Download to read offline


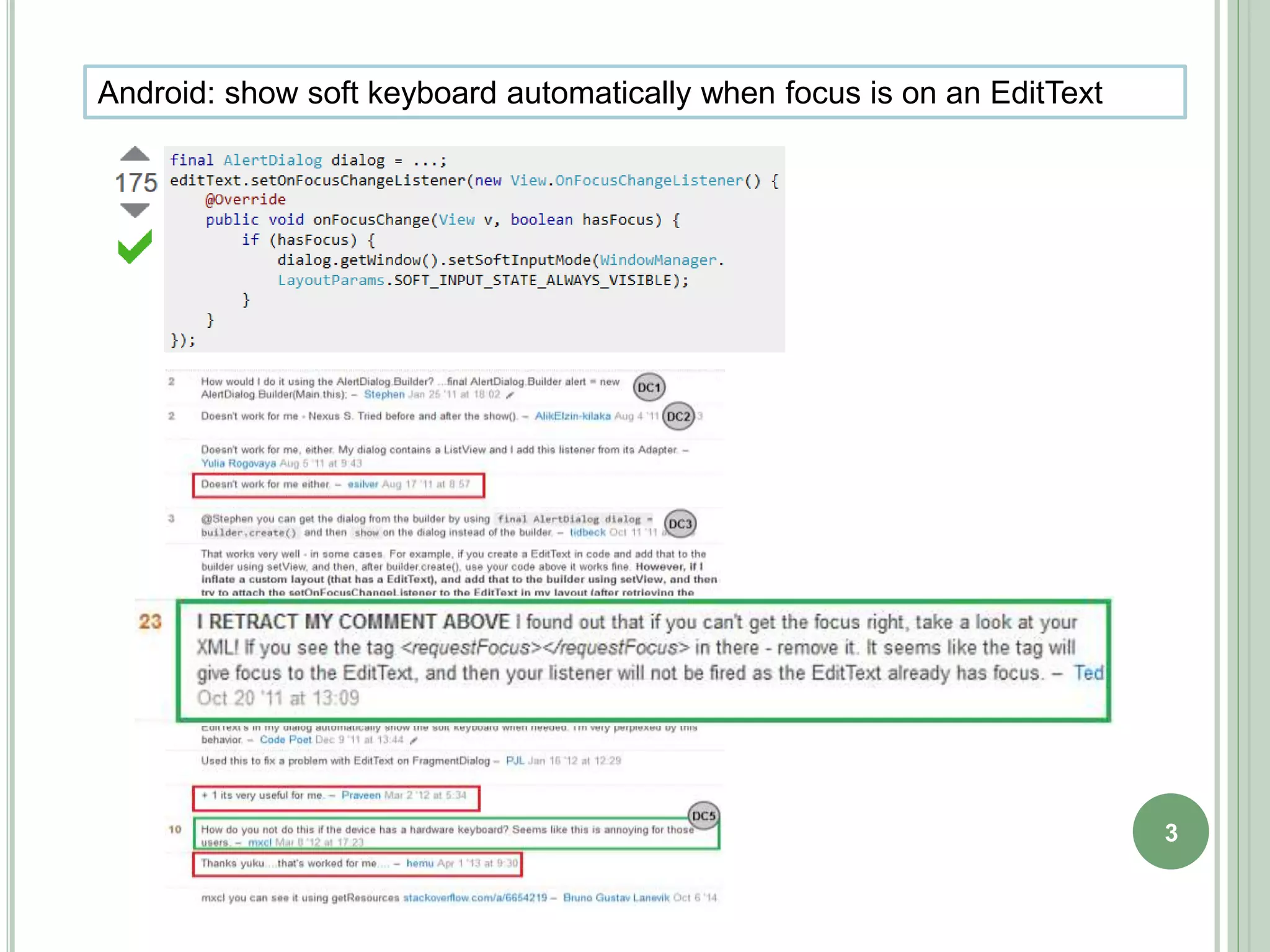
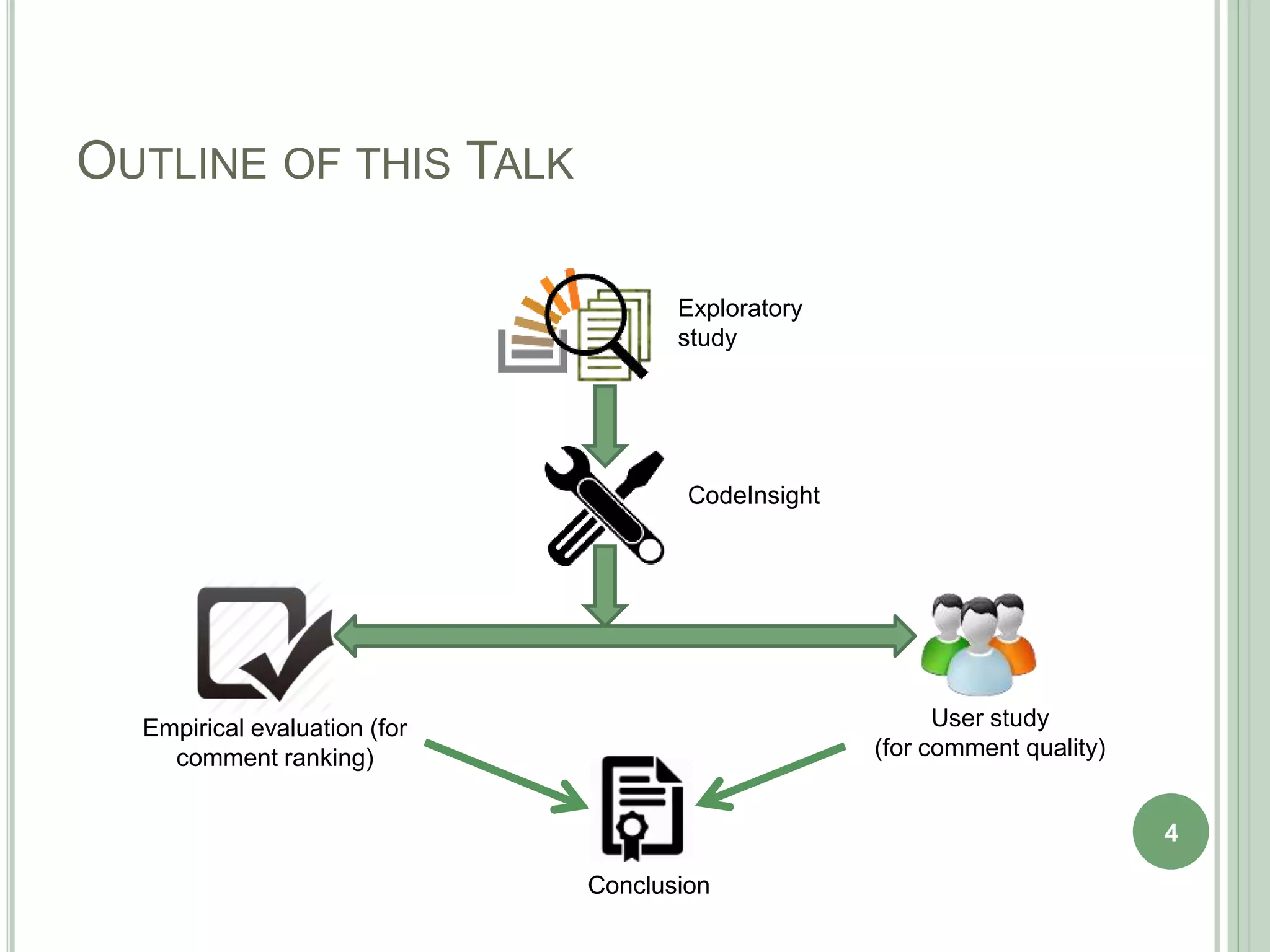

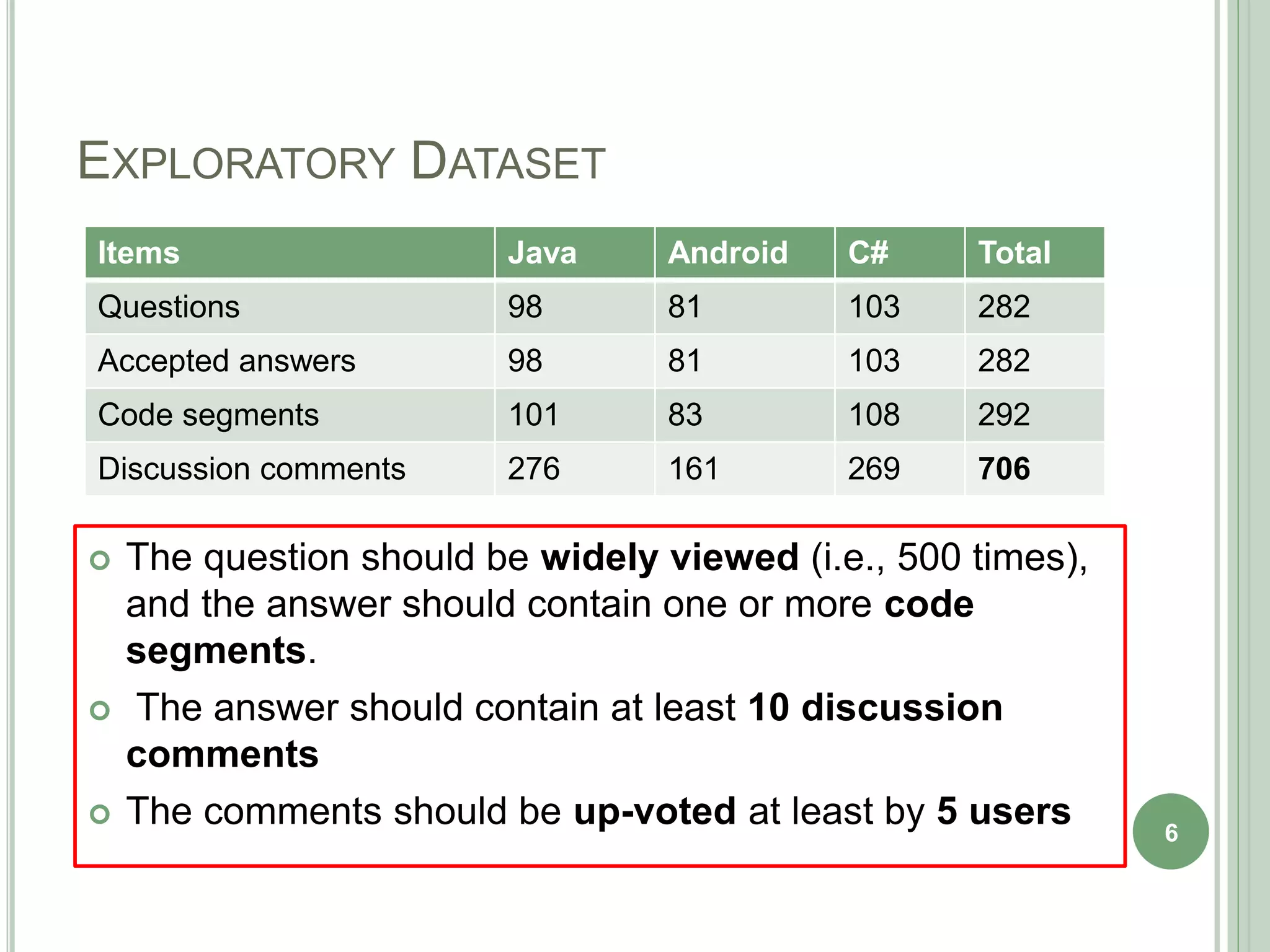
