소재데이터 AI 실습 최종보고서_ks0014_김영기.pdf
1.
KRISS 소재데이터 구축사업(구조안전소재데이터센터)
소재데이터 AI실습 최종보고서
(10.1016/j.mtcomm.2020.101897)
작성자 : 김영기( KS0014 )
제출일 : 2021년 5월 21일
2.
목 차
제 1장 실습 목적 및 사용 프로그램
§ 제 1 절 실습 목적
1. 실습목적
2. 실습 데이터
§ 제 2 절 사용 프로그램
1. 사용 프로그램
2. ASCENDS 설치 과정
제 2 장 데이터 구조 분석 및 이상치 제거
§ 제 1 절 데이터 구조
1. 데이터 컬럼 구조
§ 제 2 절 데이터 이상치 정의 및 제거 필요성
1. 데이터 이상치 정의
2. 데이터 이상치 제거의 필요성
§ 제 3 절 데이터 이상치 탐색 및 제거
1. 사용할 알고리즘
2. LOF 알고리즘 선택 이유
3. LOF 알고리즘 설명
4. DMwN 패키지 - lofactor 함수
5. R Studio를 활용한 LOF값 탐색 및 제거
§ 제 4 절 데이터 이상치 시각화
1. 데이터 이상치 시각화
2. 데이터 이상치 시각화 결과
§ 제 5 절 Training, Testing Dataset 생성
1. 중복되는 데이터 확인
2. Trainging Data, Testing Data 생성
제 3 장 Feature Selection
§ 제 1 절 Feature Selection의 필요성
1. Feature Selection의 필요성
§ 제 2 절 Feature Selection의 종류
1. Wrapper method
2. Filter method
3. Embedded method
§ 제 3 절 Filter method를 통한 Linear Feature Selection
1. Filter 기준
2. PCC분석
3. 선택된 Feature
§ 제 4 절 Wrapper method를 통한 non-Linear Feature
Selection
1. 비선형 데이터를 Wrapper로 선택하는 이유
2. PCC분석
3. 산점도 행렬을 통한 비선형성 확인
4. default Subset
5. Wrapper 결과
제 4 장 모델 학습 및 최적화
§ 제 1 절 모델 학습
1. ASCENDS 지원하는 알고리즘
2. 데이터와 적합한 알고리즘 확인
§ 제 2 절 모델 최적화
1. Feature Selection으로 선택된 컬럼 학습
2. Input 컬럼 최적화
3. 최적화 결과
제 5 장 모델 평가
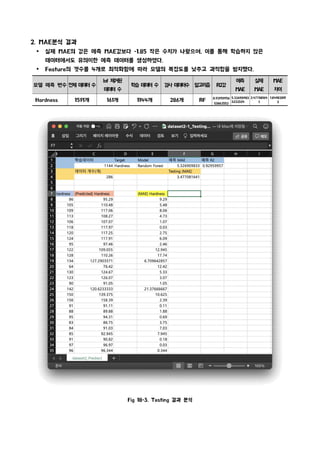
§ 제 1 절 10.1016/j.mtcomm.2020.101897 모델 평가
1. 모델 상세 정보
2. MAE 분석 결과
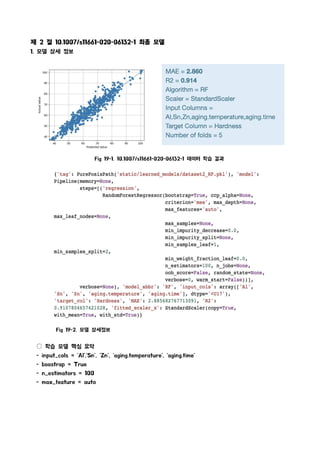
§ 제 2 절 10.1007/s11661-020-06132-1 모델 평가
1. 모델 상세 정보
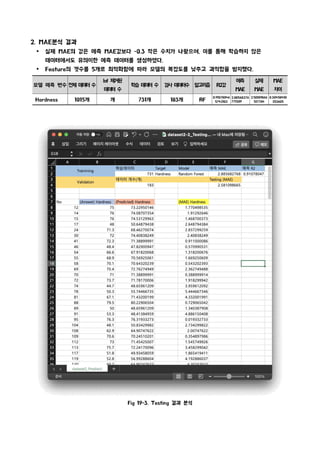
2. MAE 분석 결과
3.
