Downloaded 65 times




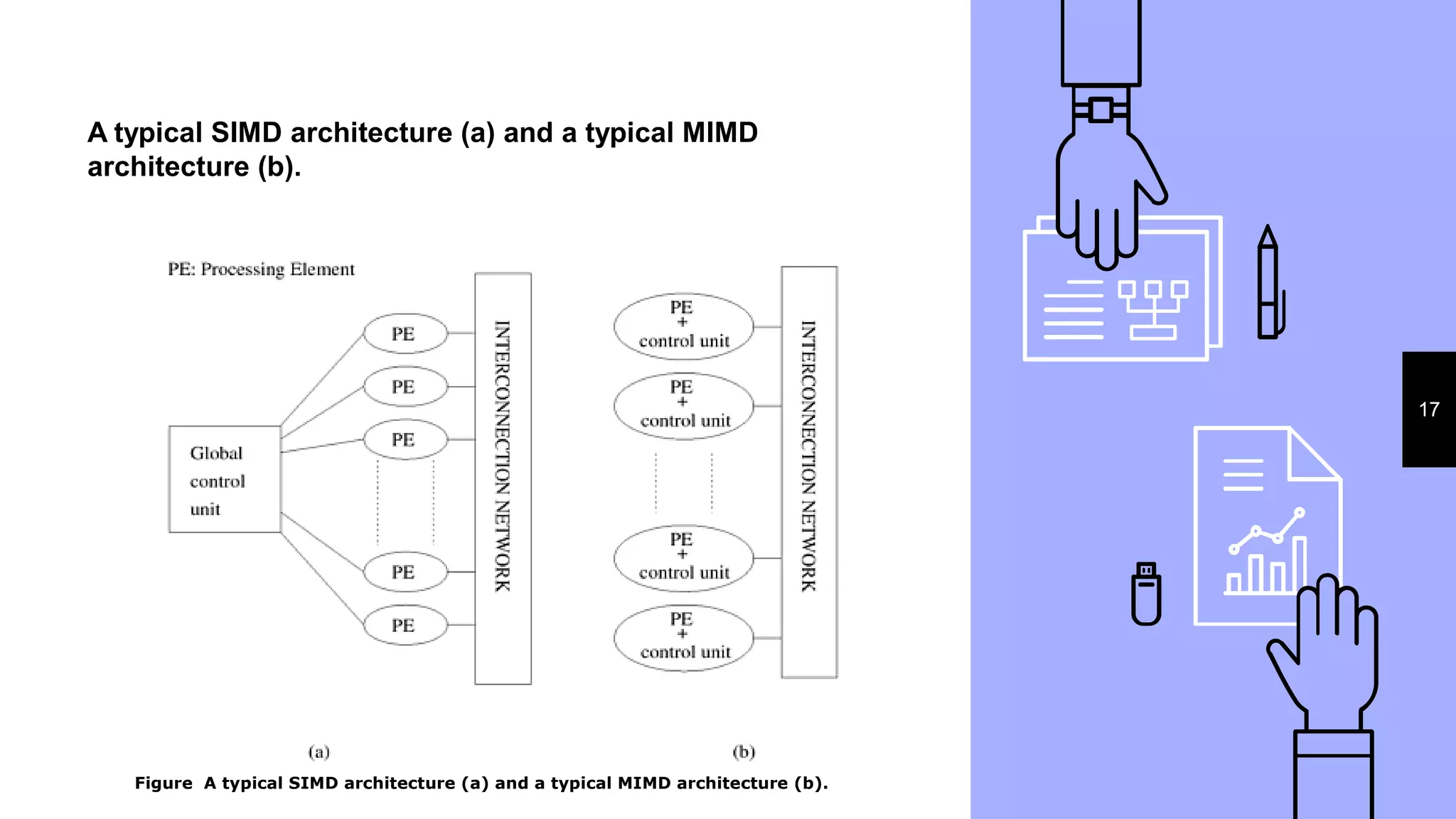
![Control Structure of Parallel Platforms
16
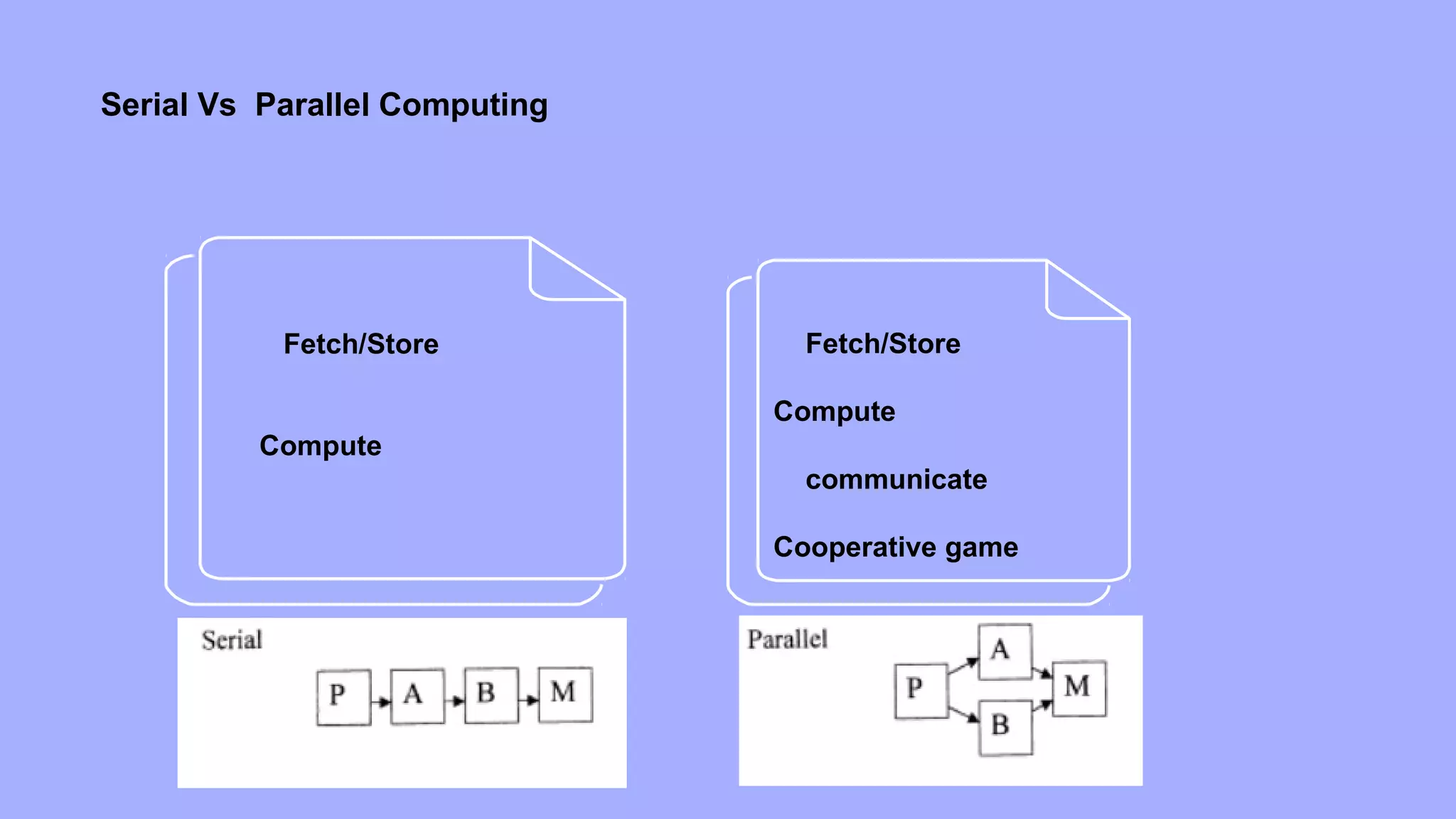
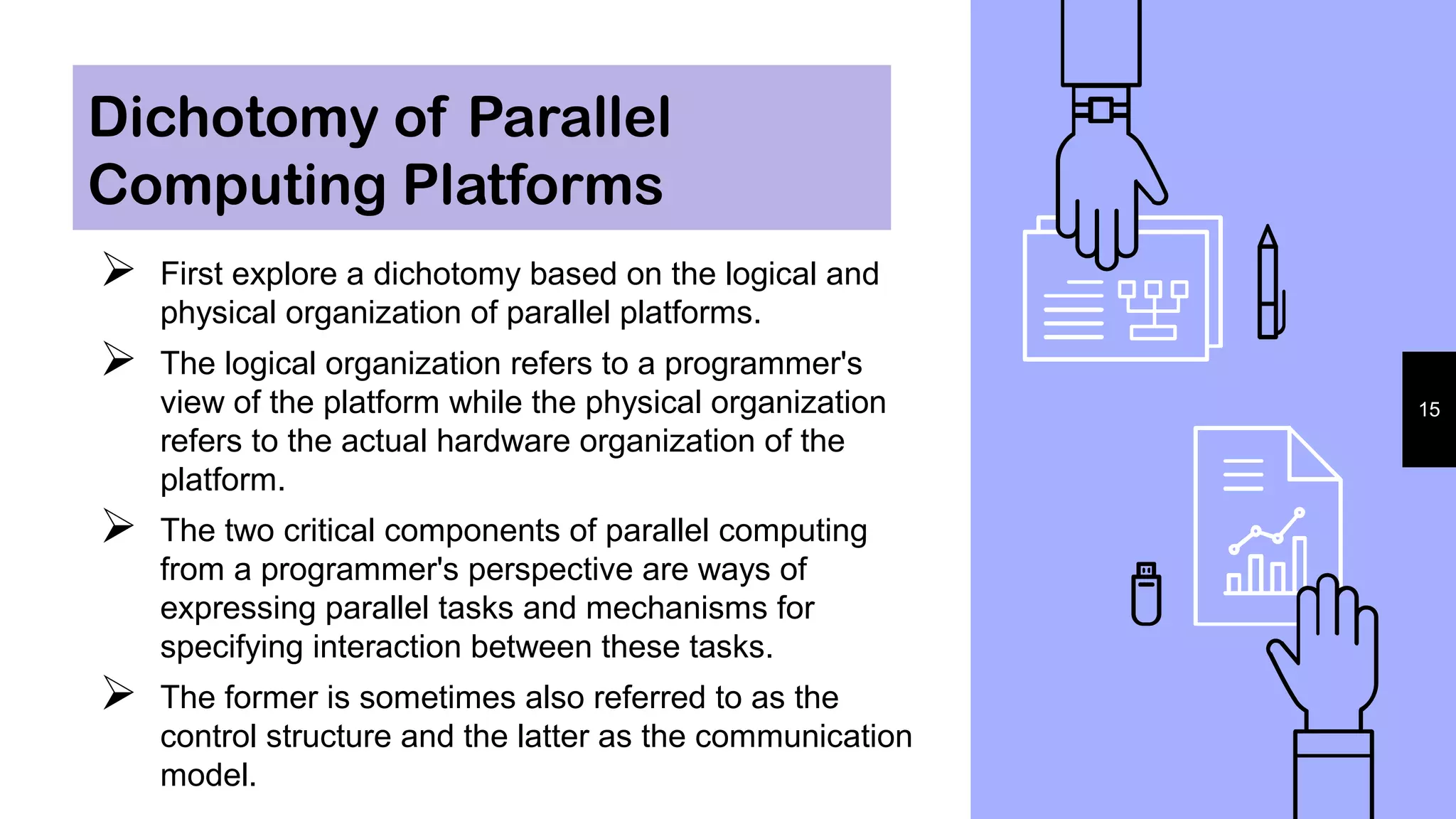
Parallel tasks can be specified at various levels of granularity.
