Download as PDF, PPTX































![바이오매스(biomass) 계산
Biomass is biological material derived from living, or recently living organisms[^1]
[^1]: http://en.wikipedia.org/wiki/Biomass
CC-BY-NC-SA http://www.dialogosfederativos.gov.br/?p=1666](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-38-320.jpg)










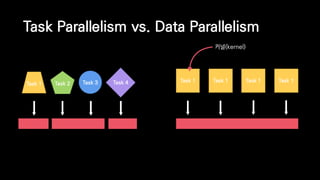





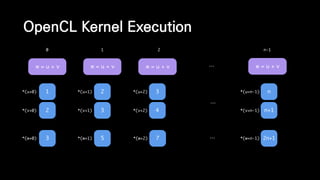
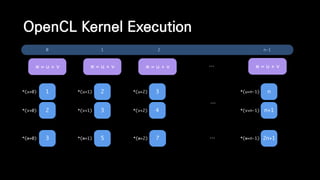
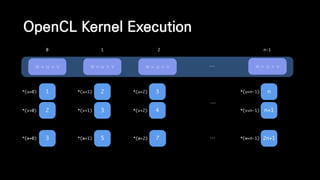
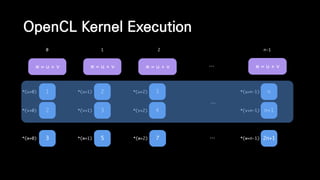
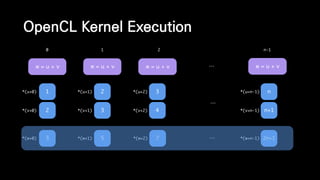
![__kernel void vector_addition(
__global float* w,
__global const float* u,
__global const float* v) {
int i = get_global_id(0);
w[i] = u[i] + v[i];
}
Example of Kernel
1차원 글로벌 인덱스](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-61-320.jpg)
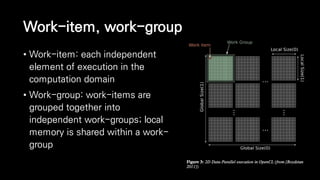

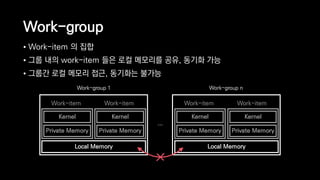
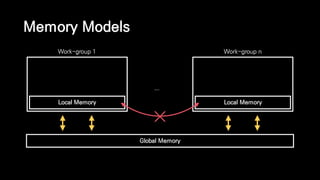
![Memory Models
OpenCL Memory Model (from [Khronos 2011])](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-65-320.jpg)








