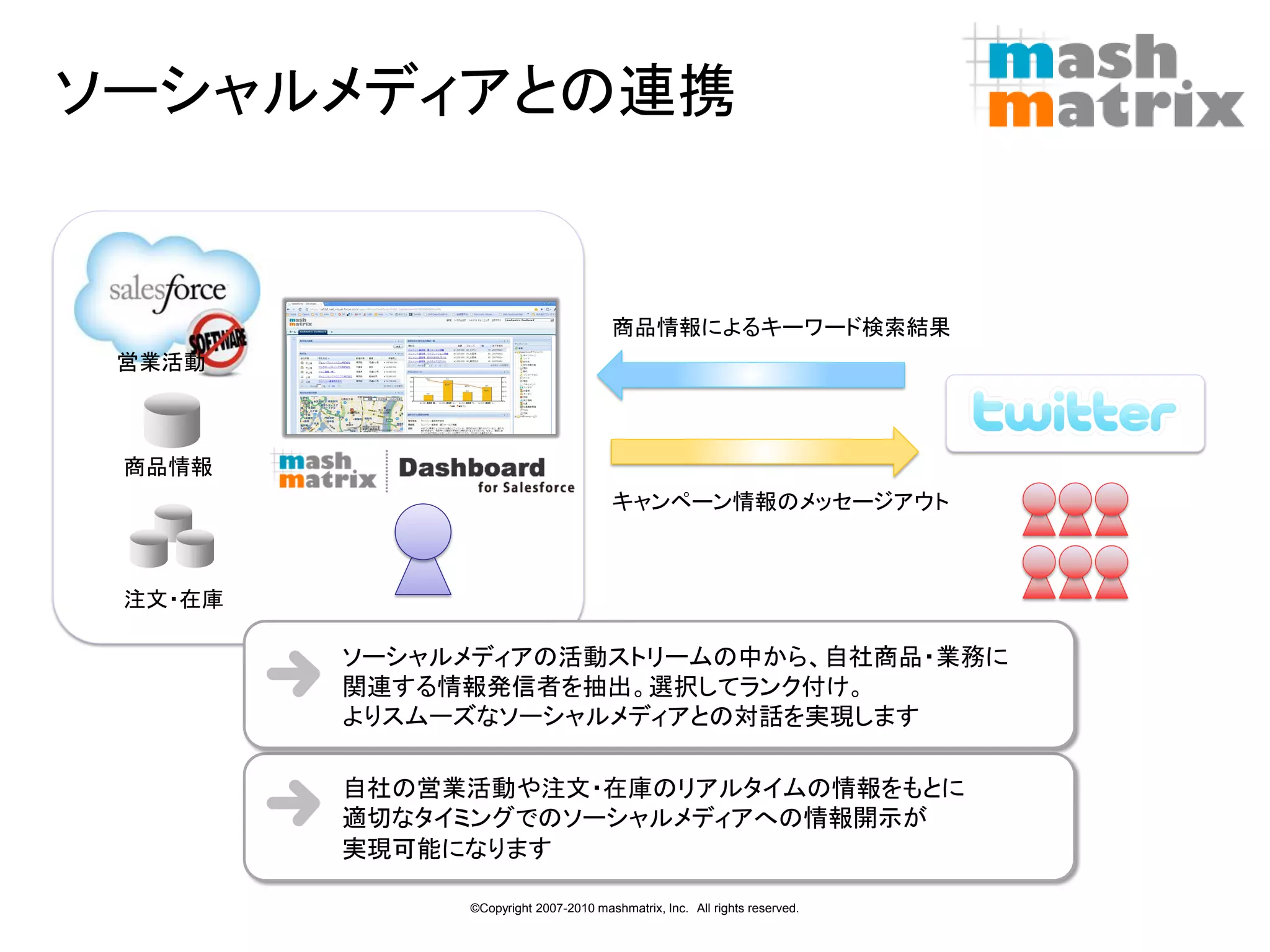
ソーシャルメディアとの連携
商品情報によるキーワード検索結果 営業活動 商品情報 キャンペーン情報のメッセージアウト 注文・在庫 ソーシャルメディアの活動ストリームの中から、自社商品・業務に 関連する情報発信者を抽出。選択してランク付け。 よりスムーズなソーシャルメディアとの対話を実現します 自社の営業活動や注文・在庫のリアルタイムの情報をもとに 適切なタイミングでのソーシャルメディアへの情報開示が 実現可能になります 11 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
12.
