Download to read offline













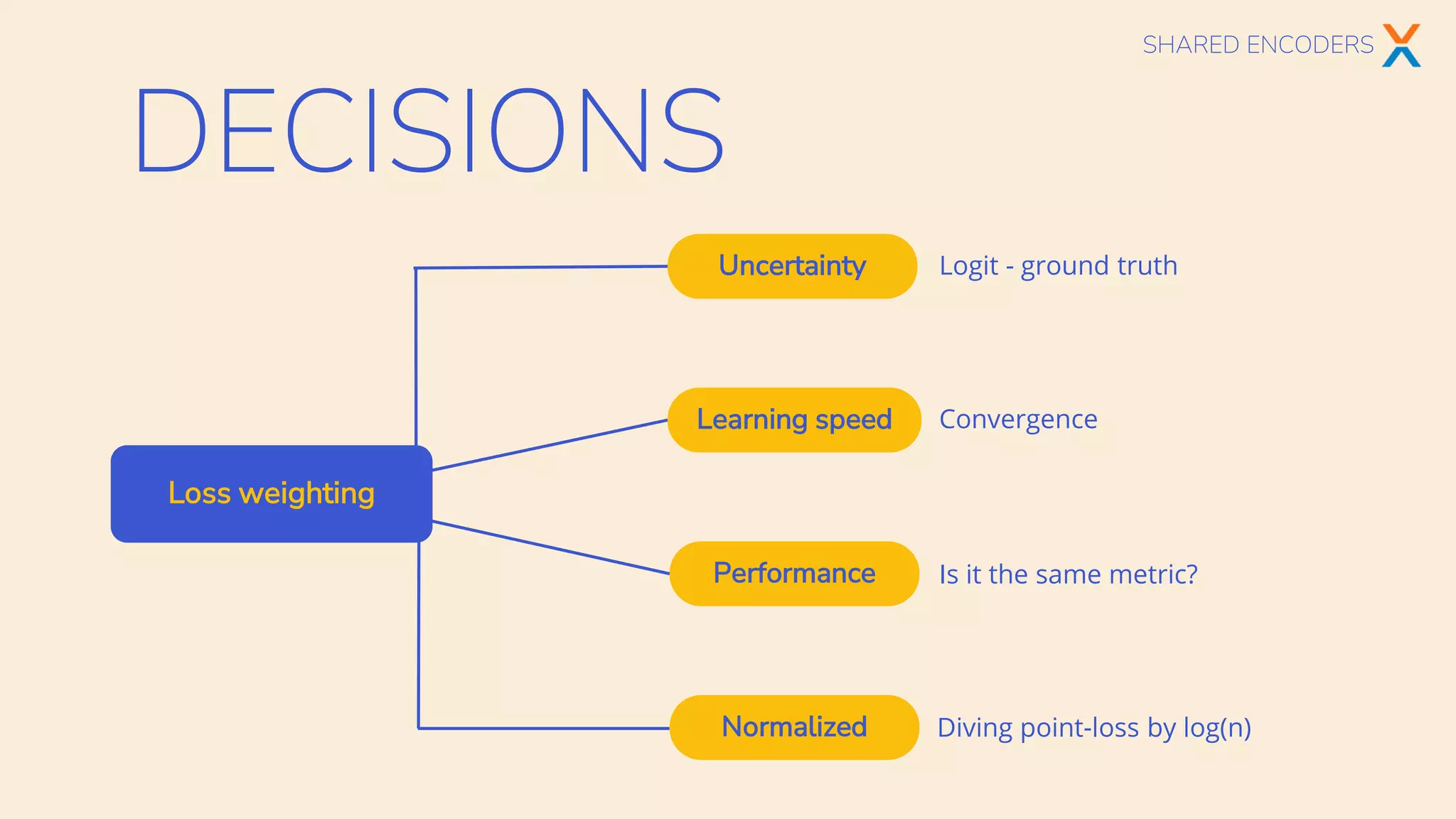



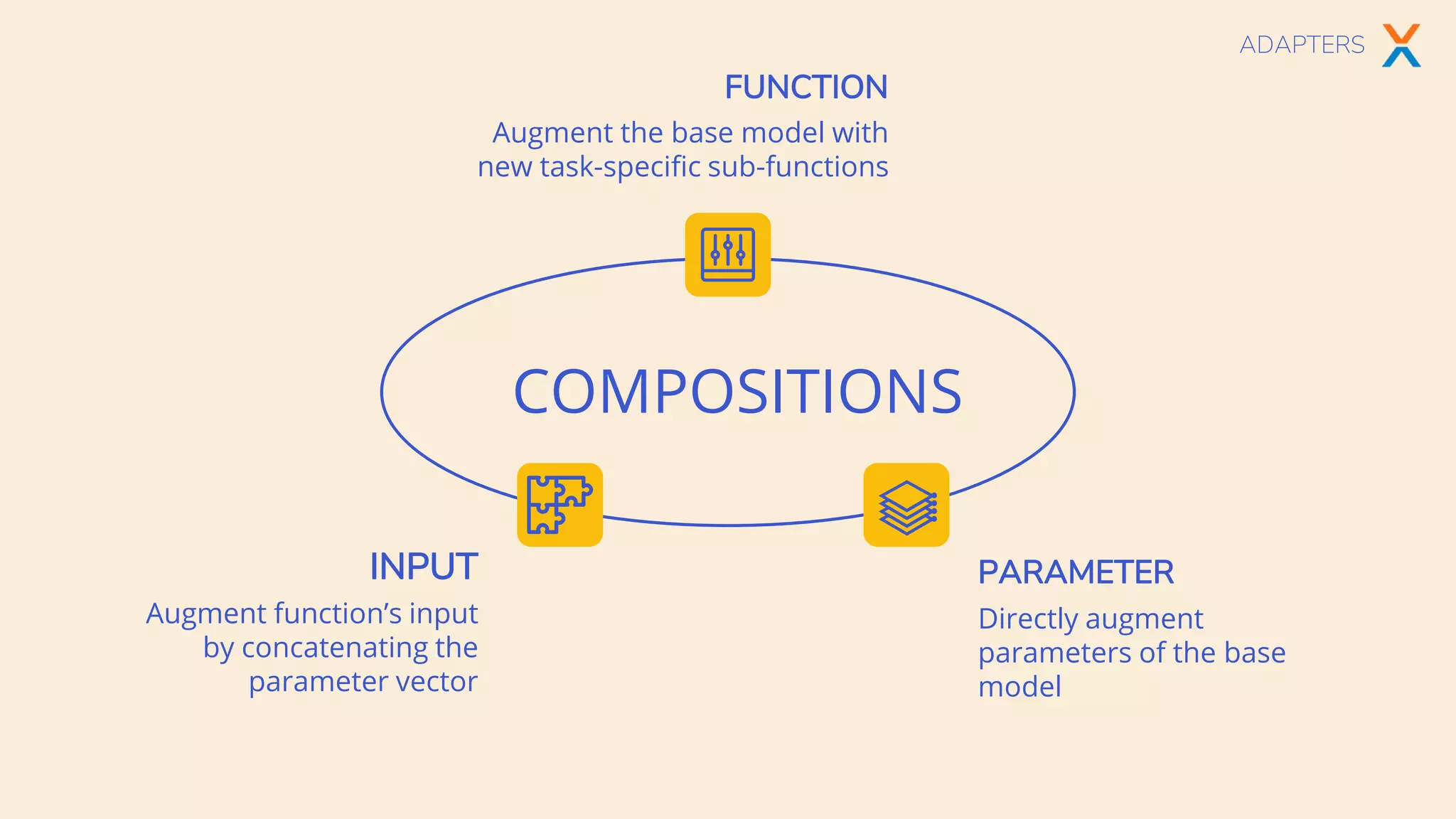

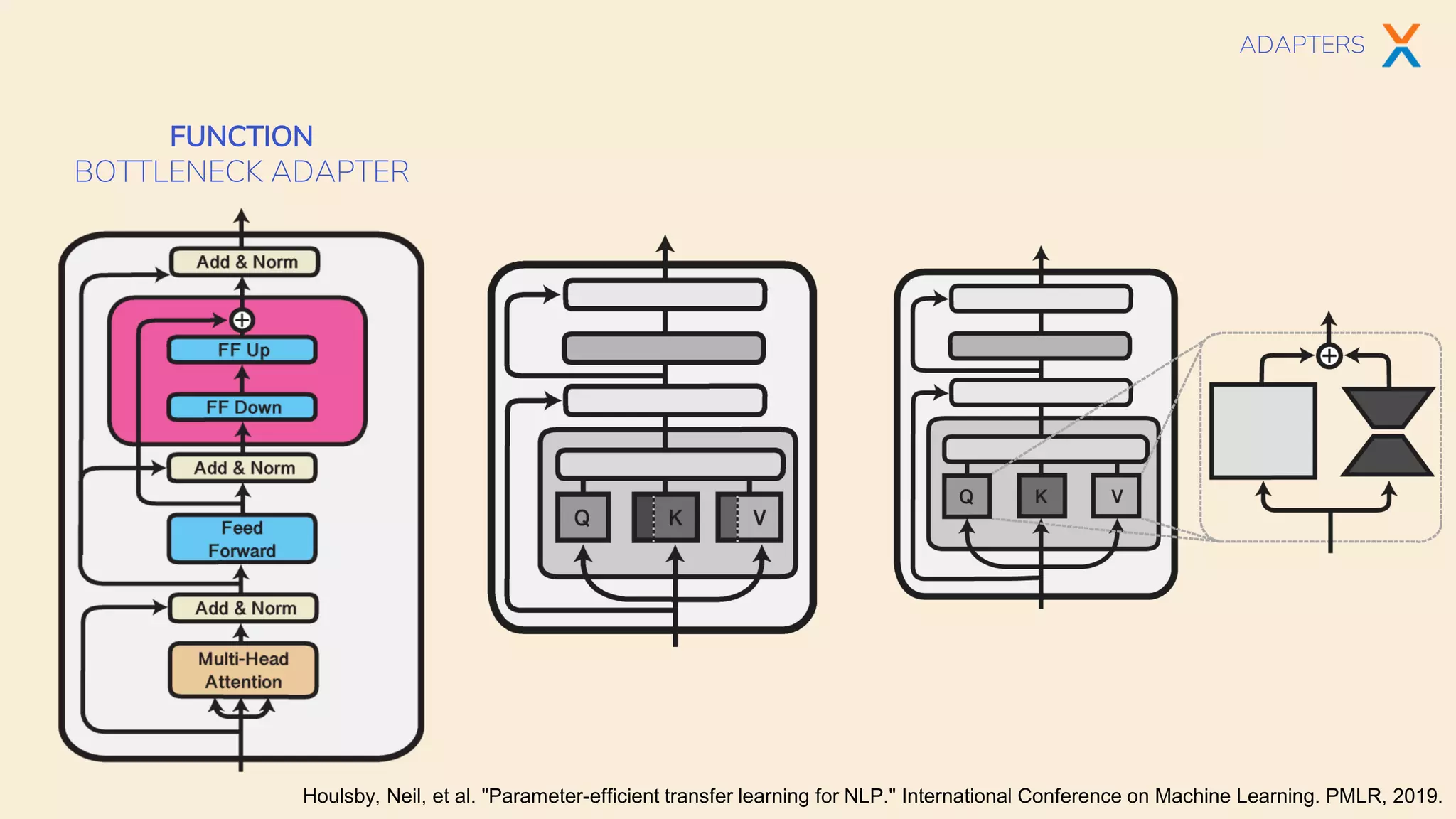


