Efficient linear skyline algorithm in two dimensional space
1.
0
Jongwuk Lee
Dept ofSoftware,
Sungkyunkwan University
Hyeonseung Im
Dept of Computer Science,
Kangwon National University
Sung-Soo Kim
ETRI
Efficient Linear Skyline Algorithm in Two-Dimensional Space
1. 계산에 사용되는개념 정리
1.1) 지배(dominance)
2
1) 정의
2) 예시
튜플 p가 모든 속성에 대해서 튜플 q보다 작거나 같고, 최소한 하나의 속성에 대해서 p
가 q보다 작을 경우(∀𝐴𝑖 ∈ 𝐴: 𝑝𝑖 ≤ 𝑞𝑖 ∧ ∃𝐴𝑗 ∈ 𝐴: 𝑝𝑗 < 𝑝𝑗), p는 q를 지배 (p ≺ q)한다고
한다.
• p(2,2), q(2,1)
• p(1,10), q(11,12)
4.
1. 계산에 사용되는개념 정리
1.2) 스카이라인(skyline)
3
1) 정의
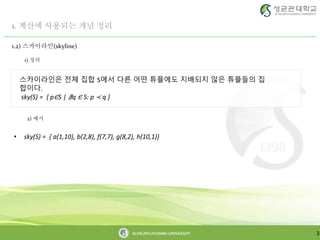
2) 예시
스카이라인은 전체 집합 S에서 다른 어떤 튜플에도 지배되지 않은 튜플들의 집
합이다.
sky(S) = { p∈S | ∄q ∈ S: p ≺ q }
• sky(S) = { a(1,10), b(2,8), f(7,7), g(8,2), h(10,1)}
5.
1. 계산에 사용되는개념 정리
1.2) 스카이라인(skyline)
4
3) 특징
장점 : 단조 증가 형태의 선호도 함수에 대해서 가장 선호되는 후보 집합을 제공
단점 : 속성들이 반상관 관계 이거나 속성의 수가 증가할 경우 스카이라인 질의
결과가 지나치게 증가한다.
6.
1. 계산에 사용되는개념 정리
1.3) 선형 스카이라인(linear skyline)
5
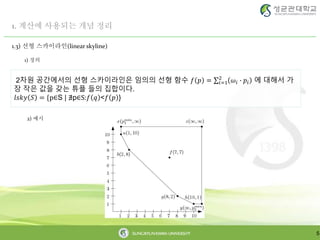
1) 정의
2) 예시
2차원 공간에서의 선형 스카이라인은 임의의 선형 함수 𝑓 𝑝 = 𝑖=1
2
𝜔𝑖 ∙ 𝑝𝑖 에 대해서 가
장 작은 값을 갖는 튜플 들의 집합이다.
𝑙𝑠𝑘𝑦 𝑆 = {p∈S | ∄p∈S:𝑓 𝑞 <𝑓 𝑝 }
2. 기존 선형스카이라인 알고리즘
2.1) 가상 튜플을 이용해 스카이라인 구하기
7
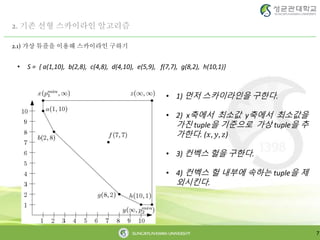
• S = { a(1,10), b(2,8), c(4,8), d(4,10), e(5,9), f(7,7), g(8,2), h(10,1)}
• 1) 먼저 스카이라인을 구한다.
• 2) x축에서 최소값 y축에서 최소값을
가진 tuple을 기준으로 가상 tuple을 추
가한다. (𝑥, 𝑦, 𝑧)
• 3) 컨벡스 헐을 구한다.
• 4) 컨벡스 헐 내부에 속하는 tuple을 제
외시킨다.
9.
2. 기존 선형스카이라인 알고리즘
2.2) 컨벡스헐 계산
8
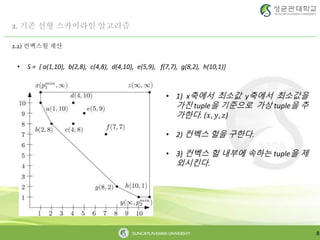
• S = { a(1,10), b(2,8), c(4,8), d(4,10), e(5,9), f(7,7), g(8,2), h(10,1)}
• 1) x축에서 최소값 y축에서 최소값을
가진 tuple을 기준으로 가상 tuple을 추
가한다. (𝑥, 𝑦, 𝑧)
• 2) 컨벡스 헐을 구한다.
• 3) 컨벡스 헐 내부에 속하는 tuple을 제
외시킨다.
10.
2. 기존 선형스카이라인 알고리즘
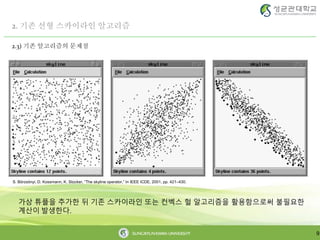
2.3) 기존 알고리즘의 문제점
9
가상 튜플을 추가한 뒤 기존 스카이라인 또는 컨벡스 헐 알고리즘을 활용함으로써 불필요한
계산이 발생한다.
S. Börzsönyi, D. Kossmann, K. Stocker, “The skyline operator,” In IEEE ICDE, 2001, pp. 421–430.
3. 제안 알고리즘QuickLS
3.0) 선형 스카이라인 특징
1) 정리
11
다른 튜플에 의해 지배되지 않으면서 속성 𝐴1에서 가장 큰 값을 갖는 튜플 p 는 속성 𝐴2
에서 최솟값을 가진다. 즉, p= 𝑎𝑟𝑔𝑚𝑎𝑥 𝑞∈𝑠𝑘𝑦(𝑆) 𝑞1이면 p= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑞∈𝑆 𝑞2을 만족한다.
13.
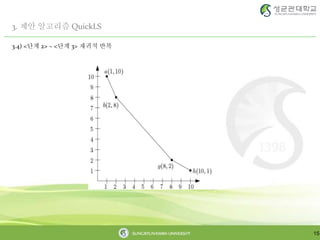
3. 제안 알고리즘QuickLS
3.1) <단계 1>
12
• S = { a(1,10), b(2,8), c(4,8), d(4,10), e(5,9), f(7,7), g(8,2), h(10,1)}
1. x축에서 최소값 y축에서 최소값을 가진 tuple을 이어 선을 긋는다. 만약 두 점이 같은
경우 skyline은 1개 이므로 종료한다.
