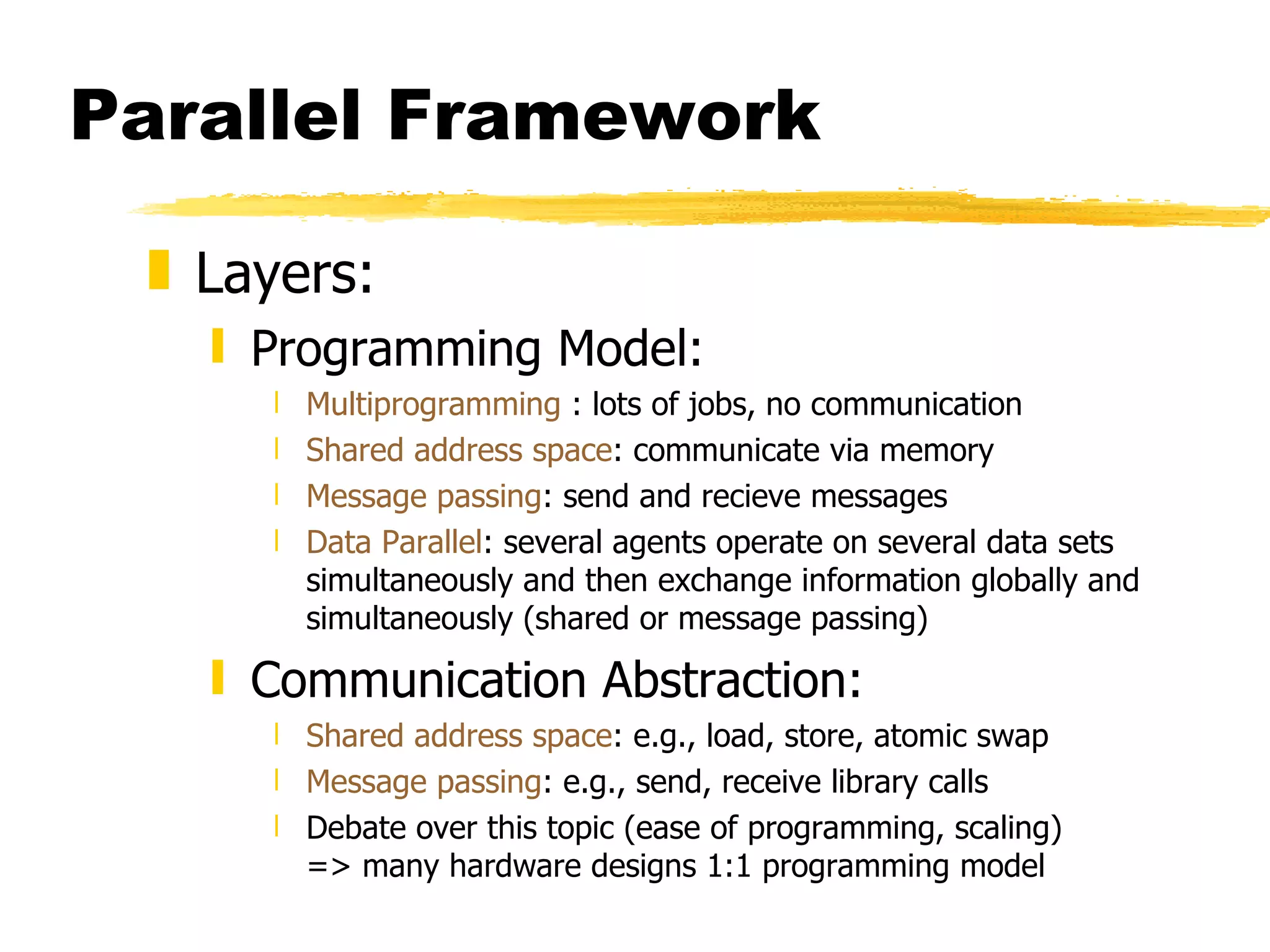
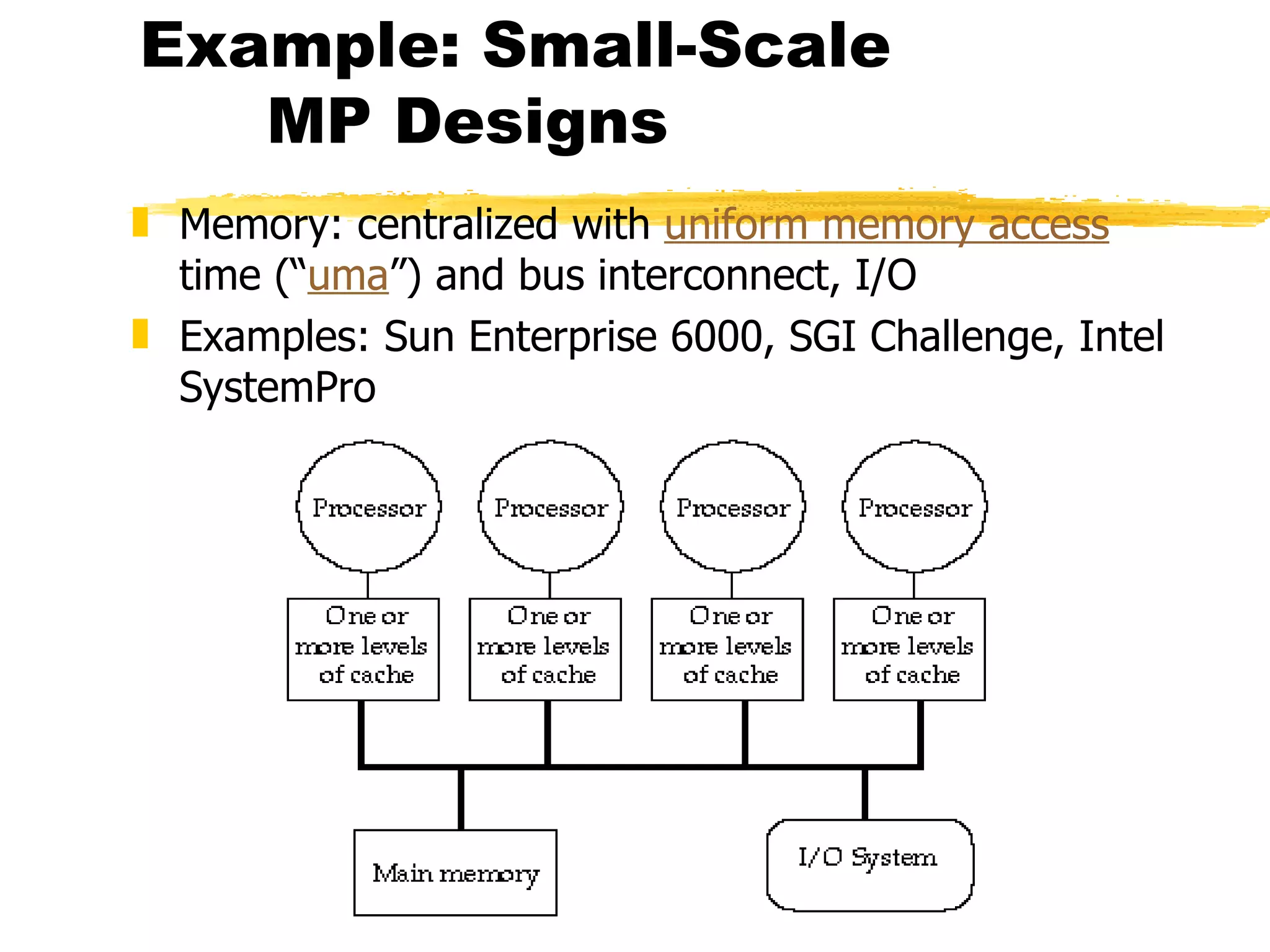
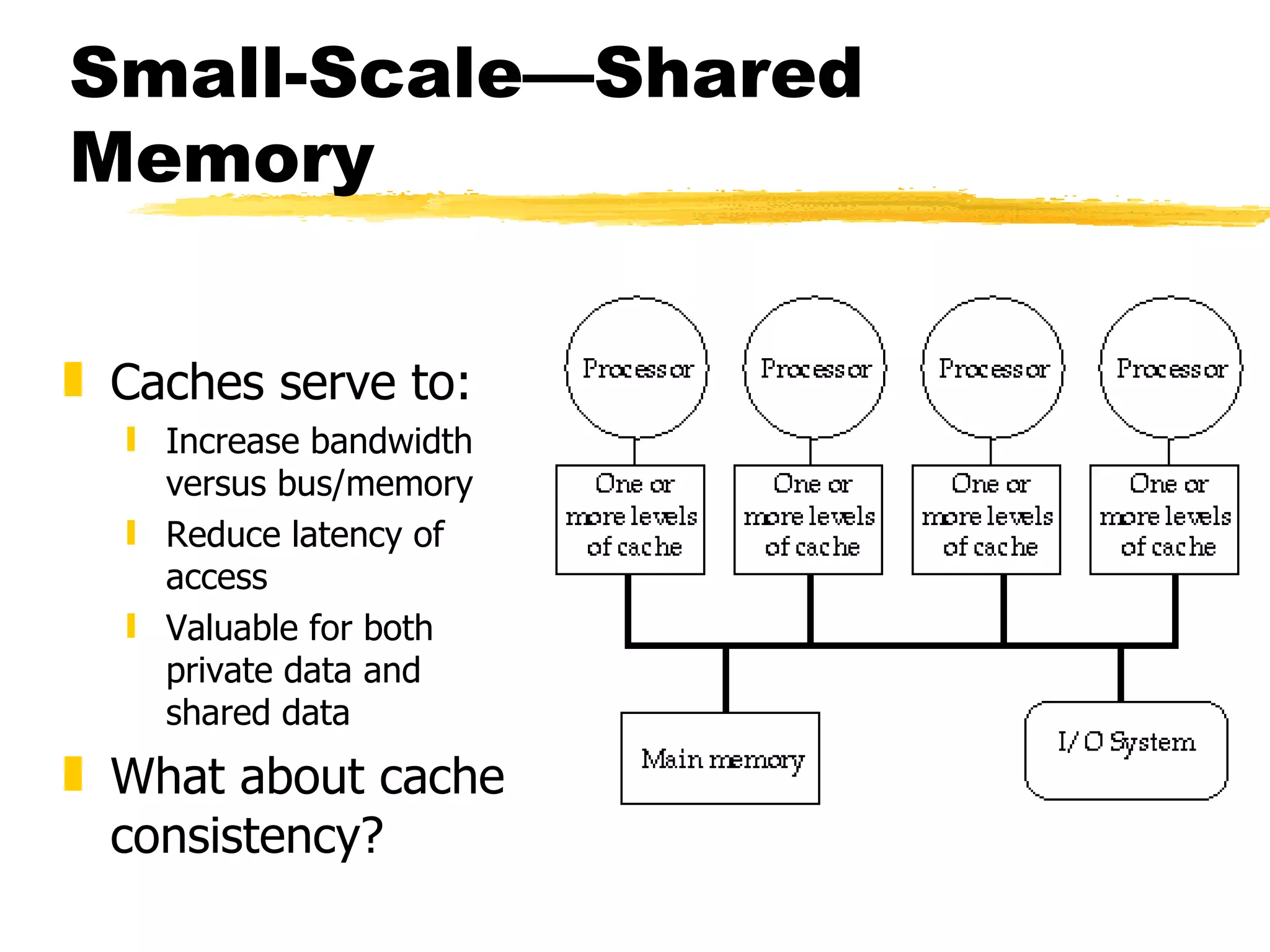
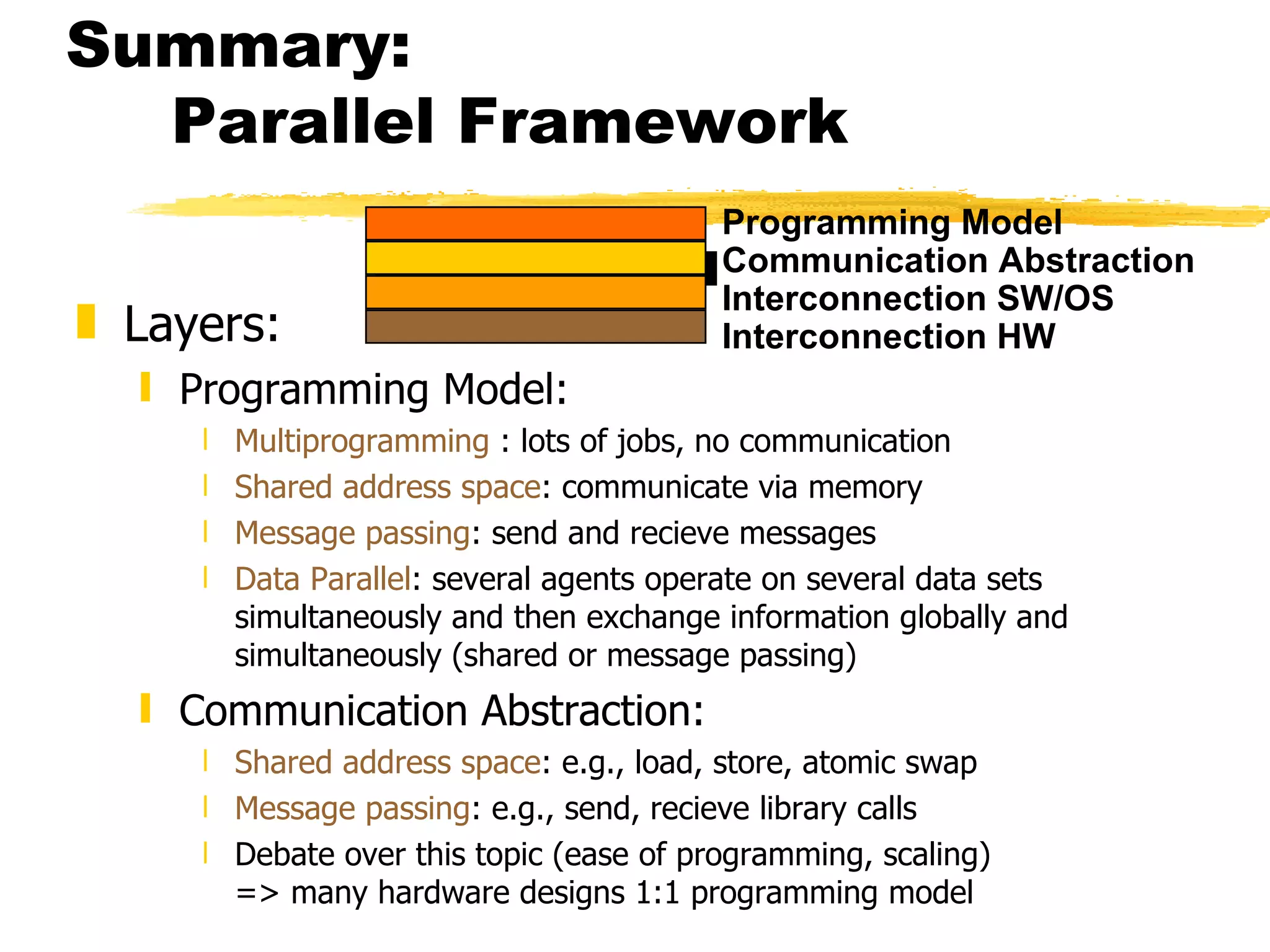
This document discusses parallel computers and architectures. It defines parallel computers as collections of processing elements that cooperate and communicate to solve problems fast. It then examines questions about parallel computers, different types of parallelism, and opportunities for parallel computing in scientific and commercial