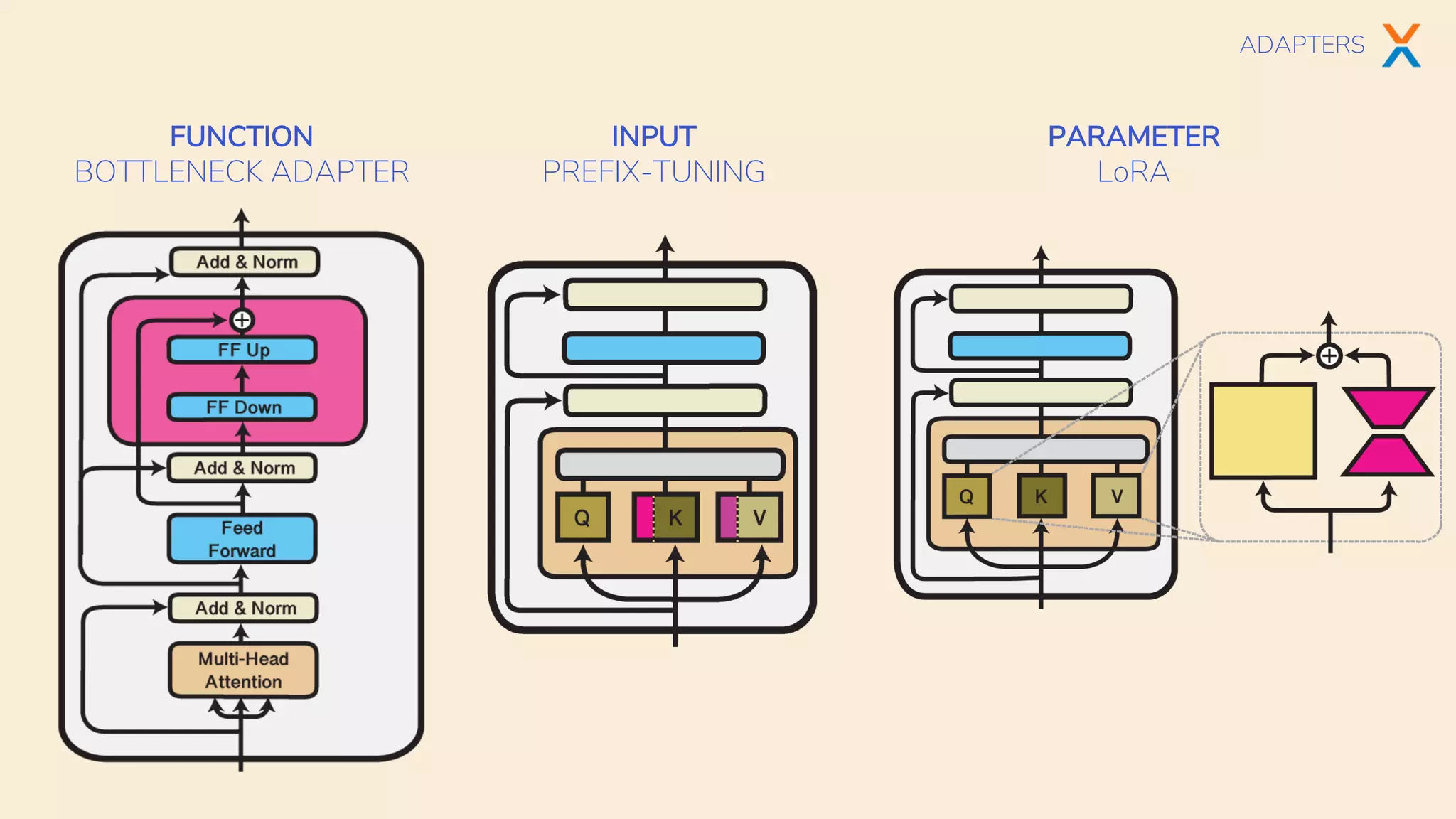












The document discusses multi-task learning in transformer-based architectures for natural language processing, highlighting techniques such as shared encoders, adapters, and hypernetworks. It emphasizes the advantages of these methods in terms of data efficiency, parameter modularity, and performance gains over traditional single-task learning. Various models and their training implications, along with the challenges of aligning datasets and managing gradient directions, are also explored.




























