Download as PDF, PPTX











![Data Ingestion
• The process of importing,
transferring and loading data for
storage and later use
• It involves loading data from a
variety of sources
• It can involve altering and
modification of individual files to fit
into a format that optimizes the
storage
• For instance, in Big Data small files
are concatenated to form files of
100s of MBs and large files are
broken down in files of 100s of MB.
Data
source #1
bus
Data
source #2
Data
source #n
[…]
Integration services
Transportation management, message
routing, message brokering,
transaction management, security, and
transformation.](https://image.slidesharecdn.com/smbud-04-data-architectures-240924210026-7919f784/85/Essential-concepts-of-data-architectures-18-320.jpg)
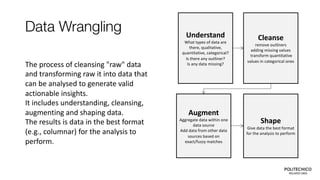


The document details data architecture concepts for big and unstructured data, focusing on schemas, transactions, partitioning, and replication methods. It emphasizes the importance of transaction systems, partitioning for scalability, and data ingestion processes. Additionally, it covers data wrangling techniques to cleanse and shape raw data for analysis.
































