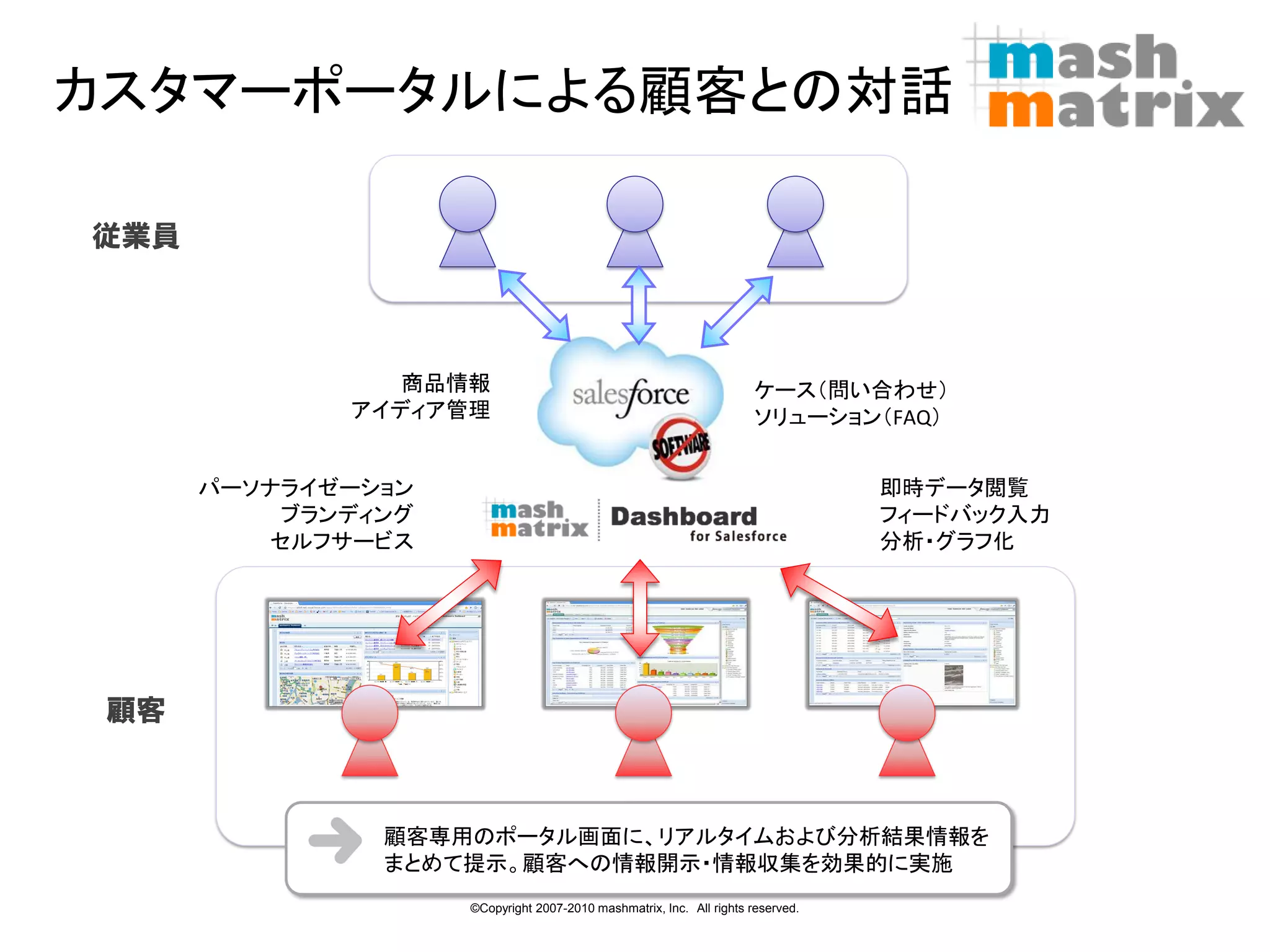
カスタマーポータルによる顧客との対話 従業員
商品情報 ケース(問い合わせ) アイディア管理 ソリューション(FAQ) パーソナライゼーション 即時データ閲覧 ブランディング フィードバック入力 セルフサービス 分析・グラフ化 顧客 顧客専用のポータル画面に、リアルタイムおよび分析結果情報を まとめて提示。顧客への情報開示・情報収集を効果的に実施 12 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
13.