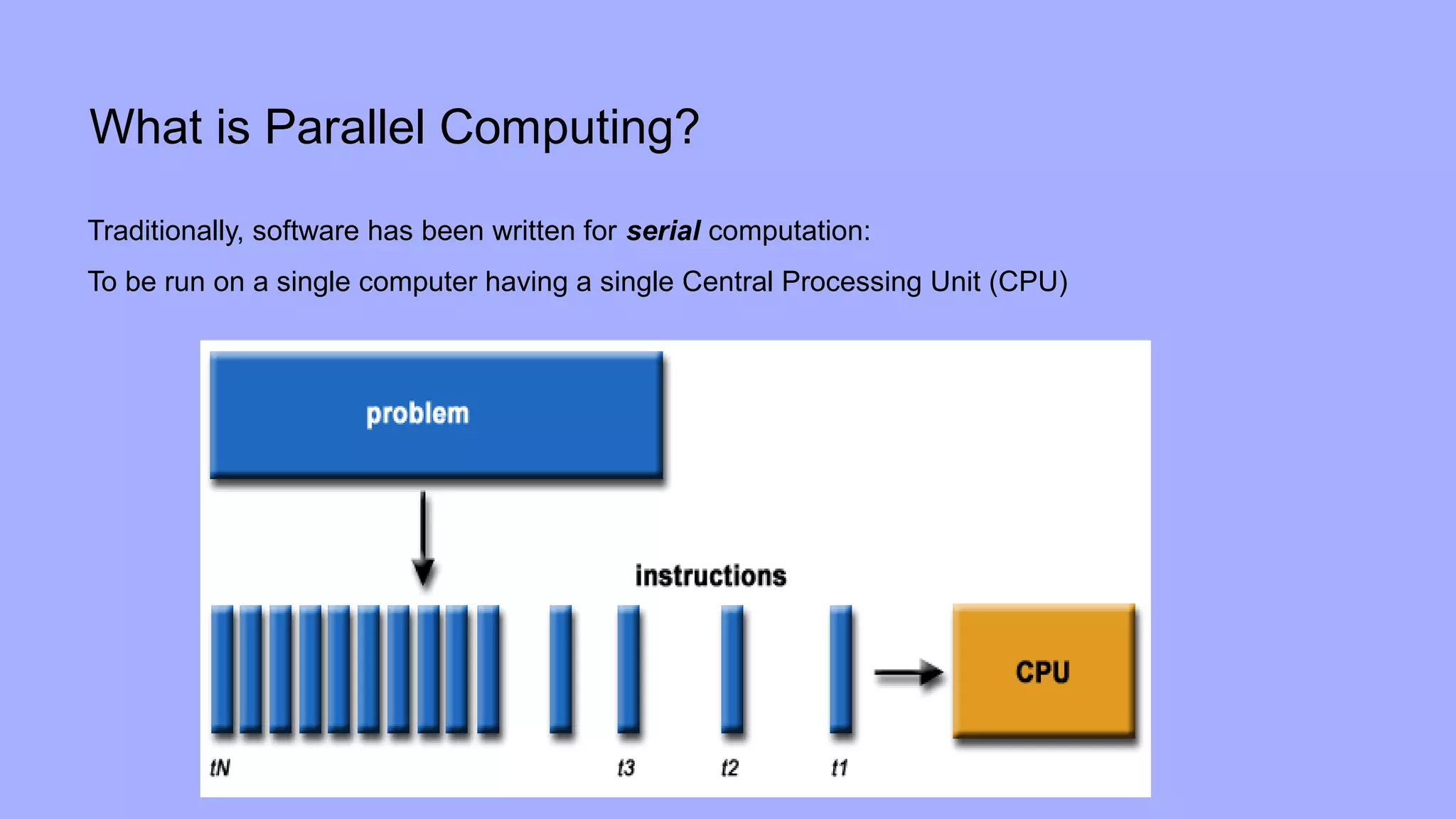
At the other extreme, individual instructions within a program
can be viewed as parallel tasks. Between these extremes lie a
range of models for specifying the control structure of programs
and the corresponding architectural support for them.
