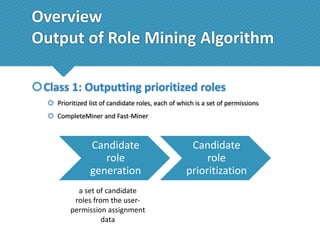
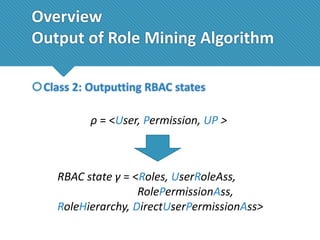
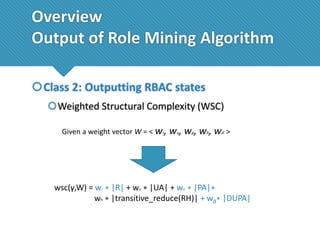
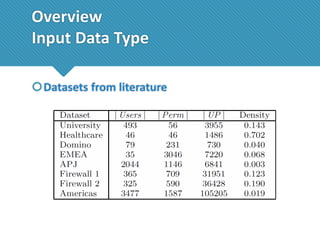
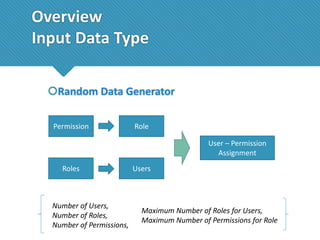
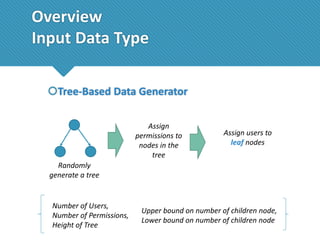
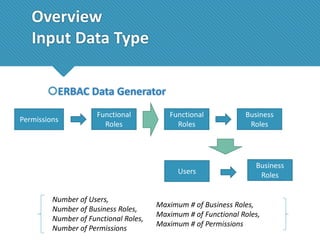
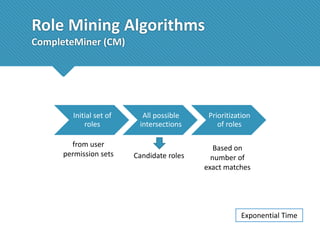
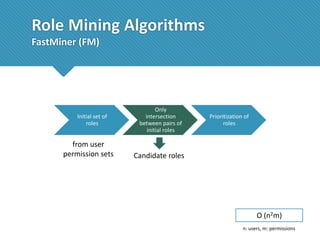
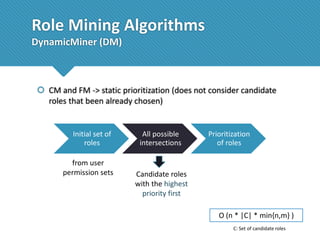
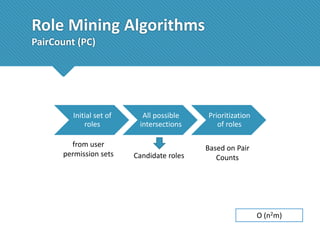
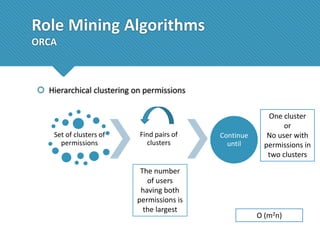
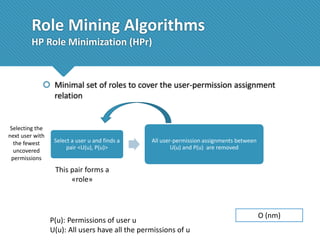
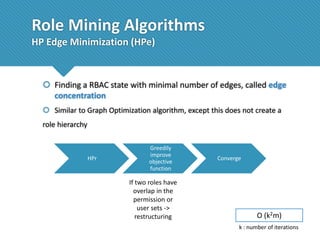
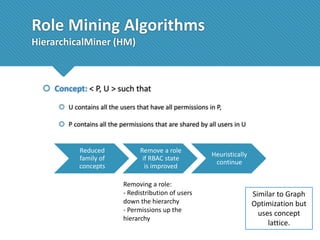
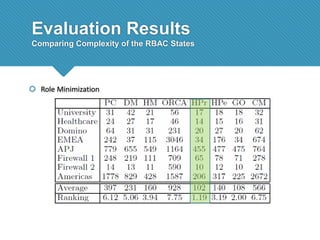
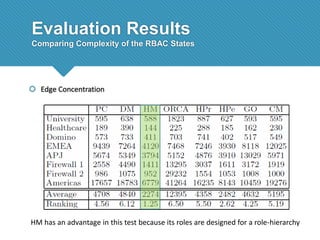
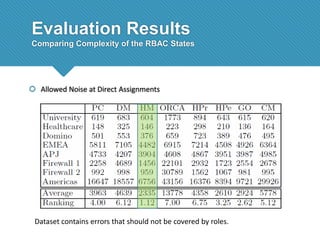
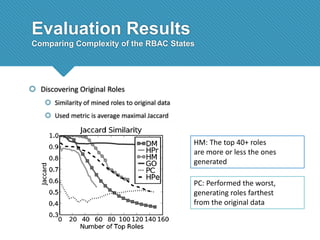
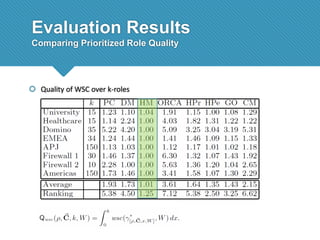
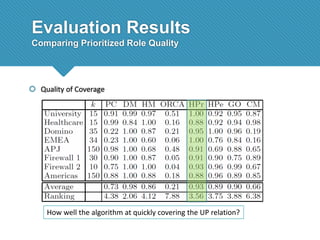
The document presents a comprehensive study comparing nine role mining algorithms, emphasizing their outputs and effectiveness in generating user-role relationships from system configuration data. It introduces two new methods for dataset generation and evaluates the algorithms based on metrics like the complexity of role-based access control (RBAC) states and the quality of roles produced. The analysis highlights strengths and weaknesses of each algorithm, suggesting areas for future improvement, including handling noisy data and incorporating attribute information.