번호 논문 제목논문 DOI 엑셀파일명
1
Machine learning-aided design of aluminum
alloys with high performance
10.1016/j.mtcomm.2020.101897
2020_Mater Today Comm_ML-aided design of Al
alloys with high performance.xlsx
2
Accelerated Development of High-Strength
Magnesium Alloys by Machine Learning
10.1007/s11661-020-06132-1
2021_MMTA_Accelerated development of
high-strength Mg alloys by ML_Suppl.xlsx
제 1 장 실습 목적 및 사용 프로그램
제 1 절 실습 목적
1. 실습목적
Ÿ 구조�
안전 소재 데이터와 인공지능모델을 활용한 소재 특성 예측
2. 실습 데이터
Ÿ set2 폴더의 논문 중 2개 선택하여 동일한 프로세스를 통해 각가 모델을 생성했음
Ÿ 해당 보고서에서는 Machine learning-aided design of aluminum alloys with high performance
1번 데이터를 기준으로 작성하였으며, 2번 데이터는 최종결과만 작성하였음.
제 2 절 사용 프로그램
1. 사용 프로그램
사용 목적 프로그램 사용 함수
PCC 분석 파이썬 pandas 패키지 corr()
PCC 분석 시각화
파이썬 seaborn 패키지 heatmap()
파이썬 matplotlib.pyplot 패키지 plt()
T r a i n i n g , T e s t i n g
dataset 생성
java Collections라이브러리 shuffle()
데이터 이상치 탐지
R Studio 4.0.5
R의 DMwR 패키지 lofactor()
모델 학습 ASCENDS 프로그램
4.
2. ASCENDS 설치과정
Ÿ 시스템 OS - MAC OS
1. ANACONDA 설치
1. ANACONDA 다운로드 및 설치
https://www.anaconda.com/products/individual
2. 설치확인 명령어
$ conda --version
2. ASCENDS 설치
1. ASCENDS 다운로드
깃허브에서 다운로드 방법 : https://github.com/ornlpmcp/ASCENDS
터미널에서 다운로드 방법 : 아래 명령어 입력
$ git clone https://github.com/ornlpmcp/ASCENDS.git
2. ASCENDS 설치
터미널에서 ASCENDS 폴더로 이동 후 아래 명령어 입력
$ conda env create -f environment.yml --name ascends
3. ASCENDS 명령어
1. 가상환경 실행
$ conda activate acsends
2. 도움말
$ python train.py --help
3. GUI 서버 실행
$ python ascends_server.py
4. 가상환경 종료
$ conda deactivate
5.
제 2 장데이터 구조 분석 및 이상치 제거
제 1 절 데이터 구조
1. 데이터 컬럼 구조
Ÿ 파일명 - 2020_Mater Today Comm_ML-aided design of Al alloys with high performance.xlsx
Ÿ 전체 Column 개수 - 34개
column 번호 column 구분
col 0 Target property
col 1 ~ col 16 Compositions
co 17 ~ col 33 Features
Table1-1. Data columns
col 0
Hardness
Table1-2. Taget
property
col 1 col 2 col 3 col 4 col 5 col 6 col 7 col 8 col 9 col10 col11 col12 col13 col14 col15 col16
Al Cu Mg Si Zn Zr Mn Ag Li Ca Fe Ti Sn Cr Ge Sc
Table1-3. Compositions
col 17 col 18 col 19 col 20 col 21 col 22 col 23 col 24 col 25
EN VE
Atomic
number
mass
Melting
point
Boiling
point
Density
Electroaffi
nity
F u s i o n
heat
col 26 col 27 col 28 col 29 col 30 col 31 col 32 col 33
atomic
radius
S p e c f i c
heat
Heat of
Vaporizatio
n
thermal
conductivit
y
group period
T i m e
(min)
Temeartur
e (K)
Table1-4. Features
6.