![[DSC Europe 25] Mahmoud Fahmy - Transforming Enterprise AI with Scalable LLM ...](https://cdn.slidesharecdn.com/ss_thumbnails/rxsvz5tfstg5fquy016q-3-251218084257-1d2ce5f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrej Zdravkovic - AI in Action: Can We Unlock 50% Productiv...](https://cdn.slidesharecdn.com/ss_thumbnails/gb3jwads9ehoagcmmzfz-1-251218084256-bf6869a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tim Sears - Making AI Real: From Research to Impact.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rgb1innksugkggjhv43s-6-251218084257-61e06116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dejan Djekic - Building Data Platforms That Build Themselves:...](https://cdn.slidesharecdn.com/ss_thumbnails/ojhu5yyxrl2sb727aghz-dejan-djekic-building-data-platforms-that-build-themselves-dsc-europe-belgrade--251218085301-a0fa979c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Matthias Rochtus - Geo-Intelligence: Business insights Throug...](https://cdn.slidesharecdn.com/ss_thumbnails/kv1lkcvasxycdlyirxxa-matthias-dsc-europe-serbia-geospatial-251218084819-1743cb20-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Oliver Kosta Zivic - Vendor Lock-in or Weekend Lock-out: Choo...](https://cdn.slidesharecdn.com/ss_thumbnails/x1wkdzrlr7aain6x3dko-vendor-lock-in-or-weekend-lock-out-choosing-between-databricks-comfort-and-spar-251218084820-88ec7e39-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - From Electrons to Innovation: How Granular Da...](https://cdn.slidesharecdn.com/ss_thumbnails/h4qk69zereaumbceubgr-dobrica-cosic-from-electrons-to-innovation-how-granular-data-and-analytics-are--251218085301-b982fb14-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Assem Hussein - Future-Proof Your Business: AI, Market Fit, a...](https://cdn.slidesharecdn.com/ss_thumbnails/jatyvqbnqc5rbebpup5t-assem-hussein-251218085553-3983d431-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mathias Halkjær Petersen - The AI workforce revolution.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3xviexv7q5gojhdsyvat-the-ai-workforce-revolution-251218084820-f3c286ed-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Wolfgang Klein & Olena Brandsch - Operationalizing GenAI: Tur...](https://cdn.slidesharecdn.com/ss_thumbnails/mdjqcqgoriqj6kdjabxk-8-251216105606-9290bc27-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Velibor Ilic - Autonomous Driving - How AI Shapes Technical ...](https://cdn.slidesharecdn.com/ss_thumbnails/gwu9aqths9ovngsrhidc-3-velibor-ilic-autonomous-driving-how-ai-shapes-technical-challenges-251219150035-7436923a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Antonio Durao - From Algorithm to Classroom: How Adaptive AI ...](https://cdn.slidesharecdn.com/ss_thumbnails/ndmhbhiztbcr1oqmalog-3-eduquest-beyond-the-right-answer-final-251219145616-bd45a359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jordi Vallverdu - Automating Nonsense.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/whnjqmquoeztfcd1htga-ai-in-labour-jordi-vallverdu-v2-251219145036-d8fcc878-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jordi Vallverdu - MINIBRAIN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/x5xrnom2scxovikrd6zx-minibrain-neuroai-251219145036-2c42e47a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic - Educating Across Boundaries in the Age of A...](https://cdn.slidesharecdn.com/ss_thumbnails/4pthtbtirpqwgga3cydt-2-edtech-251219145616-47eda643-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Pilar Baltar - From Model Drift to Capability Drift: Building...](https://cdn.slidesharecdn.com/ss_thumbnails/c3g3q8vdsc2arxmeclqs-pilar-baltar-from-model-drift-to-capability-drift-251219145036-e930d86d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