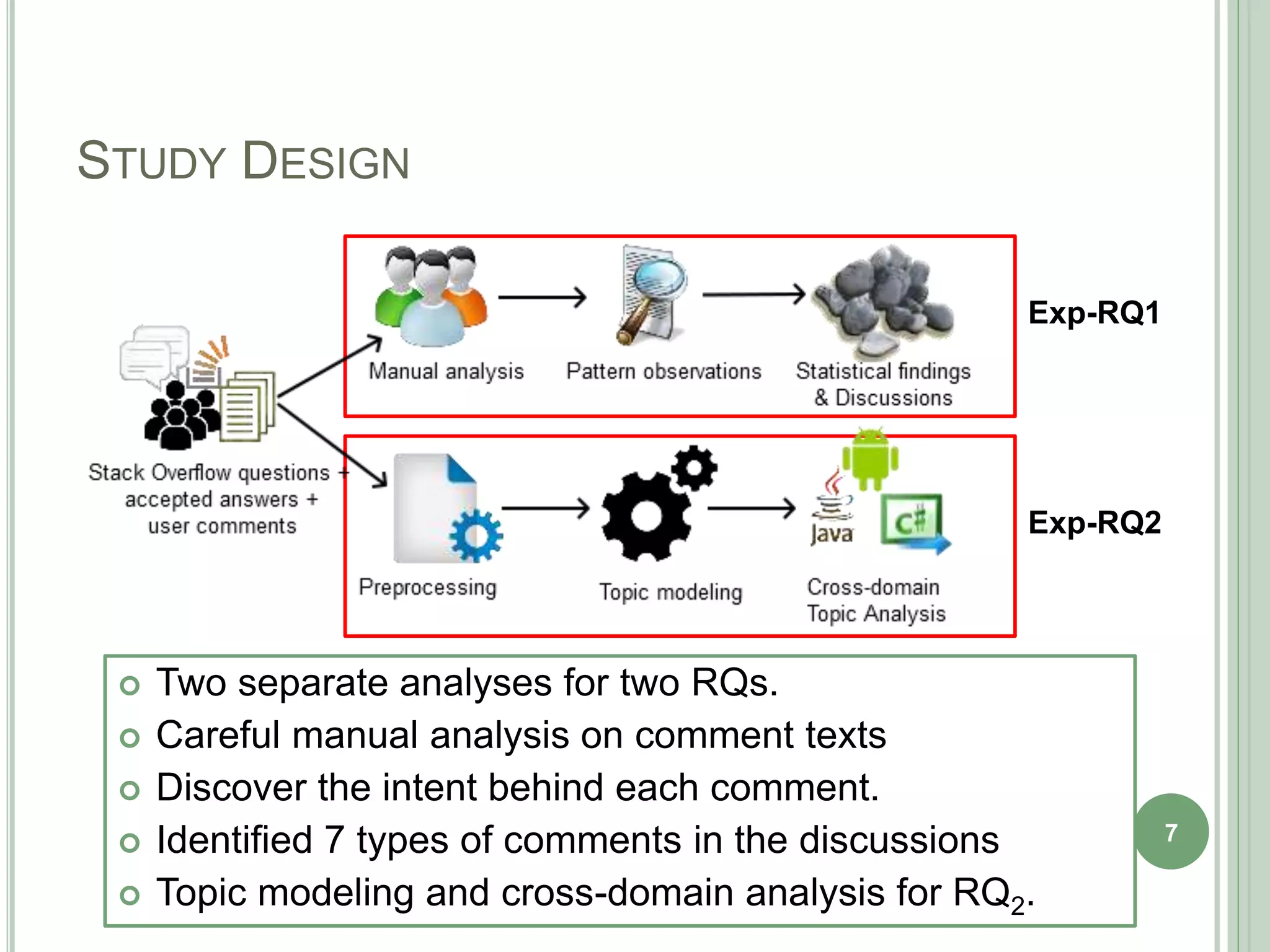



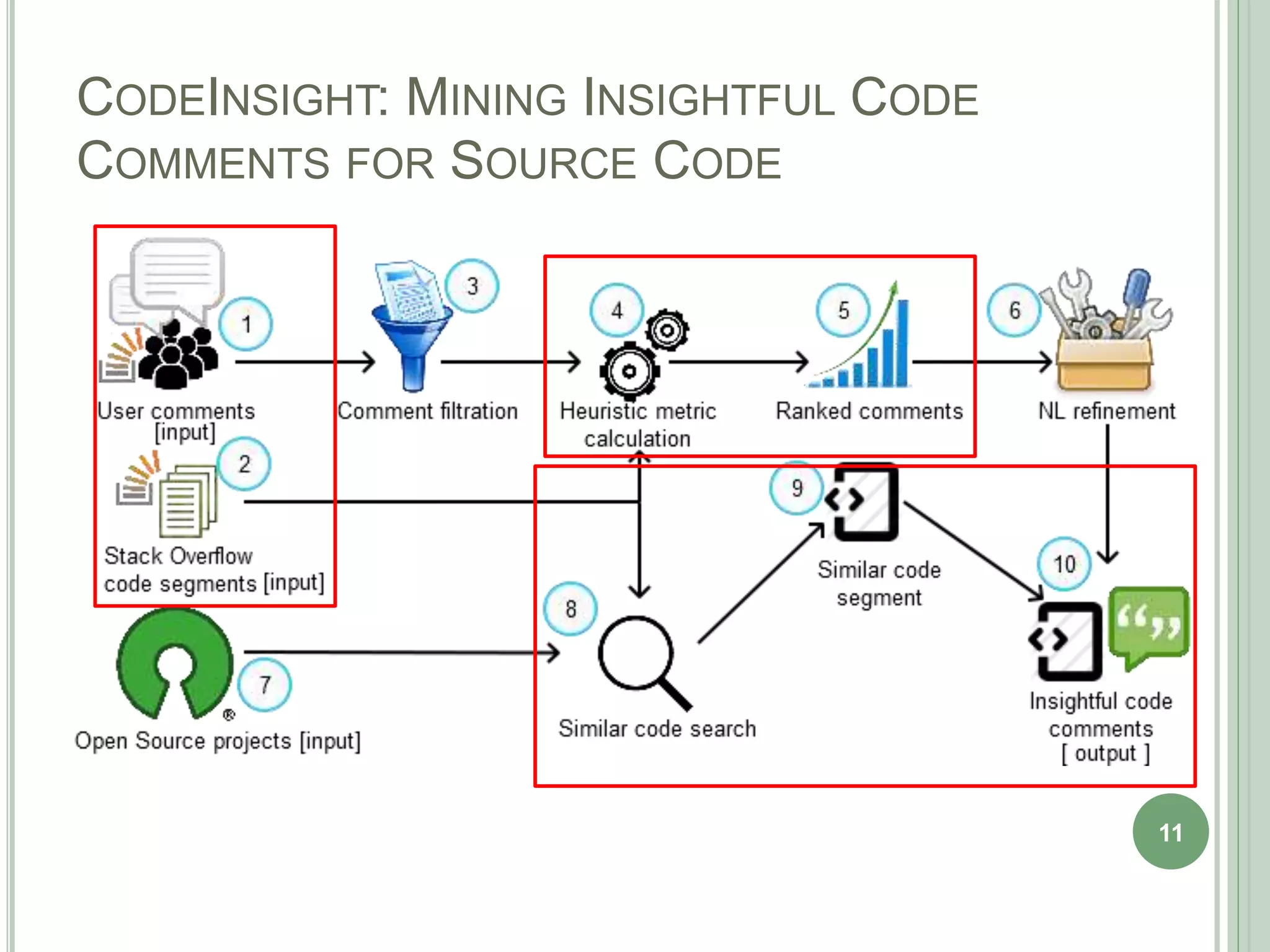


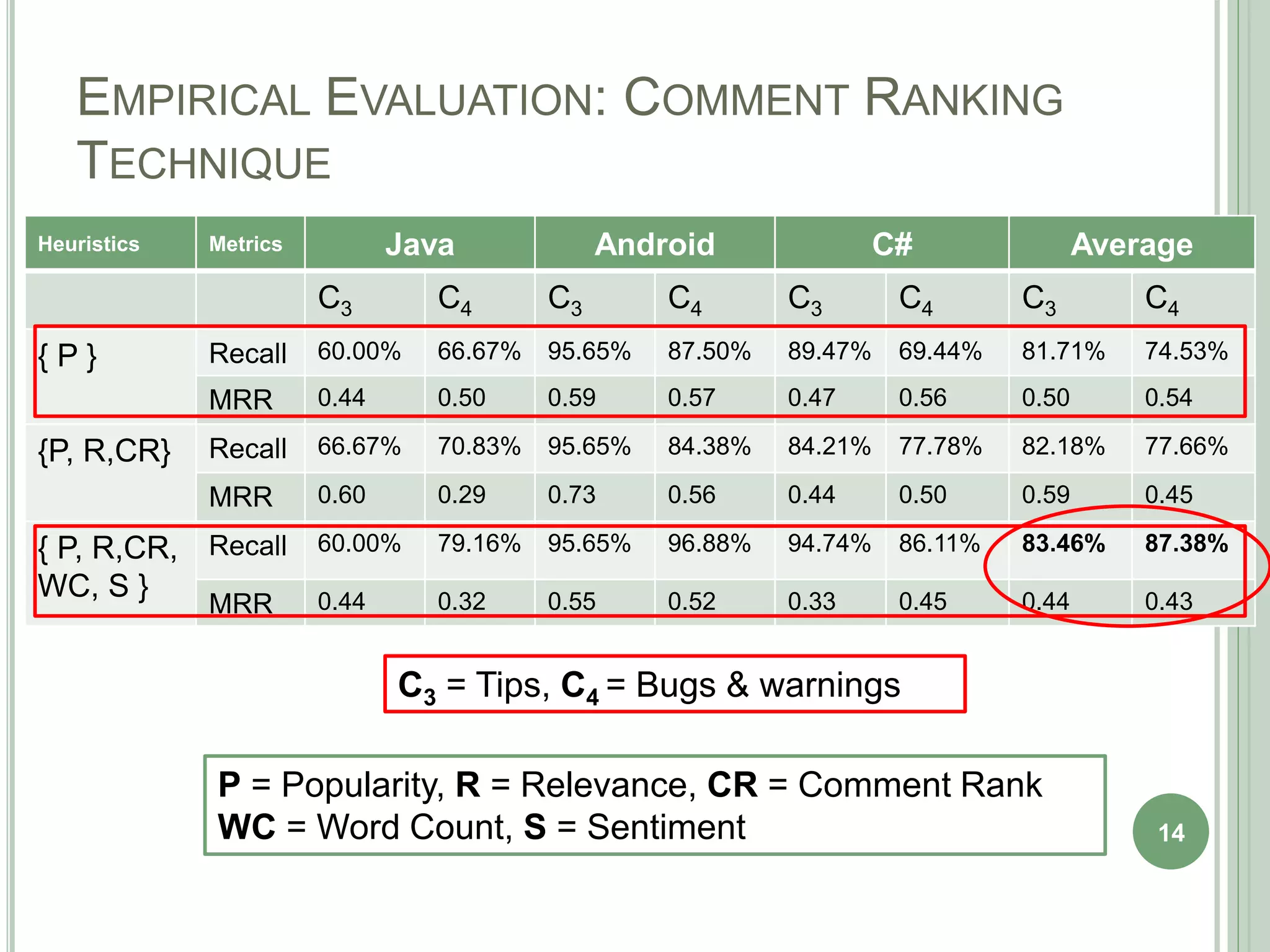