제 2 절데이터 이상치 정의 및 제거 필요성
1. 데이터 이상치 정의
Ÿ 통계에서 이상치는 다른 관측치와 크게 다른 데이터를 말한다.
Ÿ 일반적인 데이터 패턴과 다른 상이한 패턴을 가지고 있는 데이터를 말한다.
2. 데이터 이상치 제거의 필요성
Ÿ 일반적인 데이터와 이상한 패턴을 가지고 있어 머신러닝과 딥러닝시 이상치 데이터로 인해 모델의 성능이
저하될 가능성이 있다.
Ÿ 이상치 데이터를 제거함으로써 모델의 성능을 향상시킬 수 있다.
제 3 절 데이터 이상치 탐색 및 제거
1. 사용할 알고리즘
Ÿ LOF(Local outlier factors)
2. LOF 알고리즘 선택 이유
Ÿ 분석해야 될 데이터는 일반적인 통계적 분석을 통해 이상치 판별이 어렵다
Ÿ IQR 이상치 제거 방식으로 제거할 경우 3~40%정도의 데이터 손실이 발생할 수 있다
3. LOF 알고리즘 설명
Ÿ LOF는 각각의 관측치가 데이터 안에서 얼마나 벗어나 있는가에 대한 정도(이상치 정도)를 나타낸다.
LOF의 가장 중요한 특징은 모든 데이터를 전체적으로 고려하는 것이 아니라,
해당 관측치의 주변 데이터(neighbor)를 이용하여 국소적(local) 관점으로 이상치 정도를 파악하는 것이다
Ÿ k 하이퍼-파라미터(hyper-parameter)를 통해 주변 데이터의 국소적 관점의 범위를 결정할 수 있다.
Fig1. LOF 분석 시각화 예시
Fig2. local outlier factor(LOF) of an object p
7.
Fig3. DMwN의 lofactor함수사용법
4. DMwN 패키지 - lofactor 함수
5. R Studio를 활용한 LOF값 탐색 및 제거
Ÿ K=10으로 설정함
Ÿ 상위 10%의 LOF값을 제거
Fig4-1. LOF값 index number
# dataframe에서 3가지 columns만 선택 추출
>dataset_lof <- dataset %>% select(Hardness, Time.min., Temearture.K.)
# lof 알고리즘 적용, k=10
> outlier.scores <- lofactor(dataset_lof, k=10)
# 상위 10% lof값을 가지는 outlier 값 선택
> Top10percent <- order(outlier.scores, decreasing = T)[1:160]
# 기존 dataset에서 lof값 제거
> lof_df <- dataset[-Top10percent,]
# 제거한 lof값 CSV로 저장
> write.csv(lof_df, "/Users/dudrl0944/Documents/GitHub/ASCENDS/2nd/lof_dataset.csv")
Fig4-2. 생성된 CSV파일
8.
# 총 데이터행 개수 저장
> n <- nrow(dataset_lof)
# 1~n개의 labels 생성
> labels <- 1:n
# 상위 10% 값을 제외한 나머지 '.' 값으로 변경
> labels[-Top10percent] <- "."
# 색상 설정 / outlier는 빨간색, 정상데이터는 검정색
> col <- rep("black",n)
> col[Top10percent] <- "red"
# 기호 설정 / outliere는 "+", 정상데이터는 "."
> pch[Top10percent] <- "+"
Fig5-1. labels[-Top10percent] <- "." 실행 결과
Fig5-2. pch[Top10percent] <- "+" 실행 결과
Fig5-3. col[Top10percent] <- "red" 실행 결과
제 4 절 데이터 이상치 시각화
1. 데이터 이상치 시각화
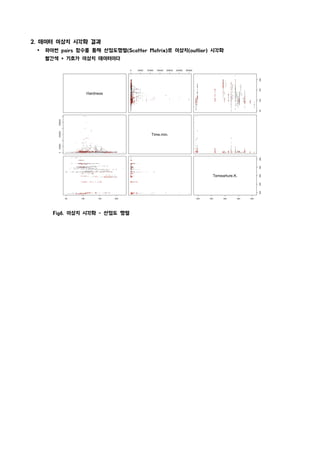
Ÿ 파이썬 pairs 함수를 통해 산점도행렬(Scatter Matrix)로 이상치(outlier) 시각화를 했다
9.
