Download to read offline


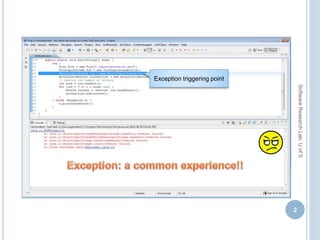








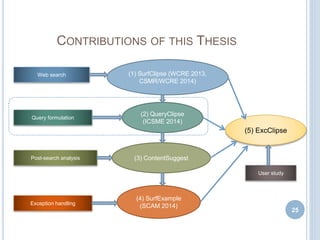
![RESULTS ON DIFFERENT RANKING ASPECTS
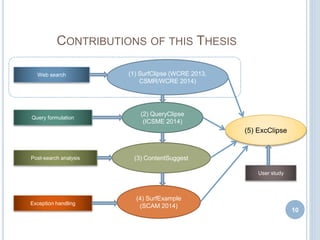
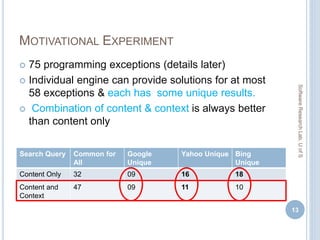
Score Components Metrics Proactive Mode
(Top 30)
Interactive Mode
(Top 30)
Content MP
TEF
R
0.0371
56 (75)
74.66%
0.0481
65 (75)
86.66%
Content +Context MP
TEF
R
0.0376
55 (75)
73.33%
0.0514
66 (75)
88.00%
Content + Context +
Popularity
MP
TEF
R
0.0381
56 (75)
74.66%
0.0519
66 (75)
88.00%
Content +Context +
Popularity
+Confidence
MP
TEF
R
0.0380
56 (75)
74.66%
0.0538
68 (75)
90.66%
[ MP = Mean Precision, R = Recall,
TEF= Total Exceptions Fixed]
22
SoftwareResearchLab,UofS](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-21-320.jpg)
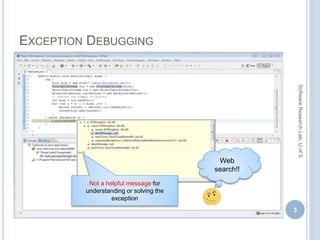
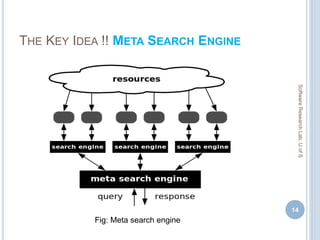
![COMPARISON WITH EXISTING APPROACHES
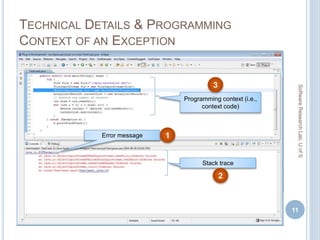
Recommender Metrics Top 10 Top 20 Top 30
Cordeiro et al.
(only stack traces)
MP
TEF
R
0.0202
15 (75)
20.00%
0.0128
18 (75)
24.00%
0.0085
18 (75)
24.00%
Proposed Method
(Proactive Mode)
MP
TEF
R
0.0886
51 (75)
68.00%
0.0529
55 (75)
73.33%
0.0380
56 (75)
74.66%
Ponzanelli et al.
(only context-code)
MP
TEF
R
0.0243
7 (37)
18.92%
0.0135
7 (37)
18.92%
0.0099
7 (37)
18.92%
Proposed Method
(Proactive Mode)
MP
TEF
R
0.1000
30 (37)
81.08%
0.0621
32 (37)
86.48%
0.0450
32 (37)
86.48%
[ MP = Mean Precision, R = Recall,
TEF= Total Exceptions Fixed]
23
SoftwareResearchLab,UofS](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-22-320.jpg)