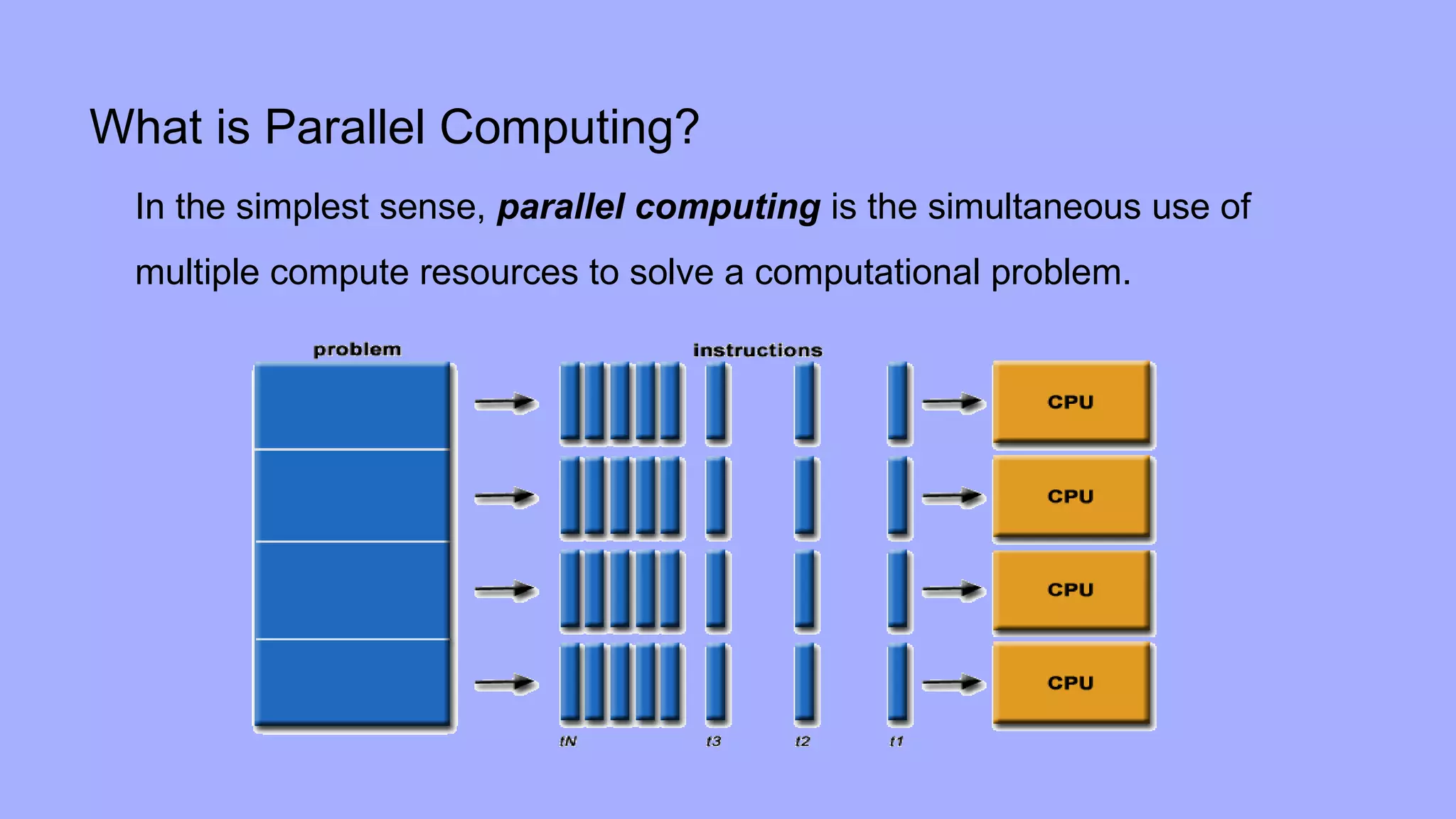
Parallelism from single instruction on multiple processors
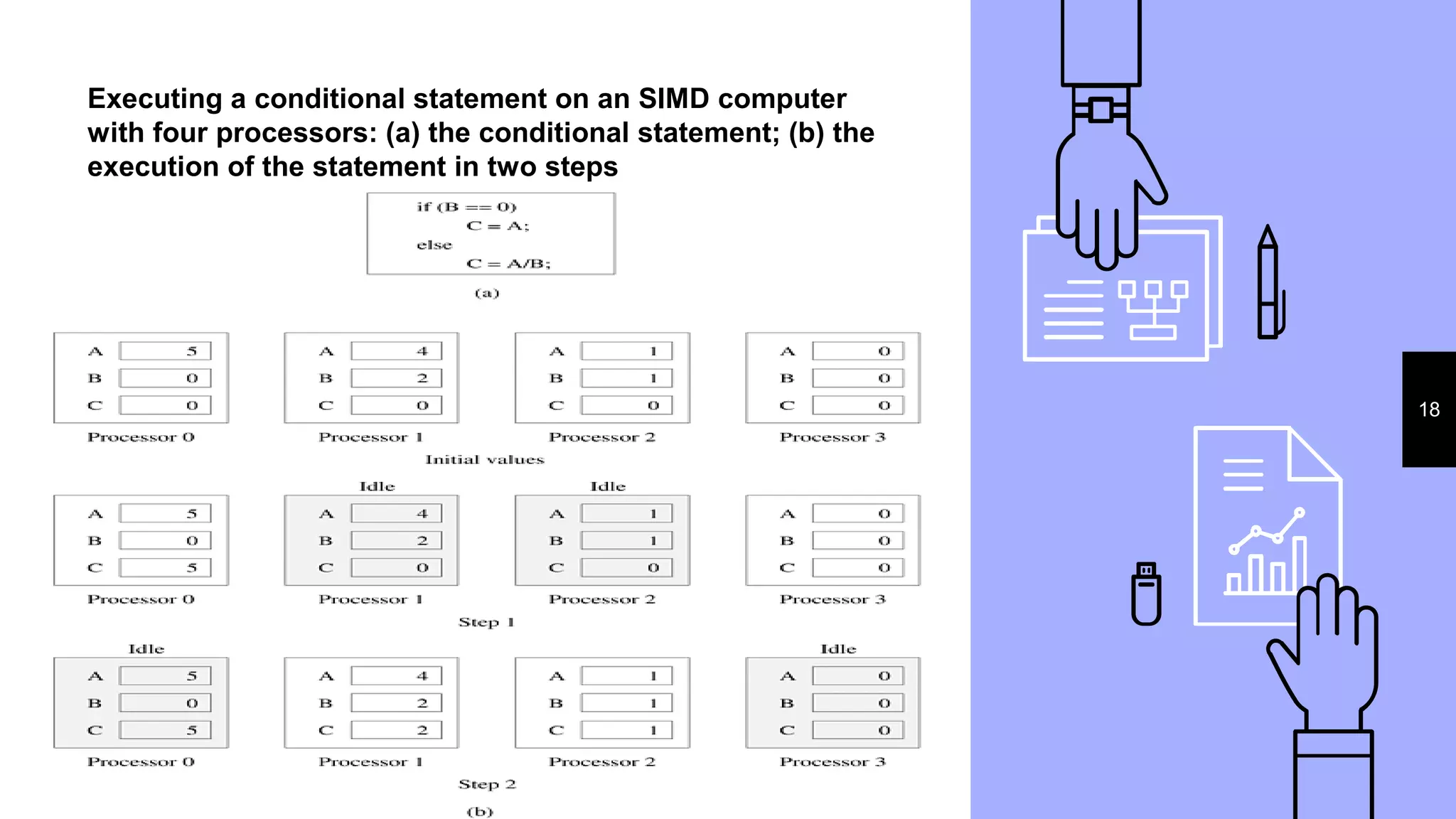
Consider the following code segment that adds two vectors:
1 for (i = 0; i < 1000; i++)
2 c[i] = a[i] + b[i];
In this example, various iterations of the loop are independent
