Download to read offline


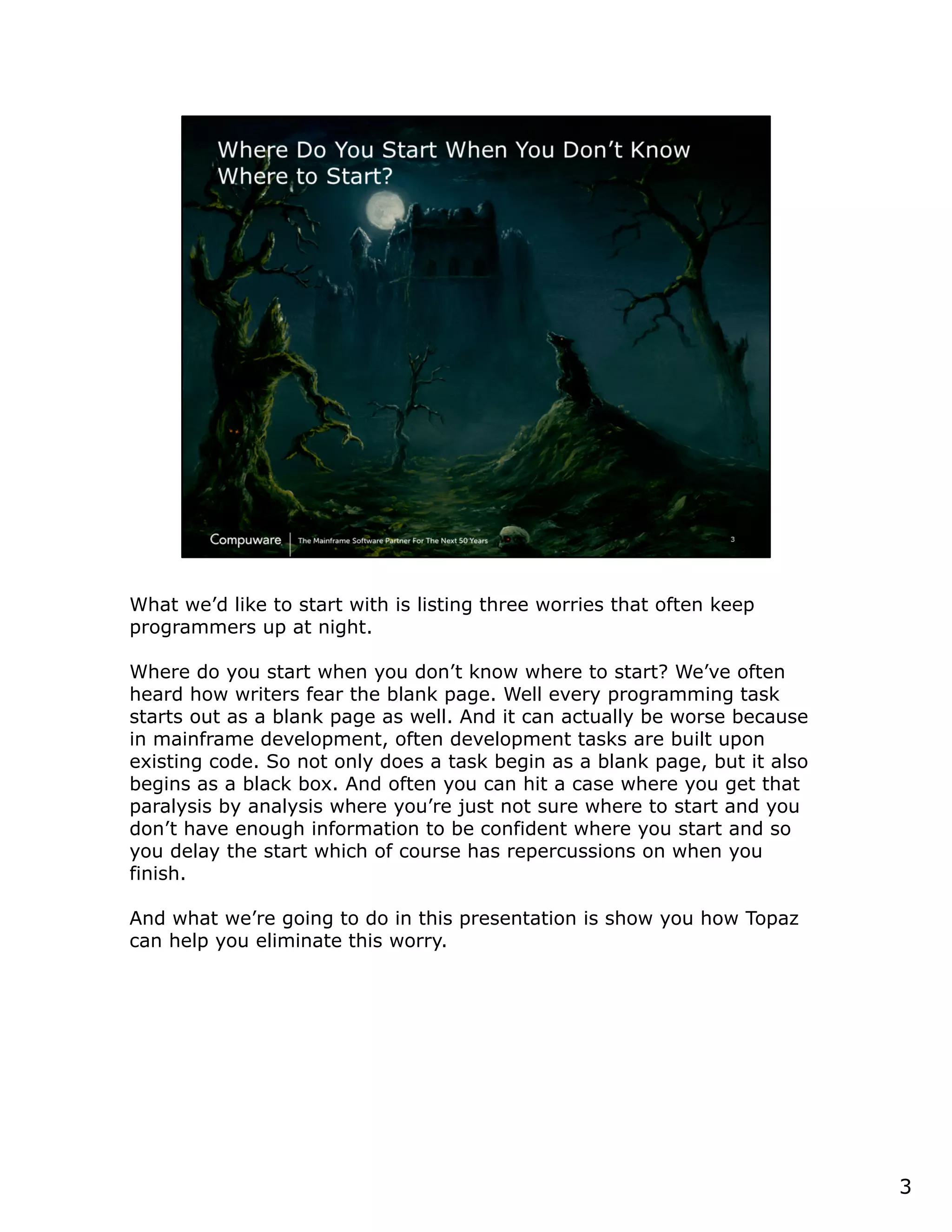



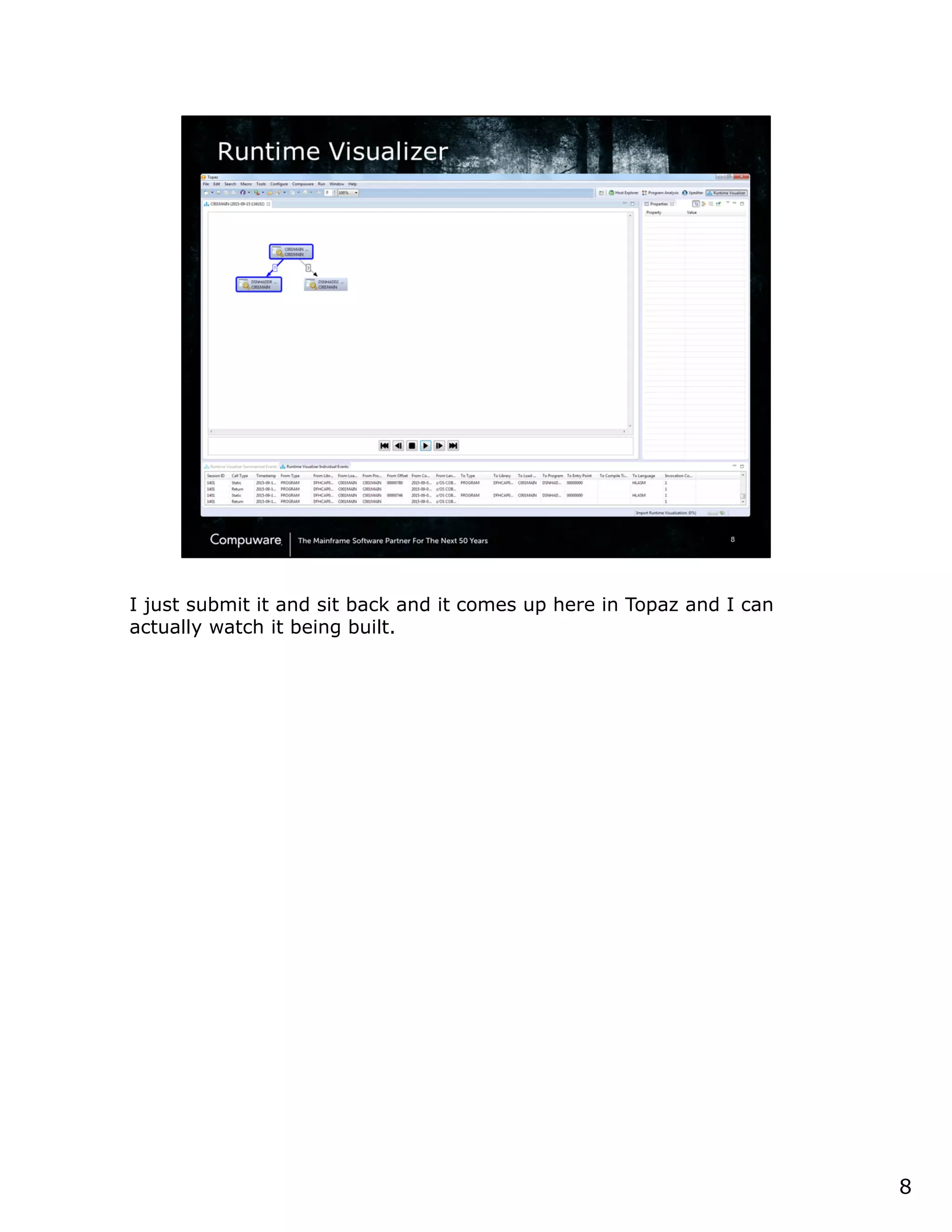
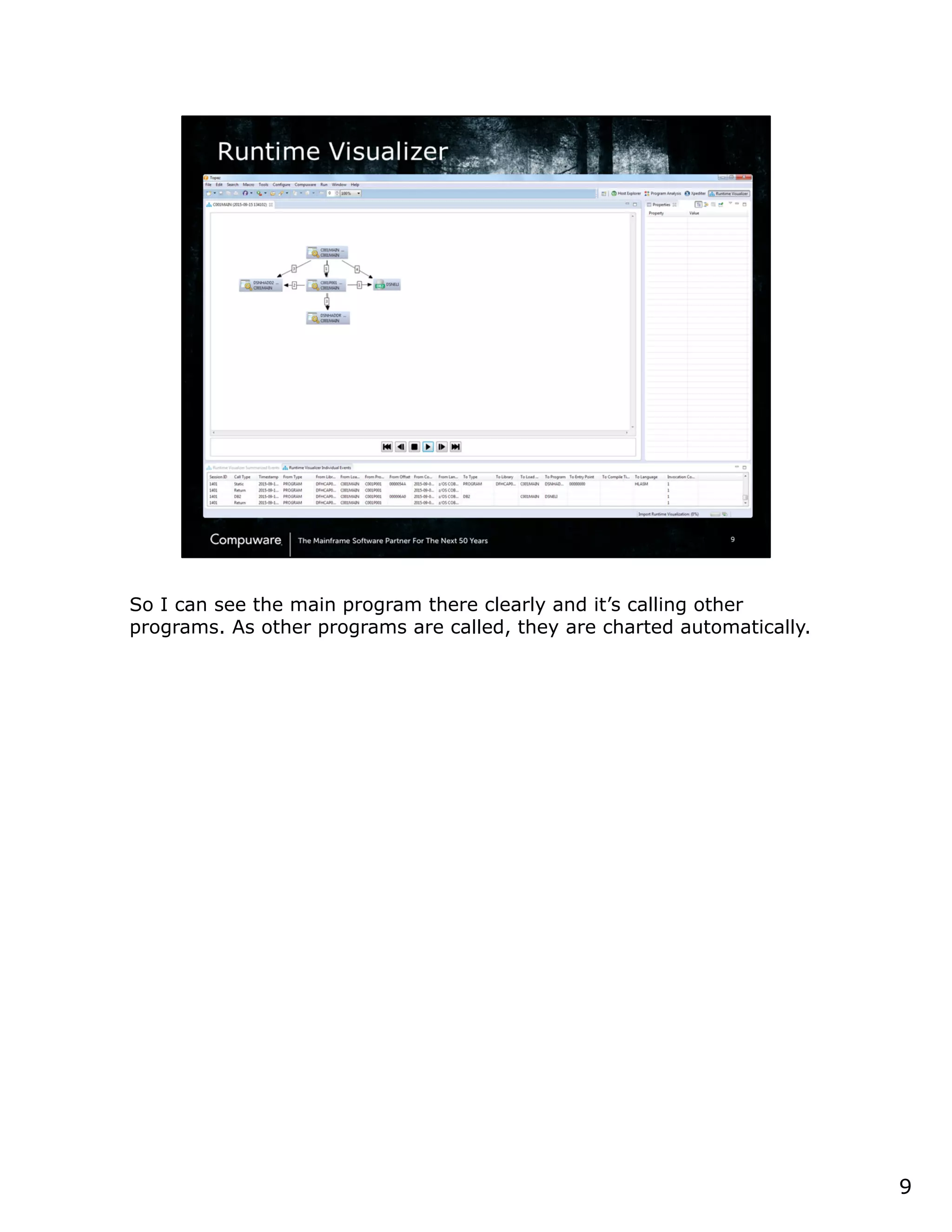
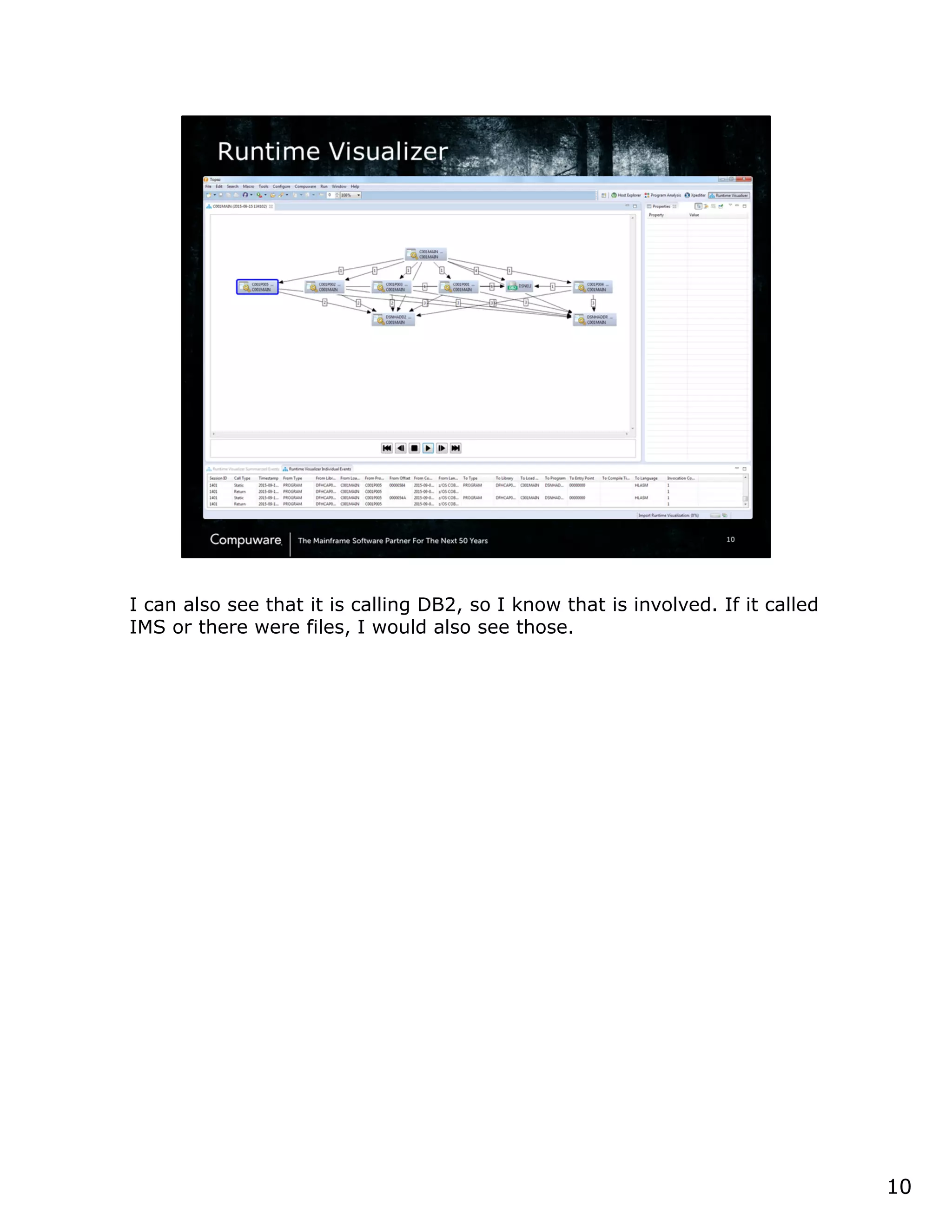