内部実装に関する情報
13 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
14.
アーキテクチャ •
クライアントサイド • Ext JS 2.1で構築されたリッチUI (3.0に移行検討中) • マッシュアップロジックはすべてクライアントサイド(Webブラ ウザ上)で実行 • Afrous マッシュアップエンジン • サーバサイド • Force.com、Google App EngineなどのPaaSクラウドに直接接 続し、データを保存。利用者はサーバセットアップ必要なし • OAuth Proxy 機能(実装中) 14 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
15.
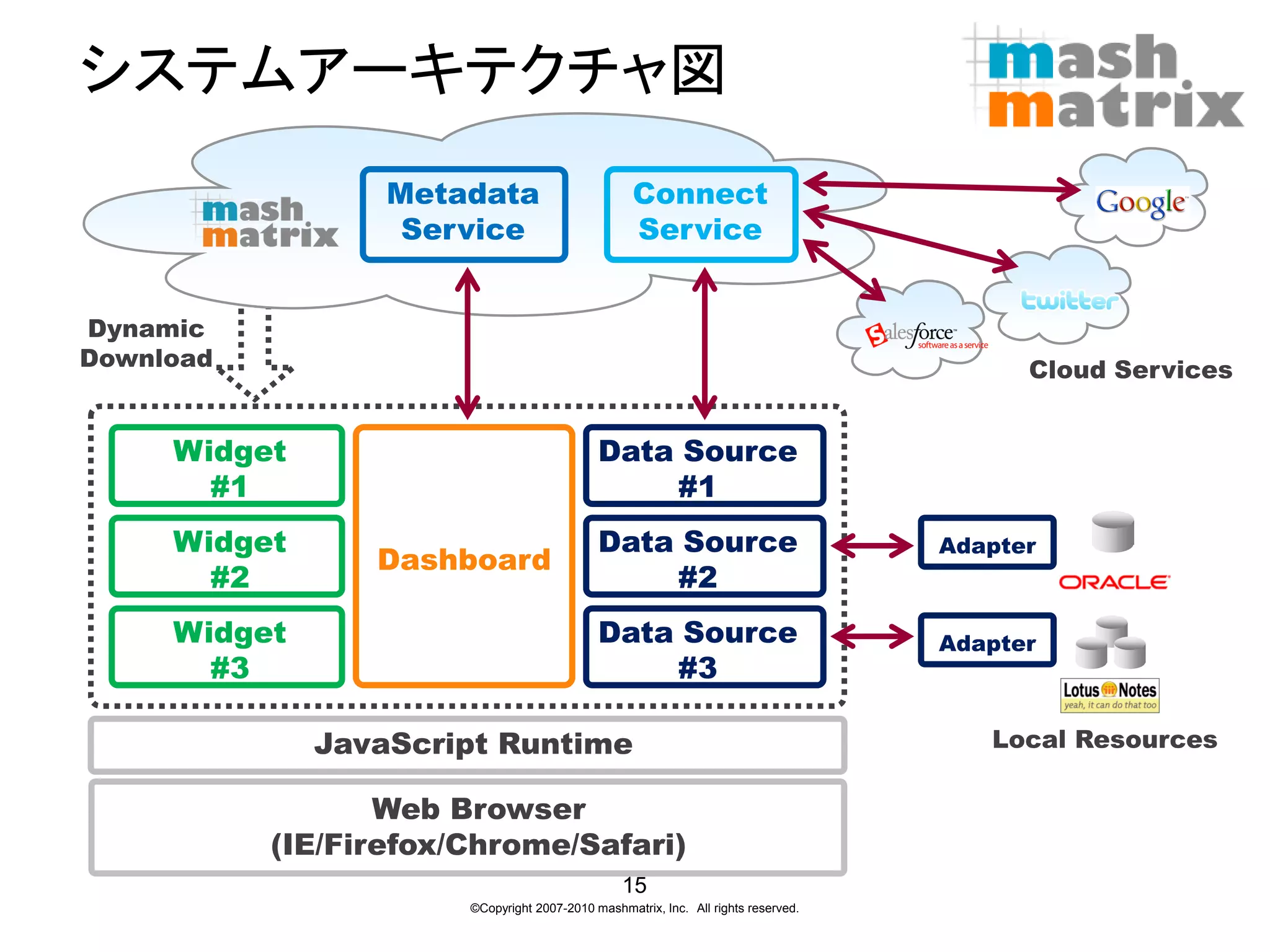
システムアーキテクチャ図
Metadata Connect Service Service Dynamic Download Cloud Services Widget Data Source #1 #1 Widget Data Source Adapter Dashboard #2 #2 Widget Data Source Adapter #3 #3 JavaScript Runtime Local Resources Web Browser (IE/Firefox/Chrome/Safari) 15 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
16.