2. 데이터 이상치시각화 결과
Ÿ 파이썬 pairs 함수를 통해 산점도행렬(Scatter Matrix)로 이상치(outlier) 시각화
빨간색 + 기호가 이상치 데이터이다
Fig6. 이상치 시각화 - 산점도 행렬
10.
제 5 절Training, Testing Dataset 생성
1. 중복되는 데이터 확인
Ÿ 중복되는 행이 존재하는 상태로 Training시 과적합(overfitting)이 발생할 수 있다.
Ÿ SHA-256 해시 함수를 통해 해시값을 생성하고 엑셀에서 중복되는 해시값이 존재하는지 확인하는 방법으로
중복되는 행의 여부를 파악했다.
Ÿ 확인 결과 - 중복되는 행 존재하지 않음
Fig 7. SHA-256 해시함수를 통해 중복되는 데이터 행 검사 코드
2. Trainging Data, Testing Data 생성
Ÿ Training Data 80%, Testing Data 20%를 기준으로 Java-Collections 라이브러리의 Shuffle함수를 사용
Ÿ 3회 Shuffle 후 80%, 20% 비율로 데이터 셋 생성
전체 데이터 행 개수 1430개
Training Dataset 행 개
수
1144개
Testing Dataset 행 개수 286개
Table 2. 데이터셋 생성 결과
Fig 8-1. Training, Testing 생성 핵심 코드
Fig 8-2. Training Dataset
Fig 8-3. Testing Dataset
11.
제 3 장Feature Selection
제 1 절 Feature Selection의 필요성
1. Feature Selection의 필요성
Ÿ 모델 학습 시, 상관이 없는 변수들이 존재할 경우 computational cost가 증가하고 과적합(overfitting)이
발생할 확률이 증가한다.
Ÿ Feature Selection의 주된 목적은 독립 변수중에서, 중복되거나 종속변수 (Y)와 관련이 없는 변수들을
제거하여, Y를 가장 잘 예측하는 변수들의 조합을 찾아내는 것이다
제 2 절 Feature Selection의 종류
1. Wrapper method
Ÿ Wrapper는 예측 모델을 사용하여 피처들의 부분 집합을 만들어 계속 테스트 하여 최적화된 피처들의
집합 만드는 방법이다.
Ÿ 대표적인 Wrapper 방법
Forward Greedy
Backward Greedy
Genetic Search
Local Search
Fig 9-1. Wrapper Method Process
2. Filter method
Ÿ Filtering은 사전적 의미 처럼 도움이 되지 않는 피처들을 걸러내는 작업을 말한다. 통계적인 측정 방법을
이용하여 피처들의 상관관계를 알아내고 적합한 피처들만 선택하여 알고리즘에 적용하는 방식이다.
Ÿ 대표적인 Filter 방법
t-test
chi-square test
Information Gain
Correlation coefficient - Pearson, Spearman
Fig 9-2. Filter Method Process
12.
3. Embedded method
ŸEmbedded는 Filtering과 Wrapper의 장점을 결함한 방법으로 학습 알고리즘 자체에 feature selection을
넣는 방식이다.
Ÿ 대표적인 Embedded 방법
LASSO = L1 regularisation
RIDGE = L2 regularisation
Fig 9-3. Embedded Method Process
제 3 절 Filter method를 통한 Linear Feature Selection
1. Filter 기준
Ÿ 데이터를 Composition과 physical feature로 나눠, 각각 상위 4개의 feature 선택
2. PCC 분석
Fig 10-1. Compositions PPC결과 Fig 10-2. feature PPC결과
3. 선택된 Feature
Ÿ Composition - Al, Mg, Zr, Zn 선택
Ÿ Physical feature - Specific heat, VE, Atomic number, mass 선택
13.
