Downloaded 43 times














![Copyright Avi Networks 2018
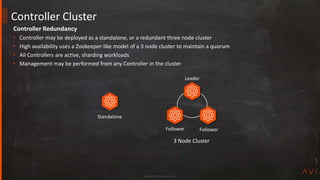
Elastic Active / Active [best practice for production apps]
• All SEs are active
• VS must be scaled across at least 2 SEs
• SE failover decision pre-determined
• Session info proactively replicated to other scaled SEs
• Faster failover, potentially greater SE resource requirement
Elastic N + M [default mode]
• All SEs are active
• N = number of SEs a new VS is scaled across
• M = the buffer, or number of failures the group can sustain
• SE failover decision determined at time of failure
• Session replication done after new SE is chosen
• Slower failover, less SE resource requirement
SE High Availability Modes
SE 1 SE 2 SE 3
SE 1 SE 2 SE 3
SE 1 SE 2 SE 3 SE 4
Steady state, each SE utilized
One SE fails
New SE created to meet HA requirement
App 2
App 1
App 2
App 3
App 2
App 4
App 2
App 1
App 3
App 2
App 4
App 2
App 1
App 2
App 4 App 3
App 2
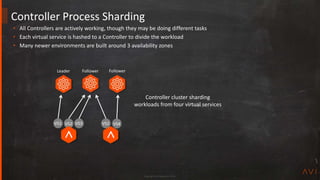
High Availability Mode A / A N + M
SE failure detection O O
Controller determines SE to fail over to O
Copy VS configuration to new SE O
Configure vNIC on new SE O
Move VIP via GARP or cloud API O O](https://image.slidesharecdn.com/avitechcorner9highavailabilityjun272019-190627182938/85/Design-Best-Practices-for-High-Availability-in-Load-Balancing-20-320.jpg)

![Copyright Avi Networks 2018
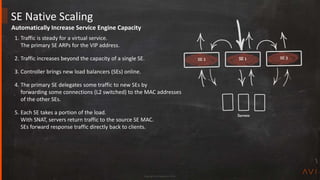
SE Auto Scaling
SE 1
Scaling
• Scale Out
• Scale In
– Gracefully remove an SE from the active/active group
– Waits one minute for connections to close before scaling in
• Migrate
1. Scale out from SE1 to SE2
2. SE2 GARPs for the VIP
3. Scale in to SE2, removing SE1 from servicing the VIP
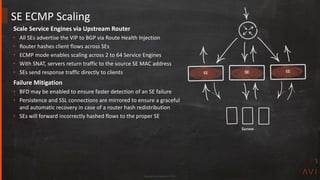
Manual Scaling
• Administrator initiated scale in, out, and migrate
• Default mode
Auto Scaling
• SE Group may be configured for manual or automatic scaling
• Avi does not [yet] recommend auto scaling
– Works for CPU above/below threshold
– Auto scale available via CLI/API](https://image.slidesharecdn.com/avitechcorner9highavailabilityjun272019-190627182938/85/Design-Best-Practices-for-High-Availability-in-Load-Balancing-24-320.jpg)




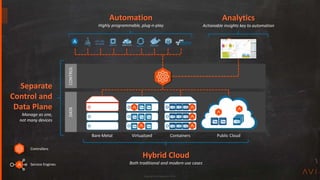
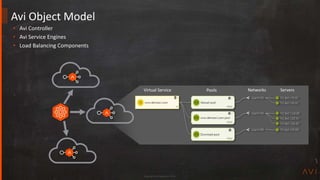
This document discusses Avi Networks' approach to high availability (HA). It describes how Avi has moved from an active-standby HA model based on physical devices to an active-active model using software-based service engines (SEs). SEs can run on bare metal, virtual machines or containers. The controller distributes load across SEs to provide nearly infinite scalability. SEs are grouped and replicate session data to provide automatic failover without impact to applications or management.




![[OpenStack Days Korea 2016] Track1 - Monasca를 이용한 Cloud 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/11hpe-160226171123-thumbnail.jpg?width=640&height=640&fit=bounds)




![[OpenInfra Days Korea 2018] (Track 2) Neutron LBaaS 어디까지 왔니? - Octavia 소개](https://cdn.slidesharecdn.com/ss_thumbnails/26octavia-180704054917-thumbnail.jpg?width=640&height=640&fit=bounds)
![PUBG: Battlegrounds 라이브 서비스 EKS 전환 사례 공유 [크래프톤 - 레벨 300] - 발표자: 김정헌, PUBG Dev...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s2-221108101842-328d500f-thumbnail.jpg?width=640&height=640&fit=bounds)












































































