Download to read offline





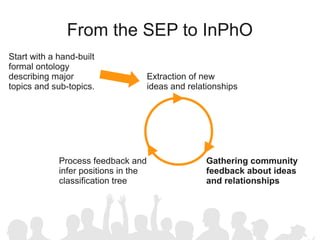
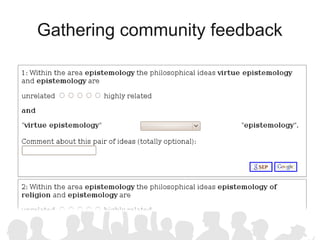


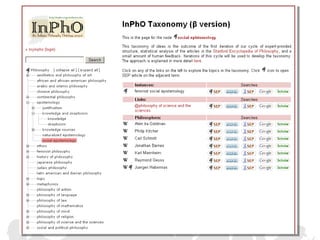



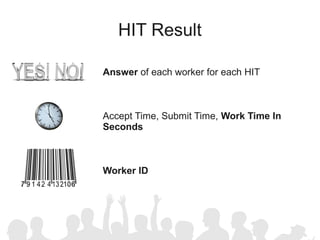



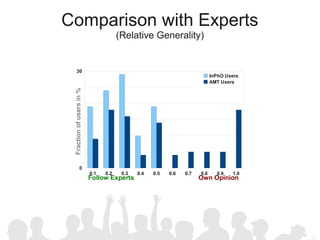
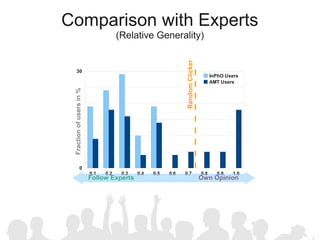
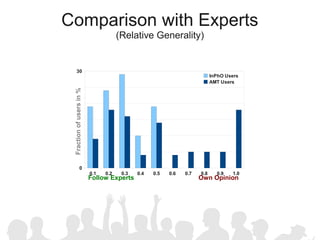
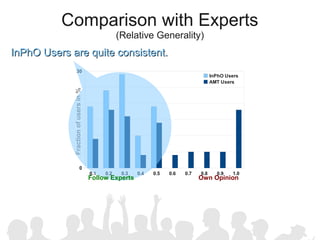
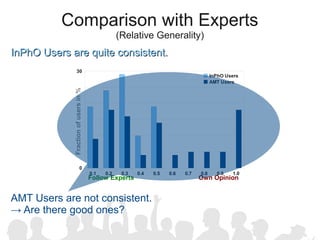
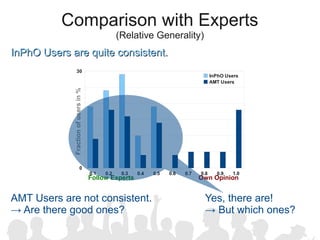
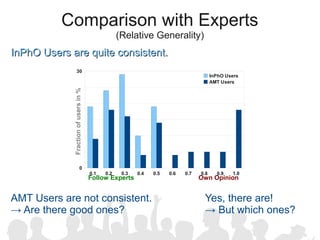


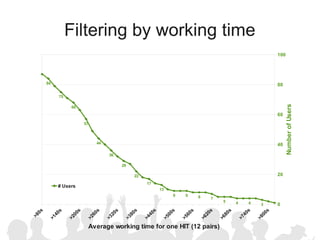
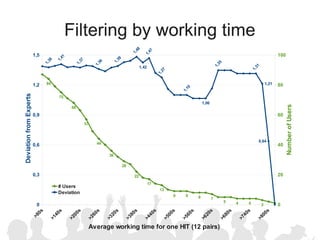


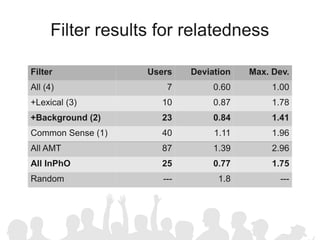
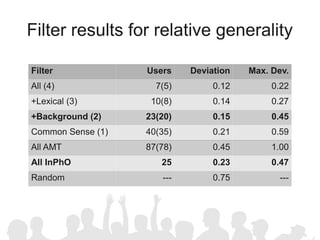
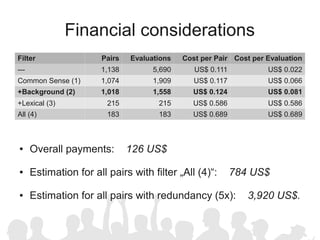




The document discusses crowdsourcing the assembly of concept hierarchies, highlighting the challenges of manual creation and the potential of user contributions through platforms like Amazon Mechanical Turk (AMT). It presents an experimental setup that evaluates the effectiveness and quality of AMT in creating a taxonomy for philosophical ideas, comparing results with those of expert users. The findings indicate that while AMT responses vary in quality, moderate filtering can yield results comparable to a specialized community.




































