Melting point electroaffinitythermal conductivity group Time(min) Temearture(K)
제 4 절 Wrapper method를 통한 Non-Linear Feature Selection
1. 비선형 데이터를 Wrapper로 선택하는 이유
Ÿ 비선형 데이터의 경우 통계적 분석을 통해 Feature와 Target column의 연관성을 파악하기 어렵기 때문에
Subset을 생성해 학습된 모델의 결과를 통해 비선형 feature와 Target 컬럼의 연관성을 쉽게 파악할 수 있다.
2. PCC 분석
Ÿ Hardness와 비선형 관계로 추측되는 6개 feature
Fig 11. Physical Feature PCC, heatmap을 통한 시각화
3. 산점도 행렬을 통한 비선형성 확인
Fig 12. 산점도 행렬(Scatter Matrix)를 통한 비선형성 확인
14.
Subset 목록 MAER2
default subset MAE = 12.134 R2 = 0.720
default subset + Temearture (K) MAE =11.324 R2 =0.763
default subset + Time (min) MAE =7.922 R2 =0.833
default subset + thermal conductivity MAE =12.218 R2 =0.715
default subset + group MAE =12.268 R2 =0.712
default subset + Electroaffinity MAE =12.225 R2 =0.715
Table 3-2. Wrapper 결과
4. default Subset
Ÿ default Subset에 비선형성을 가지는 특징을 하나씩 추가 후 모델을 학습 후 R2의 결과값으로
Hardness(Target Column)과의 연관성을 파악한다.
Ÿ default Subset feature
EN, VE, Atomic number, mass, Boiling point, Density, Fusion heat, atomic radius,
Specfic heat, Heat of Vaporization, period
Ÿ 비교할 Subset
Subset 목록
default subset
default subset + Temearture (K)
default subset + Time (min)
default subset + thermal conductivity
default subset + group
default suset + Electroaffinity
Table 3-1. 비교할 Subset 목록
5. Wrapper 결과
Fig 13. Wrapper 결과 - R2 변화량
Ÿ Temearture(K)와 Time(min)은 non-linear한 속성이지만 Hardness 결정에 영향을
미치는 속성임을 알 수 있다.
Ÿ 금속공학의 관점에서 보더라도 온도와 시간은 금속의 속성을 결정짓는 중요한 속성임을 직관적으로
알 수 있으며, 데이터 분석에서도 이런 관계성을 확인 할 수 있었다.
15.
제 4 장모델 학습 및 최적화
제 1 절 모델 학습
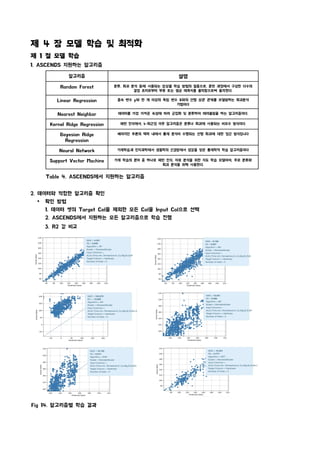
1. ASCENDS 지원하는 알고리즘
알고리즘 설명
Random Forest 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의
결정 트리로부터 부류 또는 평균 예측치를 출력함으로써 동작한다.
Linear Regression 종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관계를 모델링하는 회귀분석
기법이다
Nearest Neighbor 데이터를 가장 가까운 속성에 따라 군집화 및 분류하여 레이블링을 하는 알고리즘이다.
Kernel Ridge Regression 패턴 인식에서, k-최근접 이웃 알고리즘은 분류나 회귀에 사용되는 비모수 방식이다.
Bayesian Ridge
Regression
베이지안 추론의 맥락 내에서 통계 분석이 수행되는 선형 회귀에 대한 접근 방식입니다
Neural Network 기계학습과 인지과학에서 생물학의 신경망에서 영감을 얻은 통계학적 학습 알고리즘이다
Support Vector Machine 기계 학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와
회귀 분석을 위해 사용한다.