特徴 •
ウィジットは「表示」のみを担当。データアクセス部分はデータ ソースとして分離されている 例: • 「グリッド」ウィジットが、Googleスプレッドシートの表示やデ ータベースクエリの結果表示の双方に利用できる • 「画像タイル」ウィジットが、Google画像検索結果の表示や 楽天商品検索結果表示の双方に利用できる • 取得されたデータと表示の結びつけは画面上で設定(コーディ ング不要) 16 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
17.
データ構造 •
JSON形式でダッシュボードレイアウト・ウィジット設定を それぞれ「メタデータ」としてサーバサイドに保存 • JSONは、Ext JSのコンポーネント構造そのものではなく、独自 • 起動時にJSONデータを読み込み、動的にコンポーネントを レンダリング開始 • ウィジット設定はそれぞれ他のウィジットの値を参照し て設定値として利用可能 • データ参照を表す特殊記法を使用 ( ${…} ) • 参照データが更新された場合、自動的にウィジットも更新 17 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
18.
データ構造の例
ダッシュボード ウィジット { { "name": "テスト0331", "wtype": "grid", "key": "a0V10000000Aqz6EAC", "title": “Test Grid", "name": "w3", "layout": "1column", "storeType": "datasource", "regions": [{ "datasource": { ... }, "widgets": [{ "columns": [{ "wtype": "grid", "header": "日付", ... "value": "${Date}", }, { ... "wtype": "fc-chart", }, { .... ... }, }], "filterMode": "AND", }, { "filters": [{ "widgets": [{ "property": “Amount", ... “operation”: “<", }] "value": “${w1_click.num}" }], }, { "published": false ... } }], 18 "published": false } ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
19.
ローカルネットワークへの接続 •