![REFERENCES
[1] J. Cordeiro, B. Antunes, and P. Gomes. Context-based Recommendation to Support Problem Solving in
Software Development. In Proc. RSSE, pages 85 –89, June 2012.
[2] L. Ponzanelli, A. Bacchelli, and M. Lanza. Seahawk: Stack Overflow in the IDE. In Proc. ICSE, pages 1295–
1298, 2013
[3] J. Brandt, P. J. Guo, J. Lewenstein, M. Dontcheva, and S. R. Klemmer. Two Studies of Opportunistic
Programming: Interleaving Web Foraging, Learning, and Writing Code. In Proc. SIGCHI, pages 1589–1598,
2009.
[4] F. Sun, D. Song, and L. Liao. DOM Based Content Extraction via Text Density. In Proc. SIGIR, pages 245–254,
2011.
[5] T. Gottron. Content Code Blurring: A New Approach to Content Extraction. In Proc. DEXA, pages 29–33,
2008.
[6] S. Bajracharya, J. Ossher, and C. Lopes. Sourcerer: An Internet-Scale Software Repository. In Proc. SUITE,
pages 1–4, 2009
[7] E. A. Barbosa, A. Garcia, and M. Mezini. Heuristic Strategies for Recommendation of Exception Handling
Code. In Proc. SBES, pages 171–180, 2012
[8] R. Holmes and G. C. Murphy. Using Structural Context to Recommend Source Code Examples. In Proc.
ICSE, pages 117–125, 2005
[9] W. Takuya and H. Masuhara. A Spontaneous Code Recommendation Tool Based on Associative Search. In
Proc. SUITE, pages 17–20, 2011.
[10] M. M. Rahman, S. Yeasmin, and C. K. Roy. Towards a Context-Aware IDEBased Meta Search Engine for
Recommendation about Programming Errors and Exceptions. In Proc. CSMR-WCRE, pages 194–203, 2014
[11] M. M. Rahman and C.K. Roy. On the Use of Context in Recommending Exception Handling Code
Examples. In Proc. SCAM, 10 pp., 2014 (to appear)
[12] M. M. Rahman and C.K. Roy. SurfClipse: Context-Aware Meta Search in the IDE. In Proc. ICSME, 4 pp., 2014
(to appear)
[13] Slide 13, Meta Search Engine, http://en.wikipedia.org/wiki/Metasearch_engine 52
SoftwareResearchLab,UofS](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-50-320.jpg)