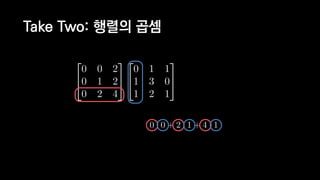
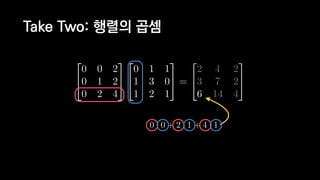
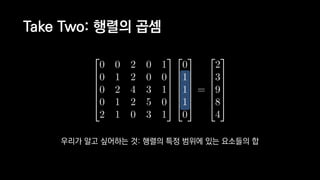
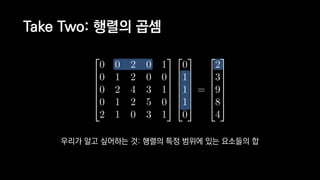
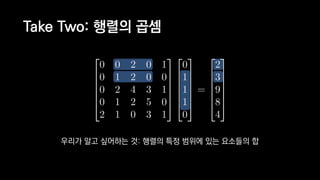
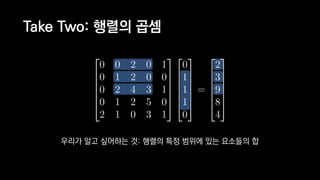
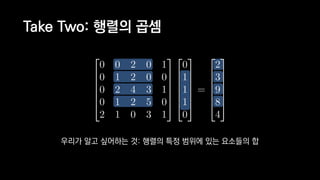
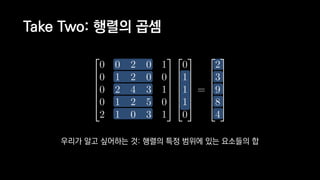
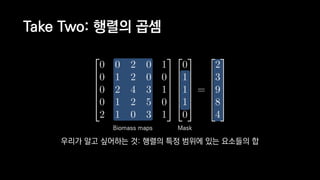
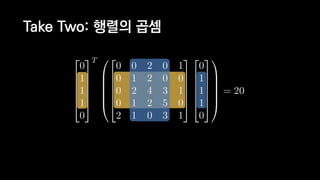
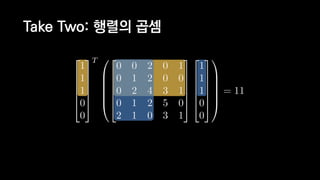
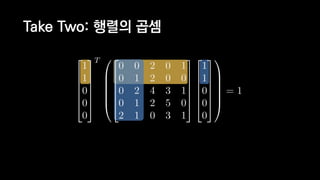
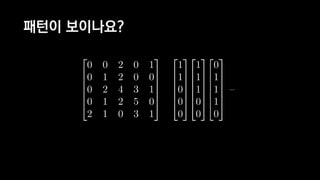
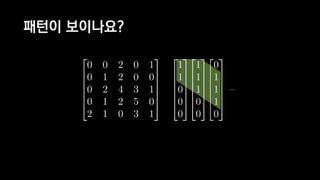
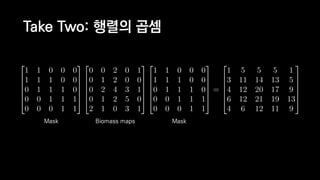
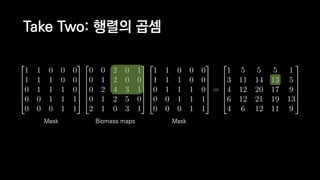
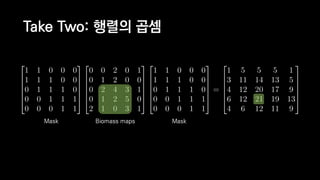





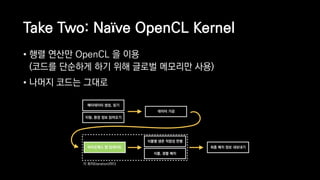
![일반적인 행렬 계산 코드
void matrix_multiplication(float* C, const float* A,
const float* B, const int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
float r = 0;
for (int k = 0; k < n; k++) {
r += A[i * n + k] * B[k * n + j];
}
C[i * n + j] = r;
}
}
}](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-100-320.jpg)
![OpenCL Kernel Code
__kernel void matrix_mul(__global float* C,
__global const float* A,
__global const float* B) {
int tx = get_global_id(0);
int ty = get_global_id(1);
int w = get_global_size(0);
float value = 0;
for (int k = 0; k < w; k++) {
value += A[ty * w + k] * B[k * w + tx];
}
C[ty * w + tx] = value;
}](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-101-320.jpg)
![__kernel void matrix_mul(__global float* C,
__global const float* A,
__global const float* B) {
int tx = get_global_id(0);
int ty = get_global_id(1);
int w = get_global_size(0);
float value = 0;
for (int k = 0; k < w; k++) {
value += A[ty * w + k] * B[k * w + tx];
}
C[ty * w + tx] = value;
}
OpenCL Kernel Code
벡터의 내적(dot product)](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-102-320.jpg)
![OpenCL Kernel Code
__kernel void matrix_mul(__global float* C,
__global const float* A,
__global const float* B) {
int tx = get_global_id(0);
int ty = get_global_id(1);
int w = get_global_size(0);
float value = 0;
for (int k = 0; k < w; k++) {
value += A[ty * w + k] * B[k * w + tx];
}
C[ty * w + tx] = value;
}
2차원 글로벌 인덱스 (x, y)
글로벌 인덱스의 1차원 축 크기
(정방행렬square matrix이므로 2차원 축 크기와 동일)
j
i
글로벌 메모리 사용](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-103-320.jpg)


