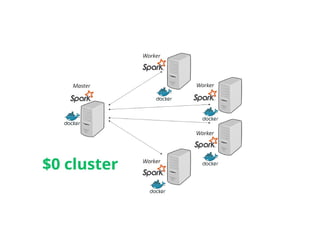
Kubernetes, a leading container orchestration platform, provides a robust environment for deploying and managing distributed applications. By deploying Spark on Kubernetes, you can take advantage of Kubernetes’ features such as dynamic scaling, fault tolerance, and resource allocation, ensuring optimal performance and resource utilization.








![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)













