of each other; i.e., c[0] = a[0] + b[0]; c[1] = a[1] + b[1];, etc., can all be
executed independently of each other. Consequently, if there is a mechanism for executing the same
instruction, in this case add on all the processors with appropriate data, we
could execute this loop much faster](https://image.slidesharecdn.com/hpc1final-180717054623/75/Parallel-Processing-Concepts-16-2048.jpg)
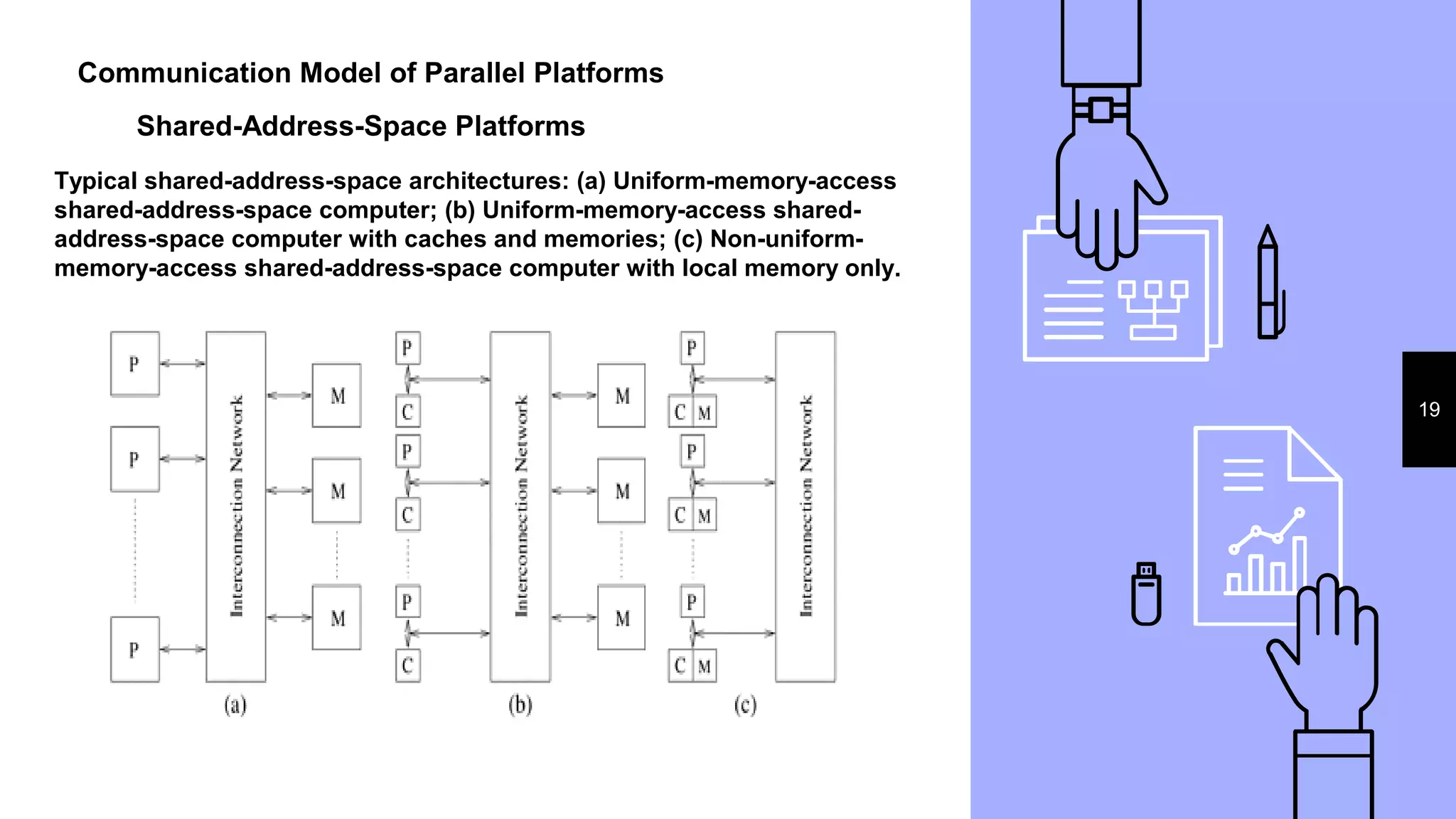
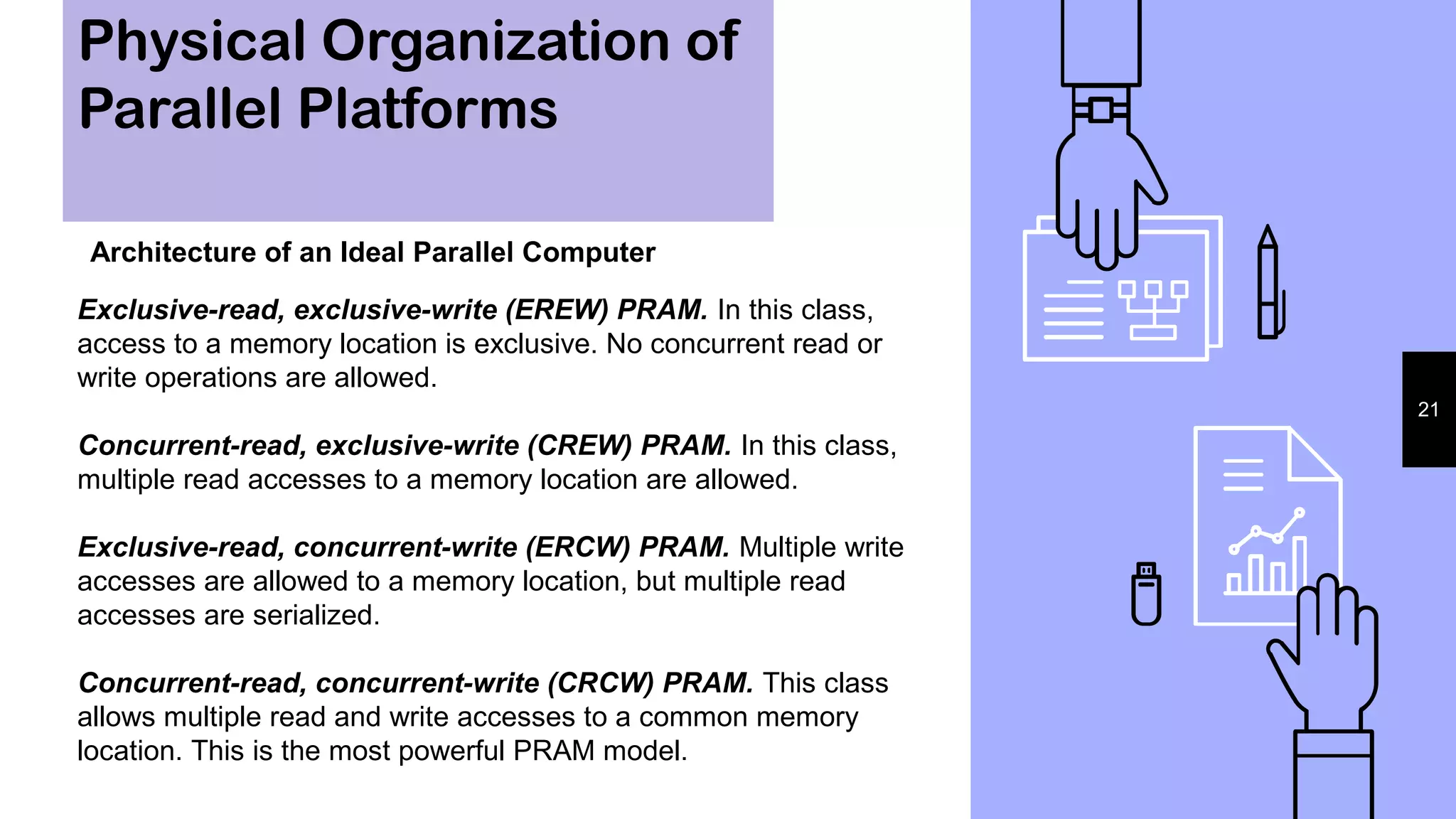
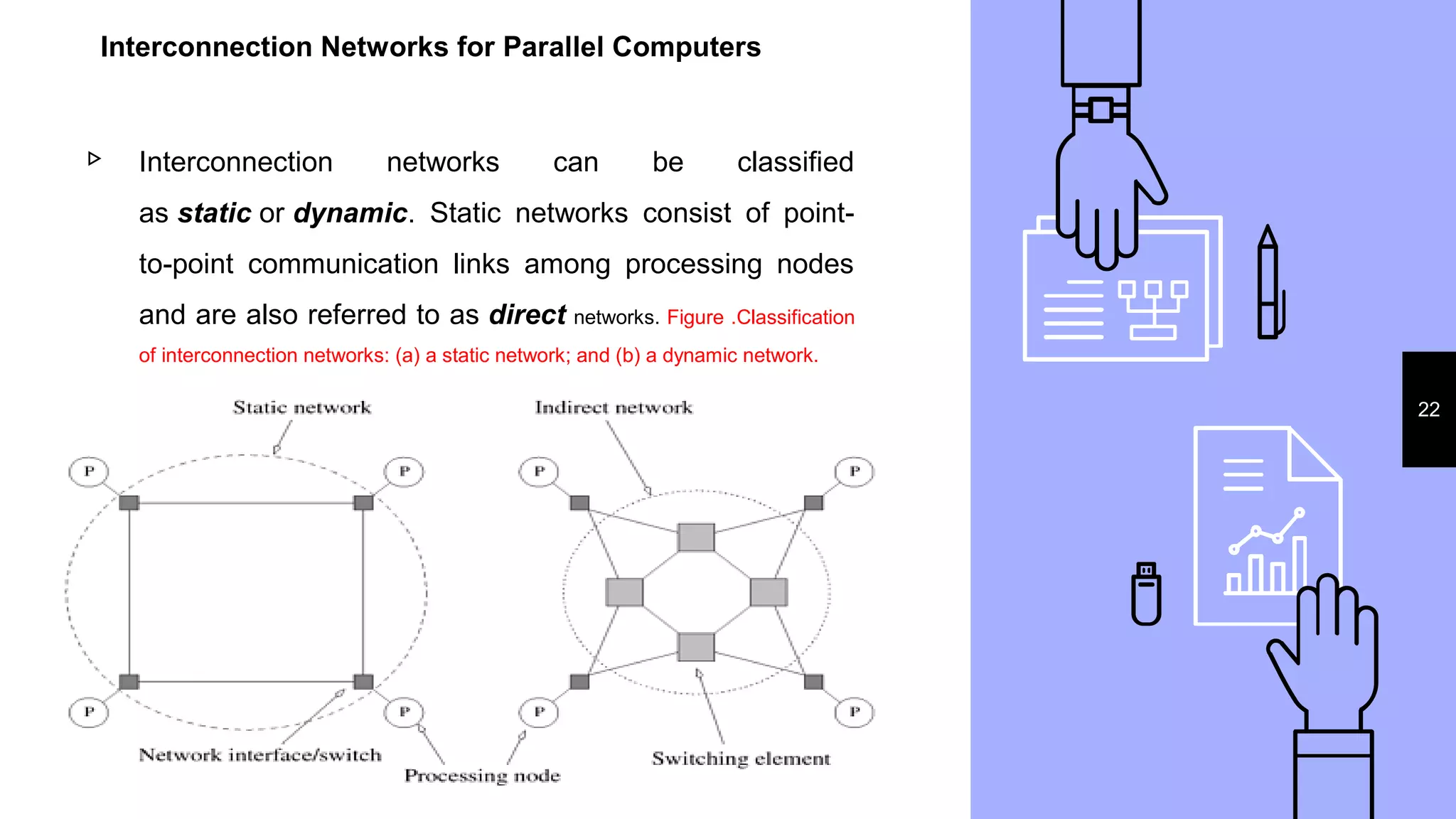
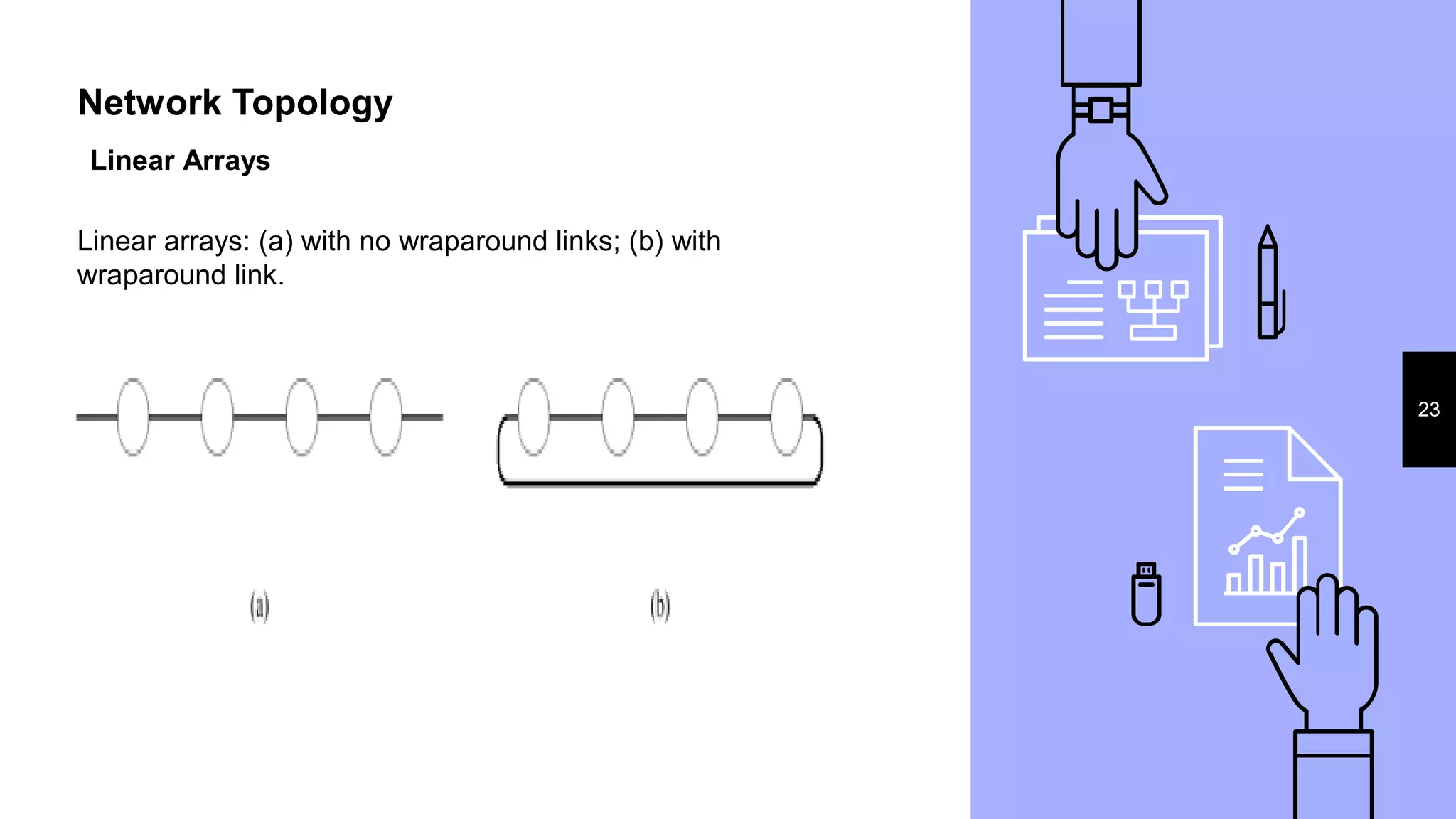
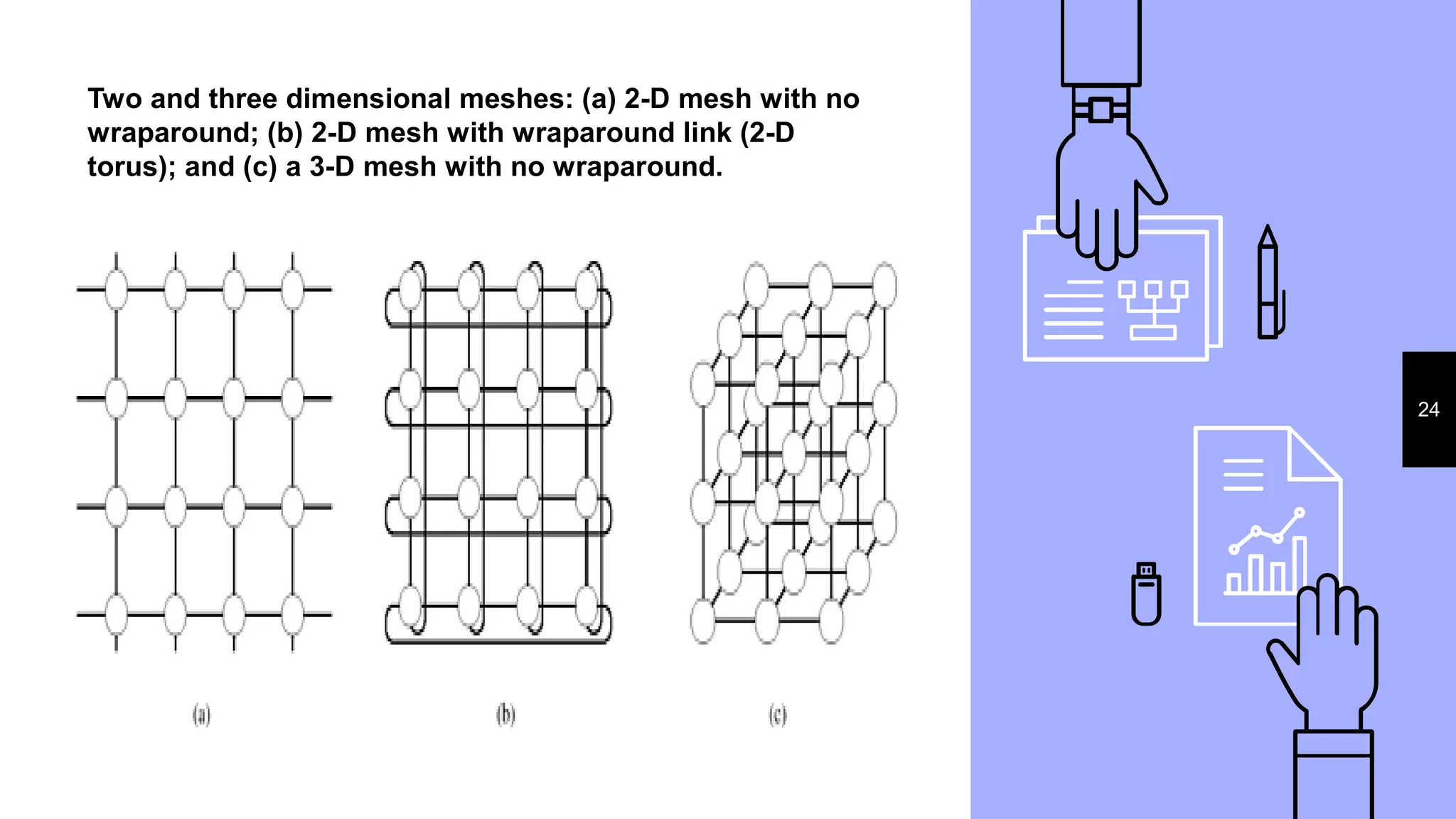
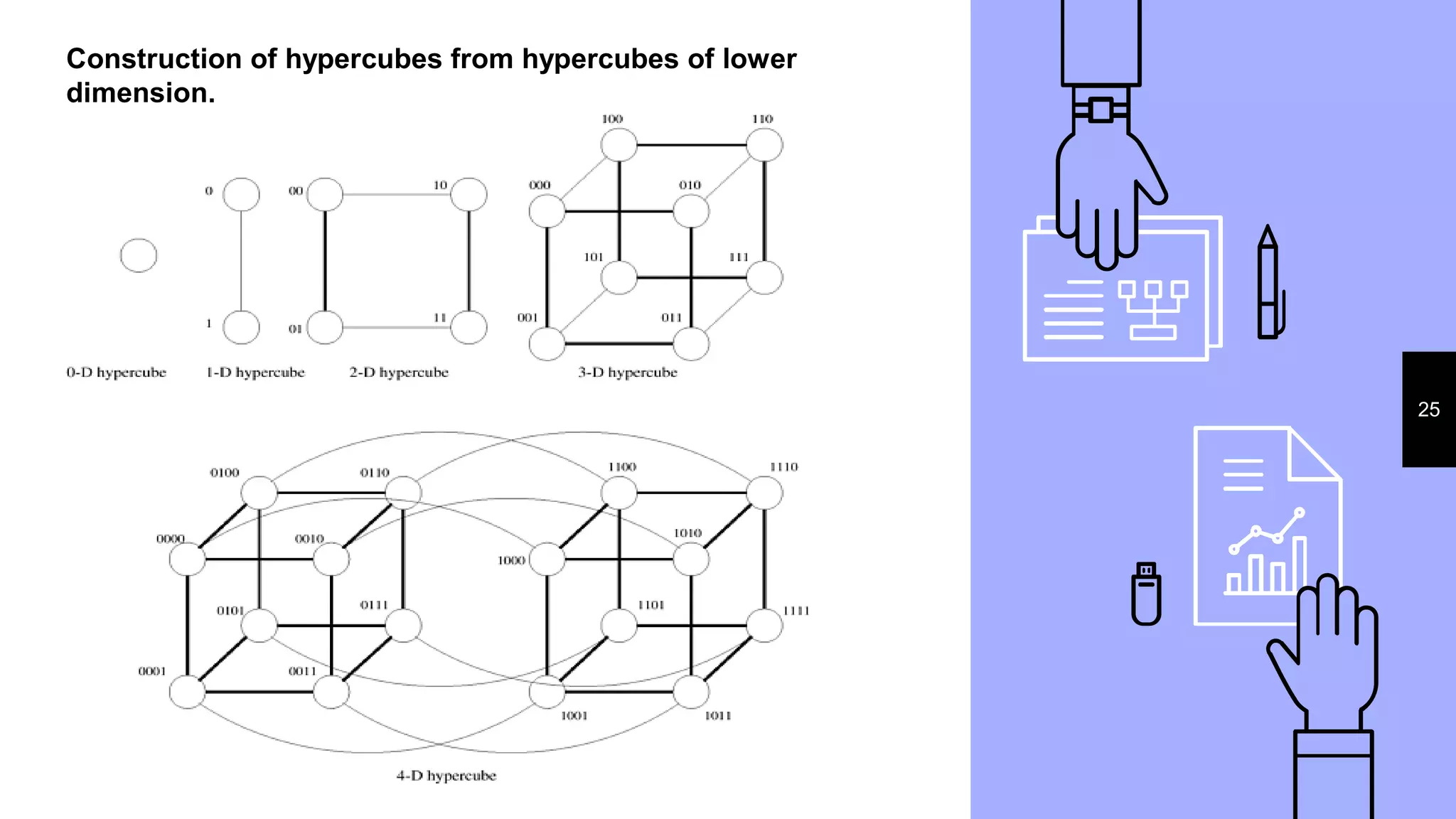
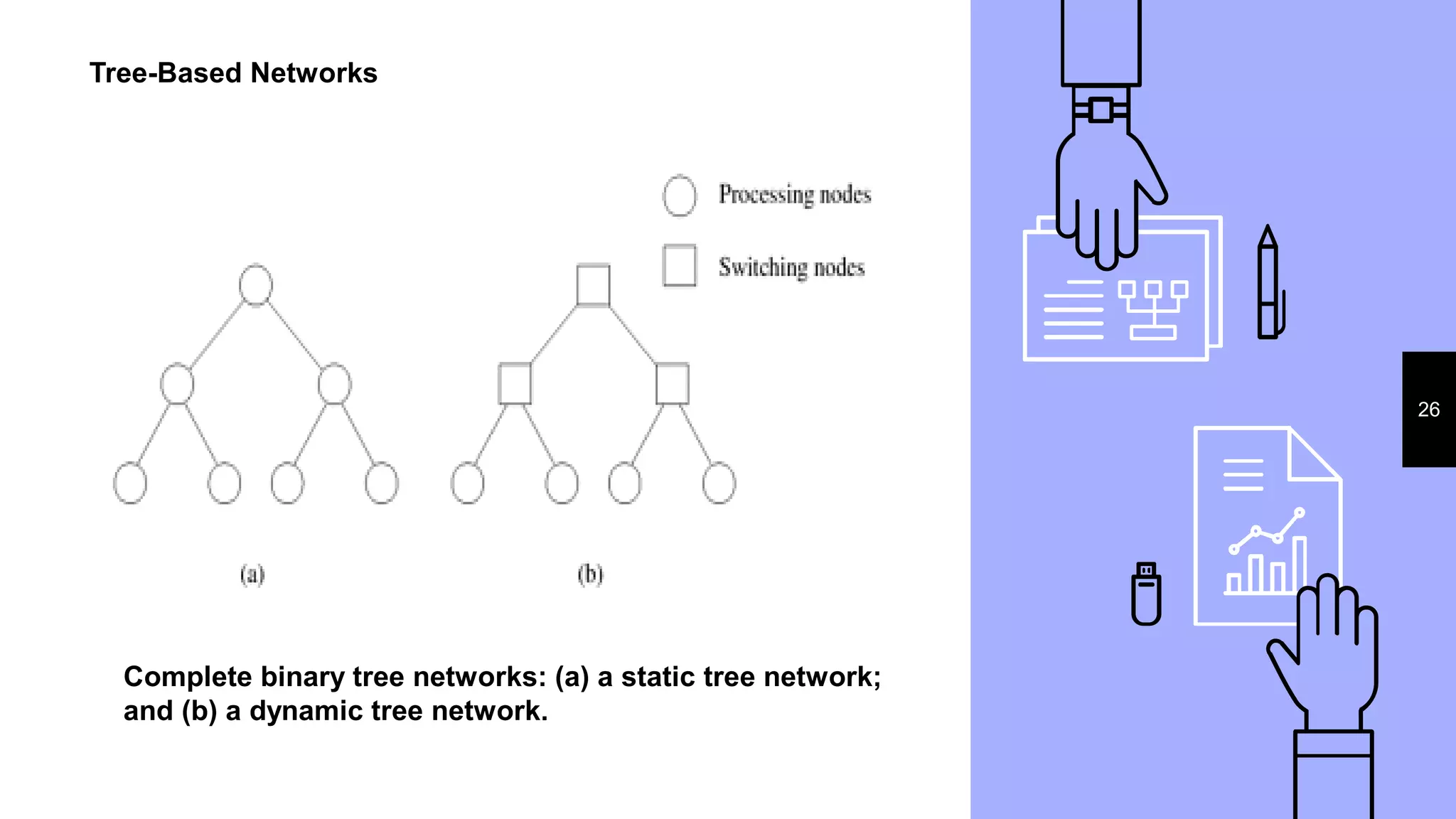