![#pragma OPENCL EXTENSION cl_khr_fp64 : enable
#define BLOCK_SIZE 32
__kernel void
matrix_mul(__global double* C,
__global double* A,
__global double* B)
{
int bx = get_group_id(0);
int by = get_group_id(1);
int tx = get_local_id(0);
int ty = get_local_id(1);
int size = get_global_size(0);
// Range of sub-matrix A
int a_begin = size * BLOCK_SIZE * by;
int a_end = a_begin + size - 1;
int a_step = BLOCK_SIZE;
// Range of sub-matrix B
int b_begin = BLOCK_SIZE * bx;
int b_step = BLOCK_SIZE * size;
double c_sub = 0;
__local double A_sub[BLOCK_SIZE][BLOCK_SIZE];
__local double B_sub[BLOCK_SIZE][BLOCK_SIZE];
for (int a = a_begin, b = b_begin; a <= a_end;
a += a_step, b += b_step) {
A_sub[ty][tx] = A[a + size * ty + tx];
B_sub[ty][tx] = B[b + size * ty + tx];
barrier(CLK_LOCAL_MEM_FENCE);
for (int k = 0; k < BLOCK_SIZE; k++) {
c_sub += A_sub[ty][k] * B_sub[k][tx];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
int c = size * BLOCK_SIZE * by + BLOCK_SIZE * bx;
C[c + size * ty + tx] = c_sub;
}](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-106-320.jpg)
![Take Three: Optimized OpenCL Kernel
__local double A_sub[BLOCK_SIZE][BLOCK_SIZE];
__local double B_sub[BLOCK_SIZE][BLOCK_SIZE];
로컬 메모리 할당](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-108-320.jpg)
![for (int a = a_begin, b = b_begin; a <= a_end; a += a_step, b += b_step) {
A_sub[ty][tx] = A[a + size * ty + tx];
B_sub[ty][tx] = B[b + size * ty + tx];
barrier(CLK_LOCAL_MEM_FENCE);
for (int k = 0; k < BLOCK_SIZE; k++) {
c_sub += A_sub[ty][k] * B_sub[k][tx];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
Take Three: Optimized OpenCL Kernel
86
부분행렬submatrix 원소들을 채워줌
다른 work-item 들이 작업을 마칠때까지 기다려줌](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-109-320.jpg)
![for (int a = a_begin, b = b_begin; a <= a_end; a += a_step, b += b_step) {
A_sub[ty][tx] = A[a + size * ty + tx];
B_sub[ty][tx] = B[b + size * ty + tx];
barrier(CLK_LOCAL_MEM_FENCE);
for (int k = 0; k < BLOCK_SIZE; k++) {
c_sub += A_sub[ty][k] * B_sub[k][tx];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
Take Three: Optimized OpenCL Kernel
부분행렬의 내적을 구하고
다른 work-item 들이 작업을 마칠때까지 기다려줌](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-110-320.jpg)

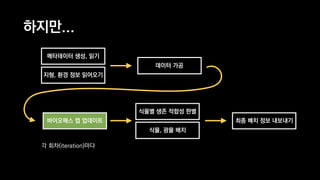
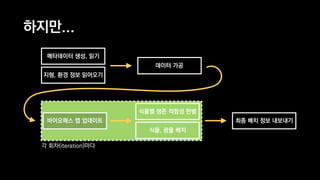

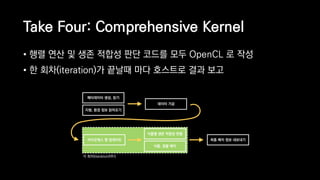



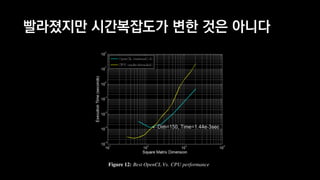
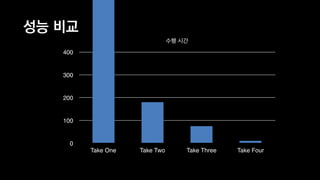
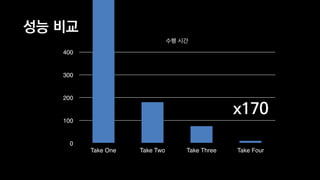