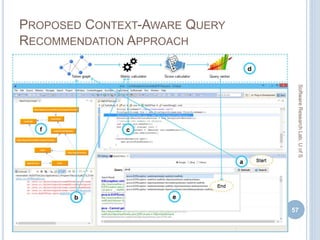


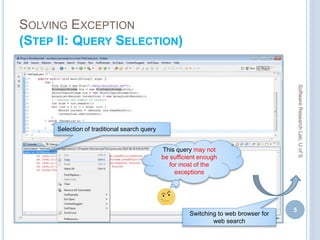
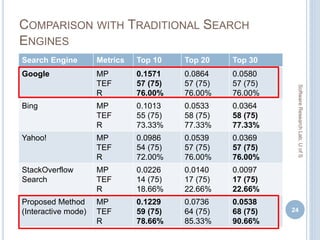
![RESULTS ON DIFFERENT RANKING ASPECTS
60
Rank
Aspects
Metrics Google Bing Yahoo!
Top 10 Top 20 Top 10 Top 20 Top 10 Top 20
{DOI, TTR} MAPK
R
PTCS
36.36%
15.19%
48.00%
36.36%
15.19%
48.00%
49.24%
27.84%
70.00%
49.24%
30.68%
76.00%
51.70%
34.09%
76.00%
51.61%
35.23%
78.00%
{TTR, TTF} MAPK
R
PTCS
38.23%
15.34%
46.00%
38.23%
15.34%
46.00%
50.18%
29.55%
70.00%
50.09%
31.25%
74.00%
45.46%
30.68%
68.00%
44.60%
32.39%
70.00%
{DOI, TTF} MAPK
R
PTCS
37.26%
17.61%
50.00%
37.26%
17.61%
50.00%
49.53%
27.84%
72.00%
48.23%
30.11%
74.00%
53.49%
30.68%
78.00%
51.35%
32.95%
78.00%
{DOI, TTR,
TTF}
MAPK
R
PTCS
34.06%
13.64%
42.00%
34.06%
13.64%
42.00%
51.85%
27.84%
72.00%
50.44%
31.25%
76.00%
55.31%
31.82%
76.00%
53.40%
35.23%
80.00%
[ MP = Mean Average Precision at K, R = Recall,
PTCS= % of Exceptions Solved]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-58-320.jpg)
![COMPARISON WITH EXISTING APPROACHES
61
SoftwareResearchLab,UofS
Approach Metrics Google Bing Yahoo!
Top 10 Top 20 Top 10 Top 20 Top 10 Top 20
Traditional
(Only error
message)
MAPK
R
PTCS
38.97%
19.88%
52.00%
38.97%
19.88%
52.00%
44.11%
24.43%
58.00%
43.82%
26.14%
60.00%
43.18%
25.00%
56.00%
43.18
25.00%
56.00%
Cordeiro et
al.
MAPK
R
PTCS
21.33%
10.80%
36.00%
21.17%
11.93%
38.00%
19.22%
11.93%
34.00%
19.22%
13.07%
36.00%
15.94%
10.80%
32.00%
16.60%
13.06%
40.00%
Ponzanelli et
al.
MAPK
R
PTCS
14.36%
9.09%
24.00%
14.36%
9.09%
24.00%
30.27%
12.50%
38.00%
29.98%
13.07%
38.00%
28.12%
12.50%
38.00%
28.12%
12.50%
38.00%
Proposed
approach
MAPK
R
PTCS
34.06%
13.64%
42.00%
34.06%
13.64%
42.00%
51.85%
27.84%
72.00%
50.44%
31.25%
76.00%
55.31%
31.82%
76.00%
53.40%
35.23%
80.00%
[ MP = Mean Average Precision at K, R = Recall,
PTCS= % of Exceptions Solved]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-59-320.jpg)
![FINDINGS FROM USER STUDY
62
SoftwareResearchLab,UofS
Query No. 1 2 3 4 5 APS MAPS
PS (Rank I) 0.75 0.89 1.00 1.00 1.00 0.93
PS (Rank II) 0.67 0.72 0.93 1.00 0.63 0.79 0.84
PS (Rank III) 0.67 0.72 1.00 0.93 0.63 0.79
[ PS = Pyramid Score, APS = Average Pyramid Score,
MAPS= Mean Average Pyramid Score]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-60-320.jpg)