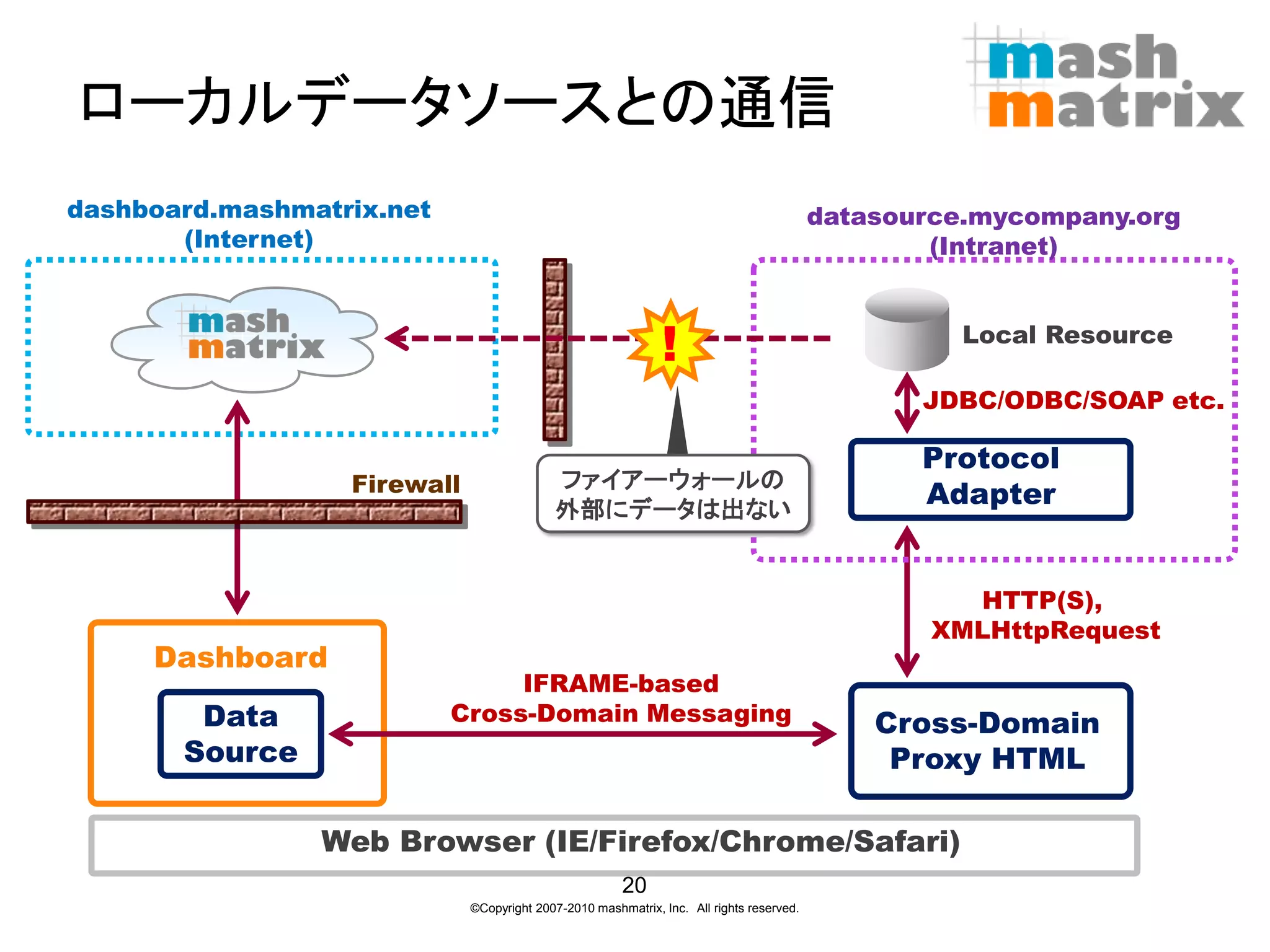
ファイアーウォール内のローカルネットワークに配置されてい るデータに対しては、クラウドを介することなくローカルネットワ ークの中のみで通信を行う。 • 仕組上、データが外部に漏れることがないため、クラウドに おけるデータセキュリティの懸念から解放 • 各データソースにアダプタが設置され、通信はWebブラウザと アダプタとの間で直接行われる。 • Webブラウザ上でのクライアントサイド・クロスドメイン接続 技術を活用 19 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
20.
ローカルデータソースとの通信 dashboard.mashmatrix.net
datasource.mycompany.org (Internet) (Intranet) ! Local Resource JDBC/ODBC/SOAP etc. Protocol Firewall ファイアーウォールの Adapter 外部にデータは出ない HTTP(S), XMLHttpRequest Dashboard IFRAME-based Data Cross-Domain Messaging Cross-Domain Source Proxy HTML Web Browser (IE/Firefox/Chrome/Safari) 20 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
21.
Ext JS DataStoreに関するTips •
Ext.data.DataStore はDataProxy(HttpProxy, MemoryProxy, ScriptTagProxy)を利用してデータをフェッチ • HttpProxy、ScriptTagProxy は、接続先がRESTful Call インター フェースであることに依存している • サーバサイドのインターフェースに手を入れられない場合あり。わざわざプロキ シサーバを置きたくない • 例:JSのToolkitを介してAPIアクセスするようなデータソース(Gdata JavaScript, Salesforce Ajax Toolkit, Twitter @Anywhere) • 自分で非同期でデータを取った後、同期的にStoreに対してデ ータロードさせる? 面倒、あまりかっこよくない 非同期呼び出しに抽象化したAsyncProxyを定義 21 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
22.