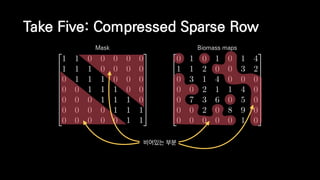
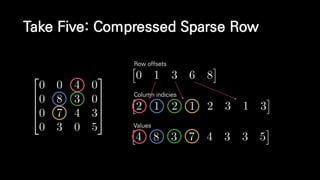
![Take Five: Compressed Sparse Row
using MathNet.Numerics.LinearAlgebra;
using MathNet.Numerics.LinearAlgebra.Double;
Matrix<double> A = SparseMatrix.OfRowMajor(2, 2, new double[] { 1, 2, 3, 4 });
Matrix<double> B = SparseMatrix.OfRowMajor(2, 2, new double[] { 5, 6, 7, 8 });
Matrix<double> C = A * B;](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-129-320.jpg)




![유지보수 어려움
• 프로그래머 구하기 어려움[^1]
• Java - 35,180
• Python - 18,668
• OpenCL - 101
• 코드는 이식 가능하지만, 성능은 이식 불가능
• 메모리 크기에 따른 work-item, work-group 수 제한
• 동시에 실행 가능한 쓰레드의 수
[^1]: LinkedIn 에서 각 키워드로 job posting 검색 결과 수 (2015-05-12)](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-134-320.jpg)
![경제적 타당성 (Financial Viability)
• OpenCL 을 이용해 프로그램 수행 속도를 20% 향상시켰지만 전기세가
두 배로 늘었다면?
• 아마존 웹 서비스(AWS)의 GPU 인스턴스는 꽤 비싼 편[^1]
• 개발 난이도와 코드 유지보수 비용 - 개발자의 시간은 비싸다
[^1]: 2015년 5월 버지니아 데이터센터 기준으로 시간당 $0.65-$2.60, 비슷한 CPU 성능을 가진 다른 인스턴스는 $0.42-$1.68](https://image.slidesharecdn.com/ndc2015-150521082100-lva1-app6891/85/21-OpenCL-135-320.jpg)




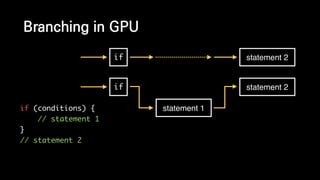



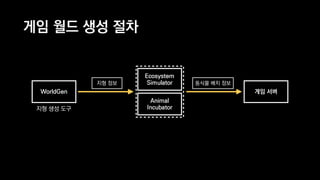
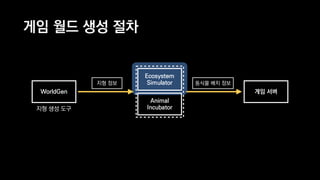
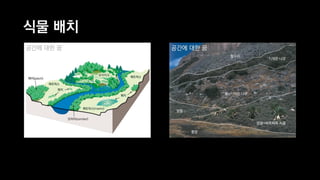
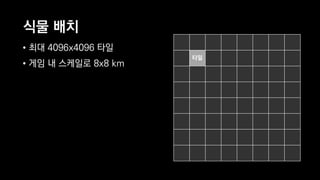
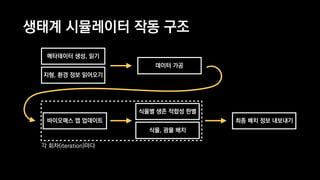
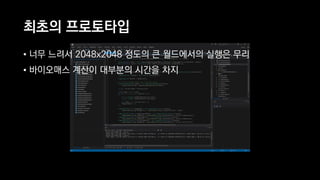
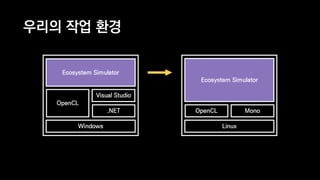
이 발표는 넥슨의 신규 개발 게임인 듀랑고의 생태계에 대한 간략한 소개와 OpenCL 을 이용한 병렬 처리에 관한 전반적인 기술적 내용을 다룹니다. 게임 속의 세계에서 지형과 기후, 지질 조건에 맞게 여러 종류의 식물과 광물들을 알맞은 곳에 배치시키는 것이 생태계 시뮬레이터의 역할인데, 이 시뮬레이터는 방대한 양의 계산을 수행합니다. 초기에 만들어진 프로토타입은 이러한 계산을 수행하는데 30분이 넘게 걸렸지만, 병렬처리, 알고리즘 시간복잡도 개선 등의 여러가지 방법들을 통해 그 시간을 11초까지 단축시켰습니다. 구체적으로 어떤 방법들을 시도했었고, 어떤 방법들이 효과가 있었는지 여러분과 그 경험담을 공유하고자 합니다.