2. 다음 단계 함수를 호출한다.(이 함수는 재귀적으로 작동한다.)
14.
3. 제안 알고리즘QuickLS
3.2) <단계 2>
13
• S = { a(1,10), b(2,8), c(4,8), d(4,10), e(5,9), f(7,7), g(8,2), h(10,1)}
1. 이전 단계에서 추가한 line 의 위쪽, 즉 dominated 되는 tuple들을 제거한다.
2. line에 속하지 않은 tuple이 없는 경우 종료한다.
15.
3. 제안 알고리즘QuickLS
3.3) <단계 3>
14
• S = { a(1,10), b(2,8), c(4,8), d(4,10), e(5,9), f(7,7), g(8,2), h(10,1)}
1. 남아 있는 tuple 중에서 line에서 먼 tuple 부터 선택하고 남은 tuple 집합에서 제거한다.
2. 이전 line의 2개의 각 tuple과 연결하여 2개의 라인을 만들고 각 라인에 대해서 단계 2-
3을 반복한다.
4. 실험
4.1) 실험환경
Algorithm
• SSkyline : 스카이라인 알고
리즘
• QHULL : 컨벡스 헐 알고리
즘
• BSHELL : 기존 스카이라인
알고리즘 1
• BSHELL2 : QHULL을 이용
한 기존 스카이라인 알고리
즘2
• QuickLS : 제안한 알고리즘
HW / SW
• 언어 : C++
• 컴파일러 : g++ (-O3 옵션)
• HW : Intel Xeon E5-2630V
3 2.4GHz, 64GB RAM
• OS : Ubuntu 14.04
Data
• 스카이라인 알고리즘의 성
능을 측정하는데 주로 사용
되는 독립(independent) 또
는 반상관 분포를 고려
• 데이터는 1M, 2M, 4M, 8M,
16M 크기의 합성 데이터
(synthetic data)를 이용
17
19.
4. 실험
4.2) 실험결과
18
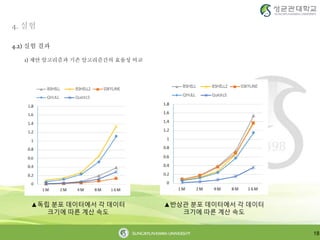
1) 제안 알고리즘과 기존 알고리즘간의 효율성 비교
▲독립 분포 데이터에서 각 데이터
크기에 따른 계산 속도
▲반상관 분포 데이터에서 각 데이터
크기에 따른 계산 속도
20.
4. 실험
4.2) 실험결과
19
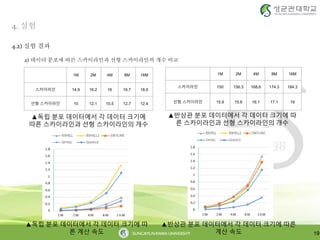
2) 데이터 분포에 따른 스카이라인과 선형 스카이라인의 개수 비교
1M 2M 4M 8M 16M
스카이라인 150 156.3 168.6 174.3 184.3
선형 스카이라인 15.9 15.6 16.1 17.1 19
1M 2M 4M 8M 16M
스카이라인 14.9 16.2 16 16.7 18.6
선형 스카이라인 10 12.1 10.5 12.7 12.4
▲반상관 분포 데이터에서 각 데이터 크기에 따
른 스카이라인과 선형 스카이라인의 개수
▲독립 분포 데이터에서 각 데이터 크기에
따른 스카이라인과 선형 스카이라인의 개수
▲독립 분포 데이터에서 각 데이터 크기에 따
른 계산 속도
▲반상관 분포 데이터에서 각 데이터 크기에 따른
계산 속도





























![[데브루키]노대영_알고리즘 스터디](https://cdn.slidesharecdn.com/ss_thumbnails/devrookiealgorithm-180926091907-thumbnail.jpg?width=640&height=640&fit=bounds)

![[SOPT] 데이터 구조 및 알고리즘 스터디 - #01 : 개요, 점근적 복잡도, 배열, 연결리스트](https://cdn.slidesharecdn.com/ss_thumbnails/1-150824001021-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[TAOCP] 2.2.3 연결된 할당 - 위상정렬](https://cdn.slidesharecdn.com/ss_thumbnails/taocp2-2-3-110422163538-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















![[이산수학]4 관계, 함수 및 행렬](https://cdn.slidesharecdn.com/ss_thumbnails/4-100318103220-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 CAMPUS] 2016 한양대학교 프로그래밍 경시대회 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/random-161228045003-thumbnail.jpg?width=640&height=640&fit=bounds)





![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)