AsyncProxy var MyAsyncProxy =
Ext.extend(AsyncProxy, { doAsyncRequest : function(params, callback) { // ここに任意の非同期データ取得処理を記述 // callbackで値を返却 } }); new Ext.grid.GridPanel({ renderTo : Ext.getBody(), width : 300, height : 100, store : new Ext.data.Store({ proxy : new MyAsyncProxy(), reader : new Ext.data.ArrayReader({ fields : ['Id','FirstName','LastName'] }) }), columns : [ … ] }); 22 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
23.
Ext JS TreePanelに関するTips •
AsyncTreeNodeの場合、Ext.tree.TreeLoaderでノードデータをロ ードする • TreeLoaderはURLでの呼び出しに強く依存している! • しかも戻り値のフォーマットもTreeLoader側が規定 • サーバインターフェースが固定の時はどうするか?はたま たサーバ以外がデータソースの場合は? • 自分で非同期でデータを取った後、(Asyncでない)TreeNodeで 同期的にツリー構築しますか? 面倒、やってられない 非同期呼び出しに抽象化した AsyncLoader を定義 23 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
24.
AsyncLoader var MyTreeLoader =
Ext.extend(AsyncLoader, { doAsyncLoad : function(node, callback) { // ここに任意の非同期データ取得処理を記述 // callbackで子ノードのconfigの配列を返却 } }); new Ext.tree.TreePanel({ renderTo : Ext.getBody(), width : 100, height : 200, autoScroll : true, root : new Ext.tree.AsyncTreeNode({ text : 'node1', value : 1 }), loader : new MyTreeLoader() }); 24 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
25.
AsyncProxy/AsyncLoaderの実装について •
昔ブログに書いた(2.1ベース) • http://d.hatena.ne.jp/shinichitomita/20081011/1223735817 • 3.xではちょっと実装を変える必要あると思う 25 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
26.
まとめ •
マッシュアップサービスによって、クラウドサービスをユーザ主 導で簡単につなげることが可能になる • クラウドサービス側のインターフェースはまちまち。マッシュアッ プサービスが吸収してあげる必要がある。 • 異なるインターフェースの解決をサーバで行おうとすると、サー バ依存が大きくなり、信頼性・スケーラビリティが損なわれる • Ext JS はクライアント側からサーバインターフェースを規定して るところが多いが、大部分はクライアントサイドでも吸収でき、 クライアントで対応したほうがよりスケーラブルになる(中間ノ ードを排除できる) 26 ©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.
27.
©Copyright 2007-2010 mashmatrix,
Inc. All rights reserved.
Download










![データ構造の例
ダッシュボード ウィジット
{ {
"name": "テスト0331", "wtype": "grid",
"key": "a0V10000000Aqz6EAC", "title": “Test Grid",
"name": "w3",
"layout": "1column",
"storeType": "datasource",
"regions": [{
"datasource": { ... },
"widgets": [{ "columns": [{
"wtype": "grid", "header": "日付",
... "value": "${Date}",
}, { ...
"wtype": "fc-chart", }, {
.... ...
}, }],
"filterMode": "AND",
}, {
"filters": [{
"widgets": [{
"property": “Amount",
... “operation”: “<",
}] "value": “${w1_click.num}"
}], }, {
"published": false ...
} }],
18 "published": false
}
©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.](https://image.slidesharecdn.com/extjs20100526-100526065158-phpapp02/75/Ext-js-20100526-18-2048.jpg)


![AsyncProxy
var MyAsyncProxy = Ext.extend(AsyncProxy, {
doAsyncRequest : function(params, callback) {
// ここに任意の非同期データ取得処理を記述
// callbackで値を返却
}
});
new Ext.grid.GridPanel({
renderTo : Ext.getBody(),
width : 300, height : 100,
store : new Ext.data.Store({
proxy : new MyAsyncProxy(),
reader : new Ext.data.ArrayReader({
fields : ['Id','FirstName','LastName']
})
}),
columns : [ … ]
}); 22
©Copyright 2007-2010 mashmatrix, Inc. All rights reserved.](https://image.slidesharecdn.com/extjs20100526-100526065158-phpapp02/75/Ext-js-20100526-22-2048.jpg)







![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)







