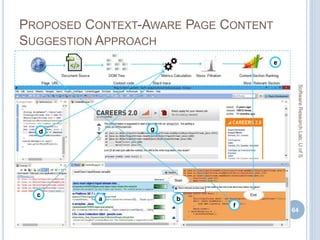


![RESULT ON DIFFERENT ASPECTS OF PAGE
CONTENT (RELEVANT CONTENT SUGGESTION)
67
SoftwareResearchLab,UofS
Content
Aspect
Metrics SO Pages Non-SO Pages All Pages
Content
Density
(CTD)
MP
MR
MF
50.91%
91.74%
62.32%
49.50%
75.71%
53.76%
50.07%
82.18%
57.22%
Content
Relevance
(CTR)
MP
MR
MF
86.63%
52.17%
61.07%
69.17%
57.66%
55.88%
76.23%
55.44%
57.98%
{CTD, CTR} MP
MR
MF
89.91%
74.90%
80.07%
74.12%
80.76%
73.91%
80.50%
78.39%
76.40%
[ MP = Mean Precision, MR = Mean Recall,
MF= Mean F1-measure]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-65-320.jpg)
![COMPARISON WITH EXISTING APPROACHES
68
SoftwareResearchLab,UofS
Approach Metrics SO Pages Non-SO Pages All Pages
Sun et al. MP
MR
MF
80.61%
86.41%
83.14%
78.70%
75.67%
75.48%
79.49%
80.14%
78.67%
ACCB [50] MP
MR
MF
90.65%
77.32%
83.07%
93.07%
79.98%
84.64%
92.06%
78.87%
83.99%
Proposed
(noise-free content
extraction)
MP
MR
MF
91.27%
89.27%
90.00%
88.90%
86.20%
85.76%
89.88%
87.48%
87.53%
Sun et al. (adapted) MP
MR
MF
52.63%
86.49%
62.57%
38.89%
41.84%
34.49%
44.44%
59.88%
45.84%
Proposed
(relevant section
suggestion)
MP
MR
MF
89.91%
74.90%
80.07%
74.12%
80.76%
73.91%
80.50%
78.39%
76.40%
[ MP = Mean Precision, MR = Mean Recall,
MF= Mean F1-measure]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-66-320.jpg)



![RESULT ON DIFFERENT RANKING ASPECTS
72
SoftwareResearchLab,UofS
Ranking Aspects Metrics Top 5 Top 10 Top 15
Structure (Rstr) MAPK
R
PEH
38.07%
50.00%
69.23%
33.84%
61.93%
75.38%
32.64%
69.32%
81.54%
Content (Rlex) MAPK
R
PEH
35.00%
45.45%
66.15%
33.85%
63.63%
75.38%
33.08%
70.45%
81.54%
{Structure (Rstr),
Content (Rlex)}
MAPK
R
PEH
43.08%
51.70%
69.23%
38.69%
66.48%
75.38%
37.33%
74.43%
81.54%
{Structure (Rstr),
Content (Rlex),
Quality (Qehc)}
MAPK
R
PEH
41.92%
57.39%
73.85%
39.92%
68.75%
81.54%
38.64%
76.70%
86.15%
[ MAPK = Mean Average Precision at K, R = Recall,
PEH= % of exceptions handled]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-70-320.jpg)
![COMPARISON WITH EXISTING APPROACHES
73
SoftwareResearchLab,UofS
Recommender Metrics Top 5 Top 10 Top 15
Barbosa et al. MAPK
R
PEH
16.15%
16.47%
27.69%
14.69%
25.57%
38.46%
13.72%
31.25%
44.62%
Holmes & Murphy MAPK
R
PEH
4.62%
11.36%
24.62%
2.31%
21.59%
38.46%
2.31%
27.84%
47.69%
Takuya & Masuhara MAPK
R
PEH
21.54%
15.34%
33.85%
20.51%
27.27%
47.69%
19.74%
30.68%
47.69%
Bajracharya et al. MAPK
R
PEH
8.46%
10.80%
18.46%
7.95%
15.91%
27.69%
6.41%
19.32%
30.77%
Proposed approach MAPK
R
PEH
41.92%
57.39%
73.85%
39.92%
68.75%
81.54%
38.64%
76.70%
86.15%
[ MAPK = Mean Average Precision at K, R = Recall,
PEH= % of exceptions handled]](https://image.slidesharecdn.com/masudmscdefence-170830051309/85/Exploiting-Context-in-Dealing-with-Programming-Errors-and-Exceptions-71-320.jpg)






This document proposes approaches to improve the process of debugging programming errors and exceptions. It summarizes existing ad-hoc approaches and their limitations. The proposed approaches leverage context from the integrated development environment to provide context-aware web search, query recommendation, content suggestion, code examples, and exception handling support. The approaches were evaluated in experiments and user studies and showed improvements over traditional search engines and existing approaches in areas like search accuracy, recall, and time to fix exceptions. The thesis contributes techniques like SurfClipse, QueryClipse, ContentSuggest, SurfExample, and ExcClipse to address different phases of the exception handling process.


























































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)