Table 4. ASCENDS에서 지원하는 알고리즘
2. 데이터와 적합한 알고리즘 확인
Ÿ 확인 방법
1. 데이터 셋의 Target Col을 제외한 모든 Col을 Input Col으로 선택
2. ASCENDS에서 지원하는 모든 알고리즘으로 학습 진행
3. R2 값 비교
Fig 14. 알고리즘별 학습 결과
16.
제 2 절모델 최적화
1. Feature Selection으로 선택된 컬럼 학습
Ÿ Feature Selection을 통해 선형 feature 8개와 비선형 feature 2개를 선택했다.
Ÿ 10개의 Feature을 통해 학습한 결과와 34개의 Feature을 통해 학습한 결과에 차이가 없었다.
Fig 15-1. Feature Selection을 통해 선택한 feature PCC 결과
Fig 15-2. Feature selection 후 RF학습 결과
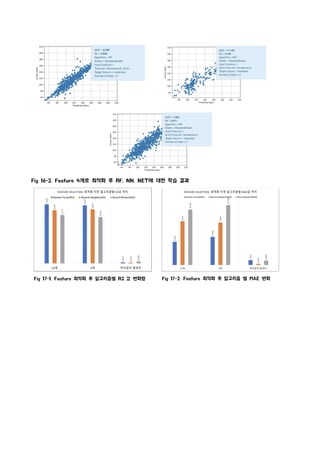
2. Input 컬럼 최적화
Ÿ 10개의 속성을 조합하여 다양한 subset을 생성하고 최소한의 속성으로
R2값을 예측할 수 있는 subset을 생성했다.
3. 최적화 결과
Ÿ Zn, Al, Time(min), Temearture(K) 4개의 Input columns과 Random forest 알고리즘을 통해
학습한 모델이 최적의 성능을 보여주었다.
Fig 16-1. Feature 4개로 최적화 후 PCC 결과 Fig 16-1. Random Forest 학습 결과
17.
Fig 16-2. Feature4개로 최적화 후 RF, NN, NET에 대한 학습 결과
Fig 17-1. Feature 최적화 후 알고리즘별 R2 값 변화량 Fig 17-2. Feature 최적화 후 알고리즘 별 MAE 변화
18.
Fig 18-1. 10.1016/j.mtcomm.2020.101897데이터 학습 결과
제 5 장 모델 평가
제 1 절 10.1016/j.mtcomm.2020.101897 최종 모델
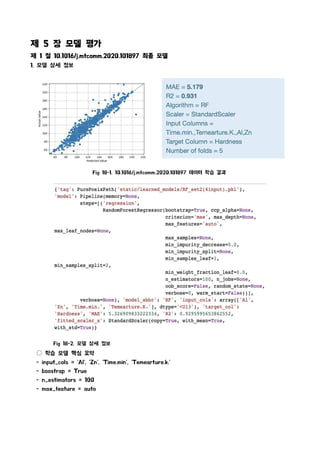
1. 모델 상세 정보
Fig 18-2. 모델 상세 정보
○ 학습 모델 핵심 요약
- input_cols = 'Al', 'Zn', 'Time.min', 'Temearture.k.'
- boostrap = True
- n_estimators = 100
- max_feature = auto
19.
Fig 18-3. Testing결과 분석
2. MAE분석 결과
Ÿ 실제 MAE의 값은 예측 MAE값보다 -1.85 작은 수치가 나왔으며, 이를 통해 학습하지 않은
데이터에서도 유의미한 예측 데이터를 생성하였다.
Ÿ Feature의 갯수를 4개로 최적화함에 따라 모델의 복잡도를 낮추고 과적합을 방지했다.
모델 예측 변수 전체 데이터 수
lof 제거된
데이터 수
학습 데이터 수 검사 데이터수 알고리즘 R2값
예측
MAE
실제
MAE
MAE
차이
Hardness 1591개 161개 1144개 286개 RF 0.92959956
53862552
5.32690983
3222334
3.47708164
1
1.84982819
3
20.