![[NDC14] 모바일 게임의 다음 혁신 - 야생의 땅 듀랑고의 계산 프로세스 중심 게임 디자인](https://cdn.slidesharecdn.com/ss_thumbnails/random-140528073950-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[IGC 2016] 블루사이드 황상훈 - 실전 시나리오 라이팅: PD가 원하면 나는 쓴다](https://cdn.slidesharecdn.com/ss_thumbnails/igc2016final-161008134901-thumbnail.jpg?width=640&height=640&fit=bounds)
![NDC 2015. 한 그루 한 그루 심지 않아도 돼요. 생태학에 기반한 [야생의 땅: 듀랑고]의 절차적 생성 생태계](https://cdn.slidesharecdn.com/ss_thumbnails/zxw42orfsbyogfutmcuz-signature-336dceb59671a895fbf4d561f6799d39719d30f09e04cae133a46c0a8f86264a-poli-150519075553-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[데브루키/141206 박민근] 유니티 최적화 테크닉 총정리](https://cdn.slidesharecdn.com/ss_thumbnails/141206-141207232632-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC2018] 캡콤 토쿠다 유야 - 몬스터헌터 월드의 게임 컨셉과 레벨 디자인](https://cdn.slidesharecdn.com/ss_thumbnails/3-181023023843-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC 2017] 넥슨코리아 오현근 - 평생 게임 기획자 하기](https://cdn.slidesharecdn.com/ss_thumbnails/igc2017in-170905063633-thumbnail.jpg?width=640&height=640&fit=bounds)









![[IGC 2017] 블루홀 최준혁 - '플레이어언노운스 배틀그라운드' DEV 스토리](https://cdn.slidesharecdn.com/ss_thumbnails/igcpubgdevstoryfinalforsharing-170906062941-thumbnail.jpg?width=640&height=640&fit=bounds)

![[0122 구경원]게임에서의 충돌처리](https://cdn.slidesharecdn.com/ss_thumbnails/random-110127021824-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[야생의 땅: 듀랑고] 지형 관리 완전 자동화 - 생생한 AWS와 Docker 체험기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2016-160426115105-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Gpg1권 조진현] 4.16~4.20 실시간 사실적 지형 + 프랙탈](https://cdn.slidesharecdn.com/ss_thumbnails/gpg14-164-20-110628073656-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[0326 박민근] udk 소개 입문](https://cdn.slidesharecdn.com/ss_thumbnails/0326udk-110327215507-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[2B2]기계 친화성을 중심으로 접근한 최적화 기법](https://cdn.slidesharecdn.com/ss_thumbnails/2b2-140929202533-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[D2CAMPUS] Algorithm tips - ALGOS](https://cdn.slidesharecdn.com/ss_thumbnails/algospart1-d2-170223060957-thumbnail.jpg?width=640&height=640&fit=bounds)






![PyCon 2017 프로그래머가 이사하는 법 2 [천원경매]](https://cdn.slidesharecdn.com/ss_thumbnails/pycon20172-170813134610-thumbnail.jpg?width=640&height=640&fit=bounds)