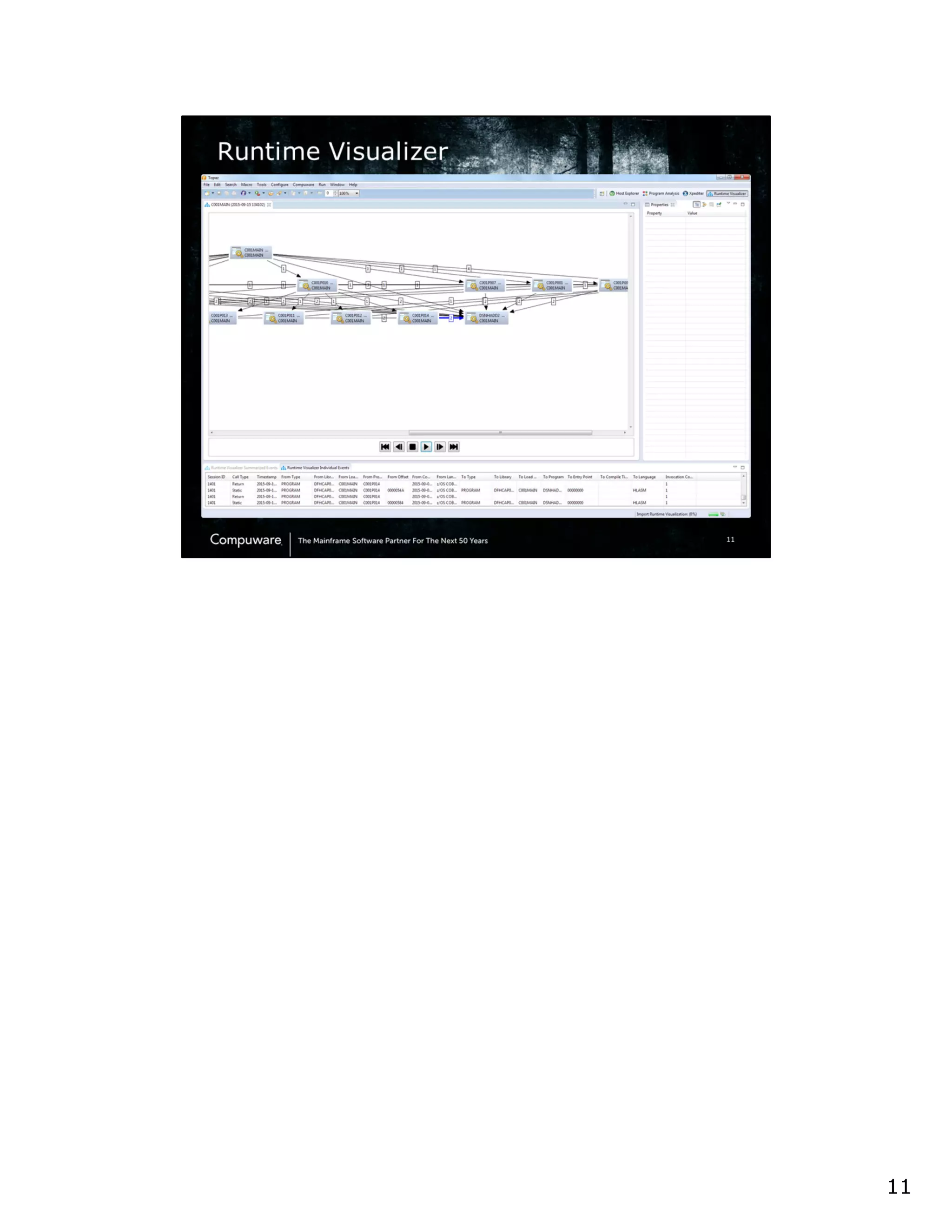
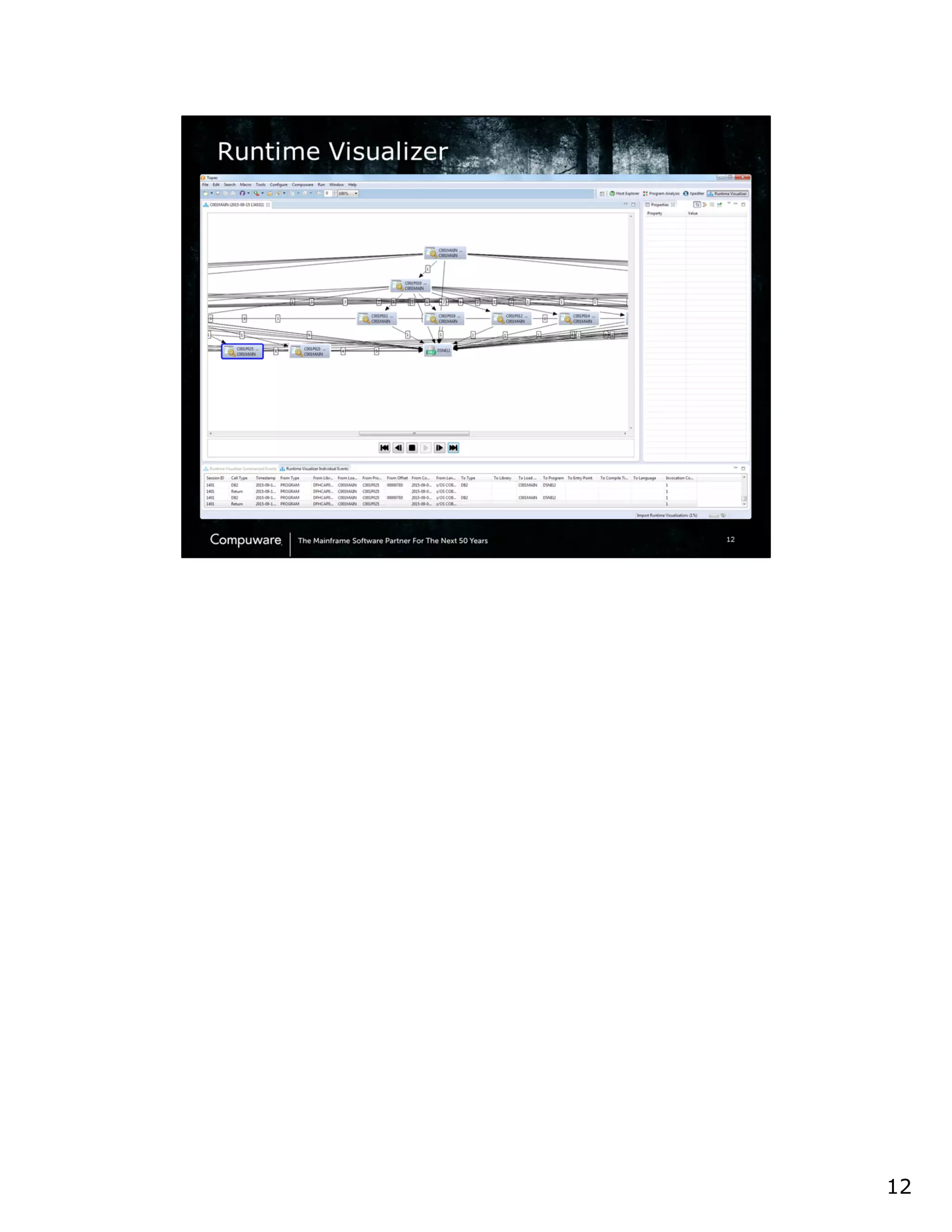
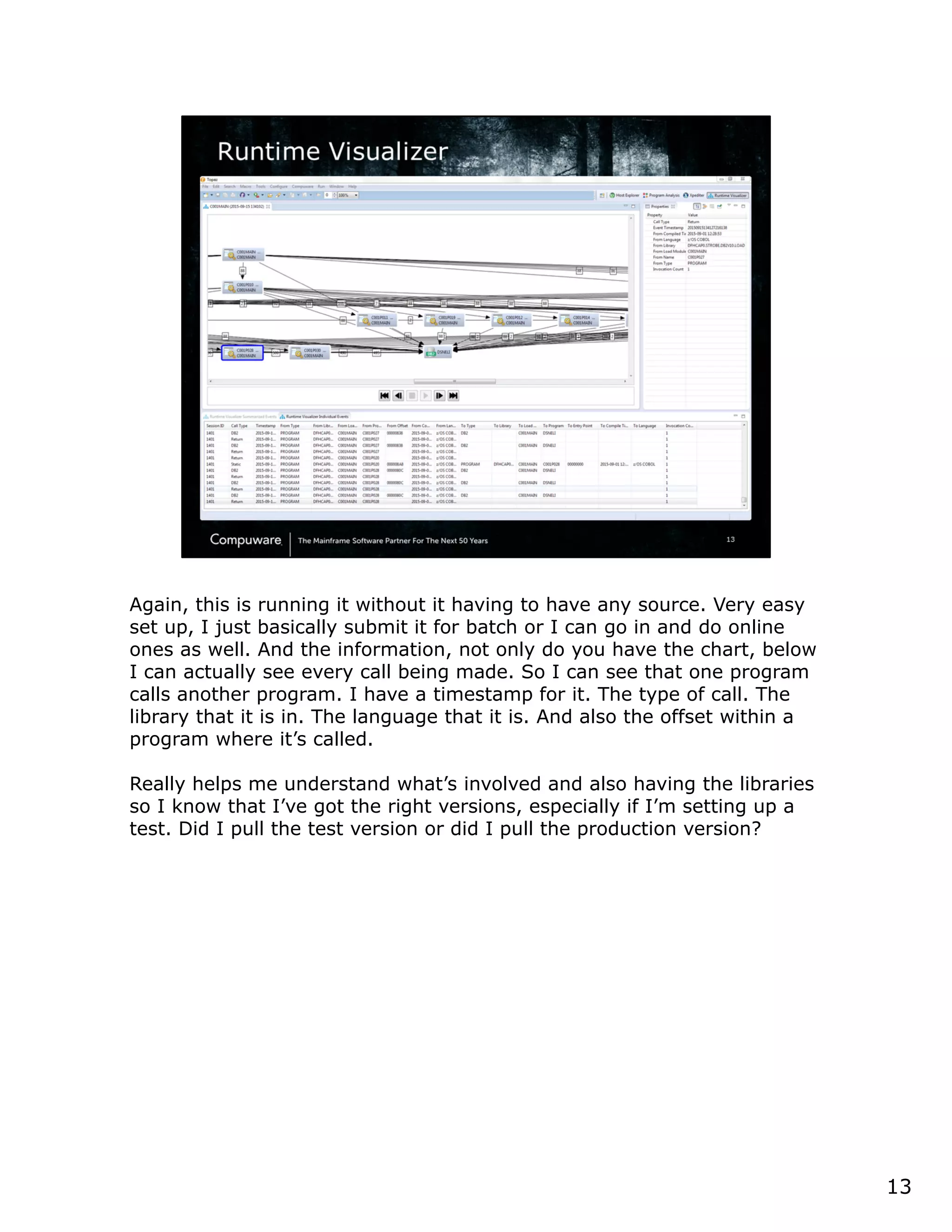
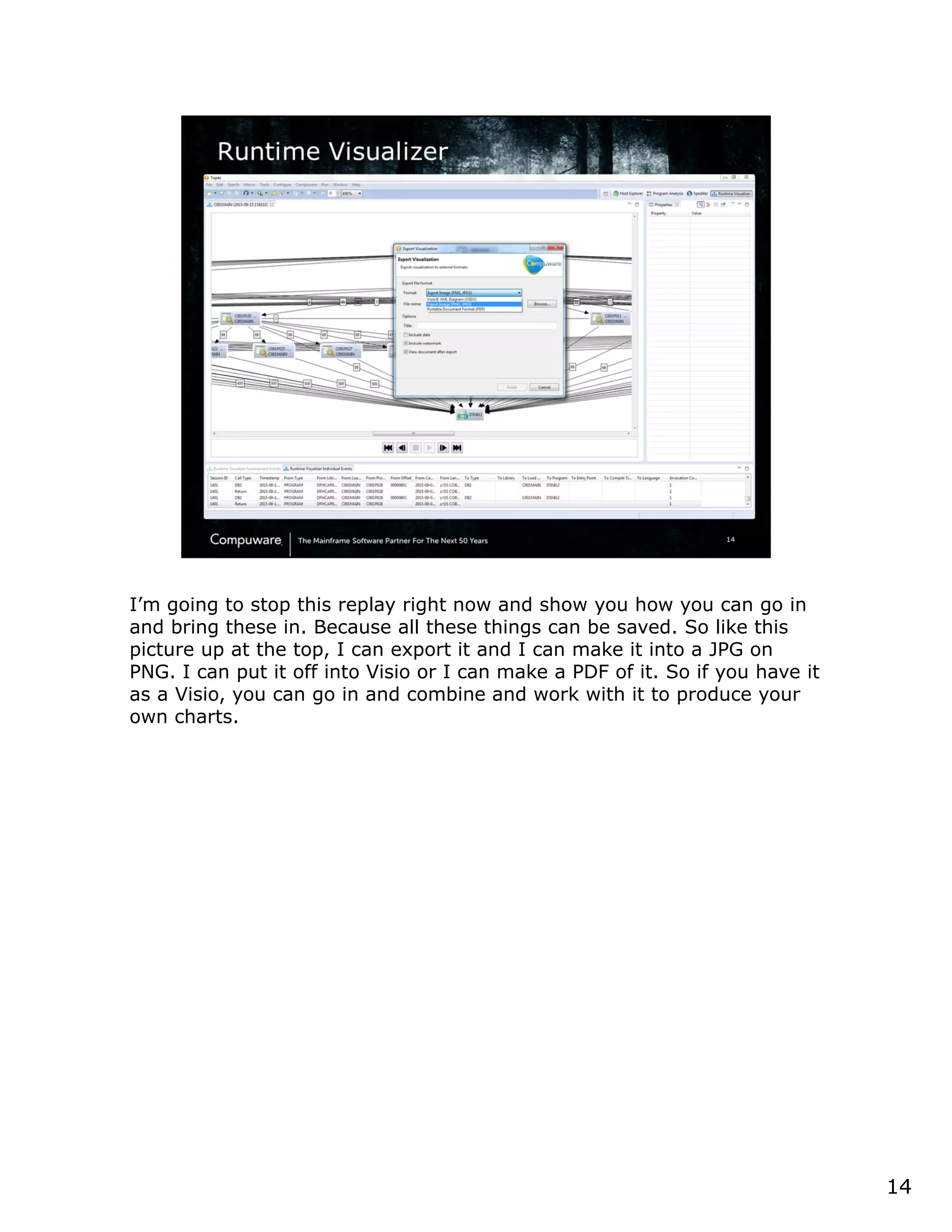
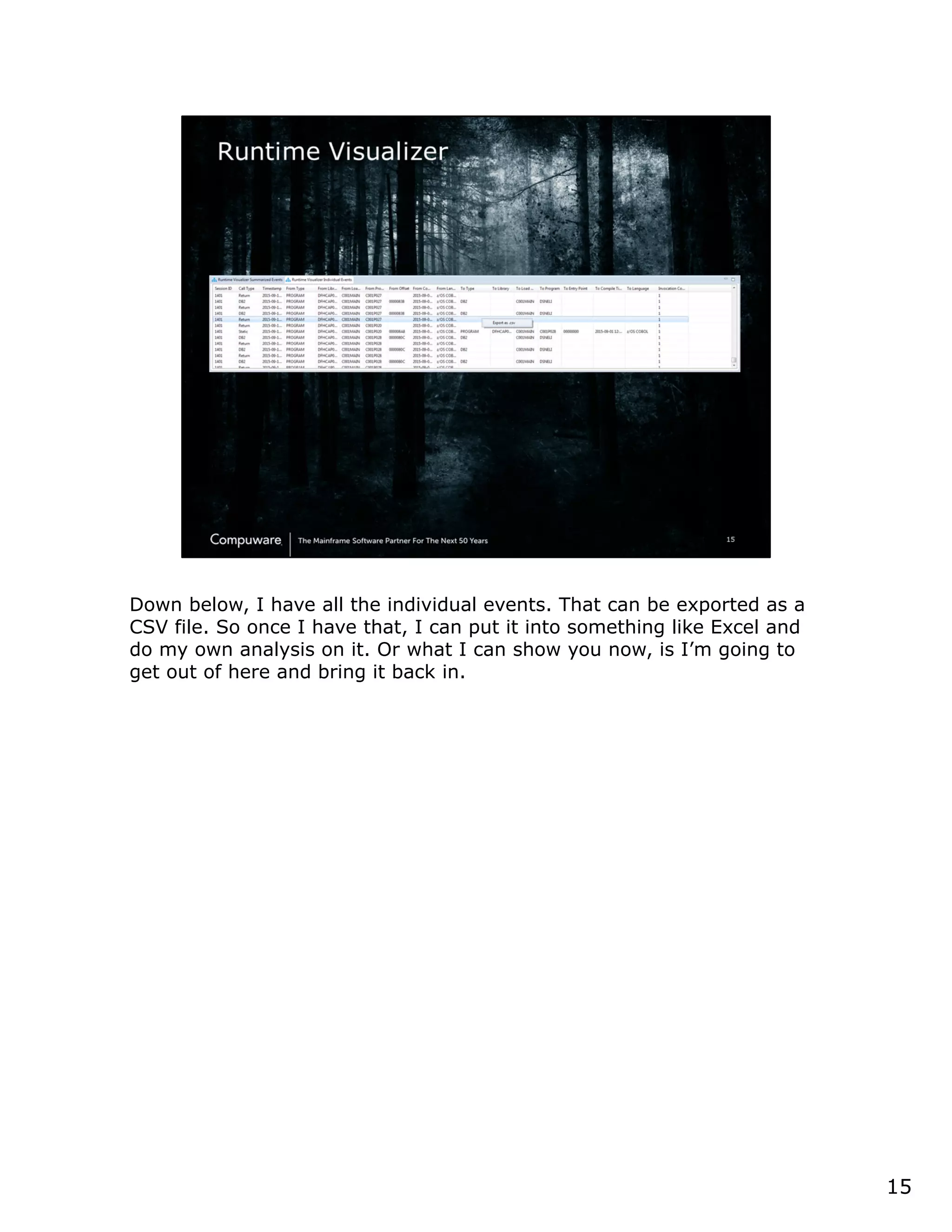