Fig 19-1. 10.1007/s11661-020-06132-1데이터 학습 결과
제 2 절 10.1007/s11661-020-06132-1 최종 모델
1. 모델 상세 정보
Fig 19-2. 모델 상세정보
○ 학습 모델 핵심 요약
- input_cols = 'Al','Sn', 'Zn', 'aging.temperature', 'aging.time'
- boostrap = True
- n_estimators = 100
- max_feature = auto
21.
Fig 19-3. Testing결과 분석
2. MAE분석 결과
Ÿ 실제 MAE의 값은 예측 MAE값보다 -0.3 작은 수치가 나왔으며, 이를 통해 학습하지 않은
데이터에서도 유의미한 예측 데이터를 생성하였다.
Ÿ Feature의 갯수를 5개로 최적화함에 따라 모델의 복잡도를 낮추고 과적합을 방지했다.
모델 예측 변수 전체 데이터 수
lof 제거된
데이터 수
학습 데이터 수 검사 데이터수 알고리즘 R2값
예측
MAE
실제
MAE
MAE
차이
Hardness 1015개 개 731개 183개 RF
0.91078046
5742102
2.88568276
771309
2.58109866
517704
0.30458410
253605






![Fig3. DMwN의 lofactor함수 사용법
4. DMwN 패키지 - lofactor 함수
5. R Studio를 활용한 LOF값 탐색 및 제거
Ÿ K=10으로 설정함
Ÿ 상위 10%의 LOF값을 제거
Fig4-1. LOF값 index number
# dataframe에서 3가지 columns만 선택 추출
>dataset_lof <- dataset %>% select(Hardness, Time.min., Temearture.K.)
# lof 알고리즘 적용, k=10
> outlier.scores <- lofactor(dataset_lof, k=10)
# 상위 10% lof값을 가지는 outlier 값 선택
> Top10percent <- order(outlier.scores, decreasing = T)[1:160]
# 기존 dataset에서 lof값 제거
> lof_df <- dataset[-Top10percent,]
# 제거한 lof값 CSV로 저장
> write.csv(lof_df, "/Users/dudrl0944/Documents/GitHub/ASCENDS/2nd/lof_dataset.csv")
Fig4-2. 생성된 CSV파일](https://image.slidesharecdn.com/aiks0014-250506144123-19174eb4/85/AI-_ks0014_-pdf-7-320.jpg)
![# 총 데이터 행 개수 저장
> n <- nrow(dataset_lof)
# 1~n개의 labels 생성
> labels <- 1:n
# 상위 10% 값을 제외한 나머지 '.' 값으로 변경
> labels[-Top10percent] <- "."
# 색상 설정 / outlier는 빨간색, 정상데이터는 검정색
> col <- rep("black",n)
> col[Top10percent] <- "red"
# 기호 설정 / outliere는 "+", 정상데이터는 "."
> pch[Top10percent] <- "+"
Fig5-1. labels[-Top10percent] <- "." 실행 결과
Fig5-2. pch[Top10percent] <- "+" 실행 결과
Fig5-3. col[Top10percent] <- "red" 실행 결과
제 4 절 데이터 이상치 시각화
1. 데이터 이상치 시각화
Ÿ 파이썬 pairs 함수를 통해 산점도행렬(Scatter Matrix)로 이상치(outlier) 시각화를 했다](https://image.slidesharecdn.com/aiks0014-250506144123-19174eb4/85/AI-_ks0014_-pdf-8-320.jpg)






![[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기](https://cdn.slidesharecdn.com/ss_thumbnails/pyconkr2018joeunparksweat-180820041651-thumbnail.jpg?width=640&height=640&fit=bounds)













![[데이터를 부탁해] 비전공자가 데이터 분석가로 거듭나기 by 황준식](https://cdn.slidesharecdn.com/ss_thumbnails/dabopenlecture151120session4-151124081608-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



















