Downloaded 110 times
![Distributed Shared Memory Paul Krzyzanowski [email_address] [email_address] Distributed Systems Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 License.](https://image.slidesharecdn.com/13-dsm-090902071117-phpapp01/85/Dsm-Distributed-computing-1-320.jpg)
![Distributed Shared Memory Paul Krzyzanowski [email_address] [email_address] Distributed Systems Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 License.](https://image.slidesharecdn.com/13-dsm-090902071117-phpapp01/75/Dsm-Distributed-computing-1-2048.jpg)






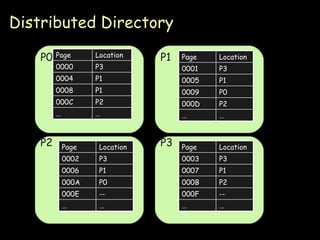












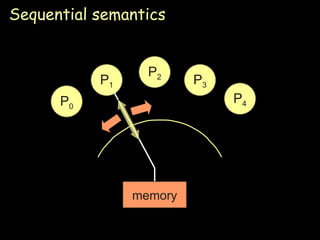














The document summarizes distributed shared memory (DSM), which allows networked computers to share a region of virtual memory in a way that appears local. The key points are: 1) DSM uses physical memory on each node to cache pages of shared virtual address space, making it appear like local memory to processes. 2) On a page fault, a DSM protocol is used to retrieve the requested page from the remote node holding it. 3) Simple designs have a single node hold each page or use a centralized directory, but these can become bottlenecks. Distributed directories and replication improve performance. 4) Consistency models define when modifications are visible, from strict sequential consistency to more relaxed models like release consistency.








































































