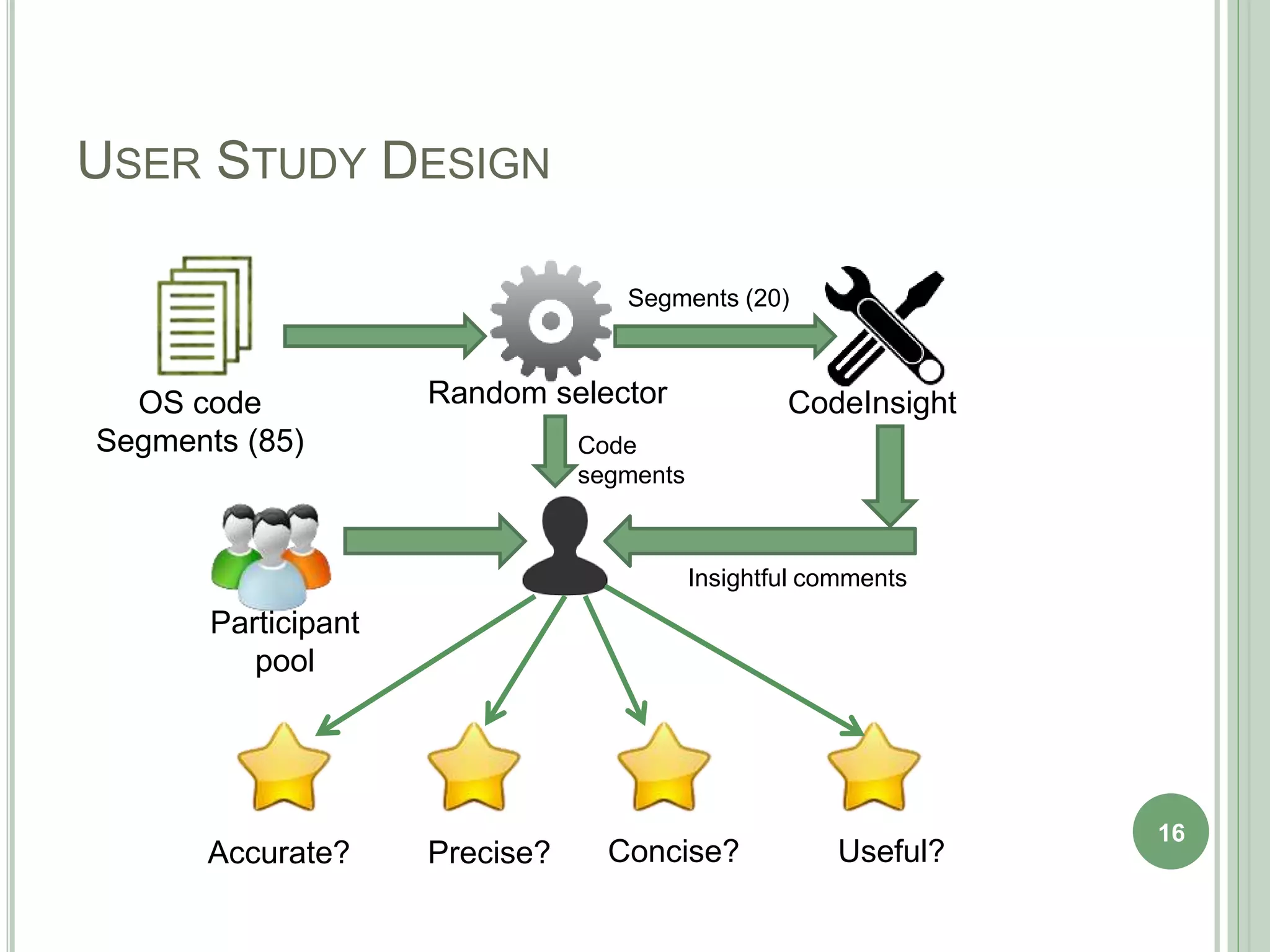
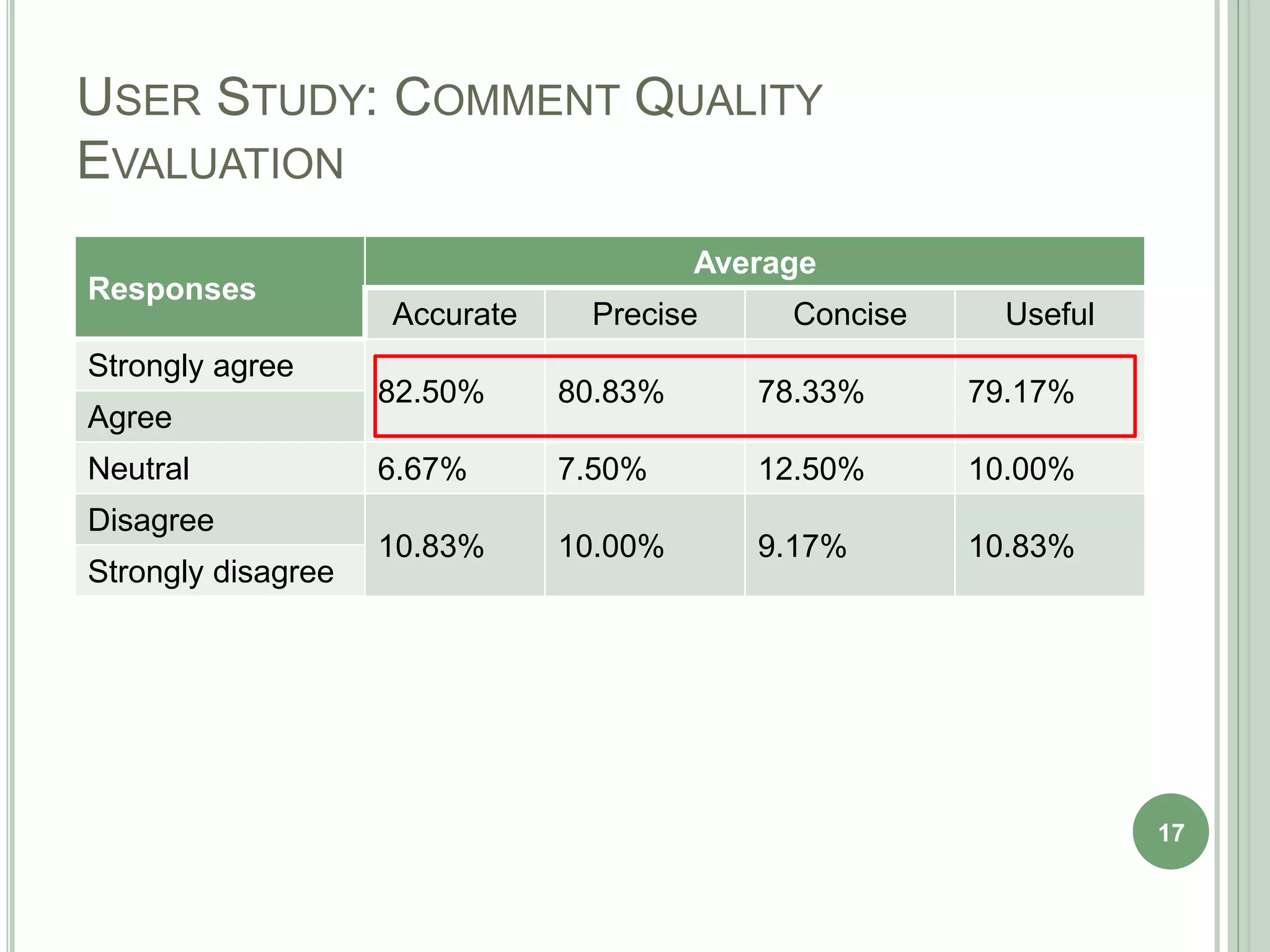





The document describes a technique called CodeInsight that mines insightful code comments from crowdsourced knowledge on Stack Overflow. An exploratory study of Stack Overflow discussions found that around 22% of comments discuss tips, bugs, or warnings related to code examples. CodeInsight uses heuristics like popularity, relevance, comment rank, sentiment, and word count to retrieve these insightful comments for a given code segment. An empirical evaluation showed the technique could recall over 80% of relevant comments on average. A user study with professional developers found that 80% of the comments recommended by CodeInsight were accurate and useful.



































