applications. Finally, it discusses fundamental issues in parallel architectures, including naming, synchronization, latency and bandwidth, and different parallel frameworks and models like shared memory, message passing, and data parallelism.









![SMP Interconnect
„ Processors to Memory AND to I/O
„ Bus based: all memory locations equal access time so
SMP = “Symmetric MP”
ƒ Sharing limited BW as add processors, I/O
ƒ (see Chapter 1, Figs 118/19, page 4243 of
[CSG96])
„ Crossbar: expensive to expand
„ Multistage network (less expensive to expand than
crossbar with more BW)
„ “Dance Hall” designs: All processors on the left, all
memories on the right](https://image.slidesharecdn.com/parallelarchitecture-120320121000-phpapp02/75/Parallel-architecture-12-2048.jpg)








![Data Parallel Model
„ Operations can be performed in parallel on each element
of a large regular data structure, such as an array
„ 1 Control Processsor broadcast to many PEs (see Ch. 1,
Fig. 126, page 51 of [CSG96])
ƒ When computers were large, could amortize the
control portion of many replicated PEs
„ Condition flag per PE so that can skip
„ Data distributed in each memory
„ Early 1980s VLSI => SIMD rebirth:
32 1bit PEs + memory on a chip was the PE
„ Data parallel programming languages lay out data to
processor](https://image.slidesharecdn.com/parallelarchitecture-120320121000-phpapp02/75/Parallel-architecture-22-2048.jpg)









































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