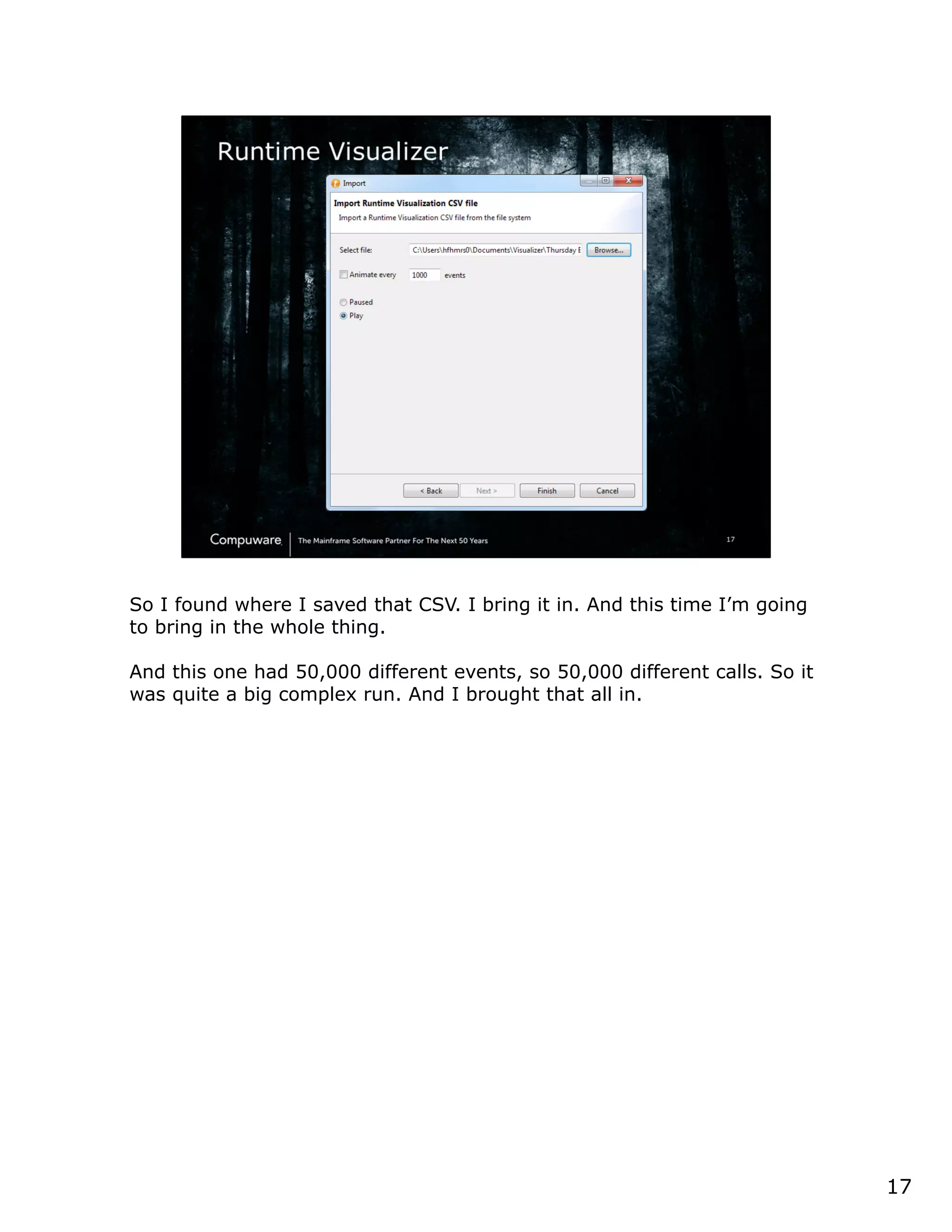
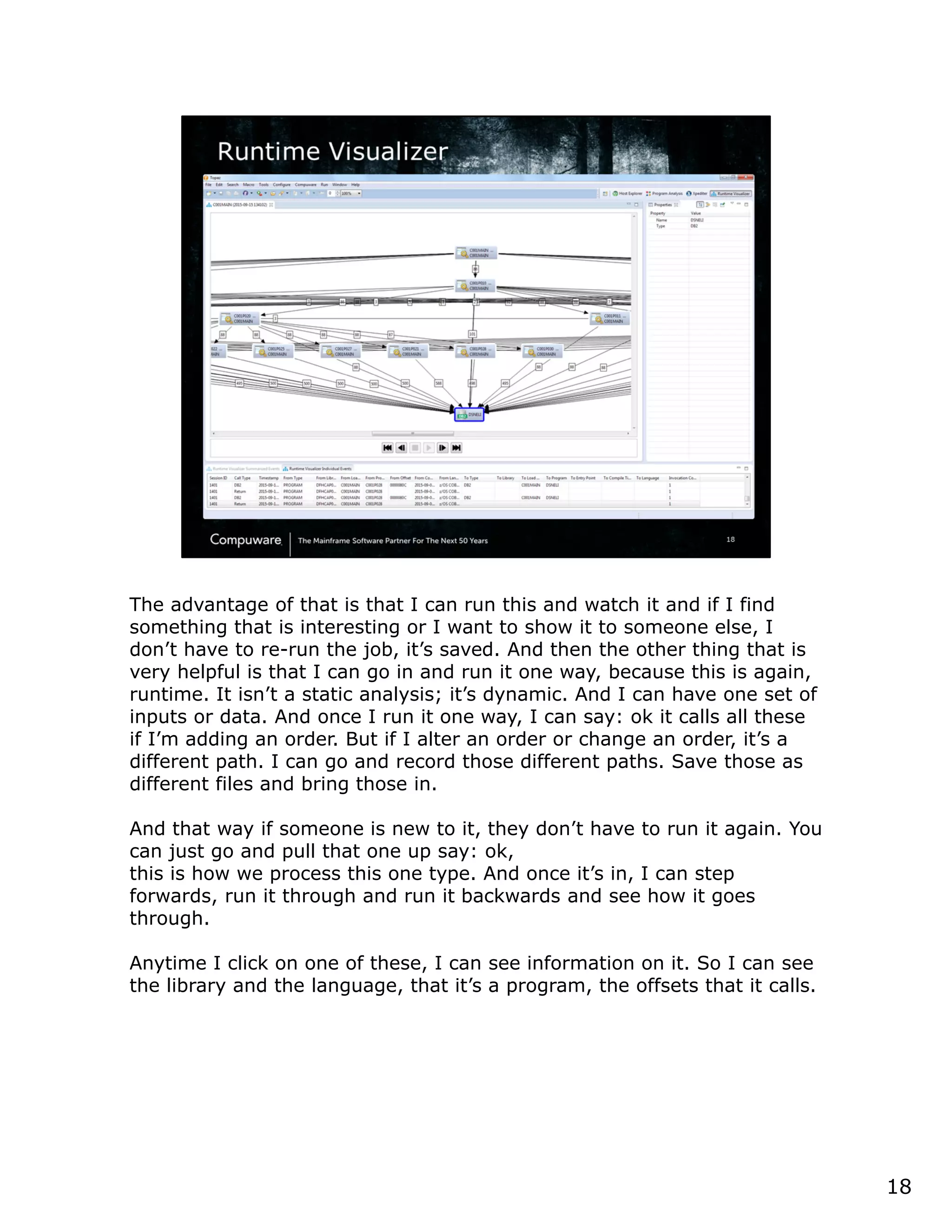
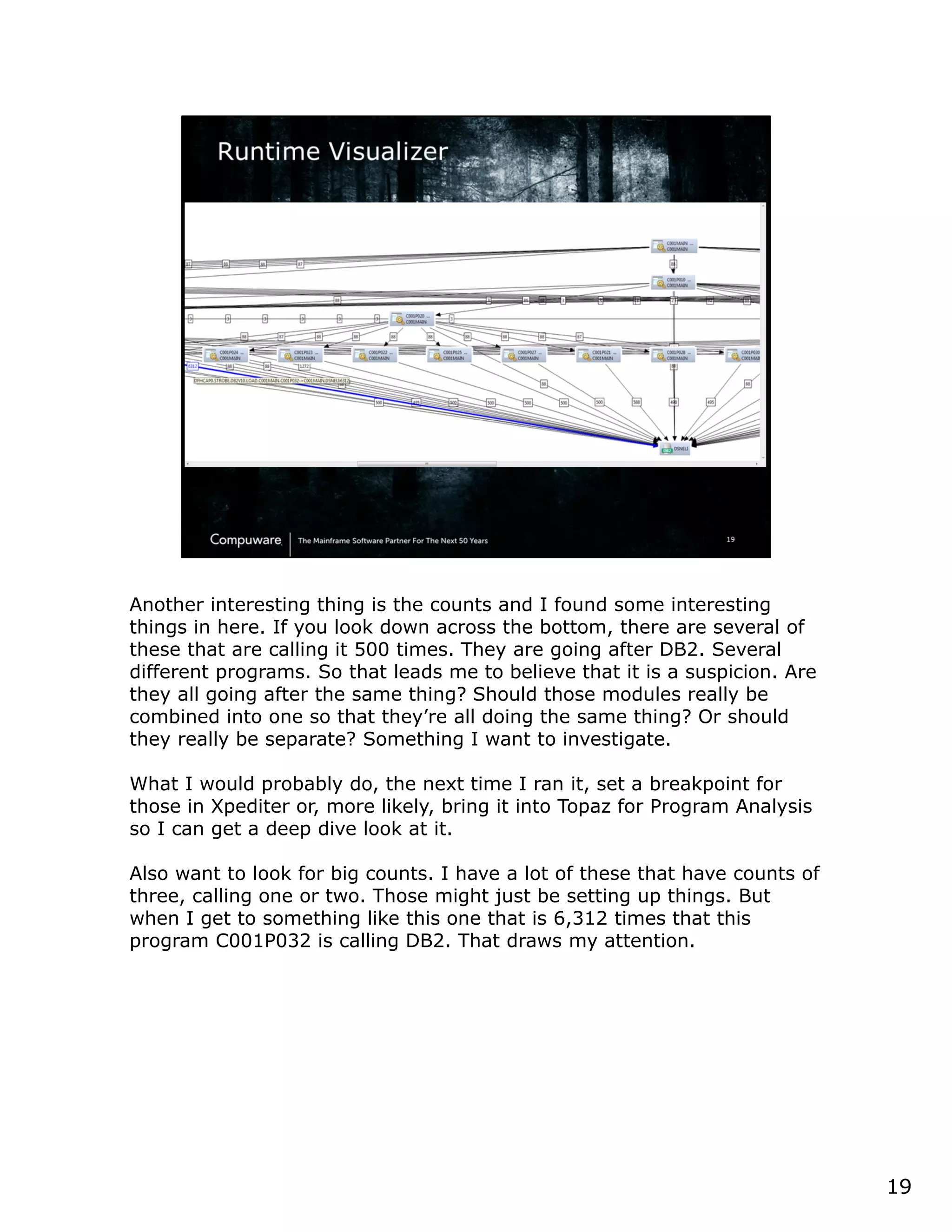



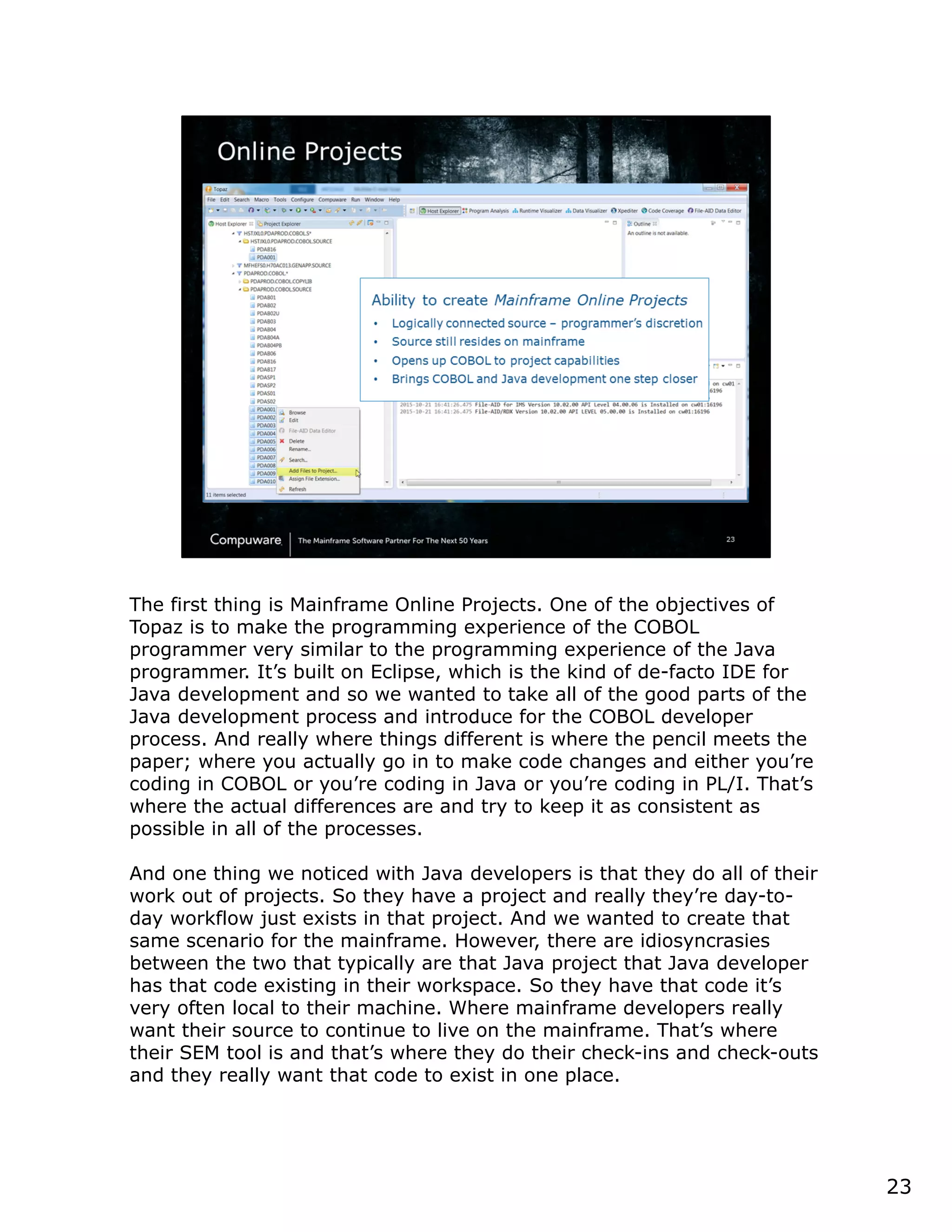













This document discusses a runtime visualizer tool that allows users to visually see how their code executes. It can dive deeper into code to help with debugging. The tool also enables online projects to connect mainframe source code logically, and provides impact analysis, program analysis and application understanding capabilities. These include seeing what programs call or are called by a given program, a program's structure and logic flow, and data flow. The document encourages that these tools can help overcome challenges in understanding unknown or complex codebases.











































![Modernize Your COBOL Testing Processes with Compuware and SonarSource [Webcast]](https://cdn.slidesharecdn.com/ss_thumbnails/31945sonarsourceandcompuwarewebcastmarch2018slideshare-180308161858-thumbnail.jpg?width=640&height=640&fit=bounds)

![What's New in ThruPut Manager [On-demand Webcast]](https://cdn.slidesharecdn.com/ss_thumbnails/31861thruputmanagerwebcast6slideshare-171212183806-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