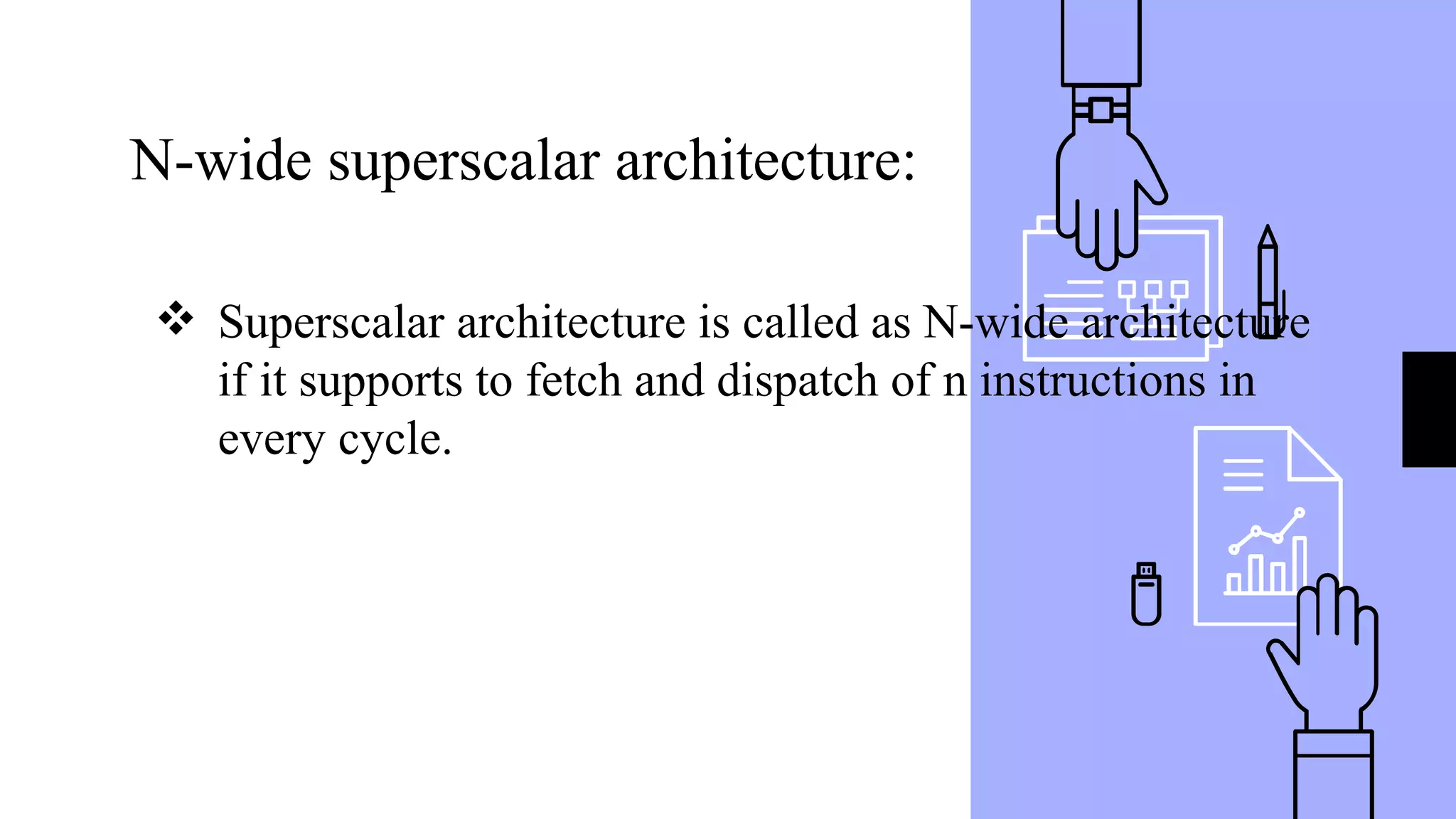
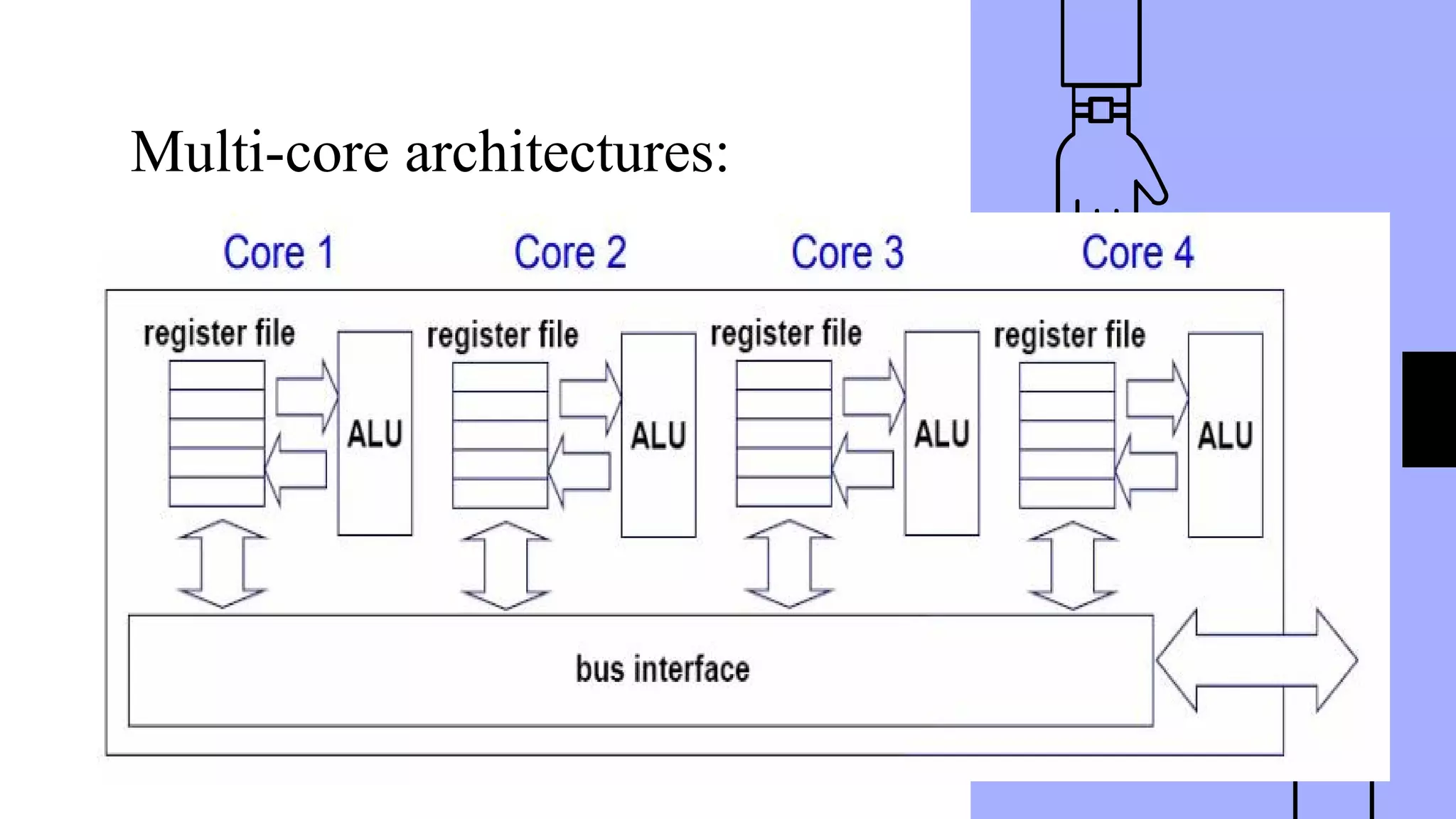



This document discusses parallel processing concepts including: 1. Parallel computing involves simultaneously using multiple processing elements to solve problems faster than a single processor. Common parallel platforms include shared-memory and message-passing architectures. 2. Key considerations for parallel platforms include the control structure for specifying parallel tasks, communication models, and physical organization including interconnection networks. 3. Scalable design principles for parallel systems include avoiding single points of failure, pushing work away from the core, and designing for maintenance and automation. Common parallel architectures include N-wide superscalar, which can dispatch N instructions per cycle, and multi-core which places multiple cores on a single processor socket.























































































